


鲲鹏服务器上Kafka性能调优的探索与实践
发表于 2025/04/29
0
作者:戚嘉伟
1 背景
XX客户鲲鹏高性能版在实时场景Kafka组件的测试中,开箱性能对比友商低XX%,较大的性能gap需要发现并使能各种调优手段来抹平差距,构建竞争力。
2 技术介绍
2.1 JNI
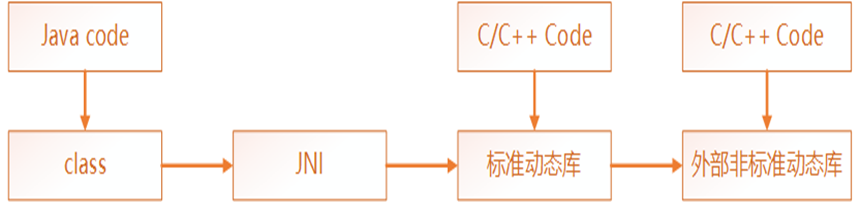
Java Native Interface,即Java本地接口。它允许在Java虚拟机内运行的Java代码与其他编程语言(如C, C++和汇编语言)编写的程序和库进行交互。简单点说, JNI可以帮助我们用Java代码访问其他编程语言。Java代码借助JNI调用由C代码生成的动态链接库文件(SO文件),从而访问C程序的函数,最后得到函数执行的结果
引入自定义的C编程,以及自定义的标准动态链接库。然后再用自定义的C去调用外部的非标准C程序。
2.2 Crc32
循环冗余校验(英语:Cyclic redundancy check,通称“CRC”)是一种根据网上数据包或计算机文件等数据产生简短固定位数校验码的一种散列函数,主要用来检测或校验数据传输或者保存后可能出现的错误。生成的数字在传输或者存储之前计算出来并且附加到数据后面,然后接收方进行检验确定数据是否发生变化。一般来说,循环冗余校验的值都是32位的整数。由于本函数易于用二进制的计算机硬件使用、容易进行数学分析并且尤其善于检测传输通道干扰引起的错误,因此获得广泛应用。此方法是由W. Wesley Peterson于1961年发表。
2.3 LZ4压缩
LZ4是一种无损压缩算法,其单核压缩速度超过500MB/s(每周期处理超过0.15字节)。该算法具有极快的解码器,单核解码速度可达数GB/s(约每周期处理1字节)。此外还提供名为LZ4_HC的高压缩率衍生版本,通过可定制的CPU时间换取更高的压缩比。LZ4库采用BSD开源协议发布。
