


OpenSSH升级到7.4后建立连接时延变长的问题定位
发表于 2025/05/15
0
作者 | 吴亦航
问题描述
某应用软件使用SFTP协议进行文件传输,旧操作系统的OpenSSH版本为5.3。迁移升级到新操作系统后,传输文件的耗时劣化40%,初步分析为SSH版本影响。新操作系统的OpenSSH版本为7.4,手动降级到5.3后,性能恢复。
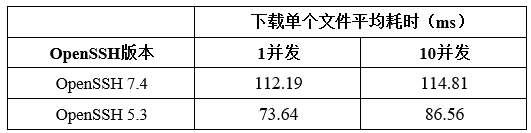
问题分析
主要有以下思路
1. SFTP是基于SSH的,即进行SFTP文件传输时需建立SSH连接,分析性能差异是在SFTP层面还是在SSH层面;
2. 对比不同SSH版本,测试时的热点、火焰图;
3. 分析OpenSSH 7.4和5.3之间加密算法的区别;
4. 走读SFTP相关代码,分析调用链。
分析性能差异是在SFTP层面还是在SSH层面
用libssh2库编写测试程序,对比OpenSSH 7.4和5.3在以下两个测试的性能差别:
1. 建立SSH连接后执行一次echo 1就断开
2. 建立SSH连接后再建立SFTP会话后断开
发现执行echo 1的测试也复现了同等的性能差异。说明该场景性能差异在SSH层面而不在SFTP层面。
对比不同SSH版本,测试时的热点、火焰图
使用perf抓取OpenSSH 7.4和5.3服务端、客户端在压测时的热点,并生成火焰图。发现服务端调用栈区别很大,无法直接看出性能差异,且热点也无明显线索。调用栈的差异主要由两个SSH版本使用不同的加解密、公钥私钥算法引入。
分析OpenSSH 7.4和5.3之间加密算法的区别
通过以下代码打印SSH会话使用的各个算法。
libssh2_session_method_pref(session, LIBSSH2_METHOD_KEX, "diffie-hellman-group-exchange-sha256");
libssh2_session_method_pref(session, LIBSSH2_METHOD_HOSTKEY, "ssh-rsa");
libssh2_session_method_pref(session, LIBSSH2_METHOD_MAC_CS, "hmac-sha1");
libssh2_session_method_pref(session, LIBSSH2_METHOD_MAC_SC, "hmac-sha1");
std::cout << "LIBSSH2_METHOD_KEX: " << libssh2_session_methods(session, LIBSSH2_METHOD_KEX) << std::endl;
std::cout << "LIBSSH2_METHOD_HOSTKEY: " << libssh2_session_methods(session, LIBSSH2_METHOD_HOSTKEY) << std::endl;
std::cout << "LIBSSH2_METHOD_CRYPT_CS: " << libssh2_session_methods(session, LIBSSH2_METHOD_CRYPT_CS) << std::endl;
