


openGauss数据库性能调优
发表于 2020/08/13
0
概述:
本文描述了openGauss数据库基于Taishan服务器,在openEuler操作系统上,为了达到数据库的极致性能,所依赖的关键系统级调优配置。
(1)硬件规格:
CPU: 鲲鹏-920(1620) ARM aarch64 64核 * 2
内存: >=512G
磁盘: Nvme SSD * 4(每块大于1TB)
网卡: 1822网卡 万兆网卡 Ethernet controller: Huawei Technologies Co., Ltd. Hi1822 Family (4*25GE) (rev 45)
(2)软件规格:
操作系统: openEuler 20.03 (LTS)
数据库: openGauss 1.0.0
Benchmark: benchmarksql-5.0
jdk: jdk1.8.0_212
ant: apache-ant-1.9.15
文章通过配置BIOS、操作系统、文件系统、网络、绑核,构造TPCC测试数据等几个方面来对数据库进行调优。- 依赖三方工具 jdk ant benchmark - linux工具 htop iostat.
benchmark htop iostat工具的安装使用请参照:benchmark使用。(https://opengauss.org/zh/blogs/blogs.html?post/optimize/opengauss-tpcc/)
BIOS配置
登录服务器管理系统,重启服务器进入BIOS界面,修改BIOS相关配置并重启 (服务器管理系统以实际为准)。
(1)机器自检后,会提示启动选项
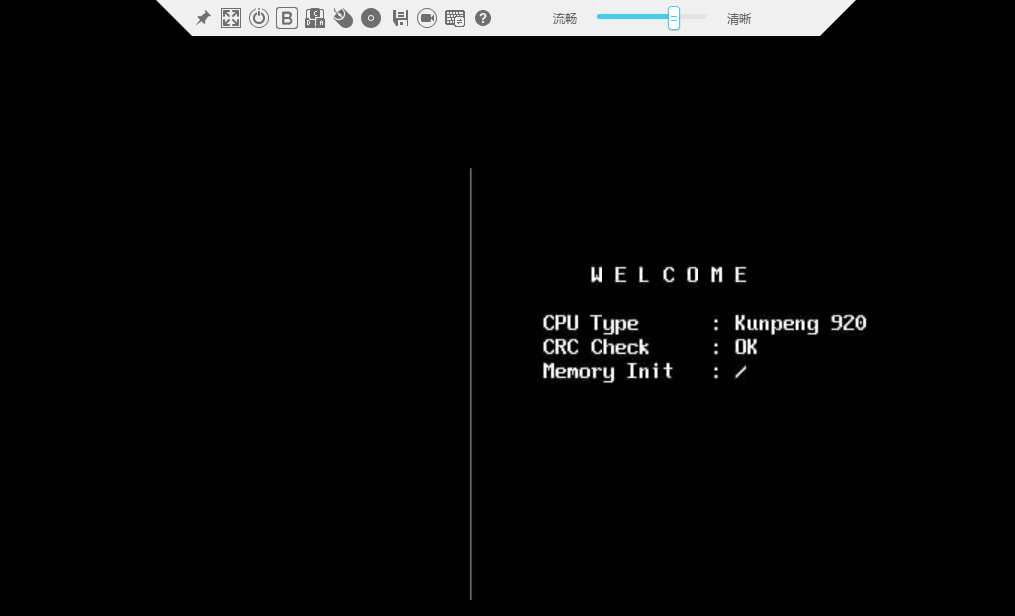
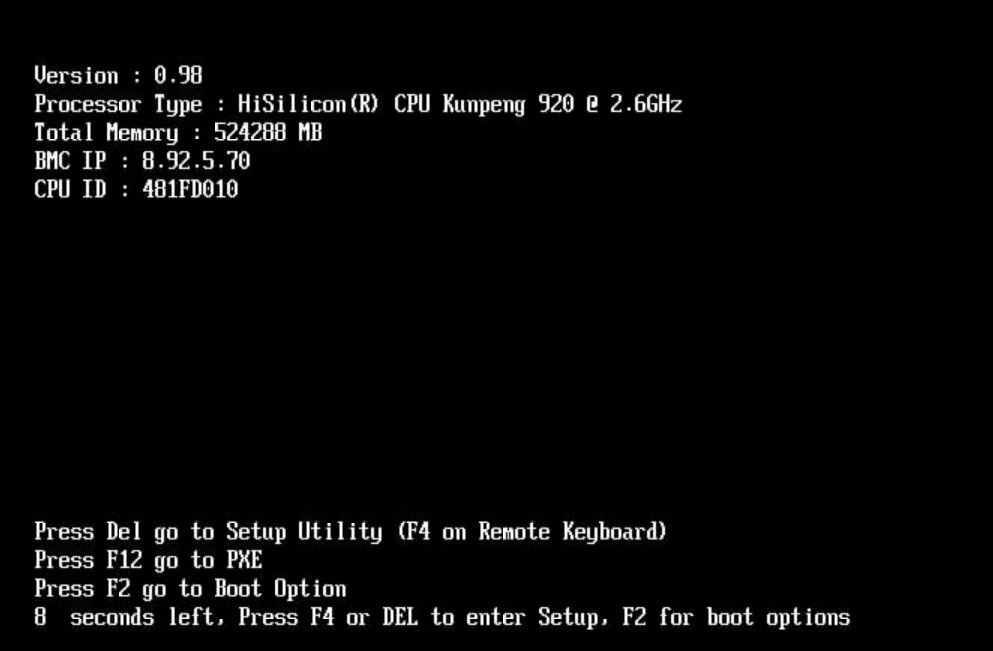
(2)按“Del”键,进入BIOS
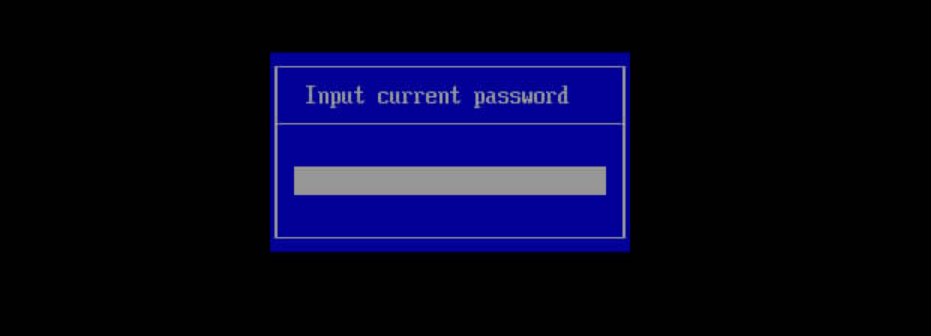
