


LLVM后端流程简介
发表于 2022/01/21
0
Program Work Flow
如果我们要编译 OpenCL/CUDA 代码,并已经有了一些 OpenCLl/CUDA kernel,以及在主机端运行的代码。主机端代码调用 kernel。如下图所示:
图 1
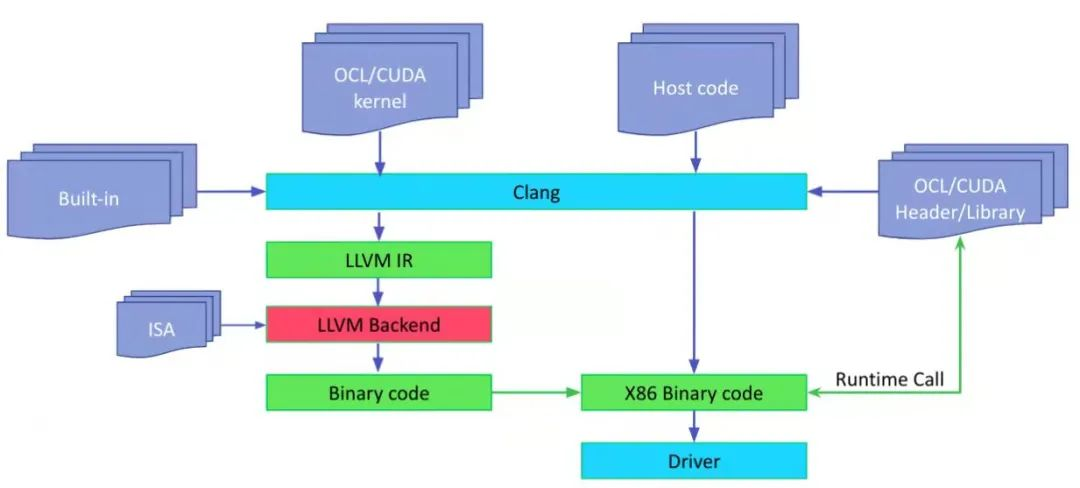
在主机端,执行 Clang 编译主机代码,这和正常编译类似,但是要链接 openCL/CUDA runtime。对 kernel 代码,也会执行 Clang 编译 kernel 代码,生成 LLVM IR。为了支持 kernel built-in function,这里使用 built-in lib,比如对 OpenCL,一般使用的 built-in lib 是 libclc。
主机代码调用 runtime api,比如 OpenCL 的 clCreateProgramWithBinary,生成 kernel。主机端代码也可以调用其它 runtime call 来为相应设备创建 comandQueue,或者得到设备或平台信息。
Pipeline
LLVM backend 的主要功能是 code gen,也就是代码生成,其中包括若干个 code gen 分析换转化 pass 将 LLVM IR 转换成特定目标架构的机器代码。当然我们希望这个机器代码是最优化的机器代码。LLVM backend 具有流水线结构,如下图所示。指令经过各个阶段,从 LLVM IR 到 SelectionDAG,再到 MachineDAG,再到 MachineInstr,最后到 MCInst。有些资料中不将 MachineDAG 不做为单独的一种指令格式,因为其基本格式仍然是 SelectionDAG,只不过其中的指令是目标相关指令。这其中经过的各个阶段实际是不同的 pass,包括 Instruction selection(指令选择)、Register Allocation(寄存器分配),Instruction Scheduling 以及 Code Emission。不同的 target 的 backend 根据需要对不同 pass 做 customization。
图 2
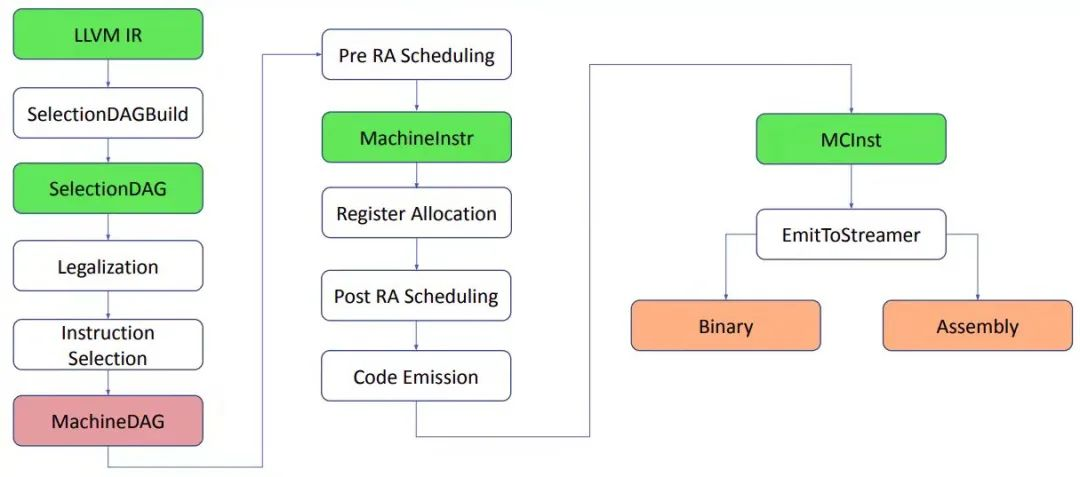
下面来具体看看每个 pass 和步骤的功能。
1. 首先,SelectionDAGBuilder 遍历 LLVM IR 中的每一个 function 以及 function 中的每一个 basic block,将其中的指令转成 SDNode,整个 function 或 basic block 转成 SelectionDAG。这时 DAG 中每个 node 的内容仍是 LLVM IR 指令。
2. SelectionDAG 经过 legalization 和其它 optimizations,DAG 节点被映射到目标指令。这个映射过程是指令选择。这时的 DAG 中的 LLVM IR 节点转换成了目标架构节点,也就是将 LLVM IR 指令转换成了机器指令。所以这时候的 DAG 又称为 MachineDAG。
