


GCC for openEuler -mcmodel选项详解
发表于 2021/12/24
0
导语
GCC for openEuler是基于开源GCC开发的编译器工具链(包含编译器,汇编器,链接器),在openEuler社区开源发布,并通过鲲鹏社区免费提供二进制包,支持包含ARM、x86在内的多种处理器架构。
本文将向大家详细介绍-mcmodel选项的作用以及GCC for openEuler 在-mcmodel选项上做的新功能支持[1]。
背景
编译的过程中,编译器是不知道要操作的数据在哪里的,计算数据地址的工作是在链接阶段实现的。也就是说,编译器需要先把拿取数据的汇编指令定下来,在编译结束之后,链接器进行重定位计算时再填上指令的操作数是多少。那就有一个问题,编译器如何选择一个合适的指令拿取数据?
PC相对寻址
在考虑这个问题前,我们先了解一下PC相对寻址。PC(Program Count)特指PC寄存器(以下都用PC表示),是计算机处理器内部的一个专用寄存器,用来表示下一个将被执行的指令的地址。在我们的程序中,如果某一条指令访问的符号(变量,函数等)是基于当前指令的相对地址,我们就称这是PC相对寻址。
例如跳转指令b, <label>中的 <label> 就是偏移量,并不是绝对地址。在链接阶段,链接器会根据符号出现的位置计算出正确的偏移,编码到指令中去。程序执行到这条指令时,就会把<label>所代表的偏移量与当前PC值相加,得到要跳转的指令地址。类似的还有ADR,ADRP指令。ADR/ADRP分别是获取某个符号的地址/页面地址,并把它们存放到指定的寄存器中。它们的格式是这样的:ADR Rd, <label>, ADRP Rd, <label>, 这里的<label>都是代表当前指令位置的偏移量。
<label>受到指令位域的限制,所以偏移量都是有限制的。比如说b, <label> 可以基于当前PC有±128MB的寻址范围,ADR Rd, <label>有±1MB的寻址范围,ADRP Rd, <label>有±4GB的寻址范围。
链接器在链接时会把各个目标文件进行合理布局,使得跳转、函数调用、变量访问等操作都不会离当前指令特别远。通常情况下,使用前面提到的指令能满足绝大多数的情景,但是如果指令要访问的符号超出了4GB(32位)的范围,这时用默认的符号取值方式就会出错。
案例
比如说在AArch64后端如果待链接符号的距离超过4GB(如图1),编译的时候又决定使用ADRP指令(32bit寻址范围,如图2)。此时如果使用这种方式去链接,则会报relocation truncated to fit这样的错(如图3)。
图1:符号相对于.bss段的偏移大于4GB
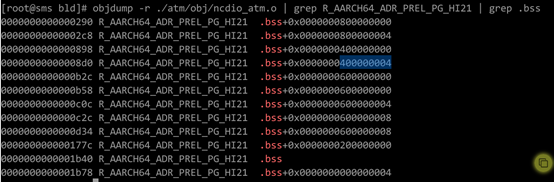
图2:指令集中对于ADRP指令的描述,可见其寻址范围只在±4GB

图3:CESM代码中出问题的字段描述,R_AARCH64_ ADR_PREL_PG_HI21对应ADRP指令进行相对PC寻址

那么怎么解决这个问题?在这种情况下需要指导编译器:符号可能特别远(超过4GB),需要生成恰当的指令来获取符号地址。那么编译器就不会再用传统的ADRP这样的指令,而是采用其他的办法。
对此,GCC提供了-mcmodel参数,用于指导编译器应该使用哪种模型来生成指令。下面是GCC的-mcmodel对AArch64架构的的官方说明:
-mcmodel=tiny
Generate code for the tiny code model. The program and its statically defined symbols must be within 1MB of each other. Programs can be statically or dynamically linked.
-mcmodel=small
Generate code for the small code model. The program and its statically defined symbols must be within 4GB of each other. Programs can be statically or dynamically linked. This is the default code model.