(3)输入BIOS密码
(4)恢复出厂设置
按下“F9”,恢复出厂设置
重要:因为现有的BIOS可能被改动过诸多默认设置,为保险起见,建议首先恢复出厂设置。
(5)修改相关BIOS设置
修改包括下面三项配置
# BIOS->Advanced->MISC Config,配置Support Smmu为Disabled
# BIOS->Advanced->MISC Config,配置CPU Prefetching Configuration为Disabled
# BIOS->Advanced->Memory Config,配置Die Interleaving为Disable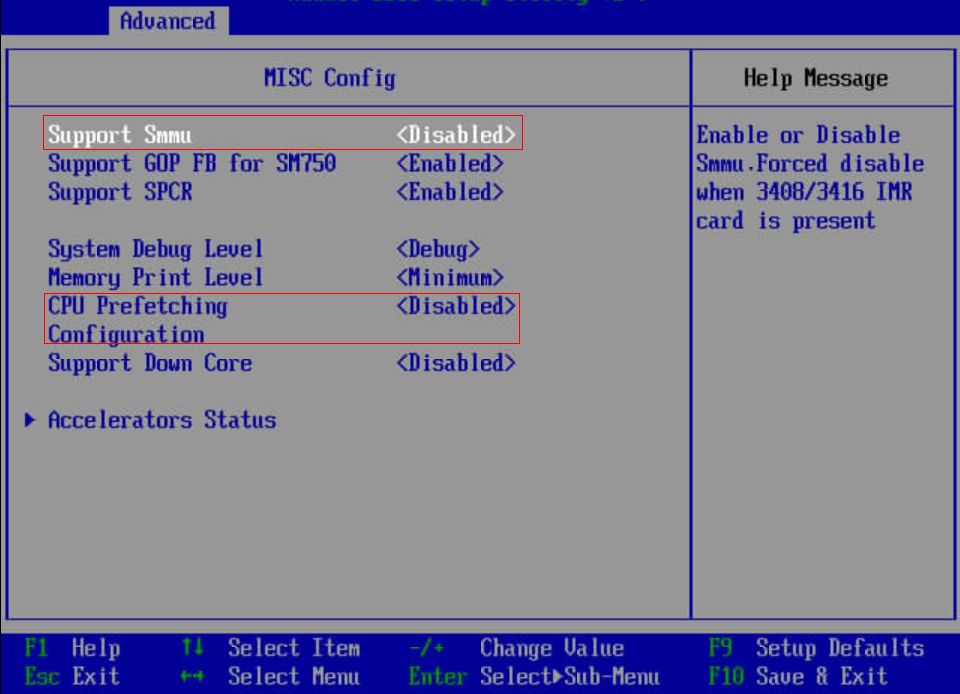
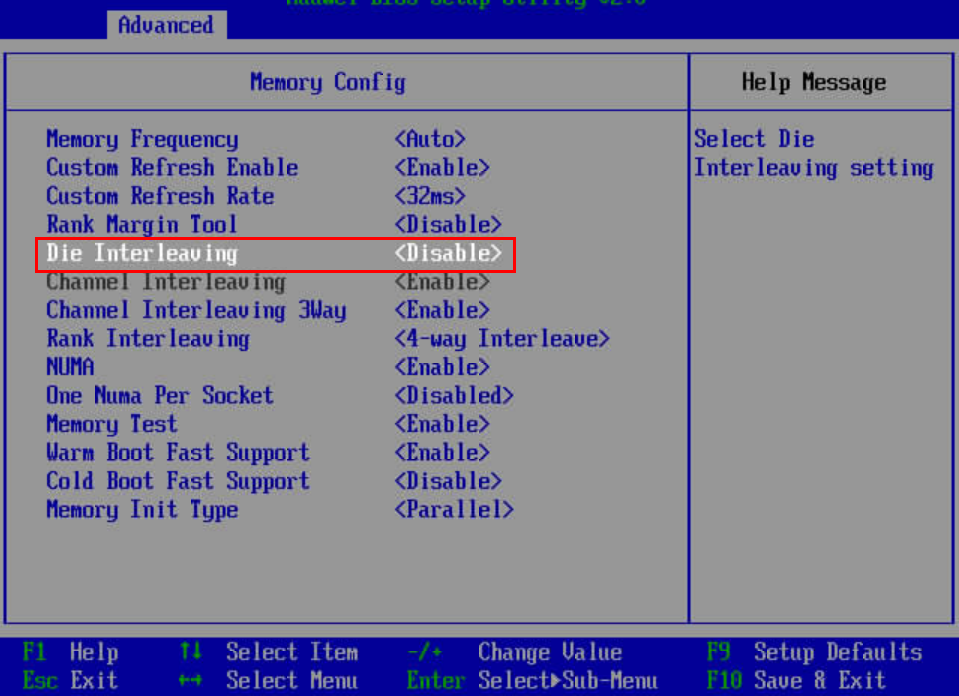
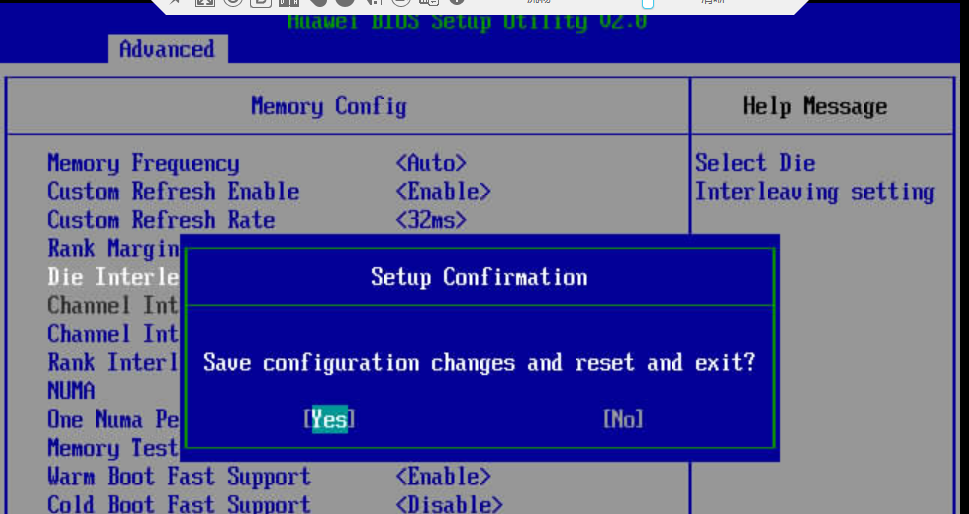
6. 保存相关BIOS设置,并重启
按“F10”保存并退出,重新启动系统。
操作系统配置
优化操作系统相关配置:
Irq balance关闭:为避免gaussdb进程与客户端抢用CPU,导致CPU使用不均衡。如果htop呈现出部分CPU压力很大,部分CPU很空闲时需要考虑是否关闭了irqbalance.
service irqbalance stop
echo 0 > /proc/sys/kernel/numa_balancing
echo 'never' > /sys/kernel/mm/transparent_hugepage/enabled
echo 'never' > /sys/kernel/mm/transparent_hugepage/defrag
echo none > /sys/block/nvme*n*/queue/scheduler ## 针对nvme磁盘io队列调度机制设置文件系统配置
修改xfs文件系统blocksize为8K:
1)确认nvme盘对应加载点的现有blocksize 下面命令查看当前挂载的nvme盘
df -h | grep nvme/dev/nvme0n1 3.7T 2.6T 1.2T 69% /data1
/dev/nvme1n1 3.7T 1.9T 1.8T 51% /data2
/dev/nvme2n1 3.7T 2.2T 1.6T 59% /data3
/dev/nvme3n1 3.7T 1.4T 2.3T 39% /data4xfs_info命令可以查看nvme盘的信息
xfs_info /data1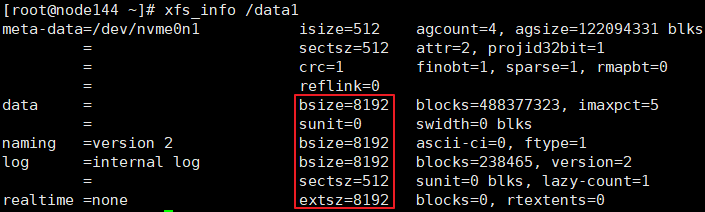
上图中block的大小正好为8K, 不需要修改。若不满足8k块大小的要求, 需要重新格式, 格式化前注意数据的备份。
2)针对需要格式化的磁盘,备份所需的数据
用户注意根据需要,将所需数据备份至其他磁盘或其他机器。
3)重新格式化磁盘,设置block大小8k
以/dev/nvme0n1盘,加载点为/data1为例,相关参考命令如下:
umount /data1
mkfs.xfs -b size=8192 /dev/nvme0n1 -f
mount /dev/nvme0n1 /data14)再次用xfs_info命令确认blocksize是否修改正确。
网络配置
(1)多中断队列设置
针对泰山服务器核数较多的特征,产品需要在服务器端和客户端设置网卡多队列。当前推荐的配置为:服务器端网卡配置16中断队列,客户端网卡配置48中断队列。
多中断队列设置工具(1822-FW)
Hi1822网卡发布版本可以从如下链接获取,IN500 solution 5.1.0.SPC401及之后正式支持设置多队列: https://support.huawei.com/enterprise/zh/intelligent-accelerator-components/in500-solution-pid-23507369/software.