3. 在 MachineDAG 已经是机器指令,可以用来执行 basic block 中的运算。所以可以在 MachineDAG 上做 Instruction Scheduling 确定 basic block 中指令的执行顺序。指令调度分为寄存器分配前的指令调度,和寄存器分配后的指令调度。寄存器分配前的指令调度器实际有 2 个,作用于 SelectionDAG,发射线性序列指令。主要考虑指令级的平行性。经过这个 scheduling 后的指令转换成了 MachineInstr 三地址表示。指令调度器有三种类型:list scheduling algo, fast algo, vliew。
4. 寄存器分配,为 virtual Register 分配 physical Register 并优化 Register 分配过程使溢出最小化。
virtual Register 到 physical Register 的映射有两种方式:直接映射和间接映射。直接映射利用 TargetRegisterInfo 和 MachineOperand 类获取 load/store 指令插入位置,以及从内容去除和存入的值。间接映射利用 VirtRegMap 类处理 load/store 指令。寄存器分配算法有 4 种:Basic Register Allocator、Fast Register Allocator、PBQP Register Allocato、Greedy Register Allocator。
5. 寄存器分配后的指令调度器作用于机器指令,也就是 MachineInstr。这时能得到 physical Register 信息,可以结合 physical Register 的安全性和执行效率,对指令顺序做调整。
6. Code emission 阶段将机器指令转成 MCInstr,并发射汇编或二进制代码。
Initial Selection Construction
SelectionDAG 类用一个 DAG 表示一个 basic block。SelectionDAG 的创建是个基本的窥孔算法。LLVM IR 经过 SelectionDAGBuilder 的处理后转换成 SelectionDAG。下图是 C 代码实现除法,只有一个 function,一个 basic block。
图 3
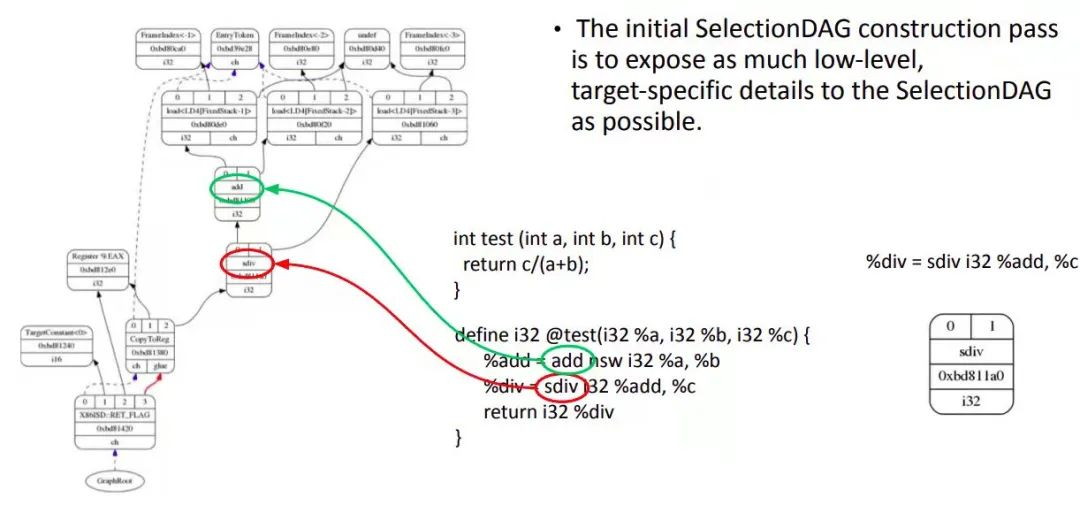
IR 经过多个优化 pass 做进一步优化后由 SelectionDAGBuilder 类产生 Selection DAG 节点。当 SelectionDAGBuilder 遇到 IR 指令,调用相应的 visit() 方法,比如,如果是 SDIV 操作,就调用 visitSDiv() 方法将两个操作数保存到 SDValue,从 DAG 中得到一个 SDNode 节点并以 ISD::SDIV 作为其操作符。在该 IR 中,操作数 0 为 %add,操作数 1 为 %c。其它计算也做类似处理。处理完所有 IR 指令后,IR 被转为如图所示的 SelectionDAG。每一个 DAG 表示一个基本块中的计算,不同的基本块与不同的 DAG 关联。节点表示计算,边有不同含义。将 IR 转化为 DAG 很重要,因为这可以让代码生成器使用基于树的模式匹配指令选择算法。此时的 SelectionDAG 还与目标设备无关,但对于具体目标设备来说,有些指令可能不合法,因为不同目标设备支持的指令集不同,指令集中的指令与 IR 指令可能没有对应关系。例如,x86 不支持 SDIV 而支持 SDIVREM。
