如何使用鲲鹏DevKit迁移工具实现软件的快速迁移
发表于 2023/06/02
0
为了解决平台差异问题,鲲鹏Devkit推出了迁移工具帮助用户进行迁移,迁移工具提供了五大迁移功能,帮助开发者简单方便的将软件迁移到鲲鹏平台上进行使用:

一个待迁移的系统往往是由很多个复杂的子组件组成的,除了自己开发的源代码,还有引用的各种依赖软件,使用鲲鹏Devkit迁移工具会使整个系统迁移工作更加简单高效。
软件迁移评估功能可以对软件包进行深入扫描,扫描软件包中不兼容的依赖库,针对性提供arm版本的依赖库,扫描报告中直接提供了下载链接可以直接进行替换;对于那些无法直接进行兼容替换的依赖库,可以获取依赖库的源码进行源码扫描迁移,或者从专项软件迁移功能提供的迁移软件列表之中搜索,专项软件迁移针对WEB、大数据、数据库等高频迁移场景提供了很多迁移好的软件,开发者可以根据迁移指导进行迁移或者直接下载替换。
源码扫描功能可以对源码包进行深入扫描,扫描报告中包含了需要修改的代码文件和详细的修改建议,点击“查看建议源码”按钮后可直接跳转到服务器对应源码文件地址,针对其中的迁移问题,开发者可以根据修改建议进行修改,或者通过QuickFix功能进行一键替换。
软件包重构功能可以对RPM、DEB、JAR、EAR包进行重构,将待迁移软件包和软件迁移评估中扫描替换得到的依赖库上传到工具中,点击“确认重构”按钮进行重构即可得到兼容鲲鹏的软件包。得到兼容鲲鹏的软件包后可以使用鲲鹏亲和分析功能进行扫描, 鲲鹏亲和分析功能支持运行模式、字节对齐、缓存行对齐、内存一致性、向量化、构建亲和、计算精度七大问题的深入扫描,给出细致的修改建议,帮助开发者快速优化问题代码。
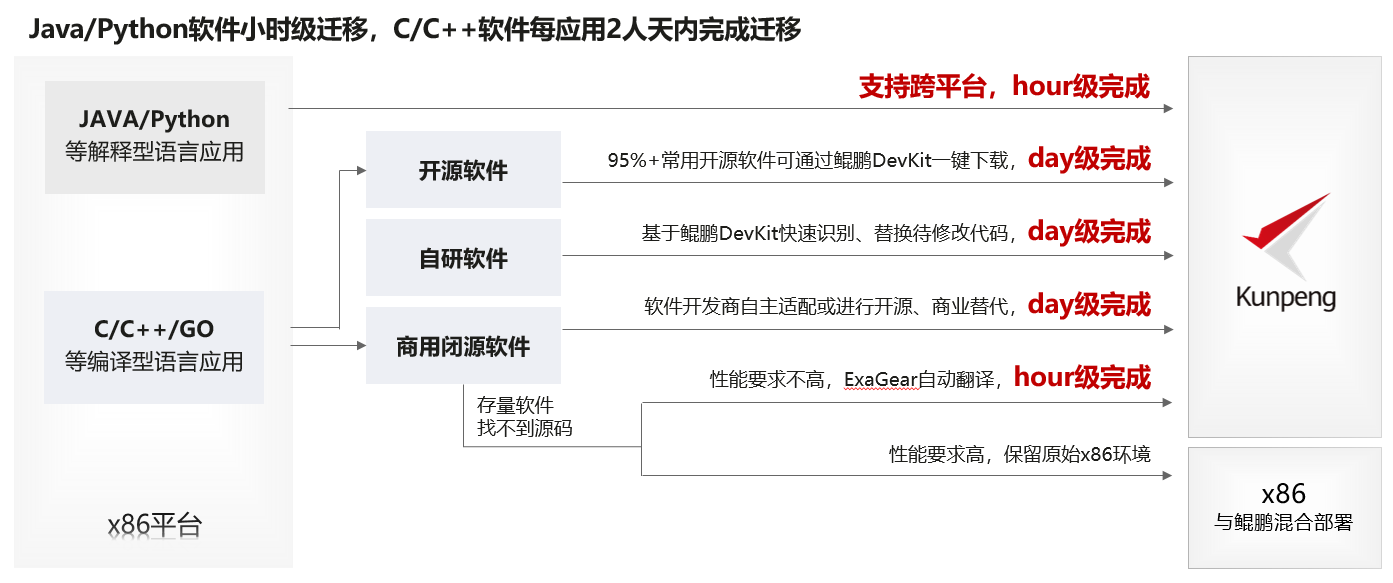
开发者进行日常代码开发过程中通常使用C++、Java、Python等语言进行应用开发,这些语言统称为高级语言,分为编译型语言和解释型语言两种类型,Java/Python/Scala等语言为解释型语言,开发的程序运行在解释器上,和底层平台无关,天然支持应用的跨平台运行。C/C++/GO等语言为编译型语言,编译型语言开发的程序在从x86处理器迁移到鲲鹏处理器时,需要经过重新编译才能运行;这两种类型的应用通过鲲鹏DevKit代码工具都可以实现快速迁移。
