


OpenMP优化调研系列文章(4)
发表于 2022/12/26
0
LLVM对OpenMP实现的优化[1]
1. Parallel region merged with parallel region at <location>. [OMP150]
这个优化让一个并行区域与其他区域合并成了一个单一的并行区域,以减少fork-join开销。
void foo() {
#pragma omp parallel
parallel_work();
sequential_work();
#pragma omp parallel
parallel_work();
}$ clang++ -fopenmp -O2 -Rpass=openmp-opt -mllvm -openmp-opt-enable-merging omp150.cpp
omp150.cpp:2:1: remark: Parallel region merged with parallel region at merge.cpp:7:1. [OMP150]
#pragma omp parallel
^2. Removing parallel region with no side-effects. [OMP160]
这个优化是删除没有任何副作用的并行区域。判断依据是如果并行区域内的代码没有将任何结果写入并行区域外代码可见的内存。这种优化是必要的,因为并行区域和串行区域之间的barrier通常会阻止死代码的消除来完全移除并行区域,仍会有fork-join的开销。
void foo() {
#pragma omp parallel
{ }
#pragma omp parallel
{ int x = 1; }
}$ clang++ -fopenmp -O2 -Rpass=openmp-opt omp160.cpp
omp160.cpp:4:1: remark: Removing parallel region with no side-effects. [OMP160] [-Rpass=openmp-opt]
#pragma omp parallel
^
delete.cpp:2:1: remark: Removing parallel region with no side-effects. [OMP160] [-Rpass=openmp-opt]
#pragma omp parallel
^
^Optimizing Barrier Synchronization on ARMv8 Many-Core Architectures[2]
一个barrier同步通常包括了三个阶段:首先是到达阶段,在这个阶段所有的线程到达barrier。线程通过修改一个或者多个共享变量发出到达信号。然后线程进入通知阶段,最后到达的线程通知其他所有线程同步已完成。此操作通常修改线程之间的共享标志变量来完成。在最后的初始化阶段,所有标志变量被重新设置以重用。