1) 解压Hi1822-NIC-FW.zip, 进入目录,在root用户下安装hinicadm.

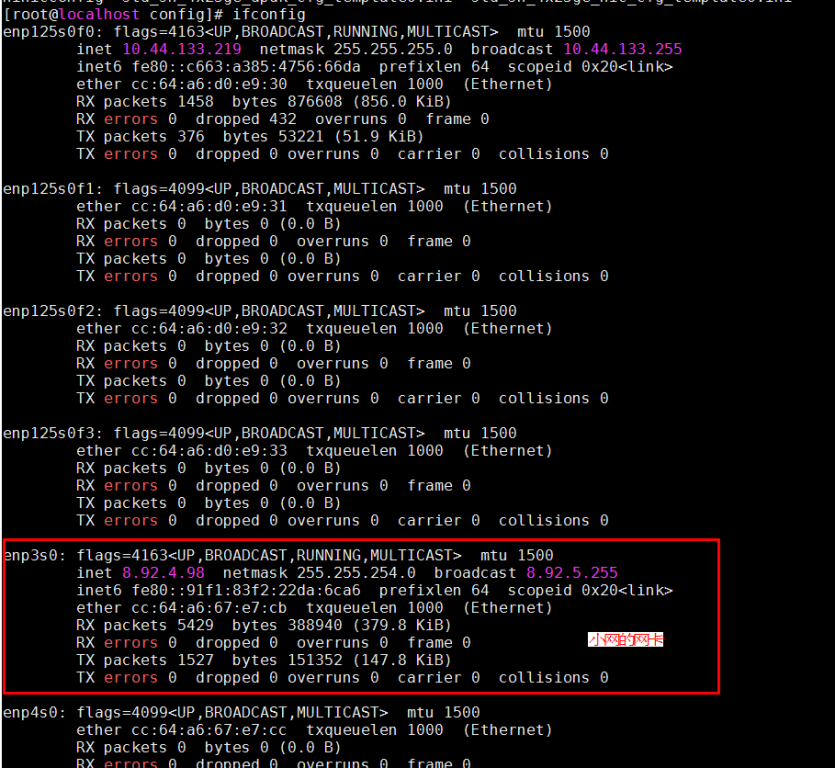
2)确定当前连接的物理端口是哪个网卡的,不同硬件平台这个网口和网卡名有差别。以如下示例机器为例,当前使用enp3s0的小网网口,属于hinic0网卡。
3)进入config目录, 利用配置工具hinicconfig配置中断队列FW配置文件:
64队列配置文件:std_sh_4x25ge_dpdk_cfg_template0.ini;
16队列配置文件:std_sh_4x25ge_nic_cfg_template0.ini;
对hinic0卡配置为不同队列数(默认16队列,可以按需要调整)
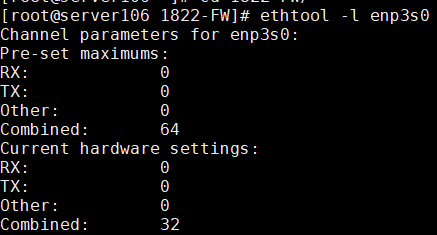
./hinicconfig hinic0 -f std_sh_4x25ge_dpdk_cfg_template0.ini重启操作系统生效,输入命令ethtool -l enp3s0查看(比如下图表示修改为(32)
化值可能不同,当前128核平台,服务器端调优值为16,客户端调优值为48)。
(2)中断调优
在openGauss数据库满跑的情况下(CPU占比90%以上),CPU成为瓶颈,开启offloading,将网络分片offloading到网卡上
ethtool –K enp3s0 tso on
ethtool –K enp3s0 lro on
ethtool –K enp3s0 gro on
ethtool –K enp3s0 gso on以1620平台为例,网卡中断绑定每个numa node中最后4个core,每个core绑定3个中断。绑核中断脚本如下所示,此脚本将在openGauss安装的时候在gs_preinstall被调用,具体执行步骤请查看产品安装说明书:
sh bind_net_irq.sh 16(3)网卡固件确认与更新
确认当前环境的小网网卡固件版本是否为2.5.0.0
ethtool -i enp3s0driver: hinic
version: 2.3.2.11
firmware-version: 2.5.0.0
expansion-rom-version:
bus-info: 0000:03:00.0 如果是2.5.0.0,建议更换为2.4.1.0,以获得更佳性能。
网卡固件更新步骤
1)上传网卡固件驱动至服务器 Hi1822_nic_prd_1h_4x25G.bin
2)使用root执行如下命令
hinicadm updatefw -i <物理网卡设备名> -f <固件文件路径>其中,“物理网卡设备名”为网卡在系统中的名称,例如“hinic0”表示第一张网卡,“hinic1”表示第二张网卡,查找方法参见前文“多中断队列设置”。例如:
# hinicadm updatefw -i <物理网卡设备名> -f <固件文件路径>
Please do not remove driver or network device
Loading...
