


编译入门那些事儿(4):MLIR概述
发表于 2023/07/07
0
MLIR基本概念
MLIR(Multi-Level Intermediate Representaion,多级中间表示)是一种用来构建可重用和可扩展编译的新方法。MLIR的设计初衷是为了解决软件碎片化问题,改进异构硬件的编译,显著减少构建特定领域编译器的成本以及帮助连接现有的编译器。当前很多语言都拥有自己的IR:
Figure 1[1]
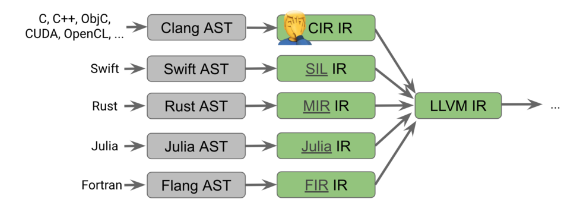
MLIR的实现原理是通过一种通用的架构来实现IR高层转换:
Figure 2[2]
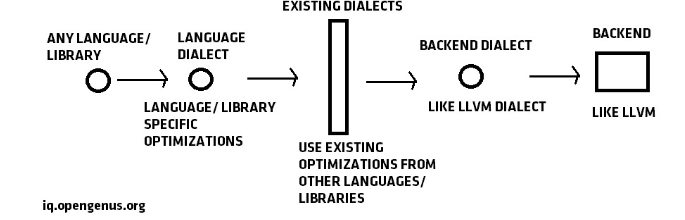
MLIR的核心组成部分包括dialect、operation、region等。
Figure 3
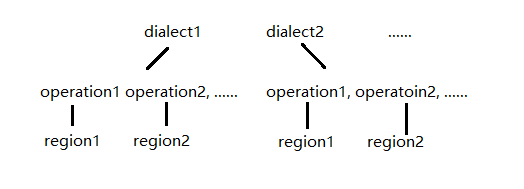
dialect可以粗略理解为一个class,operation则是class中封装的函数。例如,对于arith.constant,arith是dialect名称,constant是operation名称,涵义为:调用arith dialect中的constant operation(写法上类似于调用arith class中的constant成员函数)。通常,MLIR会将高层/高抽象化的dialect,转换成底层/低抽象化的dialect,最终生成LLVM IR。例如:dialect A -> dialect B -> ...... -> LLVM dialect -> LLVM IR。以下是一个arith dialect -> LLVM dialect -> LLVM IR的转换示例:
arith.mlir:
func.func @vector_ops(%arg0: vector<[4]xi32>) -> vector<[4]xi32> {
%0 = arith.constant dense<2> : vector<[4]xi32>
%1 = arith.addi %arg0, %0 : vector<[4]xi32>
return %1 : vector<[4]xi32>
}转换成LLVM dialect,结果如下:
arith_out.mlir:
module attributes {llvm.data_layout = ""} {
llvm.func @vector_ops(%arg0: vector<[4]xi32>) -> vector<[4]xi32> {
%0 = llvm.mlir.constant(dense<2> : vector<[4]xi32>) : vector<[4]xi32>
%1 = llvm.add %arg0, %0 : vector<[4]xi32>
llvm.return %1 : vector<[4]xi32>
}
}LLVM dialect转换成LLVM IR,结果如下:
arith.ll:
; ModuleID = 'LLVMDialectModule'
source_filename = "LLVMDialectModule"
declare ptr @malloc(i64)
declare void @free(ptr)
define <vscale x 4 x i32> @vector_ops(<vscale x 4 x i32> %0) {
%2 = add <vscale x 4 x i32> %0, shufflevector (<vscale x 4 x i32> insertelement (<vscale x 4 x i32> poison, i32 2, i64 0), <vscale x 4 x i32> poison, <vscale x 4 x i32> zeroinitializer)
