


基于N台香橙派鲲鹏Pro开发板的并行矩阵运算
发表于 2025/05/27
0
作者|楼佳明
1.实验环境
1.1 环境介绍
1.1.1 实验环境说明
- (1)2台香橙派鲲鹏 Pro开发板、openEuler 22.03操作系统;
- (2)安装mpich4.2.2;
- (3)安装OpenBLAS-0.3.8。
1.1.2 实验设备介绍
关键配置如下表所示
资源 | 说明 |
香橙派鲲鹏Pro开发板2台 | 规格:4核鲲鹏CPU,16G内存 |
以太网线3根 | PC和开发板通过以太网口连接 |
PC(个人电脑)1台 | 通过PC的命令窗口登录到开发板 |
网络集线器或者交换机 | 1台 |
用户及密码 | root用户对应密码(openEuler) |
1.1.3 香橙派鲲鹏Pro简介
香橙派鲲鹏Pro采用4核64位处理器+AI处理器,集成图形处理器,支持8-12TOPS AI算力,拥有8GB/16GB LPDDR4X,可以外接32GB/64GB/128GB/256GB eMMC模块,支持双4K高清输出。香橙派鲲鹏 Pro引用了相当丰富的接口,包括两个HDMI输出、GPIO接口、Type-C电源接口、支持SATA/NVMe SSD 2280的M.2插槽、TF插槽、千兆网口、两个USB3.0、一个USB Type-C 3.0、一个Micro USB(串口打印调试功能)、两个MIPI摄像头、一个MIPI屏等,预留电池接口等。香橙派鲲鹏 Pro支持openEuler操作系统,满足大多数AI算法原型验证、推理应用开发的需求,同时可以为各种应用场景提供更高效的算力,如云计算、大数据、分布式存储、高性能计算等。
官方资料下载:http://www.orangepi.cn/html/hardWare/computerAndMicrocontrollers/service-and-support/Orange-Pi-kunpeng.html
1.1.4 软件工具介绍
软件方面,本实验需要一台终端电脑与鲲鹏开发板连接以输入操作命令。对于Windows 10 、11/ macOS / Linux,我们可以用命令行工具ssh完成这个过程。
如果在有些Windows系统下不能运行ssh工具,也可以使用Putty或者MobaXterm工具软件。其中Putty工具的推荐下载地址:
https://hcia.obs.cn-north-4.myhuaweicloud.com/v1.5/putty.exe
MobaXterm的免费版是开源的,您可以从MobaXterm 官方站:https://mobaxterm.mobatek.net/ 下载开源版本。下文若无特殊说明,均以命令行工具ssh为例进行讲解。
1.2 连接并登录到香橙派鲲鹏 Pro开发板
1.2.1 实验设备的连接
本案例PC通过以太网和开发板相连的方式进行连接。

1.2.1.1 单个开发板