std::cout << "LIBSSH2_METHOD_CRYPT_SC: " << libssh2_session_methods(session, LIBSSH2_METHOD_CRYPT_SC) << std::endl;
std::cout << "LIBSSH2_METHOD_MAC_CS: " << libssh2_session_methods(session, LIBSSH2_METHOD_MAC_CS) << std::endl;
std::cout << "LIBSSH2_METHOD_MAC_SC: " << libssh2_session_methods(session, LIBSSH2_METHOD_MAC_SC) << std::endl;
std::cout << "LIBSSH2_METHOD_COMP_CS: " << libssh2_session_methods(session, LIBSSH2_METHOD_COMP_CS) << std::endl;
std::cout << "LIBSSH2_METHOD_COMP_SC: " << libssh2_session_methods(session, LIBSSH2_METHOD_COMP_SC) << std::endl;
std::cout << "LIBSSH2_METHOD_LANG_CS: " << libssh2_session_methods(session, LIBSSH2_METHOD_LANG_CS) << std::endl;
std::cout << "LIBSSH2_METHOD_LANG_SC: " << libssh2_session_methods(session, LIBSSH2_METHOD_LANG_SC) << std::endl;
得出客户端使用libssh2 1.9.0连接服务端OpenSSH 5.3和7.4时,SSH会话默认使用以下算法。

由于OpenSSH 7.4和5.3的算法集差异较大,尝试拉齐两边的加解密算法。手动令客户端在连OpenSSH 7.4时使用与5.3一样的算法,测试后发现OpenSSH 7.4的性能更差了。
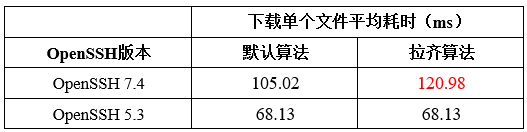
观察火焰图,调用栈相近。由于拉齐算法后,OpenSSH 7.4的性能更差,判断该场景的性能差距与SSL加密算法无关。
走读代码和插桩分析
继续细化分析是SSH连接的哪一段耗时提升了。思路是打开libssh2客户端和OpenSSH服务端最详尽级别日志,若粒度不够细,插桩OpenSSH打点分析每个阶段的耗时。
OpenSSH sshd最详尽级别的日志是DEBUG3,开启方法为在/usr/local/etc/sshd_config文件调整LogLevel:
LogLevel DEBUG3实测DEBUG3级别日志在这个场景对性能有15%的影响,并且该日志级别仍比较粗,没有时间戳。于是手动添加时间戳打印代码。
// In log.c
void pp(const char *fmt, ...) {
va_list args;
va_start(args, fmt);
struct timeval tv;
gettimeofday(&tv, NULL);
uint64_t usec = tv.tv_sec * 1000000 + tv.tv_usec;