ret <vscale x 4 x i32> %2
}
!llvm.module.flags = !{!0}
!0 = !{i32 2, !"Debug Info Version", i32 3}下面,我们会介绍一些MLIR的基本概念。
1. dialect
dialect主要由type、operations、interface、passes等构成。同时存在 ODS 和 DRR 两个重要的模块,这两个模块都是基于TableGen模块,ODS 模块用于定义operation,DRR 模块用于实现两个 dialect之间的conversion[3]。
2. operation
operation 是 dialect 的重要组成部分,是抽象和计算的核心单元,可以看成是dialect语义的基本元素。
%3 = "tosa.sub"(%2, %1) : (tensor<1xf16>, tensor<32x1x1x128xf16>) -> tensor<32x1x1x128xf16>上面的例子中,tosa.sub 中 sub 就是operation的名称,而它被定义在 tosa dialect 中,用于做tensor的减法运算。
3. region
region是嵌套在function当中的blocks的集合。在LLVM IR当中,function的主体是控制流图,控制流图由block组成;在MLIR当中,function以operation的形式出现,operation中含有一个或者多个region,region由block组成,而block中又含有operation[4]。
Figure 4[5]
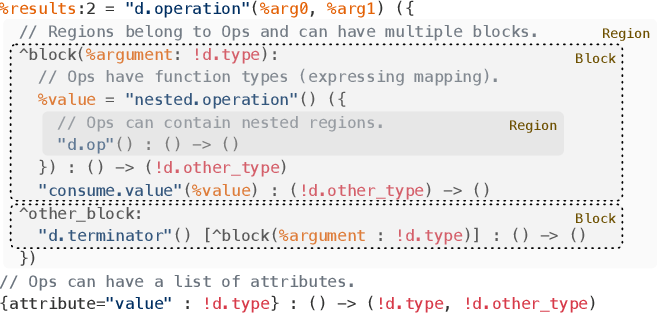
MLIR的dialect以及operation被定义在 .td 文件中,通过 tablegen 自动生成 .inc 文件。例如 mlir/include/mlir/Dialect/ArmSME/ArmSME.td 中定义的arm_sme dialect,通过tablegen生成 build/tools/mlir/include/mlir/Dialect/ArmSME/ArmSME.h.inc。
接下来我们会以SVE、SME为例简要介绍它们在MLIR中的实现方式,以及本身的概念。SVE和SME都是Arm架构下的新指令集,分别作用于加速向量计算和矩阵计算。在进行向量/矩阵的计算时,SVE和SME有自己独特的指令以及寄存器去完成这些工作并达到优化效果。新的指令意味着在LLVM IR中,SVE和SME有对应的intrinsic。MLIR可以通过定义dialect以及dialect conversion的方式,从高层dialect的op逐步lower最终生成SVE/SME对应的intrinsic,从而生成对应的LLVM IR。
SVE在MLIR中的实现
SME是基于SVE做的扩展,所以在了解SME之前,先简单介绍一下SVE。SVE和SME在MLIR当中都有自己的实现。SVE主要作用于向量计算,在后端拥有对应的intrinsic op之后,为了在MLIR中实现相关功能,我们需要:
(1)定义dialect,如arm_sve dialect、arm_sme dialect,之后为dialect添加相应的operation;
(2)定义该dialect中的operation向下lower成llvm dialect/intrinsic operation的转换;
(3)定义其它上层dialect到该dialect的转换,比如tosa dialect -> arm_sve dialect。