下面详细介绍 DAG 图中不同符号的含义。DAG 中的每个节点 SDNode 会维护一个记录,其中记录了本节点对其它节点的各种依赖关系,这些依赖关系可能是数据依赖(本节点使用了被其它节点定义的值),也可能是控制流依赖(本节点的指令必须在其它节点的指令执行后才能执行,或称为 chain)。这种依赖关系通过 SDValue 对象表示,对象中封装了指向关联节点的指针和被影响结果的序列号。也可以说,DAG 中的操作顺序通过 DAG 边的 use-def 关系确定。如果图中的 SDIV 节点有一个输出的边连到 add 节点,这意味着 add 节点定义了一个值,这个值会被 SDIV 节点使用。因此,add 操作必须在 SDIV 节点之前执行。
1. 黑色箭头表示数据流依赖。数据流依赖表示当前节点依赖前一节点的结果。
2. 虚线蓝色箭头表示非数据流链依赖。链依赖防止副作用节点,确定两个不相关指令的顺序。比如,load 和 store 指令如果访问相同的内存位置,就必须和他们在原程序中的顺序保持一致。从图中的蓝色箭头可知,CopyToReg 操作必须在 ret_flag 之前发生,因为他们之间是链依赖。
3. 红色箭头表示 glue 依赖。Glue 是用来防止两个指令在 scheduling 时分开,即他们中间不能插入其它指令。
每个节点的类型,可以是实际的数据类型,如 i32,i64 等,也可以是 chain 类型,表示 chain values,或者是 glue 类型,表示 glue。
SelectionDAG 对象有一个特殊的 EntryToken 来标记 basic block 的入口。EntryToken 的类型是 ch,允许被链接的节点以这个第一个 token 作为起始。
在这张图中,目标无关和目标相关的节点共存。CopyFromReg、CopyToReg、add 等是目标无关节点;Register %EAX、TargetConstant 和 ret_flag 是目标相关节点。
1. CopyFromReg:copy 当前 basic block 外的 register,用在当前环境,这里用于 copy 函数参数。
2. CopyToReg:copy 一个值给特定寄存器而不提供任何实际值给其它节点消费。然而,这个节点产生一个 chain value 被其它节点链接,这些其它节点不产生实际值。比如为了使用写到 EAX 的值,ret_flag 节点使用 EAX 寄存器提供的 i32 结果,并消费 CopyToReg 节点产生的 chain,这样保证 EAX 随着 CopyToReg 更新,因为 chain 会使得 CopyToReg 在 ret_flag 之前被调度。
Legalization
从 SelectionDAGBuilder 输出的 SelectionDAG 还不能做指令选择,在 SelectionDAG 机制从 DAG 节点产生机器指令之前,DAG 节点还要经过几个转化阶段,其中合法化是最重要的阶段,如下图所示。做合法化的原因是 SelectionDAGBuilder 构造的 SDNode 中的指令操作数类型和操作不一定能被目标平台支持。
图 4
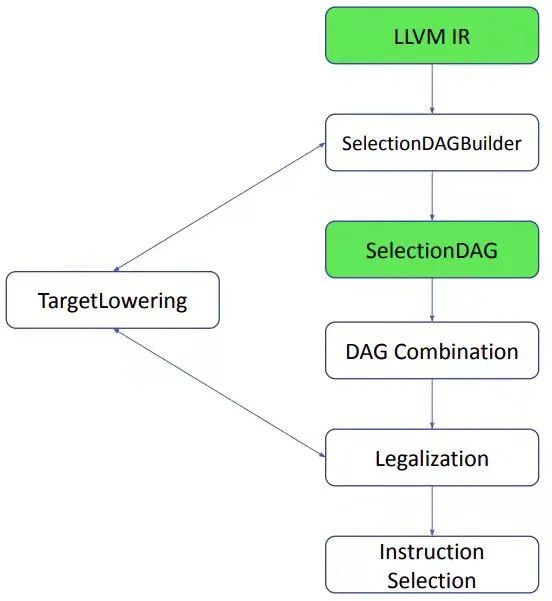
SDNode 的合法化涉及类型和操作的合法化。首先介绍操作的合法化。
目标平台一般不可能为所有支持的数据提供 IR 中所具有的全部指令,x86 上没有条件赋值(conditional moves) 指令,PowerPC 也不支持从一个 16-bit 的内存上以符号扩展的方式读取整数。因此,合法化阶段要将这些不支持的指令按三种方式转换成平台支持的操作:
1. 扩展(Expansion),用一组操作来模拟一条操作;