这篇论文介绍了几种具有代表性的barrier实现算法:
1. Sense
sense-reversing集中式barrier是一种集中式的实现。到达阶段,每个线程在进入barrier时都会原子地递减一个共享变量(计数器)以宣布它的到达。计数器的初始值是线程数P。当它的值变成0时,意味着所有线程都已到达barrier。该算法使用一个线程本地变量和一个全局变量来执行唤醒过程。本地变量被初始化为全局变量的相反值(例如,如果全局变量被初始化为1,本地变量被初始化为0,反之亦然)。当每个线程的值与全局变量的值不同时,就在其本地自旋等待释放。最后到达的线程通过反转全局变量来通知其他线程。然后,所有的线程在离开barrier进行下一次同步之前,都会反转它们的本地变量。这种全局唤醒方案被广泛用于实现通知阶段。GCC OpenMP库采用了这种算法。
2. Tree-based algorithms
在集中式barrier中,所有线程都在写和读计数器的同一内存位置,导致内存访问的热点问题。这在互连网络中引起了内存竞争,导致可扩展性差。为了缓解竞争问题,研究人员提出了几种基于树的同步算法。
(1)Software combined tree barrier
构建一棵有多个节点的树,将并行的线程分为几个组,组内的线程共享一个计数器。但是跨线程组的计数器存储在不同的内存位置中,避免了单一的热点。
(2)MCS tree barrier
该算法在到达阶段构造一个P节点树。每个线程都会被分配为树节点而不是组合树中的叶子节点。
一个扇入为4的组合树和MCS的树结构如下图所示:
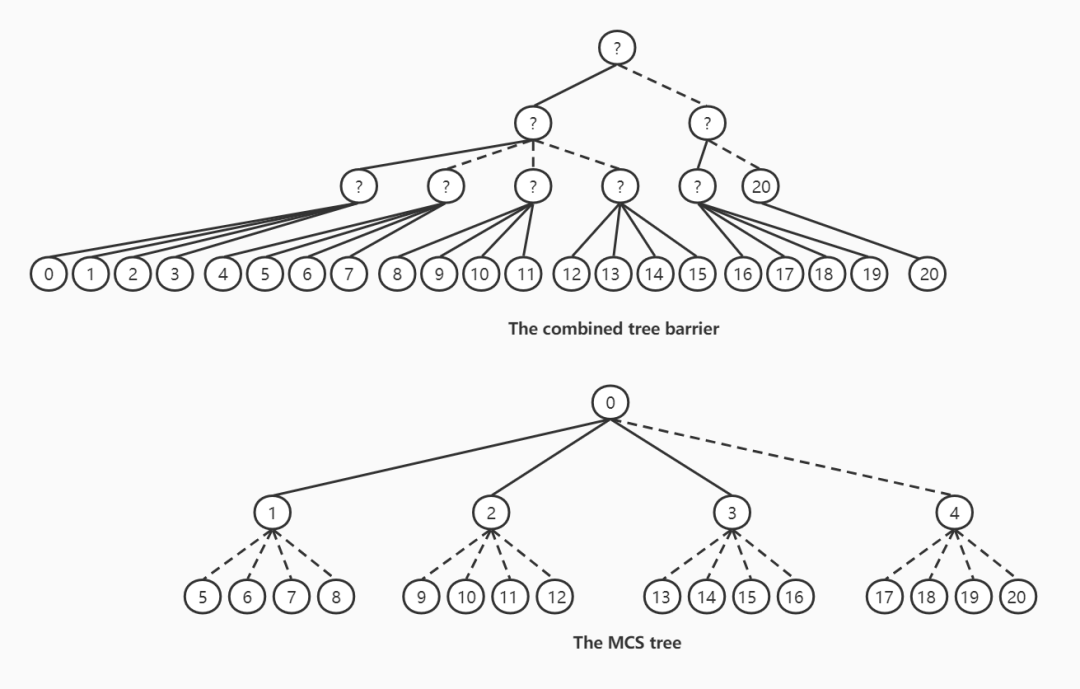
用20个线程为例,实线表示处理器核心内的操作,虚线表示跨核心集群的操作。
(3)Tournament barrier
算法类似于锦标赛比赛,在每一轮中两个线程相互对抗。胜利者会一直等待失败者的到来,胜者还需在下一轮中继续对决。最后的胜者通知其它所有线程barrier的结束。本质上来说,锦标赛barrier可以被看作一个扇入为2的自底向上的竞态组合树。该算法在通知阶段使用全局唤醒。
(4)Static and dynamic f-way tournament barriers
基于锦标赛概念,f-way锦标赛barrier将成对同步转换为每轮使用f个线程的组同步,这样的分组可以缩短关键路径长度。该算法可以看作为扇入为f的树,f的值在不同的级别上可以不同,以保持同步树尽可能平衡。
3. 针对ARMv8 Many-Core Architectures的优化
论文作者基于STOUT(static and dynamic f-way tournament)算法进行优化。由于STOUR算法需要子线程设置与父线程的共享标志来表明到达,父线程需要不断轮询子线程的到达标志,以检查是否所有子线程都到达barrier。因此,子线程的个数(即扇入)和到达标志的字节数会严重影响barrier的性能,论文作者的优化就是在目标架构上找到这两个参数的最优设置。