在完成上述步骤之后,便初步打通了高层dialect -> arm_sve dialect -> llvm dialect/intrinsic op -> LLVM IR的编译路径。
1. SVE的特性
SVE(Scalable Vector Extension)是Arm Aarch64架构下的下一代SIMD指令集,旨在加速高性能计算,SVE引入了很多新的架构特点[6],比如:
(1)可变矢量长度
(2)Predicate标注SVE向量寄存器中参与计算的部分
(3)聚集加载和分散存储
(4)横向操作
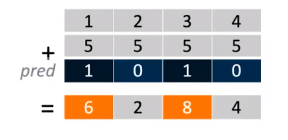
SVE中没有对于vector长度的定义,所以同样的二进制可以在不同向量长度的架构上面运行。SVE vector的长度为128bit到2048bit(128bit的倍数),具体长度根据runtime中寄存器的avaliability决定。在特定情况下,向量化性能会超过传统向量化方式,因为SVE可能会增加向量长度。虽然没有明确定义vector的长度,但是SVE可以在指令中动态获取硬件的向量长度,并在vector的loop中以此为增量。下图分别列举了标量、NEON和SVE在计算一个长度为40byte的向量时的处理方法:
Figure 5[7]

Predicate是一个vector,由0和1组成。需要的部分标注为1,不需要的部分标注为0。它的功能与bit mask类似,不过bit mask会计算整个vector,然后将不需要的部分丢弃;而Predicate则会关闭寄存器不需要的部分,只计算需要的部分。Predicate应用如下图所示:
Figure 6[7]
2. SVE的实现
MLIR可以将高层dialect lower至LLVM IR中的SVE intrinsic。由于SVE采用了单独的指令集和独特的实现方式,社区增加了arm_sve dialect,其中含有所有的SVE operation。例如:
%1 = arm_sve.masked.addi %0, %arg0, %cst : vector<[4]xi1>, vector<[4]xi32>这条operation代表arm_sve dialect中的masked addition operation。它的定义被写在 .td 文件中由TableGen进行生成。于是我们可以将所有SVE能够实现的计算定义为arm_sve dialect的各种operation。
之后我们需要定义每条operation到SVE instrinsic的lower方式(改写方式)。例如,上面的masked addition operation就会在转换成LLVM dialect时被lower成如下的SVE intrinsic:
%9 = "arm_sve.intr.add"(%8, %arg0, %0) : (vector<[4]xi1>, vector<[4]xi32>, vector<[4]xi32>) -> vector<[4]xi32>最终在LLVM IR中,这条intrinsic会被改写为如下形式:
%4 = call <vscale x 4 x i32> @llvm.aarch64.sve.add.nxv4i32(<vscale x 4 x i1> %3, <vscale x 4 x i32> %0, <vscale x 4 x i32> shufflevector (<vscale x 4 x i32> insertelement (<vscale x 4 x i32> poison, i32 2, i64 0), <vscale x 4 x i32> poison, <vscale x 4 x i32> zeroinitializer))这样,从arm_sve dialect到LLVM IR的通道就已经打通了。之后,我们需要实现从高层dialect到arm_sve dialect的lower。对于SVE来说,我们需要定义arith dialect到arm_sve dialect之间的转换。例如,刚才的 arm_sve.masked.addi 是由 arith.addi 转换形成的。由于 arm_sve.masked.addi 是带有mask的向量加法操作,我们需要在lower时添加对于mask的定义。
