


机器学习算法库特性价值
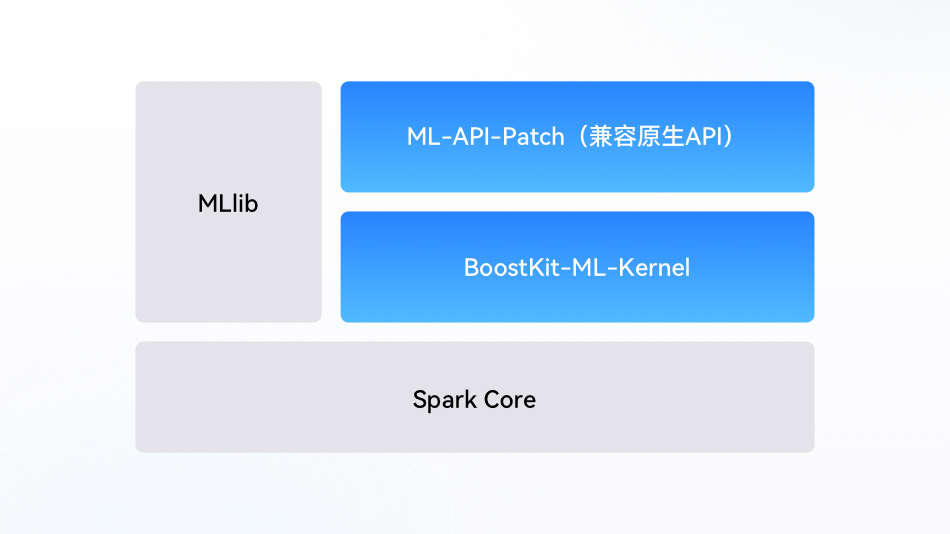
鲲鹏BoostKit机器学习算法库是经过优化的算法库,兼容Spark原生API,对机器学习算法进行了性能优化,大幅提升了大数据算法场景的计算性能
高性能
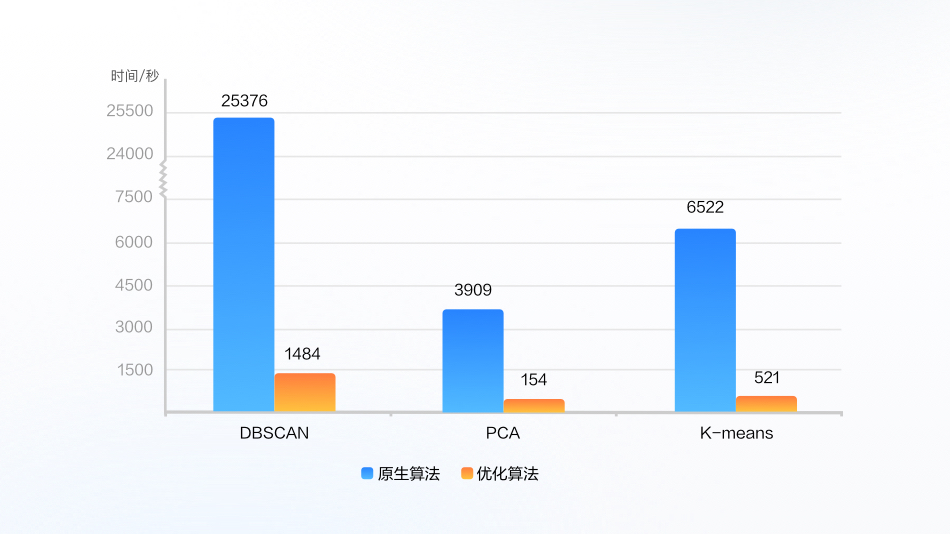
相比开源算法,性能实现倍级提升,支持更大规模数据集

覆盖全
覆盖分类回归、特征工程、聚类、模式挖掘等常用算法类型
易部署
与原生Spark算法保持完全一致的类和接口定义,无需上层应用做任何修改
基于原生算法,做了哪些创新优化
鲲鹏亲和性优化
为了充分匹配和发挥鲲鹏架构的硬件优势,鲲鹏BoostKit从多核并行、访存优化等方面进行算法亲和性优化
多核并行计算
在树模型算法中,通过数据并行和模型并行相融合的方式,在通信量不变的情况下提升算法并行度,从而发挥鲲鹏的多核优势
访存优化
在PCA等算法中,需要计算大规模矩阵的格莱姆矩阵,BoostKit算法库利用鲲鹏Cache容量大的特点,对矩阵进行分块和重排,提升Cache命中率,进而提升访存效率

快速使用算法库

'%20offset='0%25'%3e%3c/stop%3e%3cstop%20stop-color='%23969696'%20offset='100%25'%3e%3c/stop%3e%3c/linearGradient%3e%3c/defs%3e%3cg%20transform='translate(-536.0%20-2236.0)'%3e%3cg%20clip-path='url(%23i0)'%3e%3cg%20transform='translate(292.0000000000015%202208.0)'%3e%3cg%20transform='translate(242.02910884378161%2029.0)'%3e%3cpath%20d='M0,5.50423926%20L44.1917823,5.50423926%20L37.6765971,0'%20stroke='url(%23i1)'%20stroke-width='2'%20fill='none'%20stroke-miterlimit='10'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)

准备集群环境


获取算法包


软件编译


软件安装


运行验证
根据集群实际部署场景,选择参考Spark鲲鹏集群环境部署或Spark混部集群部署
学习资源


介绍类:大数据进阶算法,分析性能提升20倍
介绍大数据进阶算法关键技术和创新点,并以GBDT算法为例演示了算法库的使用
操作类:如何安装机器学习算法加速库
以安装机器学习算法库1.3.0版本为例,使能机器学习算法库,验证其相比于原生算法的优化效果


相关文档
提供配套技术文档,帮助开发者深入了解算法库



《基于鲲鹏的大数据挖掘算法实战》
面向鲲鹏生态高级开发者,提供典型算法实战赋能,帮助开发者基于鲲鹏处理器进行算法深度优化或二次开发