2. 提升(promotion),将数据转换成更大的类型来支持操作;
3. 定制(Custom),通过目标平台相关的 Hook 实现合法化。
下图以 x86 除法指令为例说明操作的合法化。LLVM IR 的 SDIV 只计算商,而 x86 除法指令计算得到商和余数,分别保存在两个寄存器中。因为指令选择会区分 SDIVREM 和 SDIV,因此当目标平台不支持 SDIV 时需要在合法化阶段将 SDIV 扩展到 SDIVREM 指令。
图 5
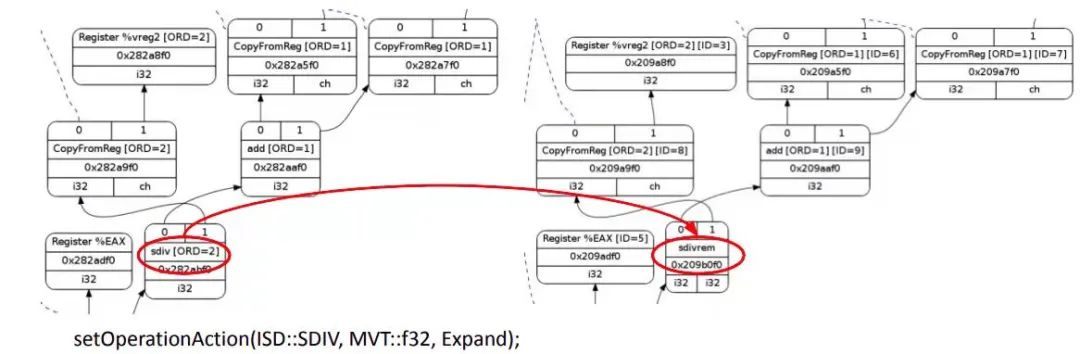
目标平台相关的信息通过 TargetLowering 接口传递给 SelectionDAG。目标设备会实现这个接口以描述如何将 LLVM IR 指令用合法的 SelectionDAG 操作实现。在 x86 的 TargetLowering 构造函数中会通过 “expanded” 这个 label 来标识。当 SelectionDAGLegalize::LegalizeOp 看到 SDIV 节点的 Expand 标志会用 SDIVREM 替换。类似的,目标平台相关的合并方法会识别一组节点组合的模式,并决定是否合并某些节点组合以提高指令选择质量。
类型合法化 pass 保证后续的指令选择只需要处理合法数据类型。合法数据类型是目标平台原生支持的数据类型,例如,目标平台的 td 文件中会定义每一种数据类型关联的寄存器类。例如:
def FPRegs : RegisterClass<“SP”, [f32], 32, (sequence “F%u”, 0, 31)>;这里定义了一组 32 个从 F0-F31 单精度浮点类型的寄存器。
def DFPRegs : RegisterClass<“SP”, [f64], 64, (add D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15)>;定义了一组 16 个从 D0-D15 双精度浮点类型的寄存器。
如果平台的 td 文件的寄存器类定义没有相应的数据类型,那对平台来说就是非法数据类型。非法的类型必须被删除或做相应处理。根据非法数据类型不同,处理方式分为两种情况:
第一种是标量。标量可以被 promoted(将较小的类型转成较大的类型,比如平台只支持 i32,那么 i1/i8/i16 都要提升到 i32), expanded(将较大的类型拆分成多个小的类型,如果目标只支持 i32,加法的 i64 操作数就是非法的。这种情况下,类型合法化通过 integer expansion 将一个 i64 操作数分解成 2 个 i32 操作数,并产生相应的节点);
第二种是矢量。LLVM IR 中有目标平台无法支持的矢量,LLVM 也会有两种转换方案, 加宽(widening) ,即将大 vector 拆分成多个可以被平台支持的小 vector,不足一个 vector 的部分补齐成一个 vector;以及 标量化(scalarizing),即在不支持 SIMD 指令的平台上,将矢量拆成多个标量进行运算。
目标平台也可以实现自己的类型合法化方法。类型合法化方法会运行两次,一次是在第一次 DAG Combine 之后,另一次是在矢量合法化之后。无论怎样,最终都要保证转换后的指令与原始的 IR 在行为上完全一致。
在做合法化时,还有其它可能的情况要考虑。比如,某种目标平台寄存器类支持某种向量类型,但某个特定的操作不支持这个向量类型。举个例子,x86 支持 v4i32 类型,但没有 x86 指令支持 v4i32 类型的 ISD::OR 操作,只支持 v2i64。这样,向量合法化 pass 就要 promote 使用 v2i64 类型。