本方式硬件连接如下所示:

使用网线连接PC和开发板,开发板插入网线,网线另一端连接PC,启动上电。

1.2.1.2 多个开发板连接
并行计算的实验需要使用至少2台开发板进行,本实验已2台开发板为例,介绍如何连接2台及以上的开发板。
设备连接图如下:
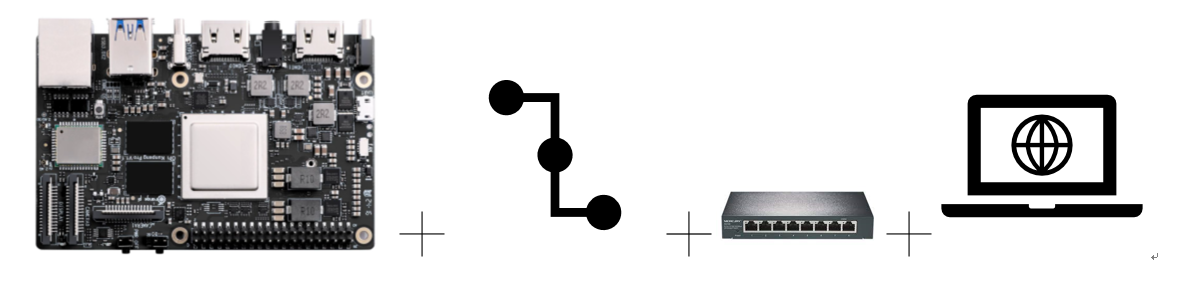
通过3根网线和hub(或者交换机)将个人pc和2台开发板连接在一起。(组成同一子网,注:如果个人pc没有水晶头的网口,还需要一个网口转换器)

1.2.1.3配置个人PC的网络设置
开发板通过网线和个人PC连接后,需要使开发板的ip地址和个人PC的以太网处于同一网段,才能实现网络互联。具体操作步骤如下:
步骤1 打开Windows设置
以window10为例配置个人PC的网络设置。
在PC上打开“开始”,单击“设置”按钮,进入“Windows 设置”界面:
步骤2 打开更改适配器选项
选择“网络和Internet”,单击“更改适配器选项”:

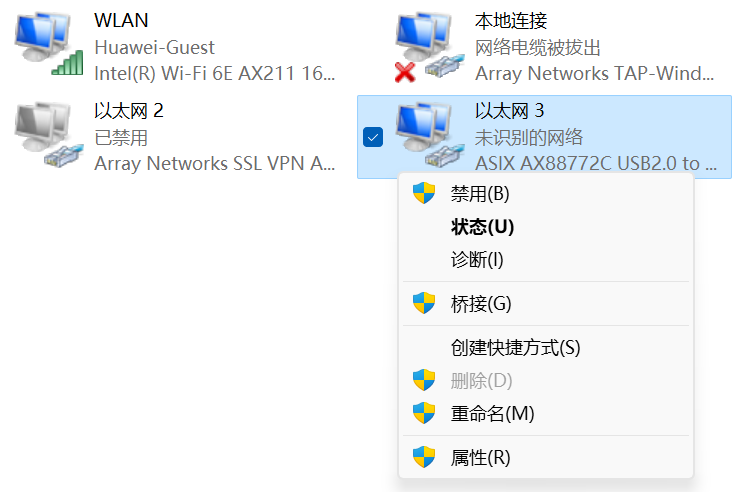
步骤3 打开连接网线对应的以太网属性
出现已连接的“以太网x”就是开发板网线连接接口,如下图中的“以太网3”,选中后右键打开,点击“以太网x”的属性;
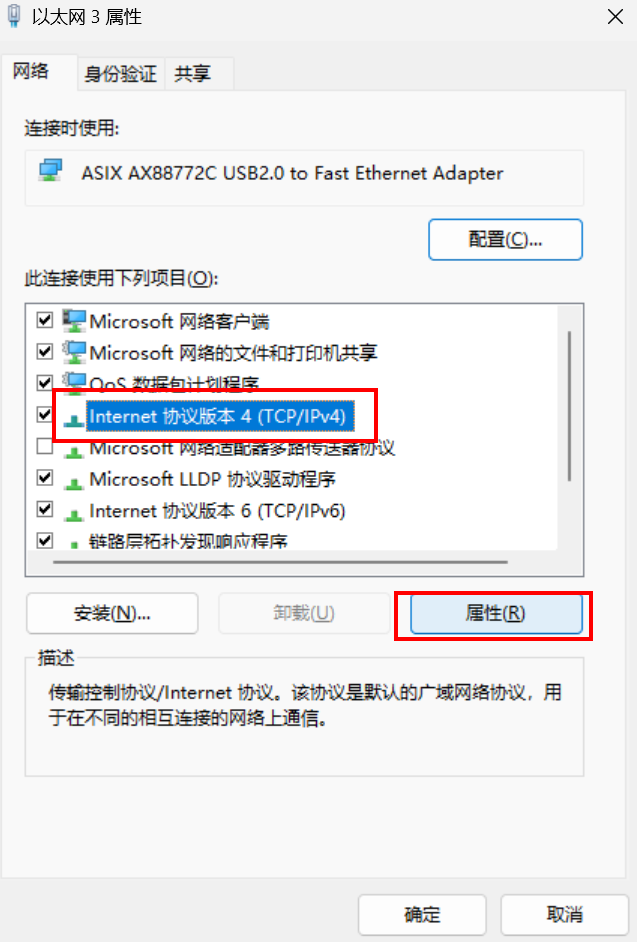
步骤4 修改IPV4属性
修改“Internet 协议版本 4(TCP/IPv4)”的属性,如下图:
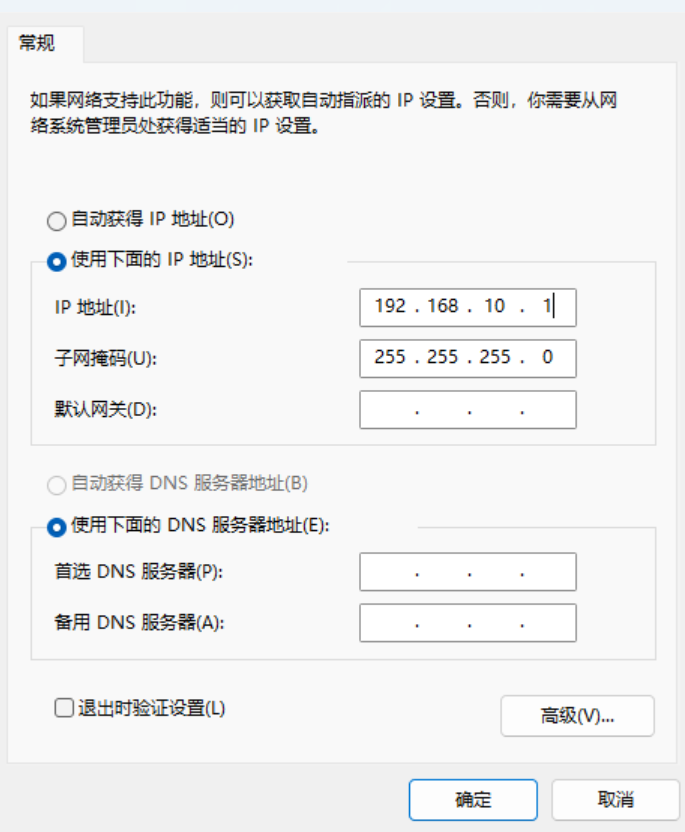
步骤5 设置ip和子网掩码
勾选“使用下面的 IP 地址”选项,填写IP地址(此处设置为192.168.10.1)和子网掩码,默认网关与DNS服务器地址为空,单击“确定”保存:
步骤6 验证
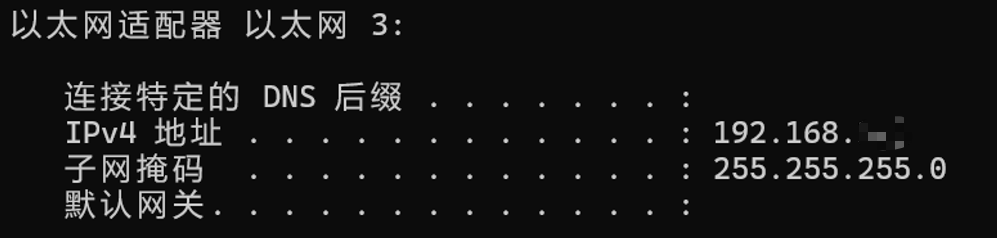
使用快捷键“Win+R”,在运行窗口输入cmd进入命令行窗口。输入ipconfig命令查询PC网口IP地址是否修改成功:
C:\Users\用户实际信息>ipconfig
1.2.2 登录开发板
1.2.2.1 通过cmd登录开发板
在客户端机器操作系统里的Console控制台或Terminal终端里运行ssh命令:
ssh root@ip以windows系统上的cmd为例,输入ssh root@192.168.10.x(需替换成自己开发板上的ip,香橙派鲲鹏 Pro开发板默认的ip为192.168.10.8。
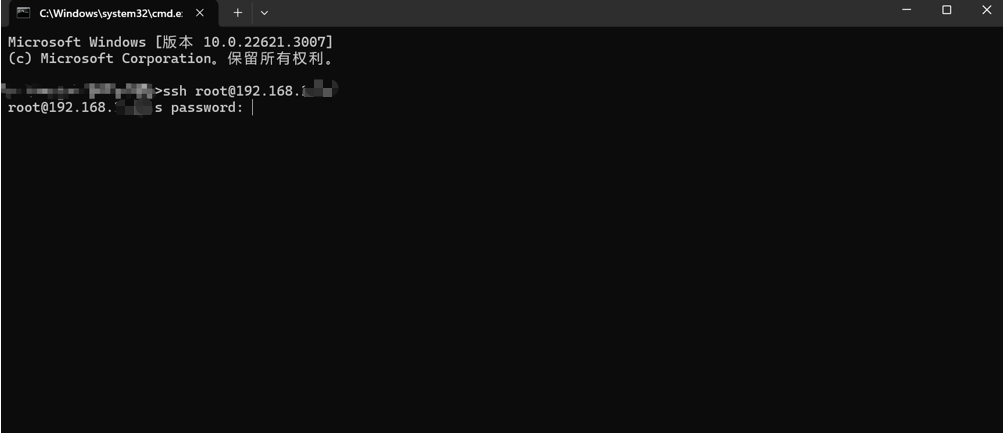
输入密码,默认开发板上root用户的密码为openEuler。登录成功后的界面如下所示:

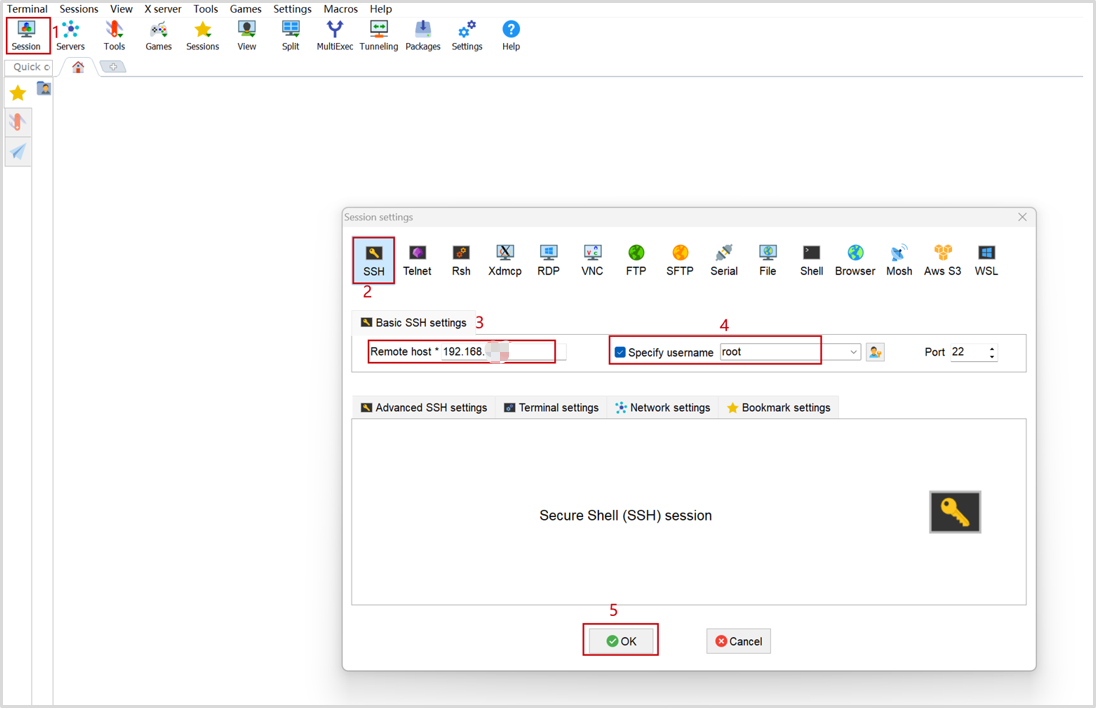
