


基于Apache Hive实现的近数据计算,提升计算性能的特性——OmniData
发表于 2025/04/09
0
作者 | 徐立
OmniData功能
- 支持Hive/Spark大数据引擎。
- 实现将计算节点的Filter、Aggregation和Limit算子下推到存储节点进行计算,将算子处理完后的结果通过网络传输到计算节点,降低网络传输数据量,提升性能。
- 实现对接HAF(Homogeneous Acceleration Framework),替换原有通信下推框架的Server/Client接口,通过注解形式实现下推。
- 实现将算子下推到Ceph/HDFS存储节点上处理。
- 实现大数据引擎内置UDF(cast、instr、length、lower、replace、substr和upper)的下推。
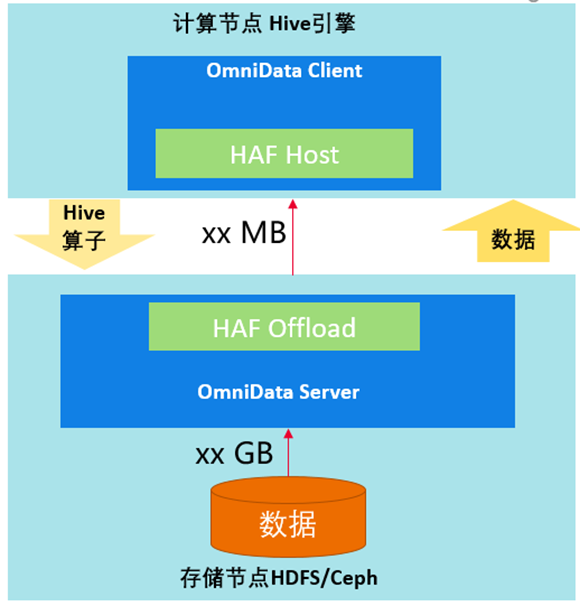
OmniData架构
- OmniData Client属于开源的部分,为不同的引擎提供相应的插件。通过HAF提供的注解和编译插件,在需要下推的函数上添加注解,HAF会自动把任务下推到卸载节点的OmniData Server中。
- Haf Host为lib库,部署在计算节点,对外提供任务卸载的能力,把任务下推到Haf Offload。
- Haf Offload为lib库,部署在存储节点提供任务执行的能力,用来执行OmniData Server的作业。
- OmniData Server提供算子下推的执行能力,接收Haf Host下推下来的任务。
OmniData应用场景
Hive作为一个常见的大数据引擎,在大数据典型硬件配置的存算分离场景下,运行标准测试用例TPC-H,采用OmniData,开启下推的10条SQL平均性能提升40%以上。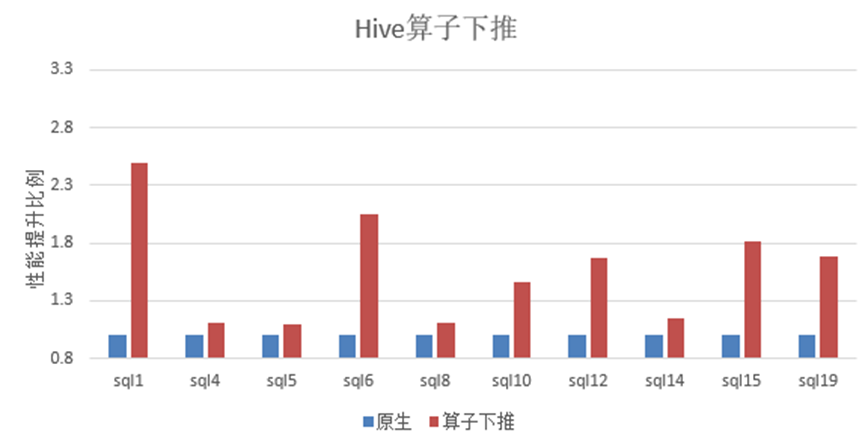