除了高级语言编写的程序,开发者开发的应用中还可能存在汇编代码,高级语言经过编译后会转化为汇编语言,相比于高级语言,汇编语言的执行速度更快,部分程序中的热点函数会将高频操作通过汇编语言进行编写,提升程序运行速度。
接下来将从编译型语言、解释型语言、汇编语言这几个方面介绍如何利用鲲鹏DevKit代码迁移工具对这些语言开发的程序进行迁移,降低迁移的门槛和工作量。
编译型语言迁移
编译型语言开发的程序在从x86处理器迁移到鲲鹏处理器时,需要经过重新编译才能运行。开发者使用的C/C++/Go语言,都属于编译型语言。编译型语言的代码迁移过程如下图所示,需要修改源代码和构建文件中的适配问题,对依赖文件进行检查和替换,重新编译后进行测试验证。
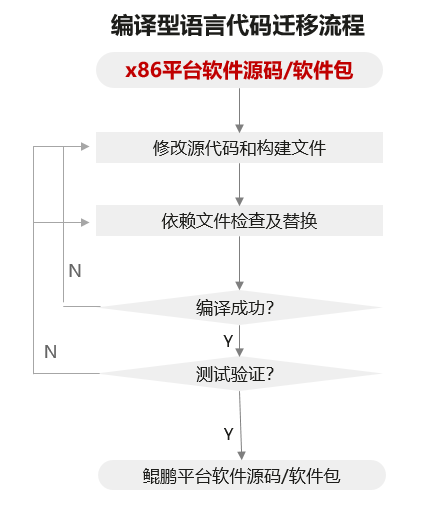
如果针对代码进行人工排查修改需要很高的技术门槛,需要了解所有相关的修改点和具体的修改措施,整个工作量将非常庞大,同时很容易出错导致不必要的重复编译测试。
开发者在进行编译型语言的迁移时可以使用鲲鹏DevKit代码迁移工具对源码包进行源码迁移扫描,根据扫描报告中提供具体的修改建议进行修改,之后重新执行编译过程就可以完成迁移了,下面将完整介绍编译型语言的源码迁移扫描报告中涉及的具体修改内容。
1.编译选项
部分传统X86平台使用的编译选项和鲲鹏平台使用的编译选项存在差异,以两个比较常见的差异点为例:
(1)在传统X86平台,定义编译生成的应用程序为64位的编译选项是-m64,在鲲鹏上是-mabi=lp64
(2)char类型变量在不同CPU架构下默认是否带符号是不一致的,在x86架构下默认为signed char(有符号字符型),在鲲鹏平台默认为unsigned char(无符号字符型)。为了保证迁移后的功能准确性,需要在编译选项中添加-fsigned-char
针对这些编译选项适配问题,开发者可以通过鲲鹏DevKit代码迁移工具的源码迁移功能进行扫描,工具会针对需要修改的点提供具体的修改建议或QuickFix一键修复功能帮助开发者快速完成修改。

2. 编译宏
很多编译型语言会在代码中添加编译宏,其中会包含平台相关的编译宏,编译宏很多时候出现在分支条件判断中,程序针对不同平台执行不同的功能,以gcc编译器自定义宏为例,X86的编译宏是__x86_64__或__x86_64,此时需要开发者添加鲲鹏对应的编译宏__aarch64__
针对这些编译宏适配问题,开发者可以通过鲲鹏DevKit代码迁移工具的源码迁移功能进行扫描,工具会针对需要修改的点提供具体的修改建议或QuickFix一键修复功能帮助开发者快速完成修改。