pid_t pid = getpid();
char s[512];
sprintf(s, "%ld - %ld - %s", usec, pid, fmt);
error(s, args);
}
// In log.h
void pp(const char *, ...) __attribute__((format(printf, 1, 2)));在多个位置打点,发现SSH 7.4服务端收到客户端发送的SSH2_MSG_CHANNEL_OPEN_CONFIRMATION与前面间隔了41ms,而SSH 5.3不存在这个时间间隔。于是怀疑是客户端进行某些处理时慢了41ms。
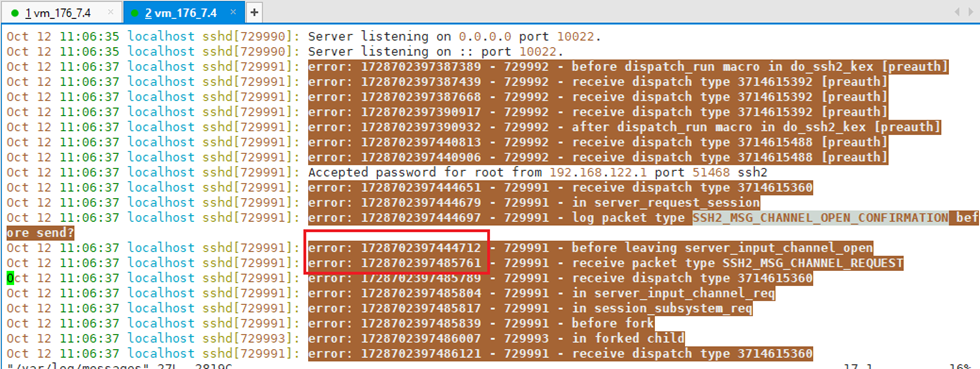
在libssh2客户端开启TRACE级别日志。libssh2的低级别日志需要在编译时使能:
cmake -DENABLE_DEBUG_LOGGING=ON -DBUILD_SHARED_LIBS=ON -B bld
cmake --build bld -j
cmake --build bld --target install
在客户端代码使能TRACE级别日志。
libssh2_trace(session, LIBSSH2_TRACE_SOCKET | LIBSSH2_TRACE_SOCKET | LIBSSH2_TRACE_KEX | LIBSSH2_TRACE_AUTH | LIBSSH2_TRACE_CONN);通过日志发现使用SSH 7.4时,客户端从服务端多接收了一个包,并且在这里能观察到40ms耗时。这个包在SSH 5.3中不存在。

通过关键词00@openssh搜索源码,找到SSH 7.4的sshd有一个notify_hostkeys函数调用,而这个函数在SSH 5.3中也是没有的。
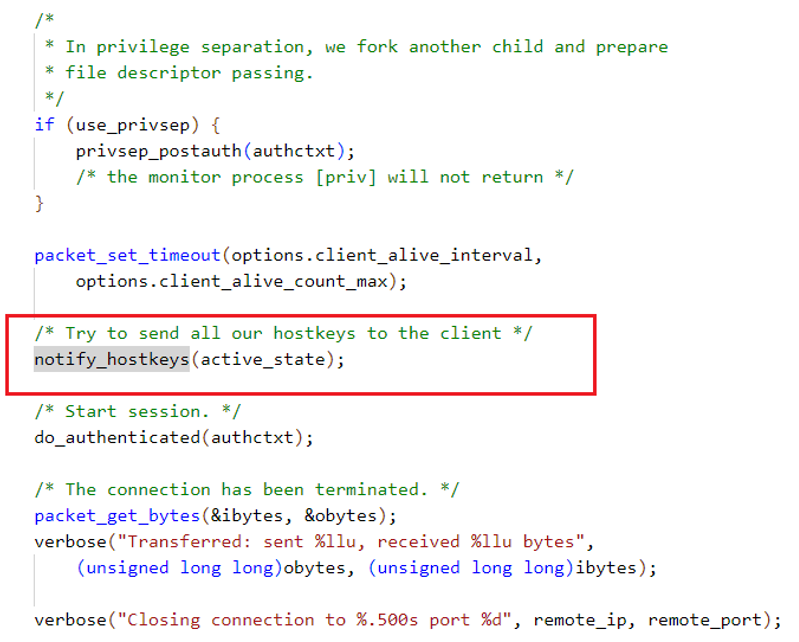
去掉该函数后,40ms额外耗时消失,SSH 7.4性能提升至与SSH 5.3一致。
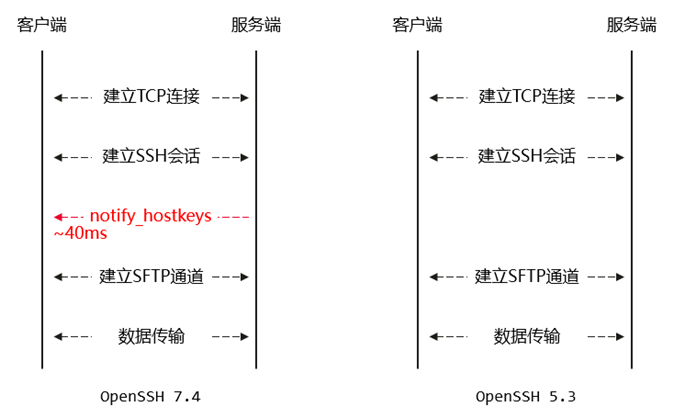
SSH公钥轮换机制
在OpenSSH源码找到与notify_hostkeys相关的Commit。
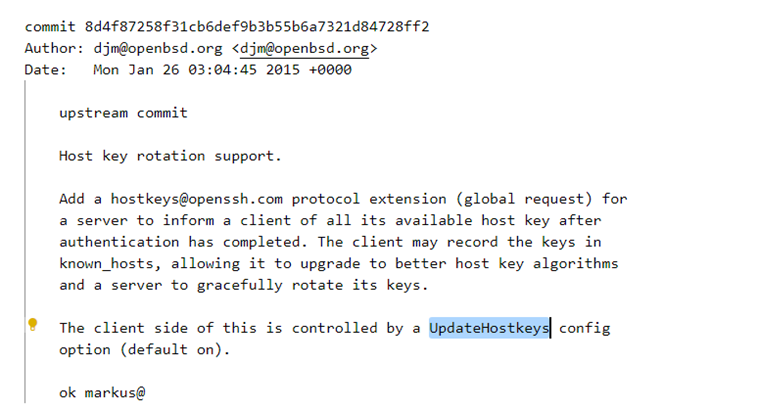
查阅资料得知,公钥轮换机制(Host Key Rotation)是OpenSSH 6.8引入的特性。在该机制下,服务端与客户端建立SSH连接后,会将自己的所有公钥(通常在/etc/ssh目录下)发送给客户端;客户端收到后,会将这些公钥保存下来(如在known_hosts文件中)。以后客户端与服务端再次建立连接时,可以识别到服务端用了新的公钥,并且可以主动选用更安全的加密算法。该机制从安全角度支持了服务端定期更换公钥(同时也需SSH客户端支持)。经排查,目前所有OpenSSH版本均无法通过配置项关闭这个功能。
如果业务场景不需要公钥轮换机制带来的安全性(如内网使用),可以关闭该机制换来性能提升,如并发在单次连接传单个小文件的业务模型。这种情况下单次SFTP连接的平均时间是百毫秒级别,而公钥轮换机制引入的开销是十毫秒量级,不可忽视。
为什么公钥轮换机制会引入40ms的延时?