主要优化方法
1. 基于数据选择率,做到动态的下推。OmniData通过统计信息计算数据选择率(选择率越低,表示过滤效果越好),通过参数设置下推的选择率阈值,OmniData就能够动态地将选择率低与阈值的算子推到存储节点上执行,实现存储节点在本地读取数据进行计算,再将计算过滤之后的数据集通过网络返回到计算节点,提升网络传输效率,优化性能。
除了数据选择率,还会根据算子是否支持,剩余资源是否足够等条件进行判断。
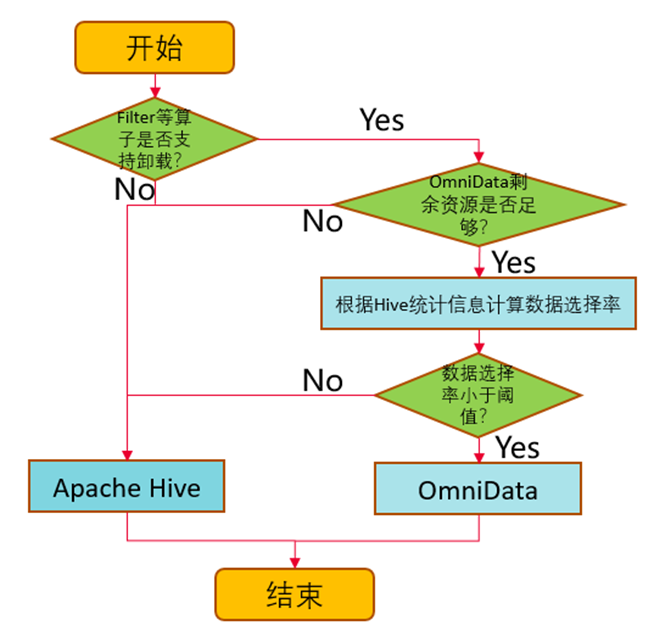
PS:统计信息通过执行Analyze语句获取
2. 存算协同,合理利用计算资源。
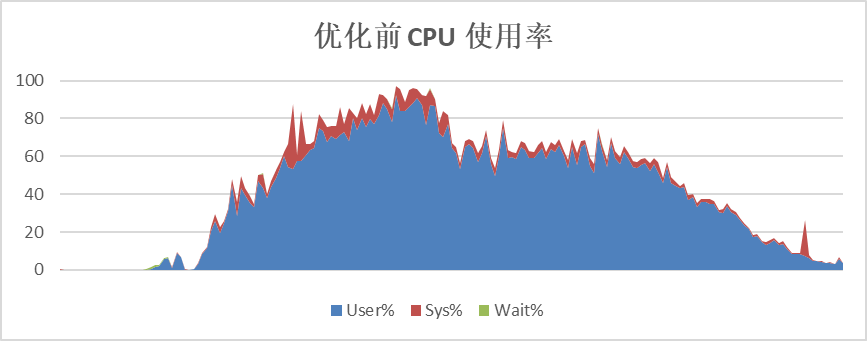
OmniData将算子下推到存储节点执行计算,可以有效地降低计算节点的CPU使用率,并且能将存储节点的CPU使用起来,提升总体计算效率。
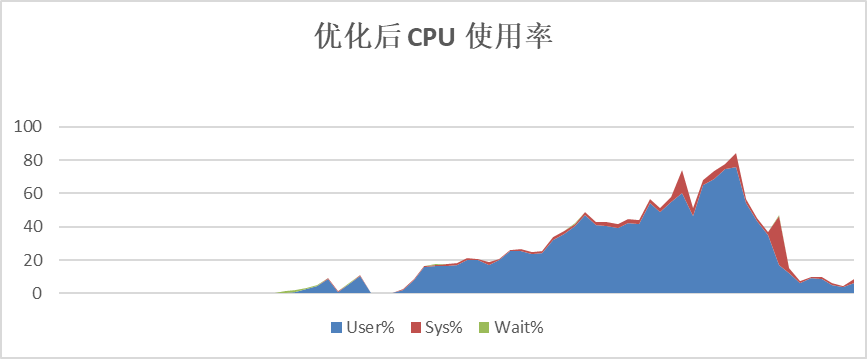
以TPC-H的SQL为例,优化前计算节点CPU平均使用率60%以上,优化后,计算节点CPU平均使用率在40%左右。
3. 提前过滤数据,减少网络传输。
数据的提前过滤是OmniData性能收益的主要源,在存储节点过滤数据,减少网络传输,减少计算节点处理的数据量。
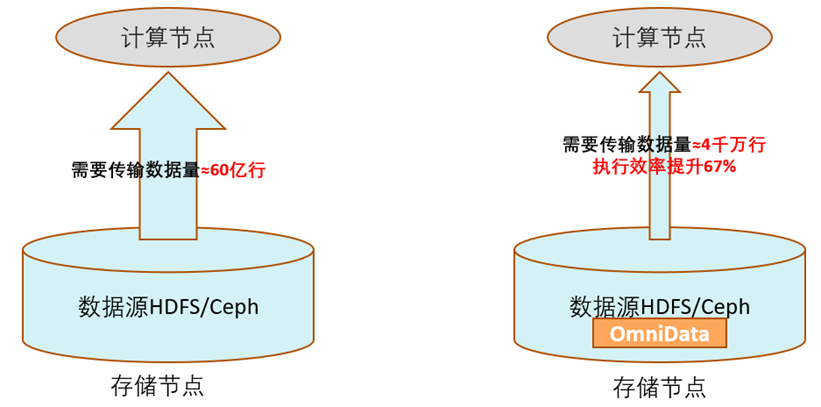
以TPC-H的SQL为例,SQL中含有多个Filter算子,优化前的算子需要跨网络从远端存储节点读取近60亿行的数据;优化后只需要传输过滤后的有效数据4000万行。执行效率提升60%以上。
欢迎感兴趣的朋友们参与进来,多多支持OmniData,代码地址:https://gitee.com/openeuler/omnidata-hive-connector