-mcmodel=large
Generate code for the large code model. This makes no assumptions about addresses and sizes of sections. Programs can be statically linked only. The -mcmodel=large option is incompatible with -mabi=ilp32, -fpic and -fPIC.-mcmodel选项指导编译器做出这样一种假设:代码里所有符号的位置都在某个位宽范围之内。比如-mcmodel=small,就是假设所有符号都在4GB范围内,32bit的位宽就可以找到符号的位置,那我们使用ADRP指令就可以了。但是假设不成立的时候,比如上面的情况,ADRP指令不再适用,需要用位宽更大的指令。这个时候就需要增大-mcmodel的预设,使用-mcmodel=large,变更寻址方式为LDR指令。LDR指令只能绝对寻址,但是有更大的寻址范围。如果你的应用可以非地址无关编译的话,那么-mcmodel=large理论上可以解决所有的问题。
而例如HPC场景中的CESM应用在符号超过4GB寻址范围的时候,作为一些共享库,仍然需要按照地址无关代码(position-independent code,PIC) 的方式编译(-fPIC / -fpic地址无关功能),可以说地址无关代码是动态共享库必须的。这时LDR指令也不再适用,因为GCC对于AArch64的支持非常有限,它仅支持非地址无关代码。这是AArch64独有的一类问题。
图4:aarch64 -mcmodle=large时的寻址方式
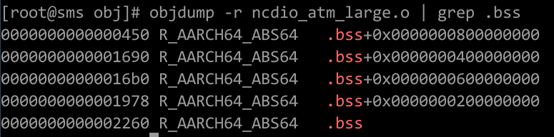
在x86上有可以大位宽操作的mov指令,它可以实现4GB以上的地址无关寻址。根据与x86后端对比可以发现,x86后端在-mcmodel=medium的时候之所以还可以生成地址无关代码,主要原因是其寻址方式还是相对PC寻址。与-mcmodel=small相比唯一的变动是相对寻址的指令由mov变成了movabs,可以进行更大范围的寻址(64bit)。
图5:x86 ABI 中对于-mcmodle=medium、-mcmodle=large的描述

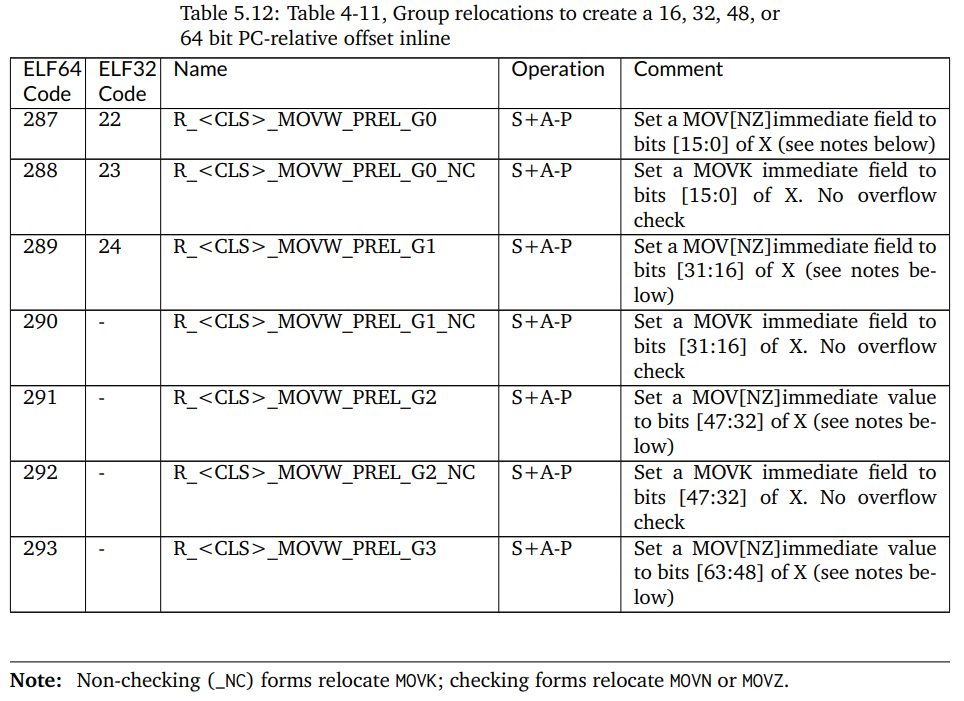
反观AArch64后端,其实相对PC寻址的指令和64bit的加法指令都是有的,甚至是64位的相对PC寻址方式在ABI中都是有的(如图6),缺少的是这种重定位方式。
图6:AArch64 ABI 中关于64位相对PC寻址的描述