%1 = arith.addi %arg0, %0 : vector<[4]xi32>lower成arm_sve dialect如下所示:
%c4 = arith.constant 4 : index
%0 = vector.create_mask %c4 : vector<[4]xi1>
%1 = arm_sve.masked.addi %0, %arg0, %cst : vector<[4]xi1>, vector<[4]xi32>这样,从高层dialect -> arm_sve dialect -> LLVM IR的流程就已经完成了。
SME在MLIR中的实现
SME(Scalable Matrix Extension)在SVE基础之上,增加了对于矩阵的一些高效处理方法。它的原理是通过outerproduct(外积)计算矩阵乘法,从而减少load次数,达到优化的效果。在MLIR当中,可以通过与SVE相同的方式进行定义,即定义SME dialect,SME dialect中的op到LLVM dialect/LLVM intrinsic的lower,以及上层dialect(如vector dialect)到SME dialect的lower。
1. outerproduct of SVE vectors
普通矩阵乘法
Figure 7[8]
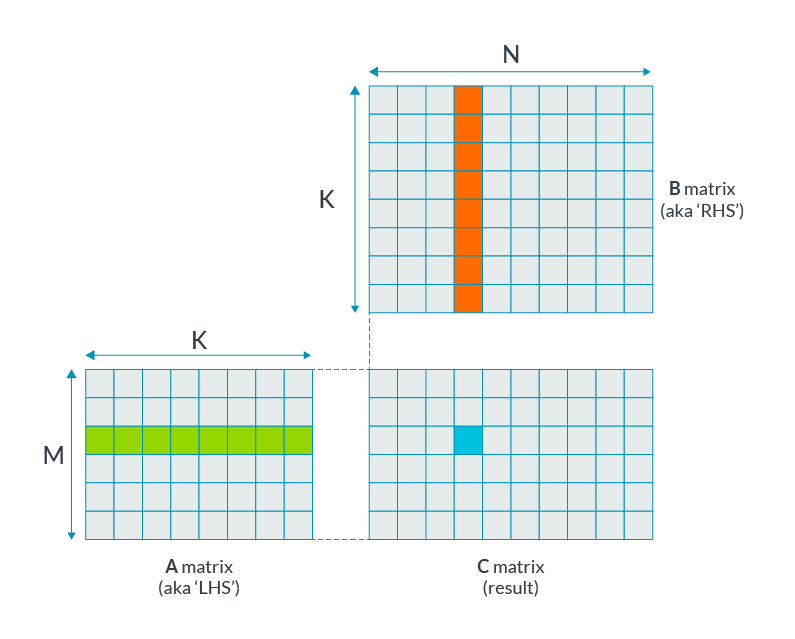
令A,B,C为4x4 f32矩阵,计算A * B = C的过程为:取A的一行,B的一列,点乘得到C中一个元素。
C(0, 0) = A(0, :) * B(:, 0)
C(0, 1) = A(0, :) * B(:, 1)
...
C(3, 3) = A(3, :) * B(:, 3)假如只有两个128bit向量寄存器,需要16次load操作。
outerproduct
Figure 8[8]
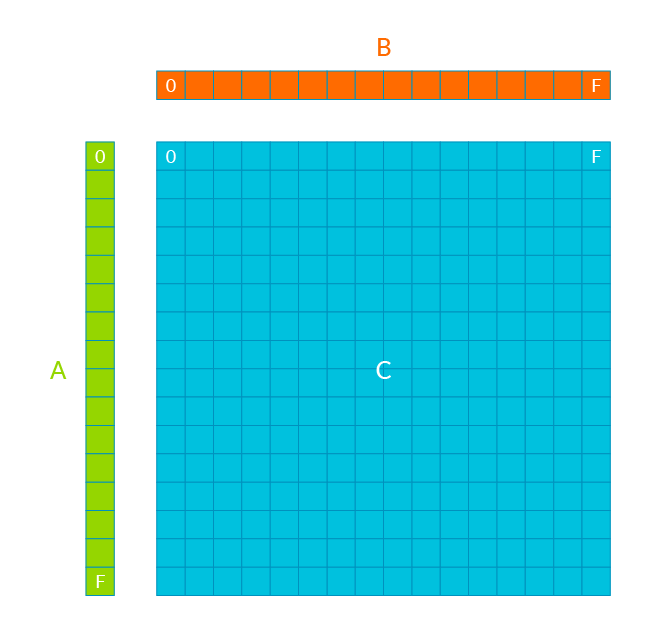
令A、B、C为4x4 f32矩阵,计算A * B = C的过程为:取A的一列,取B的一行,通过outerproduct计算出一个4x4的矩阵,然后累加到C上。
C = A(:, 0) * B(0, :)
C += A(:, 1) * B(1, :)
C += A(:, 2) * B(2, :)
C += A(:, 3) * B(3, :)假如只有两个128bit向量寄存器,需要8次load操作。
2. Streaming SVE Mode
在Streaming SVE Mode之下,SVE/SME允许“改变”原有的向量长度。新的向量长度叫做SVL(Streaming Vector Length)。它的长度不定,但必须为128bit ~ 2048bit中128bit的倍数。假如Streaming Vector Length为256bit:
SVL-B:SVL中byte数量 = 256 / 8 = 32
SVL-H:SVL中16bit数量 = 256 / 16 = 16
SVL-S:SVL中32bit数量 = 256 / 32 = 8
SVL-D:SVL中64bit数量 = 256 / 64 = 4
SVL-Q:SVL中128bit数量 = 256 / 128 = 2
...