3 需求分析
3.1 Kafka生产流程
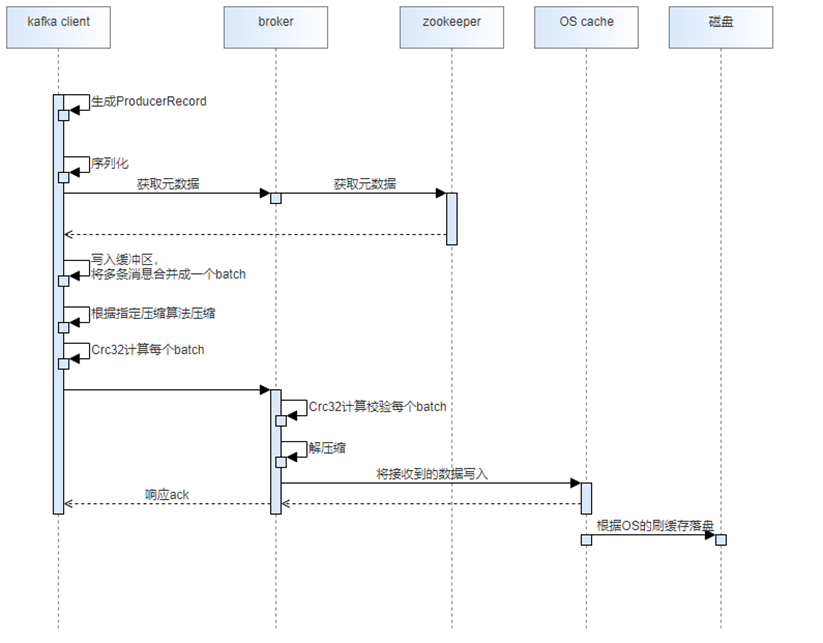
Kafka生产消息端到端流程如上图所示:
1. 客户端将生产消息封装成ProducerRecord并序列化
2. 通过zookeeper获取元数据信息决定写入partition
3. 将多条消息合并写入缓冲区
4. 到达缓冲区大小或是最大等待时间后,触发发送机制
5. 根据配置的压缩算法以batch粒度进行压缩并计算其Crc32的值附加在每个batch上
6. broker接收到batch后进行Crc32计算校验,判断消息的完整性,并解压缩逐条进行校验
7. 校验通过后,将接收到的压缩数据落盘持久化
3.2 优化分析
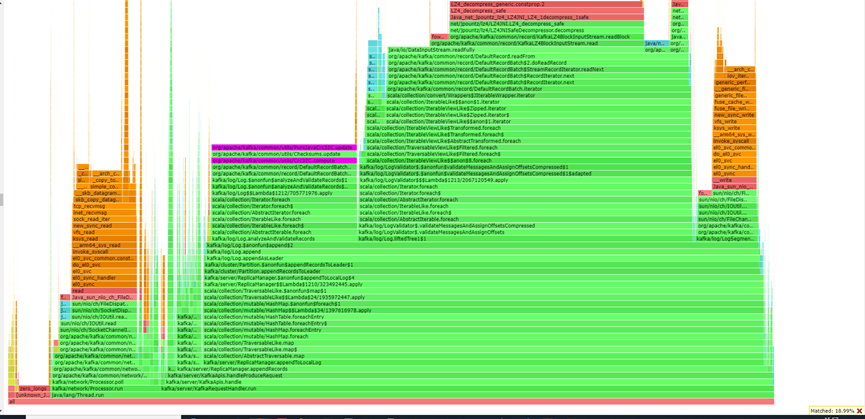
上图为XX客户现场用例的火焰图,识别到主要的热点函数为Crc32校验、LZ4解压缩和网络read系统调用和fuse write系统调用,其中软件层面可做的优化即Crc32校验和LZ4解压缩。
3.2.1 Crc32
性能分析显示,Crc32校验计算耗时占比达19%,成为系统关键性能瓶颈之一。通过全链路时序分析可以明确,Crc32校验贯穿Kafka消息处理全流程,包括:
l 客户端消息生产阶段
l 服务端broker消息接收阶段
这使得Crc32校验优化具有端到端的性能提升价值
通过火焰图堆栈定位源码识别到当前Kafka用于计算Crc32的类为PureJavaCrc32C,该类执行Crc32计算部分是纯Java代码实现的,Java由于是解释性语言,执行效率对比C语言这些更底层的语言性能要差,当前鲲鹏社区提供了经过深度优化的Crc32实现,具备以下核心优势:
1. C 语言通常比 Java 运行得更快,特别是在处理底层算法时,可以利用 C 语言的底层优化来提高性能,尤其生产者测试会涉及到大量Crc32计算,累加提升会更明显