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] [100%] [\]
Loading firmware image succeed.
Please reboot OS to take firmware effect.3)重启服务器,再确认小网网卡固件版本成功更新为2.4.1.0
ethtool -i enp3s0driver: hinic
version: 2.3.2.11
firmware-version: 2.4.1.0
expansion-rom-version:
bus-info: 0000:03:00.0 确认小网网卡固件版本成功更新成功。
数据库服务端及客户端绑核
安装数据库, 具体参考openGauss安装文档。
大概步骤如下:
1)停止数据库
2)修改postgresql.conf参数
3)以绑核方式启动数据库: numactl --interleave=all bin/gaussdb -D ${DATA_DIR} --single_node
4)以绑核方式启动benchmark: numactl -C 0-19,32-51,64-83,96-115 ./runBenchmark.sh props.pg
按照自己的绑核配置和benchmark配置文件执行此命令。这里的绑核参数是在数据库绑核参数的空隙。
(1)服务器端绑核设置
1)业务进程在运行过程中,硬件上报的网络中断会导致频繁的上下文切换,严重影响效率,因此需要将网络中断和业务分开绑定在不同的核上运行,网络中断绑核请查看上一节。
2)当前openGauss中引入了线程池机制,即数据库启动时,线程池将创建指定数目的线程来服务,线程在创建时会进行绑核,因此需要将网卡的绑核信息通过 GUC 参数传入,方便运行期间绑核设置。以128核为例,对应参数如下图:

其中线程总数为(cpu总数128 - 处理网络的cpu数目16)* 每个核上线程数(经验值推荐7.25) = (128-16)*7.25 = 812,numa节点数为4,处理中断的核数为16。
如下为辅助分配绑定CPU:
numactl -C 0-27,32-59,64-91,96-123 gaussdb --single_node -D {DATA_DIR} -p {PORT} &或者:
numactl --interleave=all gaussdb --single_node -D {DATA_DIR} -p {PORT} &(2)服务器端参数设置
postgresql.conf中新增如下参数:- advance_xlog_file_num = 10
此参数表示后台线程BackgroundWALWriter周期性地提前检测并初始化未来10个XLog文件,避免事务提交时才去执行XLog文件初始化,从而降低事务提交时延。只有在性能压力测试时作用才会体现出来,一般不用配置。默认为0,即不进行提前初始化。- numa_distribute_mode = 'all'
此参数目前有all和none两个取值。all表示启用NUMA优化,将工作线程和对应的PGPROC、WALInsertlock进行统一分组,分别绑定到对应的NUMA Node下,以减少关键路径上的CPU远端访存。默认取值为none,表示不启用NUMA分布特性。只有在涉及到多个NUMA节点,且远端访存代价明显高于本地访存时使用。当前建议在性能压力测试情况下开启。
thread_pool_attr线程池配置
thread_pool_attr = '812,4,(cpubind: 0-27,32-59,64-91,96-123)'
相关参数:
max_connections = 4096
allow_concurrent_tuple_update = true
audit_enabled = off
checkpoint_segments = 1024
checkpoint_timeout = 15min
cstore_buffers = 16MB
enable_alarm = off
enable_codegen = false
enable_data_replicate = off
full_page_writes = on
max_files_per_process = 100000
max_prepared_transactions = 2048
shared_buffers = 350GB
use_workload_manager = off
wal_buffers = 1GB
work_mem = 1MB
log_min_messages = FATAL
transaction_isolation = 'read committed'
default_transaction_isolation = 'read committed'
synchronous_commit = on
fsync = on
maintenance_work_mem = 2GB
vacuum_cost_limit = 2000
autovacuum = on
autovacuum_mode = vacuum
autovacuum_max_workers = 5
autovacuum_naptime = 20s
autovacuum_vacuum_cost_delay = 10
xloginsert_locks = 48
update_lockwait_timeout = 20min
enable_mergejoin = off
enable_nestloop = off
enable_hashjoin = off
enable_bitmapscan = on
enable_material = off
wal_log_hints = off
log_duration = off
checkpoint_timeout = 15min
autovacuum_vacuum_scale_factor = 0.1
autovacuum_analyze_scale_factor = 0.02
enable_save_datachanged_timestamp = false
log_timezone = 'PRC'
timezone = 'PRC'