论文作者还对一些在通知唤醒阶段采用二叉树唤醒法的芯片进行了优化。由于二叉树唤醒法会产生太多的远程读取,论文作者提出了一种NUMA感知树结构以进行优化。
二叉唤醒树结构和NUMA感知树结构如下图所示:
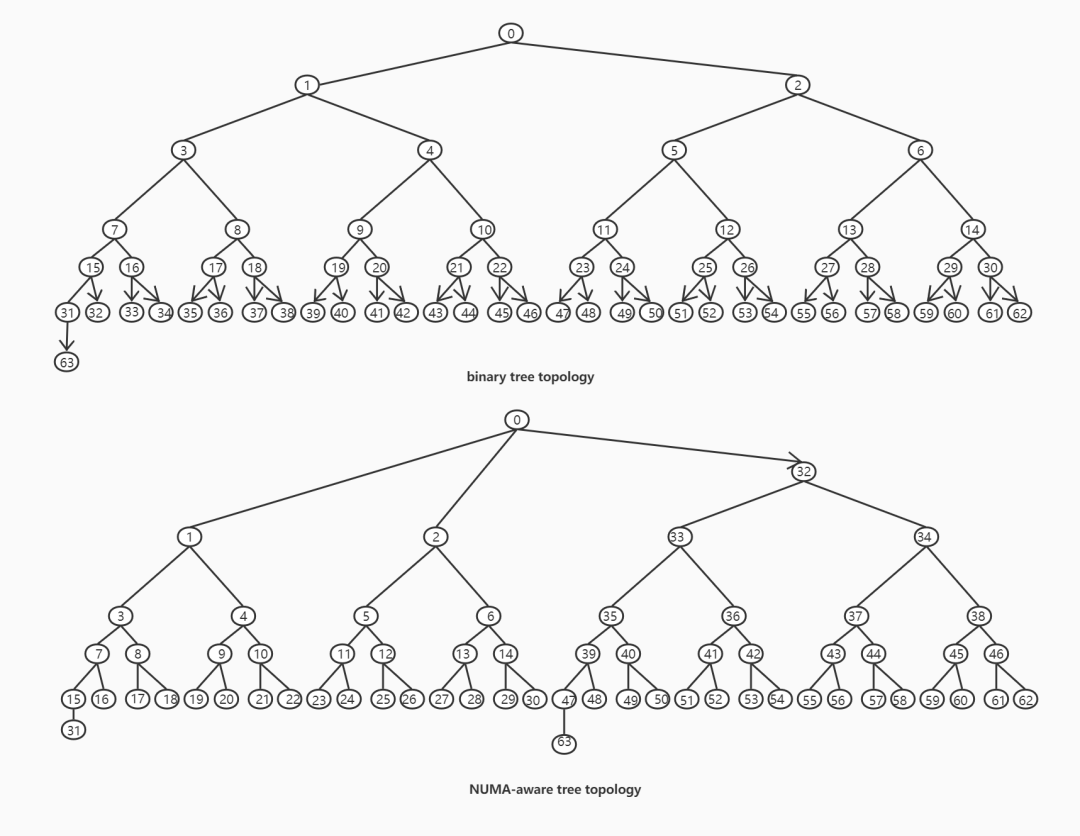
带箭头的线表示在ThunderX2芯片上的远程读取操作。
Vectorized Barrier and Reduction in LLVM OpenMP Runtime[3]
现如今,为了更有效地执行某些操作,微处理芯片上增加了矢量单元。barrier和reduction包含了应用许多数据项的操作。论文作者因此提出了用现代矢量单元加速同步和reduction的操作。论文作者提出的功能已在LLVM实现,可通过 −fopenmp_use_vbr 编译选项进行优化。
1. 向量化Barrier
矢量单元是为了处理连续的数据块。因此,论文作者为线程团队添加了一个线程间共享的数组,用于标记线程到达barrier。同样的数组也用于标记在处理完任务后对线程的释放。当共享标记数组为一个团队分配时,所有标记都被初始化为1。
实现代码如下:
gather阶段:
vec_array[thread_id] = 0;
if (master_thread) {
do {
tmp_vec[1 : VLEN] = 0;
for (i = 0; i < nThreads; i += VLEN) {
tmp_vec |= vector_load(&vec_array[ i ], VLEN);
}
} while ( tmp_vec) ;
}release阶段:
if (master_thread) {
vec_array[1 : nThreads] = 1;
} else {
while (!vec_array[thread_id]);
}在gather阶段,线程通过将共享标记数组自己的专属位置置0表示到达,团队中的线程需要在同步点等待所有线程都到达。因此,主线程连续加载共享线程的一部分(根据vec的长度),用临时变量按位或操作检查是否都到达。release阶段,主线程通过将所有线程的标志位置1来释放他们。
论文作者使用树模式进行barrier同步,分支因子可以使用环境变量设置,并且为每个树级别分配专用的共享数组。
2. 向量化Reduction
论文作者以一个例子介绍了原有的LLVM实现reduction操作 (下图参考[3] Fig. 2)。
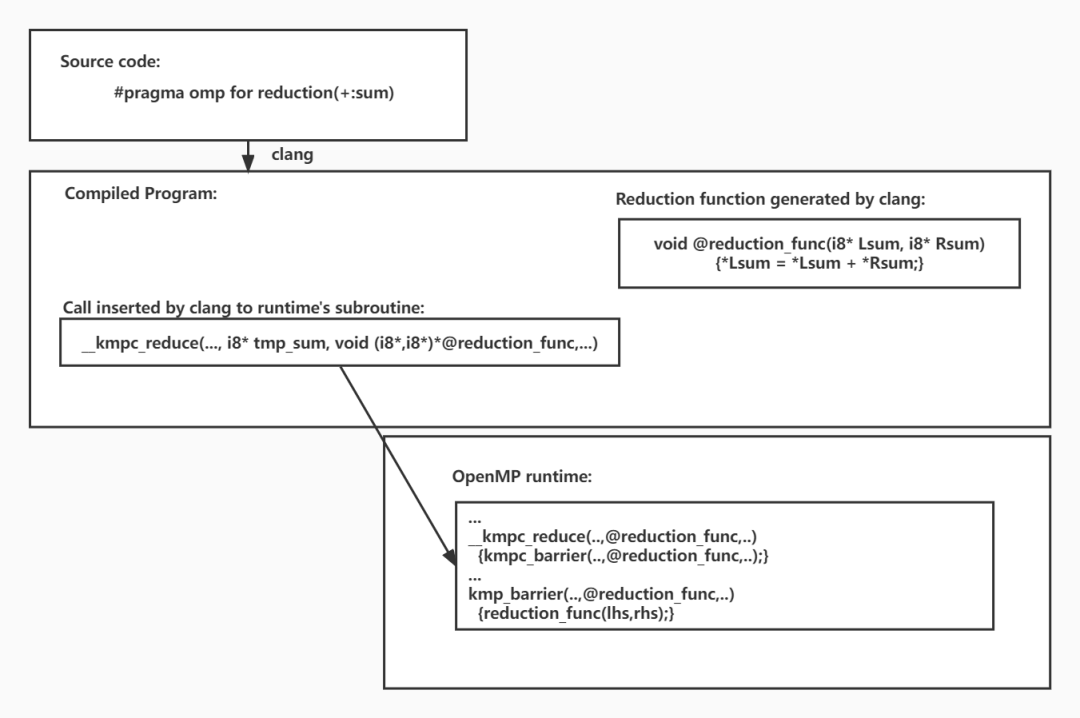
