


编译器安全专题 | 直线推测(SLS)的消减措施
发表于 2023/07/24
0
前言
侧信道攻击是一种基于硬件的攻击方式,具有高隐蔽性和高风险的特点,是目前计算机体系结构中无法绕过的一个安全问题。
关于什么是侧信道攻击,请参考 技术分享 | 幽灵攻击与编译器中的消减方法介绍。
本文不再对侧信道攻击基本概念展开介绍,主要讲述LLVM中对由straight-line speculation引起的侧信道攻击方式的一种消减措施的实现。
什么是直线推测
Arm将下面一些指令引起的处理器在控制流发生变化后的推测执行行为称为straight-line speculation(直线推测)[1]。
(1)异常生成指令(SVC、HVC、SMC、UNDEF、BRK)
(2)异常返回(ERET)
(3)无条件直接分支跳转(B、BL)
(4)无条件间接分支跳转(BR、BLR)
(5)函数返回(RET)
虽然无条件跳转分支总是会执行的,但是与条件跳转分支相同的一点是,它们的目标地址依旧需要通过分支预测单元(BPU)进行推测。当分支指令被执行时,分支预测器会预测跳转的目标地址以便它可以继续执行。那么,这也意味着无条件跳转分支也存在预测错误的情况[2]。
在乐观的情况下,BTB(Branch Target Buffer)或者RAS(Return Address Stack)可以正确给出目标地址。但如果BTB或者RAS中没有相应条目提供某个无条件跳转分支的目标地址,那么CPU就会线性取指,即根据内存中的指令序列的顺序推测执行下一条指令。
对于这些可以使控制流发生变化的指令,随着使用和研究的深入,由CPU推测执行机制带来的一些安全漏洞也逐渐浮出水面。主要是由于在推测执行机制下,错误预测执行的指令会在缓存中留下执行痕迹,从而导致攻击程序可以获得原本无法访问到的数据。
我们可以看一个Arm的白皮书中给出的例子:
...
...
ADRP x3, __foo
ADD x3, x3, :lo12:__foo
BLR x3 // x0 = __foo(x0);
LDR x1, [x0] // Use result to access memory
...在上面的例子中,直线推测会使处理器在控制流的无条件变化后线性地执行内存中的下一条指令,即推测性地执行 BLR 后的 LDR 指令。
如果在推测执行的序列中插入适当的代码序列,由于这种直线推测可能会导致缓存等的变化,而缓存中的一些数据秘密很容易被攻击者通过时序分析被获取。
但据Arm表示,直线推测攻击的安全风险实际上很低,因为这种漏洞实际上很难被利用,且尚未证明有实际攻击案例。当然,这并不代表是100%安全的,因此一些消减措施是必要的。
直线推测的消减措施
本文主要分析LLVM中AArch64后端下直线推测的消减措施的实现。在2020年,Arm公司在LLVM社区提交了一份用于消减直线推测这种幽灵攻击方式的代码,具体实现PASS为 AArch64 sls hardening,文件目录为 llvm/lib/Target/AArch64/AArch64SLSHardening.cpp。
针对前文所述的那些会造成控制流发生变化的指令,并非所有的指令都给出了一个消减方案。Arm认为对于 B、BL 指令尚无法证明存在直线推测漏洞,并不需要采取任何措施。
当前消减措施的核心是:针对RET、BR和BLR指令,在它们后面设置一个推测屏障,当投机执行遇到这些屏障时会停止执行。这些屏障是由一些Arm汇编实现。Arm架构下不同类型的屏障如下:
(1)数据同步屏障(DSB):在DSB指令执行完之前,程序指令序列中没有DSB指令之后的指令。确保在DSB指令之前的显示访存以及Cache、分支预测和TLB维护操作全部执行完毕之后才会执行DSB指令之后的指令。
(2)数据内存屏障(DMB):确保在DMB指令之前的显示访存行为全部执行完毕之后才会执行DMB指令之后的显示访存行为。
(3)指令同步屏障(ISB):刷新处理器中的流水线,在ISB指令之后的所有指令都从缓存或者闪存中获取。
(4)推测屏障(SB):禁止对SB指令之后的任何指令进行推测执行,直到SB指令执行完毕。需要注意的是:此指令是可选的,并非在所有处理器上都可用。
因为这些指令屏障添加在了无条件转移指令之后,所以这些屏障不会运行在正常的指令执行路径上,其性能开销会比较低。
LLVM中消减措施的实现
开发者可以通过选项 -mharden-sls=<value> 控制是否开启直线推测的消减措施,支持的可选值有 all、none、retbr (ARM/AArch64)、blr(ARM/AArch64)、nocomdat(ARM/AArch64)、comdat(ARM/AArch64),此处不再赘述x86平台上可选值。
代码基本实现逻辑如下:
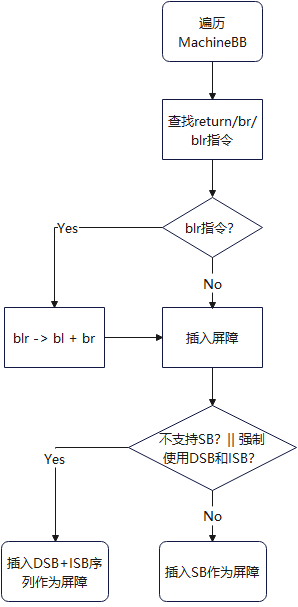
这里有一个针对 blr 指令消减的例子,我们可以看看LLVM究竟做了什么样的防护。
#include <stdlib.h>
#include <math.h>
double Func(double (*pf)(double), a) {
double b = (*pf)(a);
return cos(b);
}在未启用 -mharden-sls 之前的汇编代码如下:
<Func>:
stp x29, x30, [sp, #-16]!
mov x29, sp
scvtf d0, w1
blr x0 # call pf
ldp x29, x30, [sp], #16
b cos在启用 -mharden-sls=blr 之后的汇编代码如下:
<Func>:
stp x29, x30, [sp, #-16]!
mov x29, sp
scvtf d0, w1
bl __llvm_slsblr_thunk_x0
ldp x29, x30, [sp], #16
b cos
<__llvm_slsblr_thunk_x0>:
mov x16, x0
br x16 # calll pf
dsb sy
isb从上述汇编指令可以看到,在指定SLS的消减措施后,编译器会将用于调用函数 pf 的 blr 指令,转换为 bl 指令,变成间接函数调用,真正对函数 pf 的调用发生在了函数 __llvm_slsblr_thunk_x0 内,并在其调用指令 br 后面插入了相关屏障。由于 dsb 指令和 isb 指令并没有插入到程序的正常执行路径上,所以当前的消减措施既实现了安全漏洞的加固,又尽可能降低了对程序性能的影响。
参考
1. https://developer.arm.com/Arm%20Security%20Center/Speculative%20Processor%20Vulnerability#Resources
2. https://grsecurity.net/amd_branch_mispredictor_part_2_where_no_cpu_has_gone_before