TCP Delayed ACK和Nagle算法
TCP Delayed ACK
Delayed ACK机制是指,接收端在收到对端的报文后,对该报文的ACK会与本端需要发送的数据组成一个报文一次性发送。本端若没有数据要发送,则延迟一定时间后(如40ms)再单独发一个长度为0的ACK报文给对端。该机制能有效降低网络上的TCP报文总数,减少拥塞,提高整体网络性能。
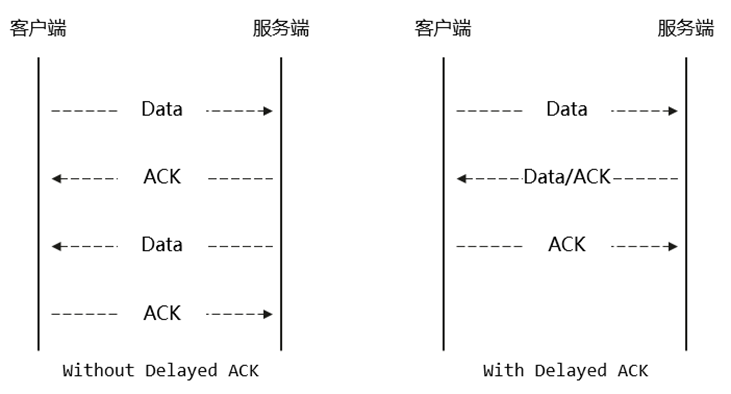
Nagle算法
Nagle算法是指本端在发送数据时,如果本端有已发送但未被对端ACK的报文,且要发送的数据量小于MSS,则先将这些待发送的数据缓存起来。等ACK收到后,或缓存累积的数据量达到一个MSS时,再将数据形成报文发送出去。该算法也能减少网络上的TCP报文总数,提升有效吞吐量。
if there is new data to send then
if the window size ≥ MSS and available data is ≥ MSS then
send complete MSS segment now
else
if there is unconfirmed data still in the pipe then
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if对性能的影响
这两个机制的本意是好的,但在某些场景下,他们共同作用会引入不可忽视的时延。在SSH场景中,客户端与服务端建立连接时,服务端因公钥轮换机制会将自己的公钥发出去,但客户端对此没有需要回复的消息。由于TCP Delayed ACK机制,客户端会等40ms再回复ACK。与此同时,服务端要发送的下一个数据是一个远小于MSS的报文,因Nagle算法,服务端不会将该报文发出去,直至收到客户端对上一个报文的ACK。于是客户端与服务端都干等40ms。
为什么是40ms?这是因为客户端的最小等待时延是由内核的TCP_DELACK_MIN参数控制。以5.10内核为例,相关代码为:
#define TCP_DELACK_MAX ((unsigned)(HZ/5)) /* maximal time to delay before sending an ACK */
#if HZ >= 100
#define TCP_DELACK_MIN ((unsigned)(HZ/25)) /* minimal time to delay before sending an ACK */
#define TCP_ATO_MIN ((unsigned)(HZ/25))
#else
#define TCP_DELACK_MIN 4U
#define TCP_ATO_MIN 4U
#endif此处HZ是系统定时器硬件向内核发出中断的频率。可以通过以下命令查看系统配置的HZ值。
grep CONFIG_HZ= /boot/config-`uname -r`在本机上,HZ是250,即中断产生周期为4ms。由上面TCP_DELACK_MIN宏得知,TCP Delayed ACK的最短延迟时间为10个周期(250 / 25),即40ms。
如何解决性能问题
TCP Delayed ACK机制和Nagle算法交互作用而产生性能问题是一个已经被讨论过的话题。有两种解决方法:
1. 禁用TCP Delayed ACK机制:在socket设置TCP_QUICKACK选项,令本端在收到数据后立即发送ACK,而不是等到自己有数据的时候发送。或,
2. 禁用Nagle算法:在socket设置TCP_NODELAY选项,令本端有数据发送时,立即形成报文发送,而不用管之前发送的报文有没有被ACK。
通常,应用在面临TCP Delayed ACK和Nagle算法共同作用导致性能下降的问题时,会禁用Nagle算法,如nginx配置文件中的tcp_nodelay选项默认是使能的。
在本项目的SSH场景中,通过在sshd.c增加如下代码禁用服务端Nagle算法。经测试,性能与关闭公钥轮换机制一致。
// Add to line 127#include <netinet/tcp.h>// Add to line 2122setsockopt(sock_in, SOL_TCP, TCP_NODELAY, &on, sizeof(on));
使用tcpdump抓包对比有无Nagle算法的情况。
使能Nagle算法(默认):

禁用Nagle算法(调优):

由此可见禁用Nagle算法能减少40ms的等待开销。