


案例分析 | g_mmpbsa软件移植毕昇编译器无法启动多线程
发表于 2022/12/02
0
背景介绍
自由能的计算在计算科学领域是一个非常重要的研究课题,所有物理、化学以及生物过程自发进行达到的程度都是由初态(反应物)与终态(产物)之间的自由能变化决定的。对在分子模拟领域, 准确计算结合自由能(binding free energy)仍然是一个挑战。g_mmpbsa 使用 MM-PBSA 方法计算结合能的分量,除了使用能量分解方案的熵项和每个残基对结合的能贡献,计算结合能的分量。
软件安装需要先安装 apbs 和 gromacs 两个依赖软件,然后安装 g_mmpbsa 软件,在华为云服务器x86架构16核32G内存下,GCC 编译场景,软件安装正常,运行官方用例选择数据1和数据13的组合,程序完成需要4分钟的时间,在运行过程中可以看到软件自动用了华为鲲鹏云服务的16核资源。
问题现象
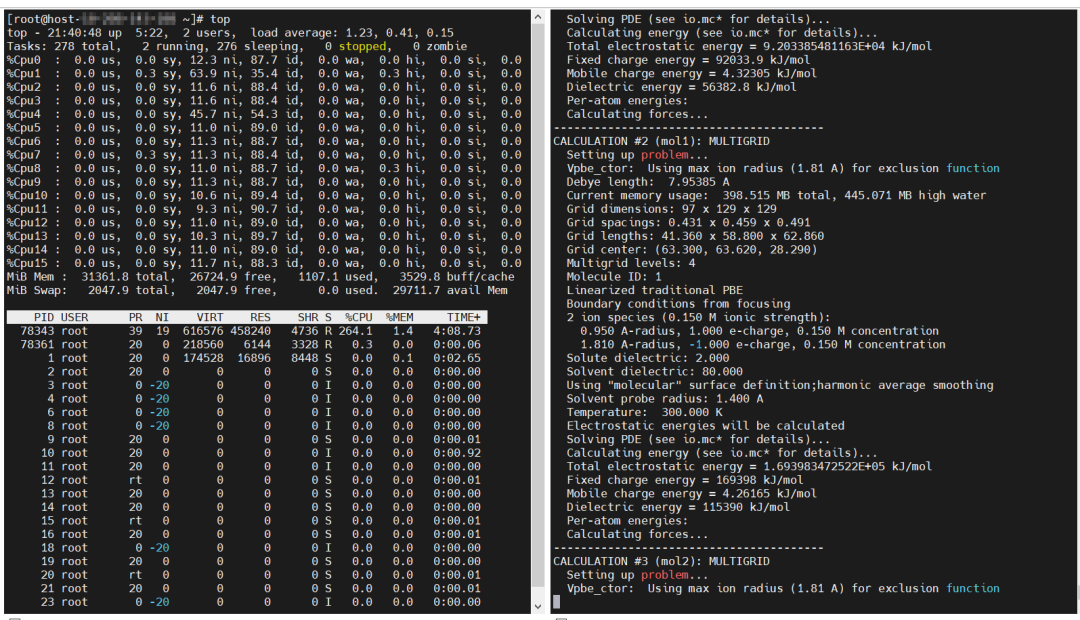
将 g_mmpbsa 软件移植到 ARM 架构的 TaiShan 服务器,操作系统是 OpenEuler 20.03(LTS-SP3),同样是16核CPU、32G内存的配置,如果使用 GCC 编译软件,软件能顺利运行,并正确跑完同样的用例,16核CPU都在运行,如下图所示。
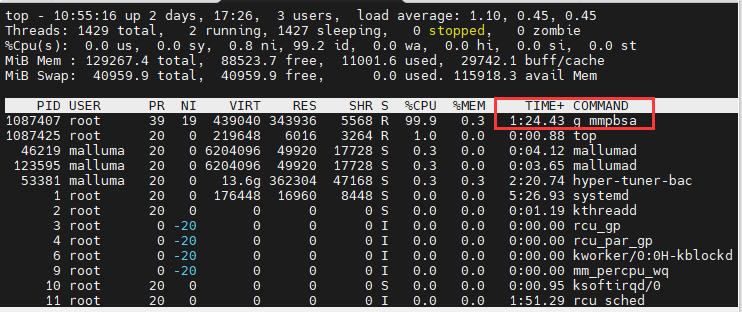
使用毕昇编译器对软件进行编译后,程序能正常运行,但是运行时间却要花40分钟左右,性能差别很大,并且在毕昇编译器编译后运行程序只有一个线程,CPU使用率都是低于100%,如下图所示。
分析解决
是什么原因导致了毕昇编译器编译出来的程序运行的时候没有自动运行多线程的呢?对比了 GCC 编译和毕昇编译的安装日志,发现毕昇编译的时候没有添加编译参数 -fopenmp,于是我们把编译参数进行了添加,如下所示:
sed -i "193c LIBS = -lm -pthread -lgmx -lgmxana -lmd -lfftw3w -ldl -lapbsmainroutines -lapbs -lapbsblas -lmaloc -lapbsgen -lz -fopenmp"但是添加以后,毕昇编译的过程中还是没有把 -fopenmp 参数带上。通过同毕昇编译器工程师共同探索后,发现是添加参数的位置不对,应该添加在 configure 的后面,如下所示:
./configure --prefix=$g_mmpbsaInstallpath/g_mmpbsa | CC=clang CXX=clang++ F77=flang CFLAGS="-O2 -fopenmp" CXXFLAGS="-O2 -fopenmp" FCFLAGS="-O2 -fopenmp"对应的 apbs 和 gromacs 两个依赖软件设置同样添加,完成以后,再用毕昇编译器编译软件,软件运行实现了多线程,但是程序运行时间还是30分钟左右,性能差别仍然较大。对比 TaiShan 服务器的 GCC 编译安装和毕昇编译的安装文件发现 apbs 编译的时候 -fopenmp 还是没有生效,如下图所示。

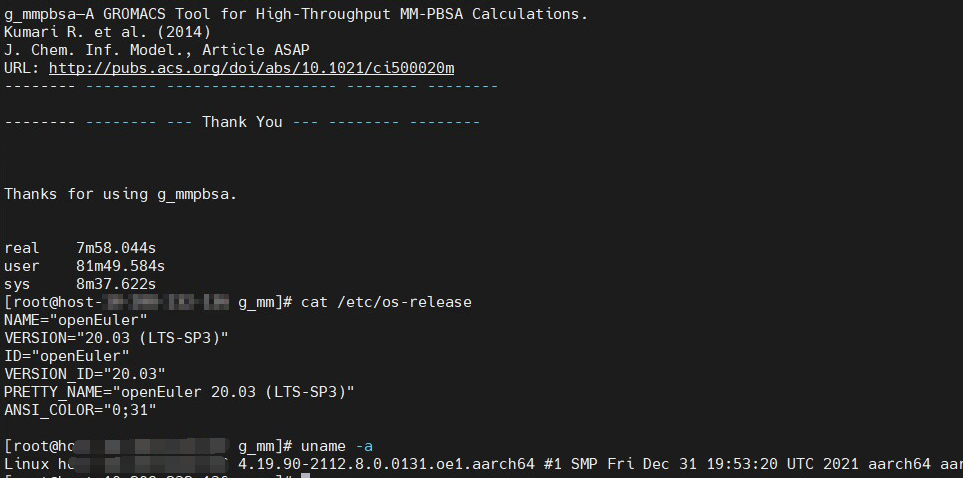
经反复修改测试,将 F77=flang 修改为 F77="flang –g –O2 -fopenmp" 以后,apbs 的多线程才生效,运行结果如下图所示。
案例总结
1. 多线程如果在应用中没有使能,可以检查构建配置,-fopenmp 选项是否已对所有模块使能。
2. 构建配置添加选项的常见方式:
(1)Makefile 或 configure 时添加 “CFLAGS=xxx”、 “CXXFLAGS=xxx”、 “FCFLAGS=xxx”。
(2)如果Makefile过于复杂,难以直接在参数上添加全局选项,可以直接在编译器参数上添加,例如 F77=“flang -fopenmp”。