1.2.2.2 使用MobaXtrem的ssh登录开发板
远程登录IP为192.168.x.x,用户为root,密码为openEuler。
1.3 开发板网络连接
1.3.1 WIFI连接
步骤1 扫描WIFI热点
开发板上执行nmcli dev wifi 命令扫描周围的 WIFI 热点:
nmcli dev wifi下图以红框圈起来的Ljm_iPhone为例。
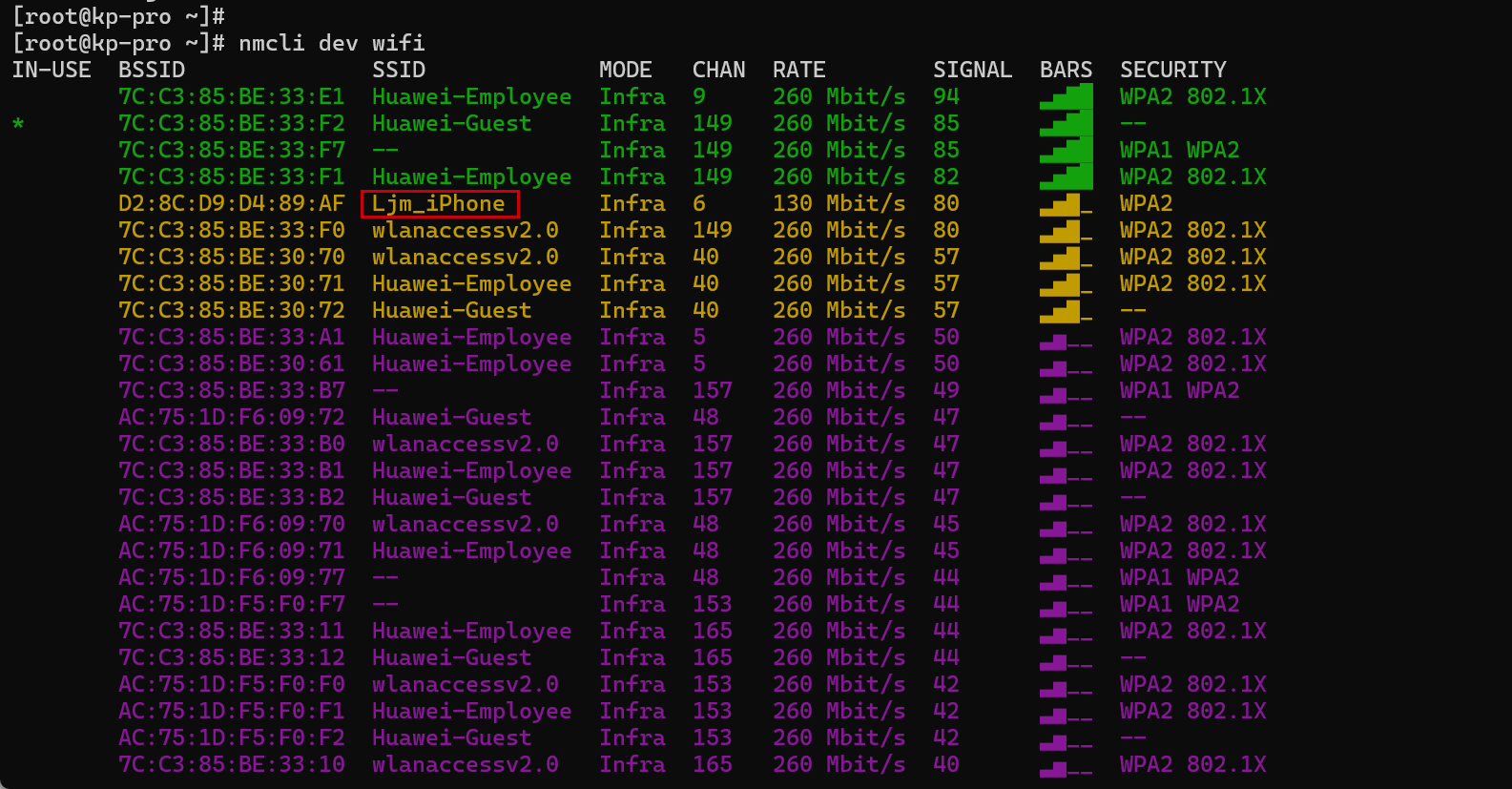
步骤2 连接指定WIFI
然后使用 nmcli 命令连接扫描到的 WIFI 热点,其中:
a. wifi_name 需要换成想连接的 WIFI 热点的名字。
b. wifi_passwd 需要换成想连接的 WIFI 热点的密码。
nmcli dev wifi connect wifi_name password wifi_passwd输入命令,以Ljm_iPhone为例,连接成功后输出:成功用 "wlan0ab877337-e465-440a-852d-c95ee6b5f4b0" 激活了设备 ""。

步骤3 测试WIFI是否连通
使用ping命令可以测试WIFI网络的连通性,ping命令可以通过Ctrl+C快捷键来中断运行。
ping www.hikunpeng.com -I wlan0输出结果如下图所示。
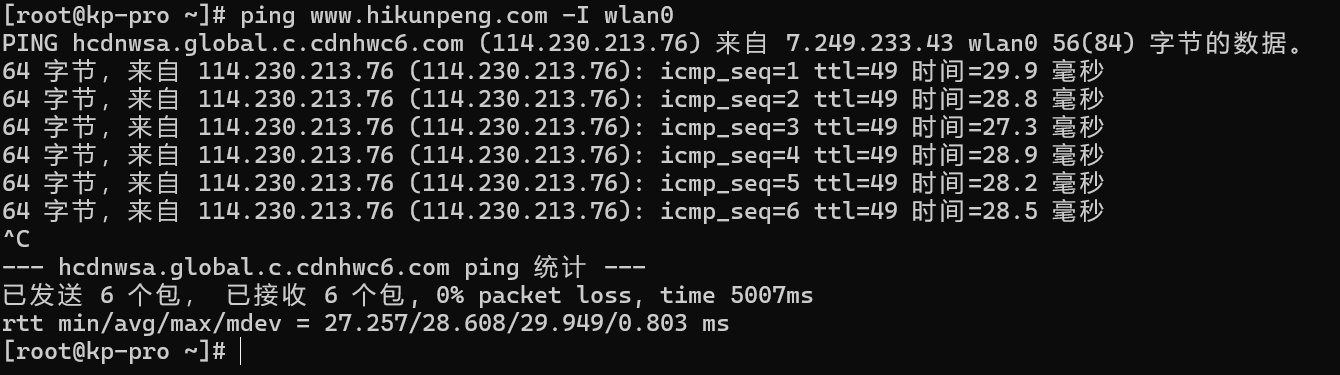
1.4 实验环境配置
1.4.1 配置免密登录环境(2台开发板都执行)
步骤1 登录开发板
连接好开发板后,使用SSH工具,输入私网IP、用户名和密码,或ssh usr@IP 即可登陆。
信息如下:(开发板默认ip为192.168.10.8,由于在同一子网内2台开发板的ip不能一样,因此需要修改ip地址)以如下ip为例。
|
主机名 |
私网ip |
|
root |
192.168.10.78 |
|
root |
192.168.10.178 |
具体如何如何修改开发板的静态ip操作如下:
(1)首先进入到network-scripts目录,并查看文件。
cd /etc/sysconfig/network-scripts/
ls
(2)使用vim修改ifcfg-eth0文件的内容。执行vim ifcfg-eth0命令,进入到vim的可视化模式,然后输入i进行编辑,修改完成后按Esc键退出编辑模式,最后输入:wq!保存并退出。
vim ifcfg-eth0内容如下,其中IPADDR字段为需要修改的静态ip地址。
TYPE=Ethernet
BOOTPROTO=static
NAME=eth0
DEVICE=eth0
IPADDR=192.168.10.x
NETMASK=255.255.255.0
ONBOOT=yes
(3)重启开发板
reboot步骤2 环境配置说明