3. SSE/AVX/MMX指令集
SSE/AVX/MMX是x86平台上对SIMD指令集的一个扩展,主要用于处理单精度浮点数。相应的,鲲鹏使用的Arm架构提供了Neon指令作为SIMD指令集的扩展,可以加速信号处理算法和功能,可以加速音频和视频处理、语音和面部识别、计算机视觉和深度学习等应用程序。二者提供的方法和参数完全不同,需要进行修改。
如果进行人工替换需要对SSE/AVX/MMX指令和Neon指令有很深的了解,门槛很高,人工排查的工作量也很大,此时开发者可以直接导入鲲鹏提供的avx2neon.h头文件,无需进行代码修改,这个头文件可以自动帮开发者进行SSE/AVX/MMX指令到Neon指令的转换。鲲鹏DevKit代码迁移工具可以扫描到代码中涉及到的指令转换问题,并提供QuickFix一键修复功能帮助开发者快速完成修改。

4. 依赖库
编译型语言的代码开发过程会用到静态/动态库辅助开发,这些依赖库同样需要迁移,鲲鹏DevKit代码迁移工具可以对程序中使用的依赖库进行完整的扫描,并识别出哪些依赖库是可以在鲲鹏上直接兼容替换的,对于可以直接兼容替换的SO,开发者可以直接下载替换;如果依赖库无法在鲲鹏上直接兼容替换,比如一些自定义的SO,此时就需要获取SO的源码进行源码扫描重新编译,获取到鲲鹏版本的SO后对原有SO进行替换,重新进行编译过程即可获得鲲鹏版本软件包。

解释型语言迁移
解释型语言(Java/Python/Scala等)开发的程序运行在对应语言的解释器上,由解释器完成上层代码到底层指令集的翻译,这就是解释型语言的跨平台特点。例如Java语言开发的程序运行在JVM上,和底层平台无关。因此相比于编译型语言,解释型语言的迁移适配点较少。总共有如下几点:
1. 解释器替换
解释型语言开发的程序在解释器上运行,由解释器屏蔽平台间的差异,因此迁移到鲲鹏平台后需要将解释器替换为Arm版本,各语言解释器的Arm版本官方已经提供,开发者直接在官方网站获取即可。下图展示的是JDK7的官方Arm版本下载页面
2. 依赖文件替换
安装好鲲鹏版本的解释器之后,开发者可以使用软件迁移评估功能扫描出解释型应用软件包中的不兼容依赖文件,扫描结果如下图所示,图中展示的是kafka软件包的扫描结果:

工具扫描出的不兼容依赖文件主要分两种,第一种是动态库SO,部分解释型语言开发的程序会在代码中调用C/C++编写的动态库SO,这些编译型语言编写的动态库需要进行迁移适配才能在鲲鹏平台上使用,鲲鹏DevKit迁移工具可以扫描出程序中调用的动态库SO,识别出哪些依赖库是可以在鲲鹏上直接兼容替换的,对于可以直接兼容替换的SO,开发者可以直接下载替换;如果依赖库无法在鲲鹏上直接兼容替换,比如一些自定义的SO,需要获取SO的源码进行源码扫描重新编译;
第二种是jar/war等依赖包,在代码开发过程中,解释型语言会用到很多第三方依赖包,常见的依赖包格式有JAR/WAR/EAR这三种,这些依赖包中可能会存在调用动态库SO的情况,也需要进行迁移。针对那些可以在鲲鹏上进行兼容替换的JAR/WAR/EAR依赖包,开发者可以直接下载替换;相比于扫描之后手动替换依赖包,建议开发者可以直接在程序中配置鲲鹏maven仓,优先获取兼容鲲鹏的依赖包,目前鲲鹏maven仓中包含6k+兼容鲲鹏的依赖包,帮助开发者更方便的进行依赖包替换。鲲鹏maven仓地址:
https://mirrors.huaweicloud.com/kunpeng/maven/
针对少数鲲鹏Maven仓中未提供的依赖包,开发者可以通过代码分析该依赖包是否需要进行替换,有如下两个常见场景是无需替换依赖包的:
(1)如果依赖包的调用逻辑写在了X86等其他平台的运行分支中,则无需替换,因为在鲲鹏Arm平台实际运行的过程中不会调用该Jar包
(2)程序调用的Jar包功能不涉及需要替换的SO时,则该Jar无需进行替换
获取到替换的依赖文件后,开发者可以使用软件包重构功能,将待迁移的软件包和获取的依赖文件上传到工具中,通过工具进行软件包的重构,之后就可以获取到迁移好的鲲鹏版本软件包了。
汇编语言迁移
编译型语言、解释型语言这类高级语言编写的程序,经过编译器编译后会转换为汇编代码。相比于这些高级语言,汇编代码的运行效率更高,一些高级语言开发的程序会在代码中嵌入汇编代码来提高运行效率。第2小节中提到由于X86平台和鲲鹏平台的指令集差异,导致汇编代码存在非常大的不同,如果需要人工修改门槛很高,而且工作量巨大。
此时开发者可以通过鲲鹏DevKit代码迁移工具对源码包进行扫描,针对嵌入式汇编这种汇编代码片段,工具提供了一键修复功能进行汇编代码的快速替换;
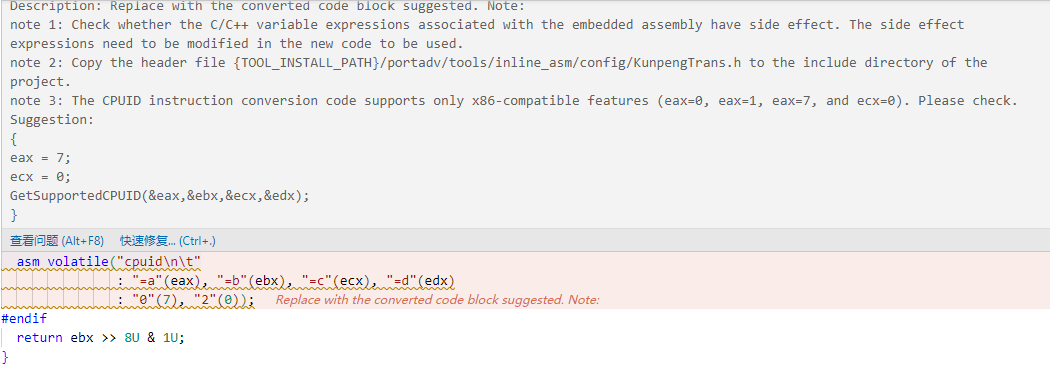
对全汇编文件,可以通过工具进行汇编文件的一键替换,极大降低了汇编代码迁移的门槛和工作量。