论文作者在OpenMP运行时为recution子句的变量创建了一个共享数组。相同的数组被重复使用于后续的reduction子句。在嵌入运行时reduction subroutine的barrier的gather阶段,每个线程的部分reduction结果被复制到共享reduction数组。然后主线程通过调用向量化的@reduction_func计算reduction结果。论文作者修改了向量化reduction subroutine __kmp_reduce的函数签名,添加了一个传递reduction的size传递给运行时,这个参数将会在之后被每个线程用来复制部分reduction结果到共享reduction数组中。
Vectorized Reduction函数的伪代码如下:
void @recution_func(i8* Lsum, i8* RedArr, nThreads) {
vec_gather[1 : VLEN] = 0;
for(int i = 0; i < nThreads; i += VLEN) {
vec_gather += Gather_load(&RedArr[i], VLEN, PaddingLength);
}
*Lsum = Vector.Reduce.Add(vec_gather);
}我们还对文献中的部分优化使用LLVM Flang编译器和classic-flang编译器进行了测试,测试结果请参考 https://gitee.com/src-openeuler/flang/pulls/22/files。
References
1. https://openmp.llvm.org/remarks/OptimizationRemarks.html
2. W. Gao, J. Fang, C. Huang, C. Xu and Z. Wang, "Optimizing Barrier Synchronization on ARMv8 Many-Core Architectures," 2021 IEEE International Conference on Cluster Computing (CLUSTER), 2021, pp. 542-552, doi: 10.1109/Cluster48925.2021.00044.
3. Farooqi, M.N., Pericàs, M. (2021). Vectorized Barrier and Reduction in LLVM OpenMP Runtime. In: McIntosh-Smith, S., de Supinski, B.R., Klinkenberg, J. (eds) OpenMP: Enabling Massive Node-Level Parallelism. IWOMP 2021. Lecture Notes in Computer Science(), vol 12870. Springer, Cham. https://doi.org/10.1007/978-3-030-85262-7_2
作者介绍

谢依晖
湖南大学硕士研究生在读,本科毕业于湖南大学计算机科学与技术专业