-mcmodel=medium, -mlarge-data-threshold=n
GCC for openEuler根据上述问题的痛点,新开发了-mcmodel=medium, -mlarge-data-threshold=n两个选项。此选项使能了32bit之外的动态取址操作。在使用-mcmodel=medium时,对于符号size大于aarch64_data_threshold的符号使用通过mov序列来获取PC值的offset,再与PC值相加的方式实现64bit的相对PC寻址,在地址无关选项打开时,可以实现64bit相对PC寻址,获取GOT表入口,并且通过mov序列+LDR方式获取符号。
说明:aarch64_data_threshold的默认值为2^16 = 65536,用户可以使用-mlarge-data-threshold=n选项指定大符号的阈值为n。
举例
如图7所示,假设foovar的符号距离寻址指令的距离大于4GB,-mcmodel=small会使用ADRP+ADD指令进行符号拿取,而foovar在链接时计算距离的方式是如使用方法中的.bss+size方式,在链接时会报relocation truncated to fit错误。在此使用图8中的mov序列+PC寻址方式可将寻址范围扩大至64位,解决由于地址溢出导致的报错。
图7:smallcode model寻址方式
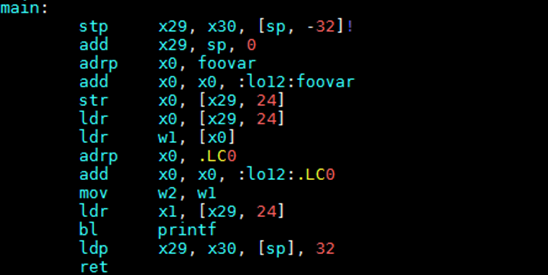
在这种模式下,通过adrp和add指令获取foovar的地址。adrp是PC相对寻址,它会把foovar的页地址偏移量与当前PC值相加,并存储到x0寄存器,下一条指令add把页内地址(低12位)再加到x0寄存器上,这样就得到了foovar的地址。
图8:mov序列+PC寻址方式
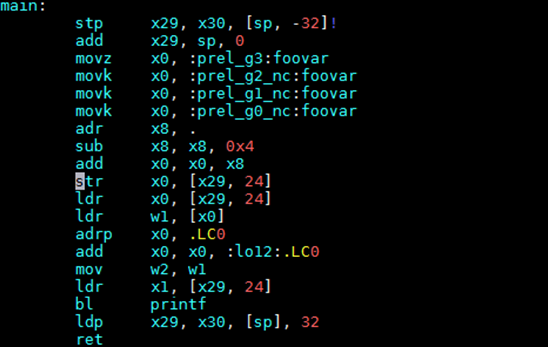
可以看出这里使用了movz, movk, adr, sub, add这样一系列的指令最终得到了foovar的地址。movz和3条movk指令的作用是把foovar的64位的偏移量分4次,每次转存16位,依次存放到了x0寄存器,adr x8, .的作用是获取当前的PC值,sub是对PC值做一些修正,然后add是把64位偏移量与修正后的PC值相加。这样就得到具有64位PC相对地址的foovar地址了。
使用方法
用例:
libdemo.cpp
#include <iostream>
char arr[10][1*1024*1024*1024];
void set_and_print(){
arr[8][0]='A';
std::cout << arr[8][0] << std::endl;
