


鲲鹏达梦数据库在4路服务器性能调优实践分享
发表于 2025/04/16
0
作者| 赵书光,谭乐天
测试场景
TPCC(Transaction Processing Performance Council)测试,也称为TPC-C,是一种用于衡量在线事务处理(OLTP)系统性能和可伸缩性的基准测试项目。TPC-C测试的核心是模拟一个商品批发公司的销售模型,涵盖了对订单、库存、账号收支等操作的管理。
BenchmarkSQL是一款经典的开源数据库测试工具,内嵌了TPC-C测试脚本,可以对PostgreSQL、MySQL、Oracle以及SQL Server等数据库直接进行测试。它通过JDBC测试OLTP(联机事务处理, Online Transaction Processing)的TPC-C。
应用软件
| 软件名称 | 版本 | 说明 |
|---|---|---|
| 达梦数据库 | 8.1.4.77 | 数据库 |
| BenchmarkSQL | 5.0 | 测试工具 |
| JDK | 1.8 | Java环境 |
| Apache-ant | 1.10.9 | 编译工具 |
调优前tpmc值略低,为此进行针对性的性能瓶颈分析与调优
性能瓶颈分析
磁盘IO分析
FIO(Flexible I/O Tester)是一种广泛使用的磁盘I/O性能测试工具,它能够模拟多种不同类型的I/O负载,包括随机读写、顺序读写、混合读写等,以评估存储系统在各种负载下的性能表现。
在块大小bs=8k/16k/32k/512k,numjobs=128,rw=randwrite下,分别测试了磁盘的随机写的带宽,测试命令如下:
fio --directory=/dm/data/fio --filesize=1g --bs=xxk --numjobs=128 --nrfiles=1 --group_reporting --direct=1 --sync=1 --name=1g_xxk --rw=randwrite --iodepth=1从测试结果来看,随着块大小的增加,磁盘随机写的带宽会增加。
fio测试的bs块大小可以模拟数据库的页大小,而通过iostat查看tpcc测试时磁盘实际运行结果,相比而言,测试阶段的写带宽远远低于fio测试32k随机写的理想性能。但是await,areq-sz请求大小和aqu-sz队列长度等指标也没有异常,说明磁盘不存在瓶颈问题,测试负载远远没有达到磁盘的极限。
在尝试修改磁盘调度策略、调大队列数、调大队列深度和关闭磁盘预取等磁盘方面的OS调优措施后,tpmC性能基本没有变化,磁盘的写带宽也没有变化。
另一方面,此次复测tpmC结果还没有达到基于旧版本达梦数据库测试的成绩,因此尝试先复现上次测试的结果。
上次测试跟此次的区别就是达梦数据库版本不同和配置文件没有设置事务合并提交的两个参数:COMMIT_BATCH和COMMIT_BATCH_TIMEOUT。其中,COMMIT_BATCH是事务合并提交数,达到这个数目才会将合并的事务一起提交;COMMIT_BATCH_TIMEOUT是达到时间阈值后,即使没有达到事务合并提交的数目也会提交事务。
在新版本达梦数据库关闭事务合并提交后,测试性能有所提升,说明是事务合并提交限制了磁盘的读写性能。
最终在不进行OS等调优的情况下,参考旧版本达梦数据库和相关配置文件,基本达到了上次测试的成绩。
总结来说,tpcc测试场景属于高并发小事务的场景,在100并发量下,事务处理速度非常快,从await时间也能看出来,如果限制了合并提交事务数目,就会产生比较大的延迟。事务提交时,为了保证持久性,需要确保redo log记录持久化到磁盘,每个事务写的redo log buffer都会写入磁盘,数据库会通过锁机制来保护redo log buffer的并发访问,在高并发场景下就会存在锁冲突的情况。COMMIT_BATCH的引入就是为了减少在高并发场景下锁的冲突,达到一定数目再一起合并事务提交,可以减少因为锁冲突带来的延迟问题,提高磁盘的吞吐量。
尝试提高并发量到400,tpmC、磁盘写带宽虽然没有达到fio测试性能的极限,但相比之前的确实提高了很多。