DAG Combine pass 是将一组节点用更简单结构的节点代替。比如一组节点表示 (add (Register X), (constant 0)) 将寄存器 X 中的值和常数 0 相加,这种情况可以简化成 (Register X),和常数 0 相加无效,被优化掉了。
setTargetDAGCombine() 方法表示哪些节点可以被组合,例如:
setTargetDAGCombine(ISD::ADD);
setTargetDAGCombine(ISD::AND);
setTargetDAGCombine(ISD::FADD);Combine pass 在 legalization 后执行,可以最小化 SelectionDAG 的冗余节点。
Instruction Lowering
SelectionDAG 中已经有和目标相关的节点。为什么会这样?为了理解这个问题,首先看图 1。这里面包括了 Instruction Selection 之前的所有步骤,以 LLVM IR 起始。首先,SelectionDAGBuilder 遍历 LLVM IR 中的每一个 basic block,生成 SelectionDAG。在这个过程中,某些指令,如 call 和 ret 已经需要目标相关信息。比如如何传递调用参数,如何从函数返回。
为了解决这个问题,TargetLowering 类中的算法会在这里被首次使用。不同目标的 backend 要实现 TargetLowering 抽象接口。只有一小部分节点会在这里转成目标相关节点,大部分节点都在 Instruction Selection 中在 pattern match 后被替换成机器指令。
Instruction Selection
指令选择是 backend 中的一个重要阶段。从耗时方面来说,指令选择占用了 backend 总耗时的一半。指令选择通过节点模式匹配完成 DAG 到 DAG 的转换,将 SelectionDAG 节点转换成表示目标指令的节点。这一阶段的输入是经过合法化的 SelectionDAG,如下图所示。
图 6
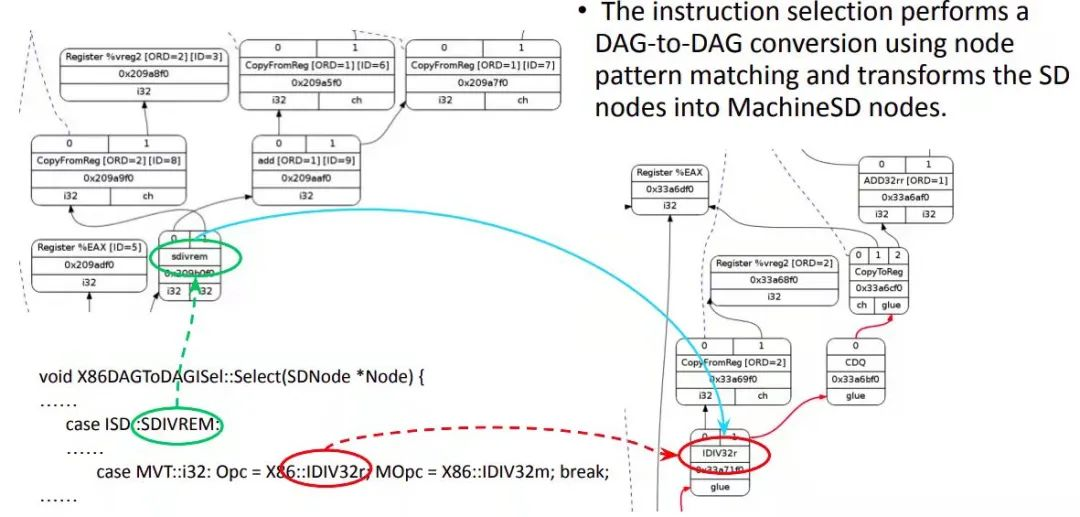
LLVM 的指令选择需要 tablegen 辅助来产生一种基于表的指令选择机制。目标平台的 backend 可以在 SelectionDAGISel::Select 方法中实现定制代码手工处理某些指令。其它指令通过 SelectCode 由默认的指令选择过程处理。例如在 x86 backend 中,对于经过合法化的 SDIVREM 操作就是手动方法做指令选择的。Select 方法的输入 SDNode 节点如果是 SDIVREM,会选择对应的 x86 指令 opcode,也就是 IDIV32r,并生成一个 MachineSD 节点。MachineSD 节点是 SDNode 的子集,其中的内容是平台机器指令,但仍然以 DAG node 的形式表示。其中 CopyToReg, CopyFromReg 和 Register 节点在寄存器分配阶段之前保持不变。有三种类型的指令表达会在同一个 DAG 中共存:一般 LLVM ISD 节点,如 ISD::ADD;平台相关 ISD 节点,如 X86ISD::RET_FLAG;和平台指令,如 X86::ADD32ri8.