3. SME ZA Storage
ZA Storage是SME独特的数据储存方式,是一个大小SVL-B * SVL-B byte的寄存器。例如:Streaming Vector Length为256bit,则SVL-B为256 / 8 = 32。ZA Storage大小为32 * 32 * 8 bit。下面是一些相关概念的定义:
(1)ZA Storage为一个寄存器,含有一个大小为32 x 32 byte的2d ZA Array。
(2)ZA Array的大小为32 x 32 byte。
(3)ZA Tile是ZA array的一部分,一个或多个ZA tile组成一个ZA array。
(4)ZA Slice是ZA tile中的一行或一列。
下图为一个ZA array,每个方格代表8 bit,大小为32 * 32 个8 bit。
Figure 9[[9]
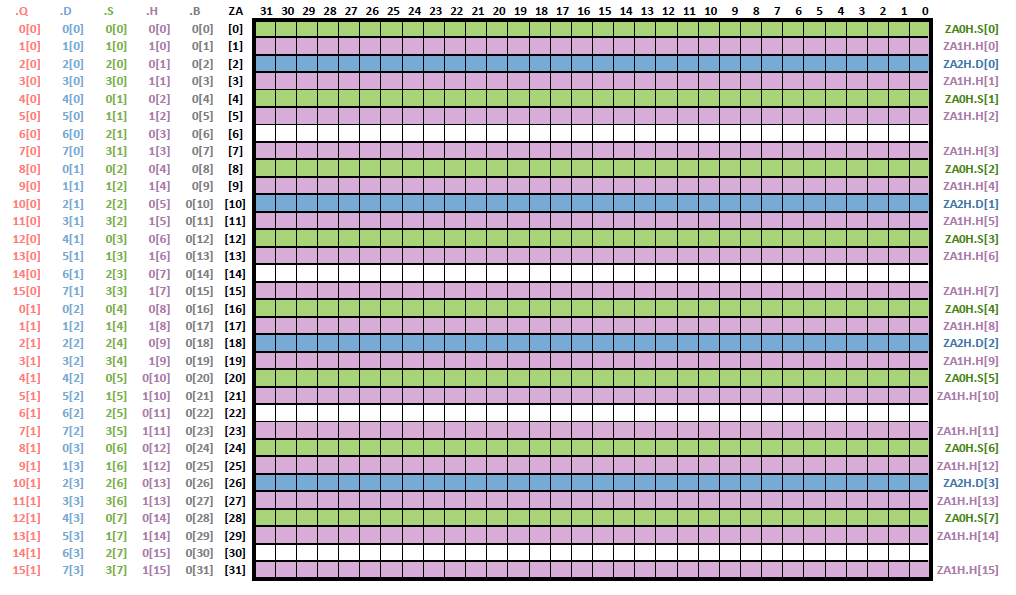
对于不同bandwidth的数据,ZA tile的数量、大小、表示方法也都不同。例如:
(1)对于8 bit数据:大小为SVL-B * SVL-B * 8 bit,即32 * 32 * 8 bit。一个ZA array中只有一个8 bit类的ZA tile,大小为32 * 32。其中:
ZA0B:整个ZA array。
(2)对于16 bit数据:大小:SVL-H * SVL-H * 16 bit,即16 * 16 * 16 bit。一个ZA array中有2个16 bit类的ZA tile,大小为16 * 32。其中:
a. ZA0H:ZA array的0,2,4,6 ...行;
b. ZA1H:ZA array的1,3,5,7 ...行。
(3)对于32 bit数据:大小:SVL-S * SVL-S * 32 bit,即8 * 8 * 32 bit。一个ZA array中有4个32 bit类的ZA tile,大小为8 * 32。其中:
a. ZA0S:ZA array的0,4,8,12 ...行;
b. ZA1S:ZA array的1,5,9,13 ...行;
c. ZA2S:ZA array的2,6,10,14 ...行;
d. ZA3S:ZA array的3,7,11,15 ...行。
以此类推。
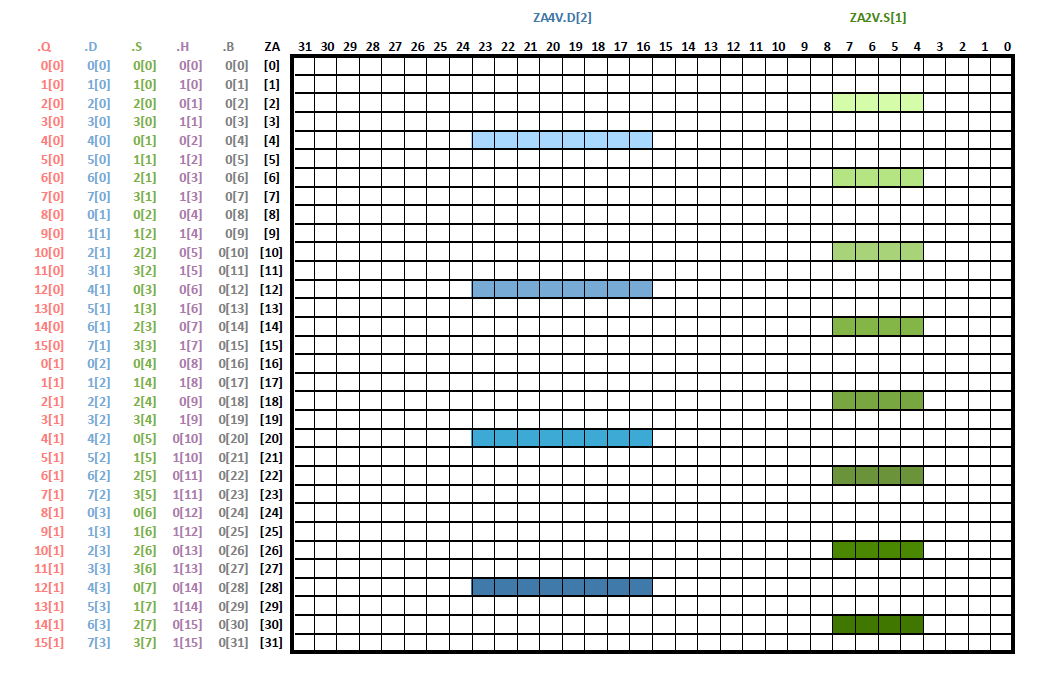