lc_messages = 'C'
lc_monetary = 'C'
lc_numeric = 'C'
lc_time = 'C'
enable_thread_pool = on
thread_pool_attr = '812,4,(cpubind:0-27,32-59,64-91,96-123)'
enable_double_write = off
enable_incremental_checkpoint = on
enable_opfusion = on
advance_xlog_file_num = 10
numa_distribute_mode = 'all'
track_activities = off
enable_instr_track_wait = off
enable_instr_rt_percentile = off
track_counts = on
track_sql_count = off
enable_instr_cpu_timer = off
plog_merge_age = 0
session_timeout = 0
enable_instance_metric_persistent = off
enable_logical_io_statistics = off
enable_page_lsn_check = off
enable_user_metric_persistent = off
enable_xlog_prune = off
enable_resource_track = off
instr_unique_sql_count=0
enable_beta_opfusion=on
enable_beta_nestloop_fusion=on(3)TPCC客户端绑核设置
客户端通过 numactl 将客户端绑定在除网卡外的核上,下图以 128 核环境举例,共80个核用于处理业务逻辑,剩余48个核处理网络中断。
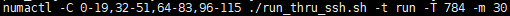
对应tpmc程序应该使用为:
numactl -C 0-19,32-51,64-83,96-115 ./runBenchmark.sh props.pg其他核用来处理网络中断。
构建TPCC初始数据
(1)修改benchmark配置
复制props.pg并重命名为props.opengauss.1000w,编辑该文件,将如下配置覆盖到文件里面:
cp props.pg props.opengauss.1000w
vim props.opengauss.1000wdb=postgres
driver=org.postgresql.Driver
// 修改连接字符串, 包含ip, 端口号, 数据库
conn=jdbc:postgresql://ip:port/tpcc1000?prepareThreshold=1&batchMode=on&fetchsize=10
// 设置数据库登录用户和密码
user=user
password=******
warehouses=1000
loadWorkers=200
// 设置最大并发数量, 跟服务端最大work数对应
terminals=812
//To run specified transactions per terminal- runMins must equal zero
runTxnsPerTerminal=0
//To run for specified minutes- runTxnsPerTerminal must equal zero
runMins=5
//Number of total transactions per minute
limitTxnsPerMin=0
//Set to true to run in 4.x compatible mode. Set to false to use the
//entire configured database evenly.
terminalWarehouseFixed=false
//The following five values must add up to 100
//The default percentages of 45, 43, 4, 4 & 4 match the TPC-C spec
newOrderWeight=45
paymentWeight=43
orderStatusWeight=4
deliveryWeight=4
stockLevelWeight=4
// Directory name to create for collecting detailed result data.
// Comment this out to suppress.
resultDirectory=my_result_%tY-%tm-%td_%tH%tM%tS
osCollectorScript=./misc/os_collector_linux.py
osCollectorInterval=1
// 收集OS负载信息
//osCollectorSSHAddr=osuer@10.44.133.78
//osCollectorDevices=net_enp3s0 blk_nvme0n1 blk_nvme1n1 blk_nvme2n1 blk_nvme3n1(2)TPCC导入数据前准备
1)替换tableCreats.sql文件
下载文件tableCreates.sql ()。 使用该文件替换benchmarkSQL中路径 benchmarksql-5.0/run/sql.common/ 下的对应文件。
该文件主要做了如下修改:
a. 增加了两个表空间
CREATE TABLESPACE example2 relative location 'tablespace2';
CREATE TABLESPACE example3 relative location 'tablespace3';b. 删除序列bmsql_hist_id_seq
c. 给每一个表增加FACTOR属性
create table bmsql_stock (
s_w_id integer not null,
.....