在 Select 方法最后会调用 Selectcode 方法,如下图所示。这个方法是 tablegen 为目标平台生成的。主要的作用就是将 ISD 和平台 ISD 映射到机器指令节点。这种映射通过 Matcher table 实现。
图 7

Instruction Scheduling
指令选择完成后的 MachineDAG 内容虽然是机器指令,但仍然是以 DAG 形式存在,CPU/GPU 不能执行 DAG,只能执行指令的线性序列。寄存器分配前的指令调度的目的就是通过给 DAG 节点指定执行顺序将 DAG 线性化。最简单的办法就是将 DAG 按拓扑结构排序,但 LLVM backend 用更智能的方法调度指令使其运行效率更高。
调度器会调用 InstrEmitter::EmitMachineNode 发射一系列指令到 MachineBasicBlock,指令的形式是 MachineInstr(MI),DAG 表示形式不再使用,可以销毁。指令调度会根据性能需要做优化,特别是考虑寄存器 footprint。
图 8

Register Allocation
经过指令选择阶段产生的代码是 SSA 形式的,即静态单赋值。这些代码假定可以使用无限多的虚拟寄存器。这当然是不可能的。因此接下来要执行寄存器分配,将无限的虚拟寄存器替换成有限的物理寄存器。如果物理寄存器数量不够用,虚拟寄存器就会被 assing 到内存,也就是 spill slot。但也有例外,比如在 x86 的除法指令中,输入要保存在 EDX 和 EAX 寄存器中。指令选择阶段就已经知道这个限制,因此在那个时候,也就是 select 方法中就会为除法指令分配物理寄存器而不必等到寄存器分配阶段。
寄存器分配过程依赖几个 pass 的分析结果,包括 Register coalescer 和 virtual register rewrite,如下图所示。
图 9

由于二地址转换过程中生成了 copy 指令,从而引入了新的虚拟寄存器,这对后续的物理寄存器分配带来了压力。由于 copy 指令连接的两个虚拟寄存器的值相同,因此,在某些情况下可以合并 这些虚拟寄存器的生命期(live range),这个过程叫做合并(coalesce)。
Coalescer 的目的主要是消除冗余的 copy 指令,在 RegisterCoalescer 类中实现,这是一个 machine function pass。Machine function pass 是按 function 为单位作用在机器指令而不是 IR 指令上。
在 coalescing 时,joinAllIntervals 方法遍历 copy 操作列表,joinCopy 方法从 copy 机器指令中生成 Coalescerpair,并将 copy 合并。
Interval 是程序的一对起点和终点。从起点开始,某个值被产生并在被某个临时位置持有,一直到这个值被使用和销毁。下面分析在 bc 程序上运行 Coalescer 情况,如下图所示。
图 10

其中的序号 0B,16B… 是每条 MI 的序号,也称为 slot index,每个序号对应一个 live range slot。字母 B 对应 Block,用于 live range 的进入 / 离开一个 basic block 的边界。在这个例子中,index 都带 B,因为这是默认的 slot。不同的 slot,字母 r,会出现在 interval 中,表示寄存器,用于标号一个普通的寄存器 use/def slot。
从示例中的指令可以看出,%vreg0,%vreg1,%vreg2,%vreg3 是需要分配物理寄存器的虚拟寄存器。因此在这段代码中会用掉 4 个物理寄存器,另外还有两个 & I0 和 & I1。这两个是已经使用的物理寄存器,因为有遵守 ABI 调用规则。需要这些物理寄存器传递函数参数。
在 coalescing 之前会运行活动变量(live variable)分析 pass,因此实例代码中会有活动变量信息,显示每个寄存器在哪个时刻被定义和销毁。INTERVALS 之后的信息就是活动变量分析结果,MACHINEINSTRS 之后的信息是机器指令。活动变量信息对我们分析寄存器的相互影响很有用,如果在同一时间有几个虚拟寄存器存活,就需要分配不同的物理寄存器。