为了防止大家的文件混乱,建议在每一台开发板下都建立个人账户,不建议统一使用root账户,下面以用户名openEuler 为例(openEuler为默认子用户,大家可以也可以创建自己的用户名),2台开发板名分别为kp-pro1, kp-pro2, 四台机器的ip为192.168.10.78, 192.168.10.178,以下所有的操作均在kp-pro1该台开发板上执行演示,环境配置时在每一台开发板上都需要重复执行(IP需要根据实际分配进行相应调整)。
首先需要修改主机名,将ip为192.168.10.78的开发板修改为kp-pro1, 将ip为192.168.10.178的开发板修改为kp-pro2。通过vim命令编辑修改etc目录下的hostname配置文件。
vim /etc/hostname
执行reboot命令重启开发板后,可以看到主机名已经成功刷新。
reboot
步骤3 查看openEuler用户
每台主开发板默认都已经有openEuelr用户了,使用以下命令查看:
ls /home说明:openEuler用户的密码默认为openEuler。

如果想要创建自己的用户。
每台开发板都需要在root账户下建立个人的账户,命令如下:
adduser zhangsan
passwd zhangsan
usermod -aG wheel zhangsan
说明:zhangsan密码建议设置成openEuler,和root用户的密码统一。
步骤4 免密配置
以下所有步骤在二台开发板上均需要重复执行。
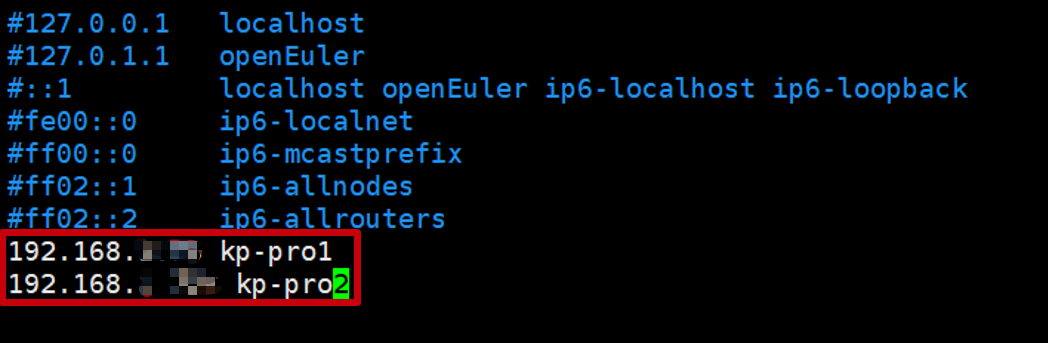
①配置2台开发板主机名和ip解析(各主机ip可以通过ifconfig或者控制台界面查看)
vim /etc/hosts删除文件原先本身的信息或者注释文件原先本身的信息并添加以下信息(注释的目的是因为会对本实验程序的运行产生报错):
192.168.10.78 kp-pro1
192.168.10.178 kp-pro2
添加完后,信息如下:
②登录新账户
首先退出root账户重新登陆到openEuler下:
su - openEuler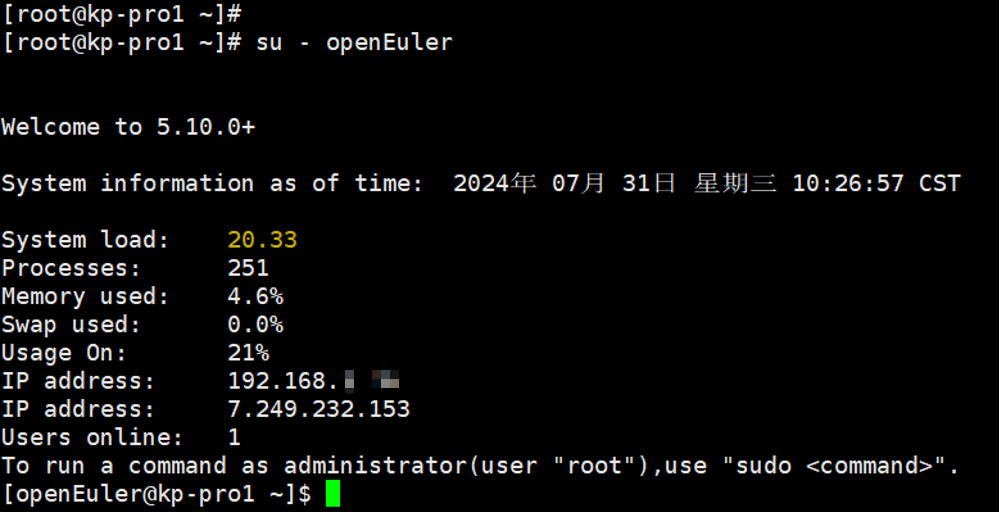
③本地生成秘钥
ssh-keygen -t rsa -b 4096 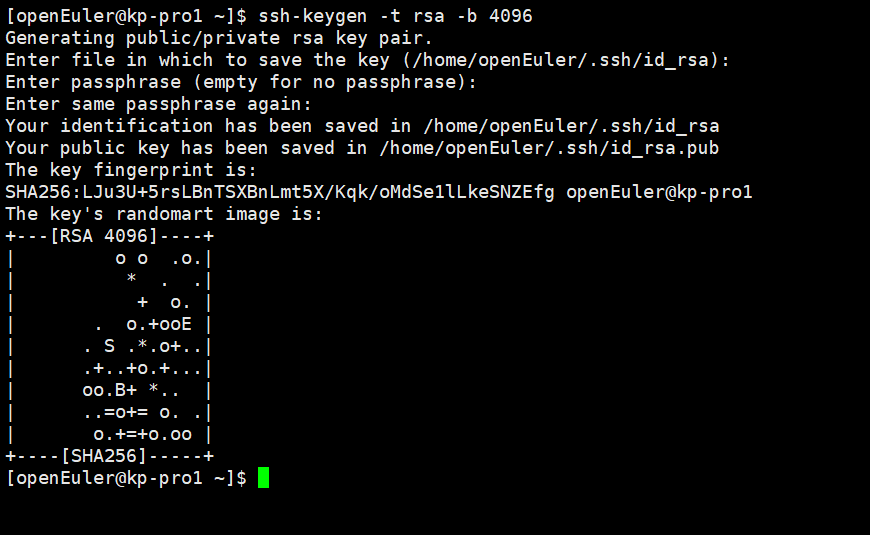
④添加公钥至2台开发板中
依次执行以下命令,根据提示先输入yes,然后输入openEuler用户的密码,默认为openEuler(注意密码输入不会显示)。
ssh-copy-id openEuler@kp-pro1
ssh-copy-id openEuler@kp-pro2
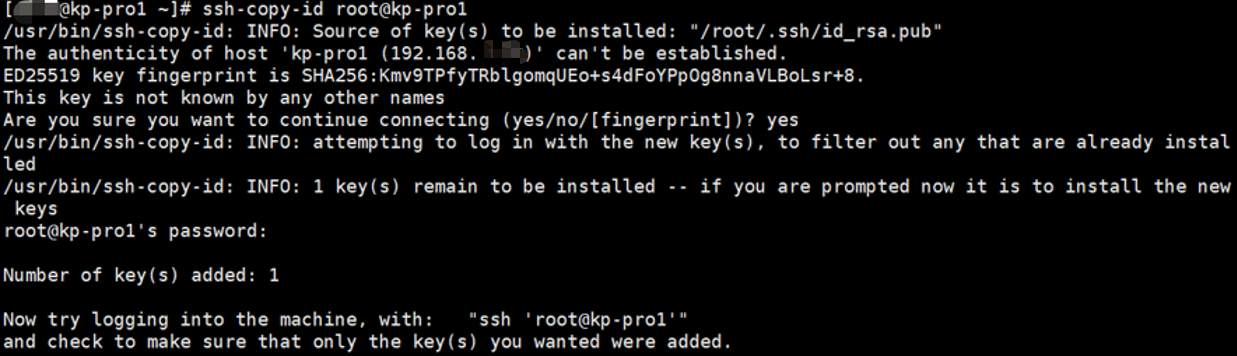