s_dist_10 char(24)
) WITH (FILLFACTOR=80) tablespace example3;2)修改索引indexCreates.sql
修改run/sql.common/indexCreates.sql文件
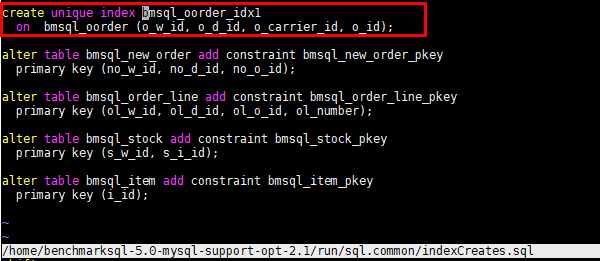
修改上图中红框中的内容如下:

在该文件中添加下图中红色内容,可以在benchmark自动生成数据的时候自动生成到不同的数据表空间,如果未添加可以在benchmark生成数据之后再数据库端修改,用于分盘。

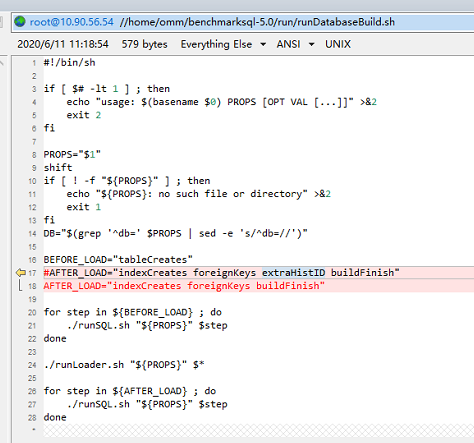
3)修改runDatabaseBuild.sh文件 修改下图内容可避免生产数据时候的外键不支持错误。
(3)导入数据
运行runDatabaseBuild.sh导入数据
(4)数据备份
为了方便多次测试, 减少导数据的时间, 可以将导好的数据备份, 一种常用的做法是: 停止数据库, 将整个数据目录做一次拷贝。恢复时参考脚本如下:
#!/bin/bash
rm -rf /ssd/omm108/gaussdata
rm -rf /usr1/omm108dir/tablespace2
rm -rf /usr2/omm108dir/tablespace3
rm -rf /usr3/omm108dir/pg_xlog
cp -rf /ssd/omm108/gaussdatabf/gaussdata /ssd/omm108/ &
job0=$!
cp -rf /usr1/omm108dir/tablespace2bf/tablespace2 /usr1/omm108dir/ &
job1=$!
cp -rf /usr2/omm108dir/tablespace3bf/tablespace3 /usr2/omm108dir/ &
job2=$!
cp -rf /usr3/omm108dir/pg_xlogbf/pg_xlog /usr3/omm108dir/ &
job3=$!
wait $job1 $job2 $job3 $job0(5)数据分盘
在性能测试过程中, 为了增加IO的吞吐量, 需要将数据分散到不同的存储介质上。由于我们机器上有4块NVME盘, 可以将数据分散到不同的盘上。我们主要将pg_xlog, tablespace2, tablespace3这三个目录放置在其他3个NVME盘上, 并在原有的位置给出指向真实位置的软连接. pg_xlog位于数据库目录下, tablespace2, tablespace3分别位于数据库目录pg_location下。对tablespace2分盘的示例命令如下:
mv $DATA_DIR/pg_location/tablespace2 $TABSPACE2_DIR/tablespace2
cd $DATA_DIR/pg_location/
ln -svf $TABSPACE2_DIR/tablespace2 ./(6)运行TPCC程序
numactl –C 0-19,32-51,64-83,96-115 ./runBenchmark.sh props.opengauss.1000w(7)性能监控
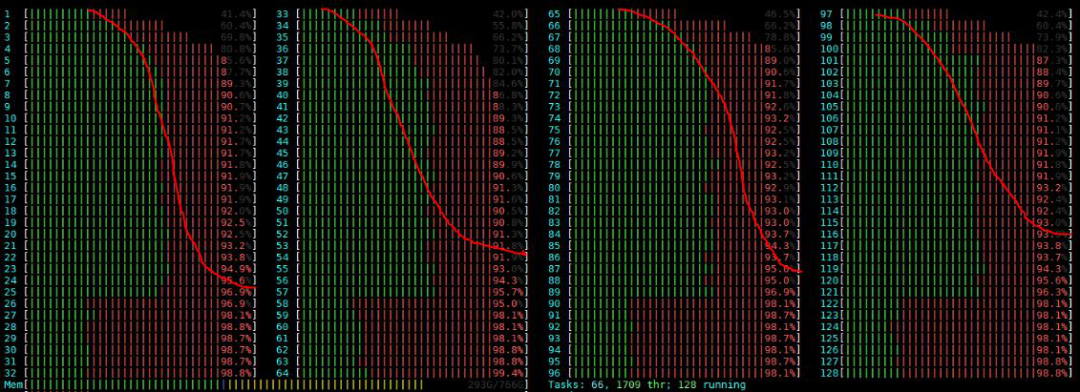
使用htop监控数据库服务端和tpcc客户端CPU利用情况, 极限性能测试情况下, 各个业务CPU的占用率都非常高(> 90%), 若有CPU占用率没有达标, 可能是绑核方式不对, 需要进行调整
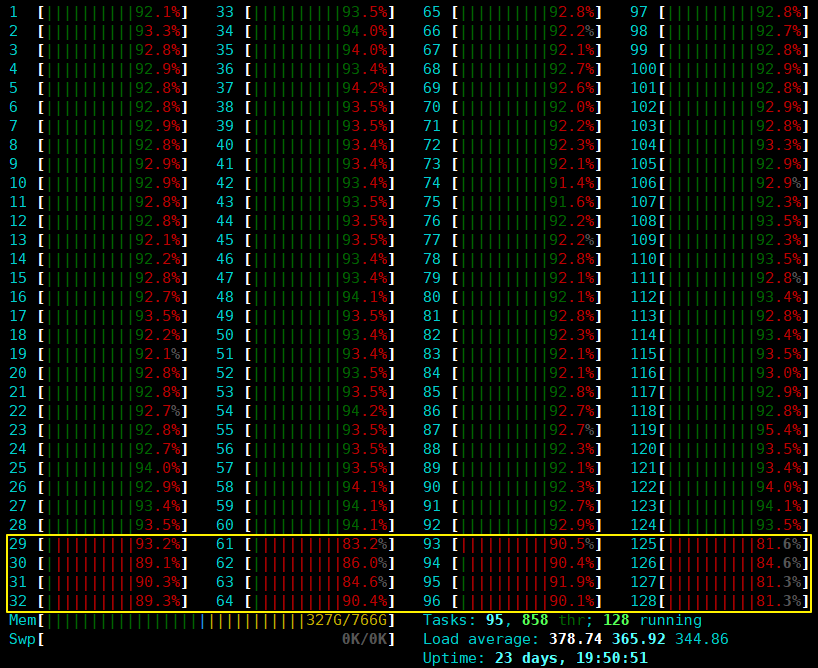
上图中黄线框中的是处理网络中断的CPU.