2. JNI调用依赖不同平台的本地代码,当前使用存储算法加速库KSAL只能使能在鲲鹏上,可以构建护城河
3.2.2 LZ4解压缩
火焰图分析结果表明,在当前测试场景中,LZ4解压缩操作耗时占比超过20%,已成为主要性能瓶颈。通过火焰图分析和源码跟踪,我们发现Kafka通过KafkaLZ4BlockInputStream和KafkaLZ4BlockOutputStream两个核心类来调用底层的LZ4本地库(native库)实现解压缩功能,流程如下图所示。
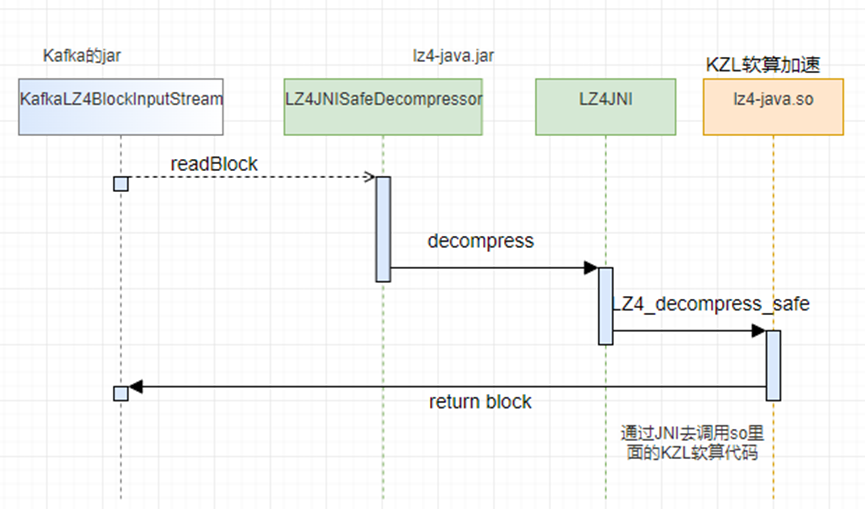
鲲鹏社区提供的专用加速库KZL针对LZ4算法在鲲鹏架构上进行了深度优化。通过将标准LZ4本地库替换为鲲鹏加速库KZL版本,可以显著提升LZ4解压缩在鲲鹏服务器上的执行效率。该优化方案具有以下独特优势:
1. 性能提升:专为鲲鹏架构优化的算法实现,解压缩效率显著提高
2. 技术壁垒:加速库仅支持鲲鹏平台,形成特有的性能优势护城河
3. 无缝集成:保持原有API接口不变,确保系统兼容性
4 集成方案分析
4.1 Crc32
4.1.1 Kafka原生Crc32流程分析
通过源码分析,内部Crc32具体计算流程如下图
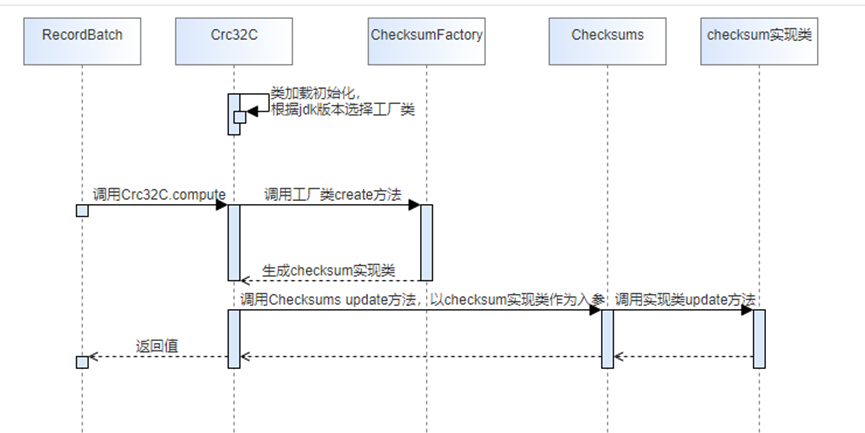
代码中未发现通过配置决定使用类的相关代码,只能侵入式修改Crc32部分的代码。
从上图流程分析,集成存储算法加速库到Kafka计算Crc32的部分,存在以下多种修改方式:
1. Crc32C类加载初始化时选择自定义工厂类
2. 工厂类创建对象的时候加入自定义逻辑
3. 修改CheckSum实现类的计算逻辑
4.1.2 KSAL存储算法库集成分析
为了尽可能保留原生的类不被修改,并且代码合理结构清晰,修改Crc32C类加载初始化的逻辑最为合适。其代码如下图所示,该部分存在两个分支:
1. JDK版本高于8时,生成的CheckSum实现类为java.util.zip.CRC32C
2. 其余低版本JDK为Kafka自己实现的org.apache.kafka.common.utils.PureJavaCrc32C
为了集成存储算法加速库进去,在这里新增一个分支,将工厂类赋值为使用集成存储算法加速库的CheckSum工厂类,分支判断流程如下图所示,通过判断架构决定是否使用KSAL存储算法加速库,并在加载失败时回退到原生流程,保证兼容性和健壮性
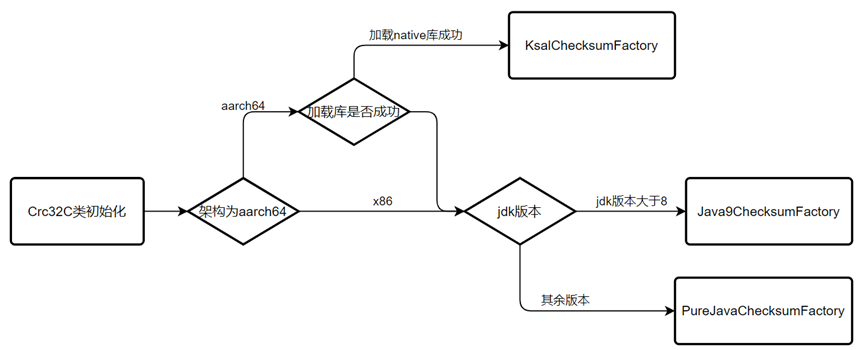
4.1.3 KSAL存储算法库使用分析
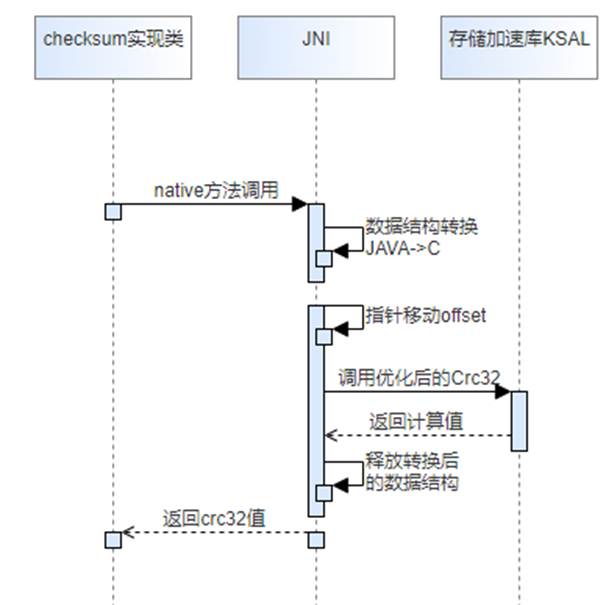
结合流程分析,当存在需要计算Crc32值的操作时,会调用该工厂类创建一个CheckSum实现类(对于当前KSAL的实现类应集成了JNI调用存储算法加速库),然后使用该实现类去调用算法加速库,从而实现端到端的流程使能KSAL加速库。
使用流程图如下所示,这块使用主要涉及两部分:
1. JNI调用相关流程,包括数据结构的转换、内存的分配和释放
2. 调用KSAL存储算法加速库接口
4.2 LZ4解压缩
LZ4压缩算法在开源社区中有两个仓库,一个是C代码的lz4仓,另一个是Java代码的lz4-java仓。Java代码或者Java组件能够直接调用lz4-java.jar来使能LZ4算法。Kafka组件通过KafkaLZ4BlockInputStream和KafkaLZ4BlockOutputStream类来调用lz4-java-1.7.1.jar,来使能LZ4压缩算法。

lz4-java仓在编译jar包时,会直接将so打包进jar里面,所以使能KZL软件包时,需要将KZL的代码替换原生LZ4的代码,再进行编译即可。