至此2台开发板间的免密登录已完成,可以通过ssh+开发板主机名称的方式,测试是否配置成功。如在主机kp-pro1中执行以下命令,能成功登录到kp-pro2,则说明说明免密登录配置正确,需要2台开发板都测试。
ssh kp-pro1
ssh kp-pro2
接下来需要从openEuler用户退回到root用户,执行并行计算实验所需软件包的安装。
exit
1.4.2 执行安装mpi(2台开发板都执行)
以下mpi的安装步骤需要以root用户登录,且每一台开发板上都需要执行。
步骤1 修改openEuler yum源文件
进入到源文件所在目录。
cd /etc/yum.repos.d/
cp openEuler.repo openEuler.repo.bak
使用vim命令打开openEuler.repo源文件。
vim openEuler.repo按shift+:进入到命令模式,输入%s/gpgcheck=1/gpgcheck=0/g,将所有gpgcheck=1改为0。最后按shift+:进入到命令模式,然后输入wq!保存并退出。
步骤2 依赖包的安装
使用yum命令进行安装。(前提是需要先配置好开发板的网络连接)
yum install -y gcc-gfortran 步骤3 检查gcc是否正常安装
执行以下命令,检查GCC10.3.1是否正常安装。
gcc -v若返回结果已包含gcc版本信息,说明gcc10.3.1已安装。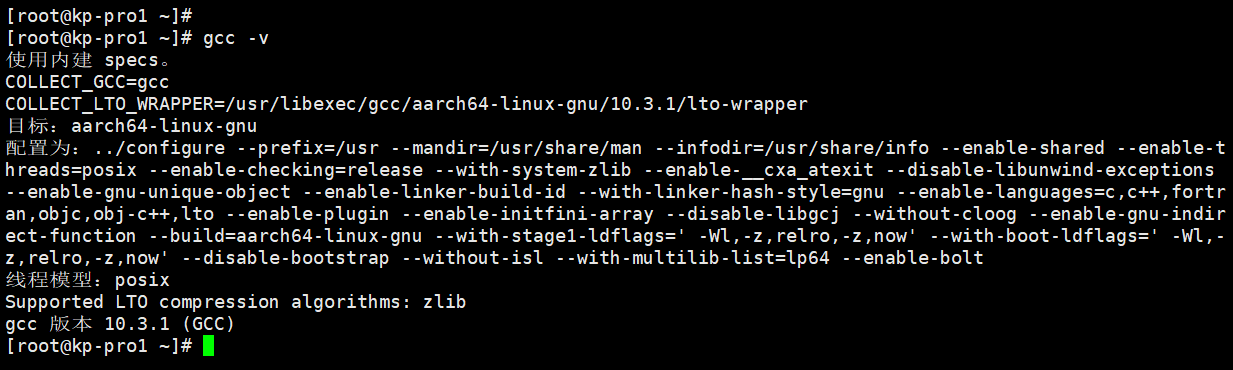
步骤4 下载软件包
创建并进入download目录。
cd /root
mkdir download
cd /root/download
执行以下命令,下载软件包。
wget https://www.mpich.org/static/downloads/4.2.2/mpich-4.2.2.tar.gz步骤5 编译安装mpi
执行以下命令,解压并进入到解压后的目录。
tar -zxvf mpich-4.2.2.tar.gz
cd mpich-4.2.2
执行以下命令,进行预编译。
./configure --prefix=/path/to/mpi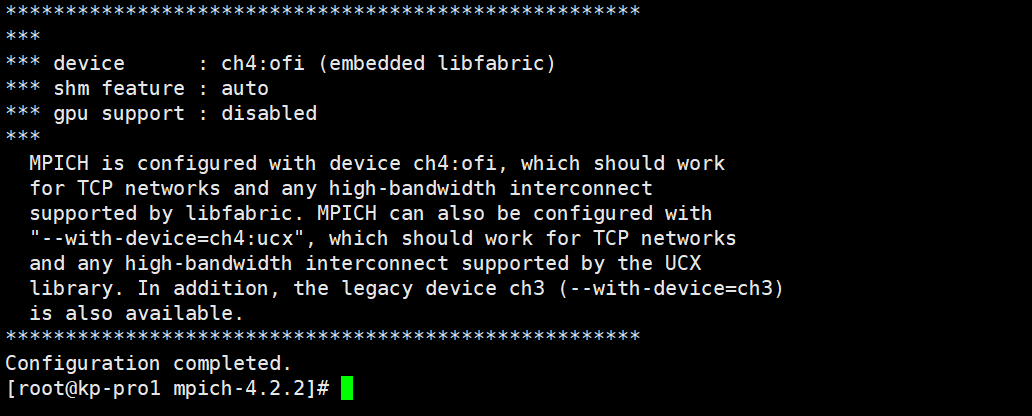
执行以下命令,进行编译安装。(由于香橙派鲲鹏 Pro开发板是4核的,make编译工程时一般会是CPU核心数的2 倍,8个任务线程进行编译)
make -j8
make install
修改mpi目录的文件夹权限。
chmod -R 777 /path/to/mpi步骤6 配置MPI的环境变量
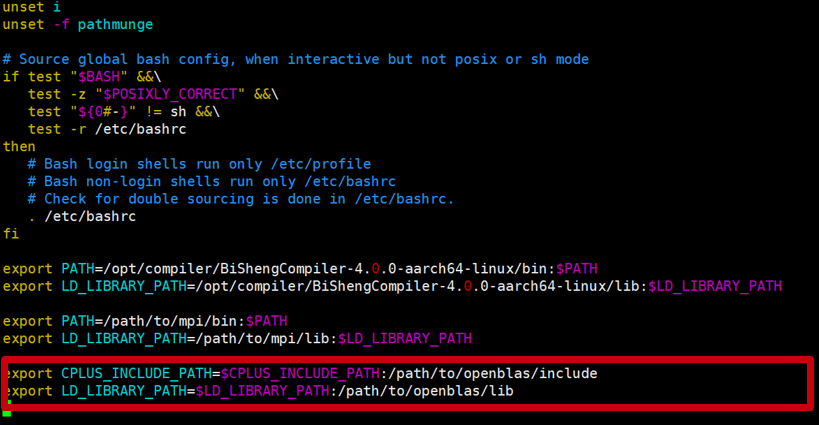
使用vim打开/etc/profile。
vim /etc/profile按“shift+g”拉到文件最下方,按“i”进入insert模式,添加export语句,完成后按esc键,最后输入“:wq”保存退出vim。