(8)调优后的监控状态
经过调优后的htop状态呈现这种状态是比较可靠的状态
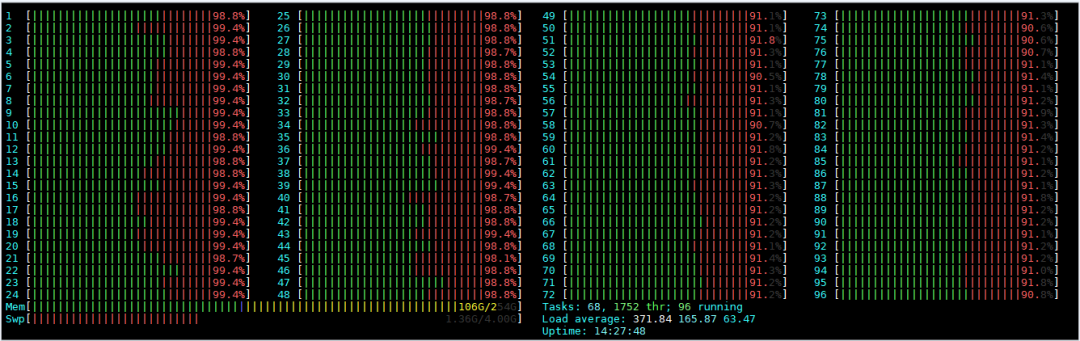
数据库调优是一个繁琐的工作,需要不断去修改配置,运行TPCC,反复去调试以达到最优性能配置。
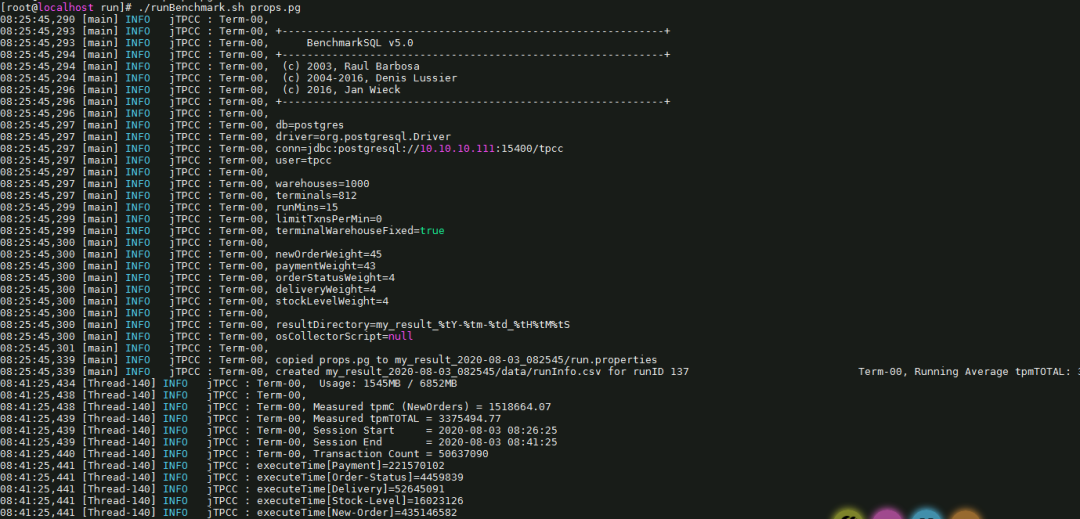
TPCC运行结果:
openGauss开源社区官方网站:
openGauss组织仓库:
openGauss镜像仓库:
https://github.com/opengauss-mirror
往期推荐:
(3)一张图看懂openGauss第1期:openGauss概述