}上述代码定义了一个二维数组arr,第一维有10个元素,每一个元素又是一个总大小为1GB的字符数组。在访问arr[8][0]时需要偏移8GB,已经超过了ADR, ADRP这样的取值范围。
main.cpp
extern char arr[10][1*1024*1024*1024];
void set_and_print();
int main(){
set_and_print();
return 0;
}主程序会使用共享库中的set_and_print函数。
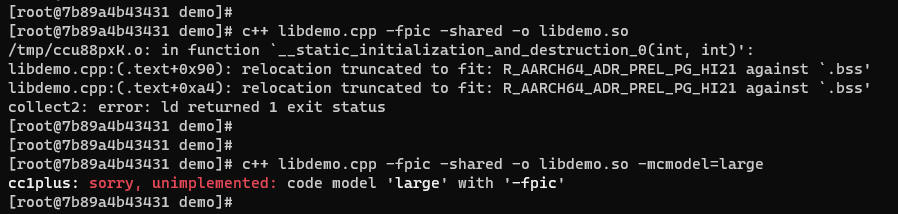
现在我们来编译上面的代码。如下图所示,如果不指定-mcmodel参数就会报relocation truncated to fit错误;当程序指定-mcmodel=large时,又与-fpic冲突,无法生成动态共享库。
图9:不指定-mcmodel,或者指定-mcmodel=large进行编译,编译失败
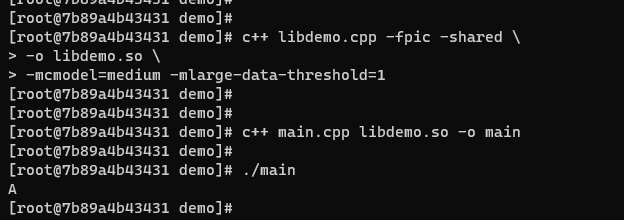
当我们使用GCC for openEuler开发的-mcmodel=medium和-mlarge-data-threshold=1后,动态共享库被成功创建了,主程序也能正常调用它,并且得到正确的结果。
图10:指定-mcmodel=medium -mlarge-data-threshold=1进行编译,编译成功
我们对共享库进行反编译查看汇编代码就会看到,取址指令已经是movz, movk这样的序列了。
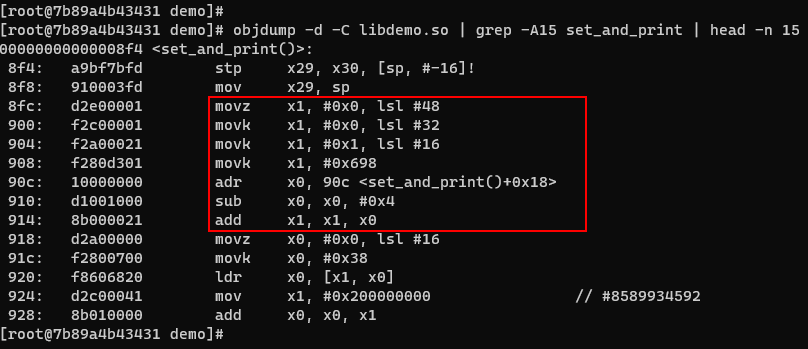
编译命令:
c++ libdemo.cpp -fpic -shared -o libdemo.so -mcmodel=medium -mlarge-data-threshold=1
c++ main.cpp libdemo.so -o main运行主程序:
./main总结
该选项通过软件模拟的方式,使用多条指令去模拟movabs指令,使得在HPC领域一些需要大范围地址无关寻址的应用能够平滑地从其他平台迁移到鲲鹏平台中来。
所以在GCC for openEuler使用过程中,若出现relocation truncated to fit错误,可以尝试添加编译选项-mcmodel=medium -mlarge-data-threshold=1解决。
时间问题暂时写到此处,后续会继续更新一些GCC for openEuler或者毕昇编译器相关优化选项的介绍,感兴趣的朋友敬请博客留言,也可以点击文末阅读原文进入GCC for openEuler网页下载使用GCC for openEuler。
参考
[1] https://bbs.huaweicloud.com/blogs/272527