CPU分析
通过top命令分析,CPU的整体利用率不高。经过分析,我们认为是因为tpcc测试场景这个测试压力下,只能用到这么多CPU资源,无法充分利用更多CPU更多核的资源。
热点函数分析
利用perf top -p $PID查看热点函数,结果如下:
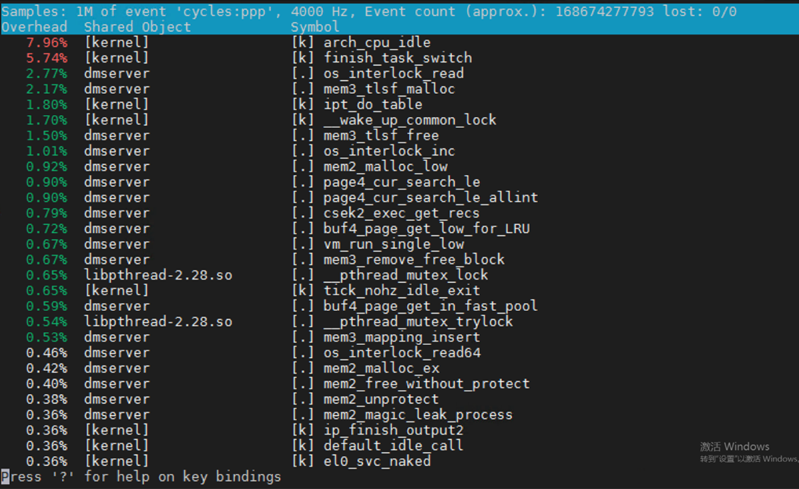
存在两个热点函数 arch_cpu_idle 和 finish_task_swtich,分别是CPU进入空闲状态和进程在上下文切换时调用的函数,tpcc测试场景中大部分cpu核都是空闲的,而且在高并发场景下,进程上下文切换会很多,所以这两个热点函数属于正常情况。
生成火焰图,在鲲鹏4路上仓数为1000并发数为400时,热点线程主要为dm_sql_thd,是达梦数据库处理事务的主线程,其中有 ntsk_process_commit和ntsk_pricess_exec两个线程,分别是事务提交和事务处理。当增加仓数和并发数的时候,dm_sql_thd线程占比增大,其中ntsk_process_commit也会增大,仓数越大数据量越大,并发数越大会话数越大,所以这两个增大是合理的。其他没有发现明显的异常热点线程。
数据库分析
如果checkpoint刷盘和tpcc测试同时进行,会增大磁盘读写延迟,严重的话甚至会锁住数据库,性能严重下降。查看checkpoint刷盘时的热点函数和火焰图,可以看到热点函数os_interlock_read占据了大量的CPU时间,导致tpcc测试无法正常读写磁盘,吞吐量急剧下降。调大CKPT_INTERVAL 刷盘时间间隔,关闭redo log触发检查点操作,设置CKPT_RLOG_SIZE=0,降低测试阶段对磁盘读写性能的影响。
设置DIRECT_IO=1,不使用文件系统缓存,启用直接I/O,所有的I/O操作会绕过OS的缓存,直接在数据库和磁盘之间进行数据传输。提高I/O线程数目,设置IO_THR_GROUPS=128。
基于以上设置,可以降低checkpoint刷盘操作对磁盘I/O的影响,增大磁盘读写的吞吐量,tpmC性能有所提高。
调优实施
BIOS 调优
|
设置 |
优化值 |
含义 |
|
BIOS->Advanced->Performance Config->Power Policy |
Performance |
电源策略,效率模式省电,性能模式性能更优 |
|
BIOS->Advanced->Memory Config->Custom Refresh Rate |
64ms |
内存刷新频率,拉长刷新率性能更优 |
|
BIOS->Advanced->PCIE Config -> CPU X PCIe -> Port X -> PCIe Max Payload |
512B |
PCIe最大负载,即每次传输最大单位 |
|
BIOS->Advanced->MISC Config->Support Smmu |
Disabled |
虚拟化场景建议打开,非虚拟化场景对网卡性能有影响,建议关闭 |
|
BIOS->Advanced->MISC Config->CPU Prefetching Configuration |
Disabled |
CPU预取可以令CPU先行提取下一段指令,提高系统效能,内存带宽提高,内存延迟增加,预取内容若错误则造成额外开销,需根据实际情况选择是否打开 |
|
BIOS->Advanced->Performance Config->DEMT |
Disabled |
CPU一直运行在最大频率,不会降频 |
OS 调优
硬盘:
1)修改IO调度策略,SSD场景一般建议noop(none)
echo none > /sys/block/sdb/queue/scheduler2)提高IO调度队列nr_requests,可以提高系统的吞吐量
echo 4096 > /sys/block/sdb/queue/nr_requests3)关闭磁盘预取,tpcc测试场景主要是随机写
echo 0 > /sys/block/sdb/queue/read_ahead_kbCPU:
1)NUMA绑核,将达梦数据库主进程dmserver绑到128-255核上,将TPCC测试进程绑到9-63核上,1-8一般为系统级进程
numactl -C 128-255 DmServiceTPCC start
numactl -C 9-63 nohup ./runBenchmark.sh props.dm > res_xxx.log 2>&1数据库:
1)vim /data/dmdbms/dm.ini,将BUFFER值修改为以下命令查出的值(空闲内存的60%)
echo 3 > /proc/sys/vm/drop_caches # 清除缓存
free -m|grep free -A 1|awk '{print $4}'|grep [0-9]|xargs -I {} expr {} \* 6 / 102)增大checkpoint刷盘时间间隔,关闭redo log触发检查点,增大线程数。修改dm.ini参数如下:
CKPT_INTERVAL=3600
CKPT_RLOG_SIZE=0
DIRECT_IO=1
IO_THR_GROUPS=128
3)设置事务合并提交数目和超时时间,在高并发场景下可以减少锁冲突
COMMIT_BATCH=18
COMMIT_BATCH_TIMEOUT=2
TPCC 测试脚本参数优化
terminalWarehouseFixed参数用于指定终端和仓库的绑定模式,设置为true时可以运行4.x兼容模式,意思为每个终端都有一个固定的仓库。设置为false时可以均匀的使用数据库整体配置。
terminalWarehouseFixed设置为true。
调优后的性能提升
1. 关闭DEMT提升效果非常明显,说明保证CPU一直保持在最大频率,对于性能影响很大。
2. 在并发量100的场景下,关闭数据库的事务合并提交,可以显著提升,说明在并发量不大的情况下,开启事务合并提交会增大磁盘I/O的延迟,在低并发量下建议关闭。
3. 对于磁盘I/O侧的OS调优措施,修改磁盘调度策略等,对于性能有小量的提升;将dmserver数据库进程和测试进程分别绑核,也可以获得少量提升。说明磁盘的优化和NUMA绑核,对于性能提升还是有一定的作用。
4. 对于数据库侧,增大checkpoint时间间隔等,可以降低checkpoint刷盘给测试带来的影响;在高并发场景下(增大并发量到400),开启事务合并提交,可以减少事务提交时redo log buffer的锁冲突,大大提高了磁盘I/O的读写带宽,显著提升了测试性能,达到客户目标。
5. 此外,新版本相较于旧版本,在相同配置下(不设置事务合并提交)进行了测试。在不同并发量上,新版本达梦数据库的性能都优于旧版本,可以提升15%以上。
新版本达梦数据库对于事务合并提交做了优化,在并发量为400时,对于不同的COMMIT_BATCH和COMMIT_BATCH_TIMEOUT进行了测试。在COMMIT_BATCH=18,COMMIT_BATCH_TIMEOUT=2的时候,性能可以达到最优。
- 提高事务合并提交数目,当事务执行时间很短的时候,会增大对磁盘I/O的延迟;
- 增大超时时间,如果事务提交较少,会一直等待达到超时时间才会合并提交事务,增加了延时等待时间,没有充分利用磁盘资源。
所以提高或者降低事务合并提交的数量,性能都有所下降;保持事务合并提交数不变,提高超时时间,性能也会下降。
总结思考
要善于借助历史经验,学会控制变量。比如这次在尝试了很多调优措施没有效果后,在旧的数据库版本和配置上复现了历史数据,并找到两次测试的区别,快速定位到是事务合并提交参数的影响。
深入理解数据库原理,比如日志和checkpoint的机制,对于这次测试有很大帮助。
遗留问题
数据库层面,因为这次没有采用非常极限的配置,而是尽可能地贴近生产环境,比如redo log写策略等,所以还有一定的提升空间。
checkpoint刷盘操作对于磁盘读写性能影响很大,这次采用调大刷盘时间间隔降低对磁盘读写性能的影响,可以继续详细分析checkpoint对于性能的影响,尝试其他细粒度的优化措施。
磁盘写带宽还没有到达极限,可以继续增大并发量或者其他增加负载的办法,将磁盘性能继续压榨,数据库性能还能继续提高。