前面提到,coalescing 只是寻找寄存器 copy。在寄存器到寄存器的 copy 中,Coalescer 会尝试将源寄存器的 interval 和目的寄存器的 interval 连起来,使源和目的寄存器公用一个物理寄存器,这样就可以减少一个 copy 指令,16B-32B 就是这种情况。Coalescer 需要知道每个虚拟寄存器存活的 interval 以便知道应该将哪些 interval 合并。例如,从示例中可以看到,虚拟寄存器 %vreg0 的 interval 是 [32r:48r:0)。这表示 %vreg0 在 32 定义,在 64 被销毁。48 后的 0 是一个代码,表示第一次定义这个 interval 的地方。0 的含义在 0@32r 中表示,说明 0 就在 32r,其实我们已经知道这个含义了。但如果 interval 在后面被分裂了,这个定义可以用来跟踪 interval 的原始定义。
从示例中的 interval 可以发现,%I0 的 interval 是 [0B, 32r : 0],%vreg0 的 interval 是[32r , 48r : 0]。在 32 处有一个 copy 指令将 %I0 copy 到 %vreg0。这是就可以做 coalesce,将[0B, 32r : 0] [32r , 48r : 0] 这两个 interval 合并,并为 %I0 和 %vreg0 分配同一个物理寄存器,过程如下图所示。但遗憾的是,物理寄存器(例如 %I0)的 interval 必须被保留,也就是物理寄存器不能被分配到其它的 live range 存活范围。所以 Coalescer 会放弃这个机会,因为担心将 %I0 分配给整个 range 可能会对整体运行性能有影响,所以让后续的寄存器分配阶段来决定。
图 11
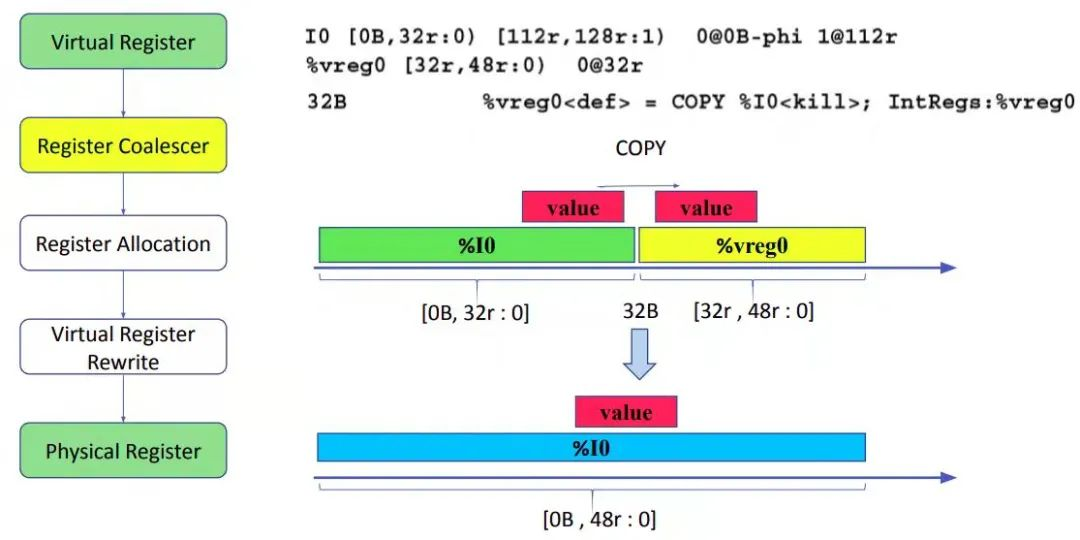
寄存器分配 pass 为每个虚拟寄存器分配物理寄存器后,VirtRegMap 会保存寄存器分配结果,实际是一张从虚拟到物理寄存器的映射表,如下图所示。接下来,虚拟寄存器 rewrite pass 要清除代码。理论上,rewrite pass 只需要把 MIR 中的虚拟寄存器替换成分配到的物理寄存器即可。虚拟寄存器 rewrite pass 会根据映射表将指令中的虚拟寄存器替换成物理寄存器,并删除相同寄存器之间的 copy 操作。所以,coalesce 不能删除的 copy 指令,寄存器分配可以通过给两段 live range 分配相同的物理寄存器,将冗余 copy 操作删除。
图 12

调用约定
调用约定定义描述了怎样向函数传值,以及如何从函数返回值。参数传递方式和目标平台高度相关。td 格式文件中定义的调用约定由一系列条件和预定义 action 组成。为了支持平台特定的调用约定,在 <target>CallingConv.td 定义了目标平台返回值调用约定和基本 C 调用约定,文件中使用 CCIfType 和 CCAssignToReg 等接口指定:
1. - 函数参数分配顺序
2. 函数参数和返回值是放在寄存器中还是放在 stack
3. 使用哪个寄存器
4. caller 或 callee 是否对栈回溯
从下图的例子可以看出 CCIfType 和 CCAssignToReg 接口的用法。如果 CCIfType 预测为真,也就是说,如果当前参数类型是 f32 或 i32,就会执行 CCAssignToReg 这个动作 action,也就是将参数值赋值给 I0-I5 的第一个可用寄存器。
图 13

其中,RetCC_Sparc32 指明了对某种标量返回类型应该用哪个寄存器。例如,单精度浮点返回到 F0,双精度浮点返回到 D0,32 位整型返回到 I0/I1。CC_Sparc32 还用到了 CCAssignToStack,这个 action 会以指定的大小和对齐方式将值赋给 stack slot。在这个例子中,第一个参数 4 表示 slot 的大小为 4byte,第二个参数 4 表示 stack 是 4 字节对齐。如果参数为 0,则沿用 ABI 中的定义。
函数参数会首先尝试放入 I0-I5 中的可用寄存器。如果 I0-I5 全都被之前的函数调用占用,就会采用 stack model 的调用约定。将函数参数值放入一个 4 字节大小、4 字节对齐的 slot。