export PATH=/path/to/mpi/bin:$PATH
export LD_LIBRARY_PATH=/path/to/mpi/lib:$LD_LIBRARY_PATH
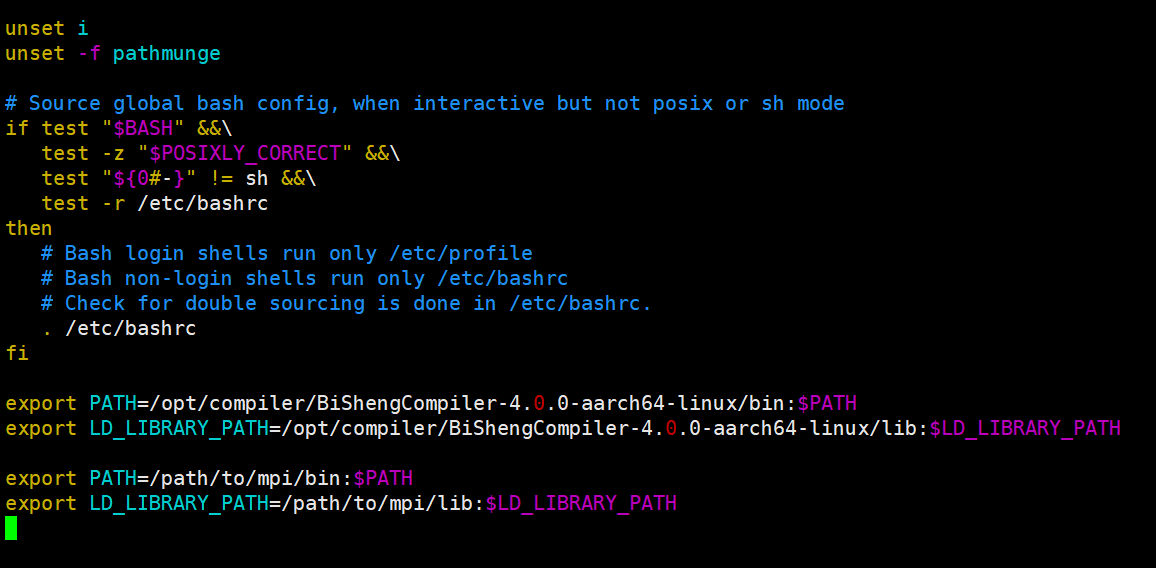
source profile文件,使得环境变量生效。
source /etc/profile步骤7 验证MPI的版本。
执行以下命令,进行安装后检查。
which mpirun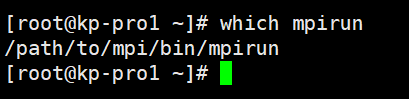
1.4.3 安装Openblas(2台开发板都执行)
以下Openblas的安装步骤需要以root用户登录,且在每一台主机上都执行。
步骤1 执行以下命令,获取包
cd /root/download
wget https://github.com/xianyi/OpenBLAS/archive/v0.3.8.tar.gz
步骤2 执行以下命令,进行编译
tar -zxvf v0.3.8.tar.gz && cd OpenBLAS-0.3.8
export CC=gcc CXX=c++ FC=gfortran
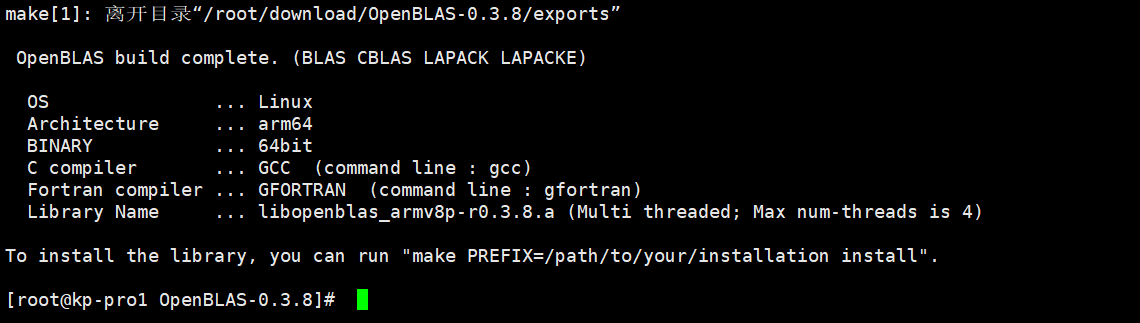
make -j8
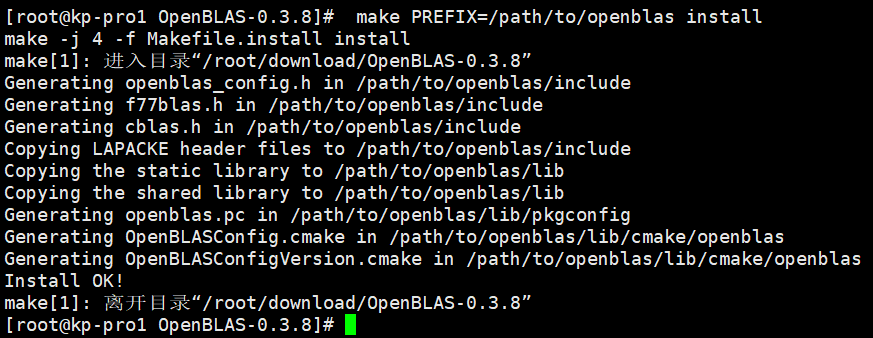
make PREFIX=/path/to/openblas install
步骤3 执行以下命令,完成安装
ln -s /path/to/openblas/lib/libopenblas.so /usr/lib/libopenblas.so修改openblas目录的文件夹权限。
chmod -R 777 /path/to/openblas步骤4 执行以下命令,配置OpenBLAS环境
vim /etc/profile添加下列内容
export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/path/to/openblas/include
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/openblas/lib
执行以下命令,使环境变量均生效(2台开发板都执行)
source /etc/profile
cd ~
至此实验环境搭建完成,接下来我们将在开发板上完成矩阵运算的实验。
2.矩阵运算
2.1 实验简介
本实验指导书通过在香橙派鲲鹏 Pro开发板上,编译运行矩阵乘法、池化、卷积等程序。完成实验操作后,读者会掌握简单的程序编写以及编译运行,集群MPI并行计算的配置以及加深对并行计算的了解。同时掌握如何在2台或者N台香橙派鲲鹏 Pro开发板上完成矩阵乘法、池化、卷积等操作的程序编写及编译运行。