ZA Slice为ZA tile中的一行或一列,拥有特定表示方法,例如:ZA0H.S[2] 表示 ZA0S 这个tile中的第2行,H表示行(若是V则表示列),2表示行号(列号)。同理,ZA4V.D[2] 表示 ZA4D tile中的第二列,ZA2V.S[1] 表示ZA2Stile中的第一列,如下图所示:
Figure 10[9]
4. SME的实现
与SVE十分类似,我们同样去为SME定义自己的dialect。之后我们会在arm_sme dialect中添加相应的operation,并定义这些operation到arm_sme intrinsic的lower流程,以及从高层的vector dialect到arm_sme dialect的lower流程。例如SME的mopa operation如下所示:
arm_sme.mopa za0s, %pred.32, %pred.32, %1, %1 : vector<[4]xi1>, vector<[4]xi1>, vector<[4]xf32>, vector<[4]xf32>这条operation会对两个向量进行外积计算,并将结果累加到za0d所对应的ZA tile中。它会被lower成如下的SME intrinsic:
"arm_sme.intr.mopa"(%28, %27, %27, %arg0, %arg0) : (i32, vector<[4]xi1>, vector<[4]xi1>, vector<[4]xf32>, vector<[4]xf32>) -> ()转换成LLVM IR之后形式如下:
call void @llvm.aarch64.sme.mopa.nxv4f32(i32 0, <vscale x 4 x i1> %11, <vscale x 4 x i1> %11, <vscale x 4 x float> %0, <vscale x 4 x float> %0)参考文献
1. https://zhuanlan.zhihu.com/p/420729459
2. https://iq.opengenus.org/mlir-compiler-infrastructure/
4. https://www.youtube.com/watch?v=Y4SvqTtOIDk
5. https://arxiv.org/abs/2002.11054v2
6. https://zhuanlan.zhihu.com/p/189589184