还有一种比较常用的接口是 CCDelegateTo,该接口用于查找特定的子调用约定。例子中,当前函数参数值赋值给 ST0/1 后,就会执行 RetCC_X86Common。CCDelegateTo 经过 tblgen 处理后会变成函数调用。CCIfCC 接口用于将参数 1 中给定的名称与当前调用约定匹配。如果参数 1 的名称与当前调用约定相同,参数 2 指定的 action 会被执行。例子中,如果正在使用 Fast CallingConv( “CallingConv::Fast”),RetCC_X86_32_Fast 这个 action 就会被执行。
def RetCC_X86_32_C : CallingConv<[
CCIfType<[f32],
CCAssignToReg<[ST0, ST1]>>,
CCIfType<[f64],
CCAssignToReg<[ST0, ST1]>>,
CCDelegateTo<RetCC_X86Common>
]>;
def RetCC_X86_32 : CallingConv<[
CCIfCC<"CallingConv::Fast",
CCDelegateTo<RetCC_X86_32_Fast>>,
CCIfCC<"CallingConv::X86_SSECall",
CCDelegateTo<RetCC_X86_32_SSE>>,
CCDelegateTo<RetCC_X86_32_C>
]>;Code Emission
在介绍 code emission 之前首先介绍 MC framework。MC framework 的主要作用是对 function 和指令做底层处理。和其它后端模块相比,MC framework 设计的目的是用来辅助产生基于 LLVM 的汇编器和反汇编器。之前的 NVPTX backend 没有集成的汇编器,编译过程只能进行到发射 PTX 为止,产生 PTX 作为输出,然后依赖外部工具,比如 PTXAS 完成其余的编译步骤,如 Register Allocation 和 Code Emission。在 Code Emission 的早期阶段会用机器码指令(MCInstr)取代机器指令(MachineInstr)。和 MI 相比,MCInst 携带的程序信息较少。
Code Emission 阶段发生在所有 post-register allocation 之后。Code Emission 在 Asmprinter 这个 pass 中开始。下图是从 MI 指令到 MCInstr,再到汇编或二进制指令要经过的步骤:
图 14
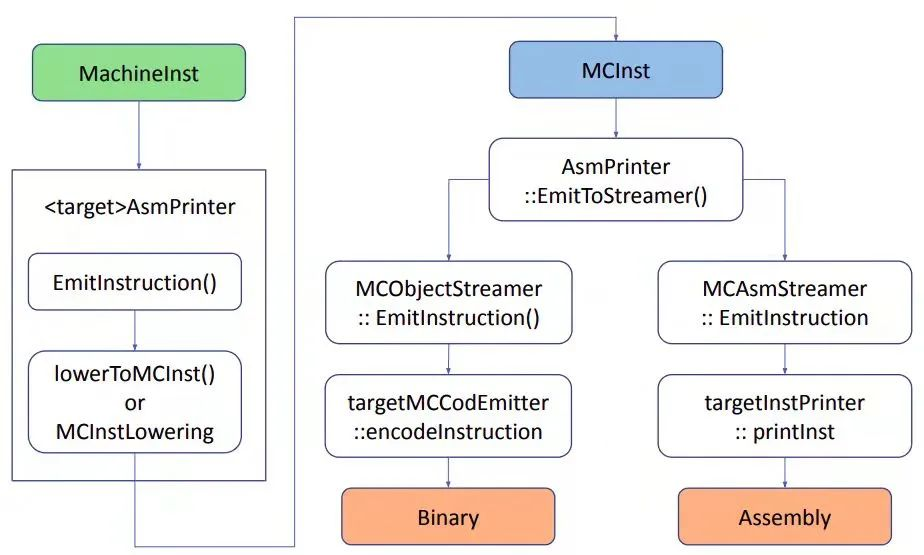
1. AsmPrinter 是一个 machine function pass。<br />AsmPrinter 首先发射 function header,然后遍历所有基本块,一次分发一条 MI 指令到 EmitInstruction() 方法做后续处理。自定义 backend 都会提供一个 AsmPrinter 子类重载这个方法。
2. 目标设备的 EmitInstruction() 收到 MI 指令输入后通过 MCInstLowering 接口将其转换为 MCInst 实例。自定义 backend 会提供 MCInstLowering 接口子类,并由其中的定制代码产生 MCInst 实例。
3. 此时有两个选项:发射汇编或二进制指令。MCStreamer 类处理 MCInst 指令流,通过两种类 MCAsmStreamer 和 MCObjectStreamer 将其发射到选定的输出。MCAsmStreamer 子类将 MCInst 转换为汇编指令,MCObjectStreamer 子类将 MCInst 转换为二进制指令。
4. 如果生成汇编代码,MCAsmStreamer::EmitInstruction() 被调用,并使用自定义 backend 提供的 MCInstPrinter subclass 将汇编指令打印到文件中。
5. 如果生成二进制指令,MCObjectStreamer::EmitInstruction() 被调用 LLVM object code assembler,并使用自定义 backend 提供的 MCCodeEmitter::EncodeInstruction() 函数,生成二进制代码。
参考文献
【1】https://www.ibm.com/developerworks/cn/linux/l-powasm4.html
【2】LLVM Essentials
【3】LLVM Cookbook
作者简介: Frank Wang,北京理工大学 工学博士,曾在MTK、Sony等公司从事软件研发管理工作,目前在美国硅谷某AI芯片初创公司从事编译器和算子库开发。