2.2 实验任务操作指导
2.2.1 创建矩阵乘法源码
实验说明:随机生成大小为1024 *1024的矩阵作为输入,实现对应的矩阵乘法,矩阵乘法主要利用了矩阵划分方法,每一个工作节点的进程负责某一行和某一列的乘法,主节点则负责矩阵的划分以及分发到各个工作节点。
以下步骤均以openEuler用户执行。
执行以下命令,创建matrix目录存放该程序的所有文件, 并进入matrix目录(2台开发板都执行)
su - openEuler
mkdir /home/openEuler/matrix
cd /home/openEuler/matrix
执行以下命令,创建矩阵乘法源码gemm.cpp(2台开发板都执行)
vim gemm.cpp代码内容如下:
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <iostream>
#include "mpi.h"
// #include <cblas.h>
using namespace std;
// void CheckStatus(MPI_Status &status) {
// if (status.MPI_ERROR != MPI_SUCCESS) {
// cout << MPI::Get_error_class(status.MPI_ERROR);
// }
// }
void randMat(int rows, int cols, float *&Mat) {
Mat = new float[rows * cols];
for (int i = 0; i < rows; i++)
for (int j = 0; j < cols; j++)
Mat[i * cols + j] = 1.0;
}
void openmp_sgemm(int m, int n, int k, float *&leftMat, float *&rightMat,
float *&resultMat) {
// rightMat is transposed
#pragma omp parallel for
for (int row = 0; row < m; row++) {
for (int col = 0; col < k; col++) {
resultMat[row * k + col] = 0.0;
for (int i = 0; i < n; i++) {
resultMat[row * k + col] +=
leftMat[row * n + i] * rightMat[col * n + i];
}
}
}
return;
}
void blas_sgemm(int m, int n, int k, float *&leftMat, float *&rightMat,
float *&resultMat) {
// cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasTrans, m, k, n, 1.0, leftMat,
// n, rightMat, n, 0.0, resultMat, k);
}
void mpi_sgemm(int m, int n, int k, float *&leftMat, float *&rightMat,
float *&resultMat, int rank, int worldsize, bool blas) {
int rowBlock = sqrt(worldsize);
if (rowBlock * rowBlock > worldsize)
rowBlock -= 1;
int colBlock = rowBlock;
int rowStride = m / rowBlock;
int colStride = k / colBlock;
worldsize = rowBlock * colBlock; // we abandom some processes.
// so best set process to a square number.
float *res;
if (rank == 0) {
float *buf = new float[k * n];
// transpose right Mat
for (int r = 0; r < n; r++) {
for (int c = 0; c < k; c++) {
buf[c * n + r] = rightMat[r * k + c];
}
}
for (int r = 0; r < k; r++) {
for (int c = 0; c < n; c++) {
rightMat[r * n + c] = buf[r * n + c];
}
}
delete[] buf;
MPI_Request sendRequest[2 * worldsize];
MPI_Status status[2 * worldsize];
for (int rowB = 0; rowB < rowBlock; rowB++) {
for (int colB = 0; colB < colBlock; colB++) {
rowStride = (rowB == rowBlock - 1) ? m - (rowBlock - 1) * (m / rowBlock)
: m / rowBlock;
colStride = (colB == colBlock - 1) ? k - (colBlock - 1) * (k / colBlock)
: k / colBlock;
int sendto = rowB * colBlock + colB;
if (sendto == 0)
continue;
MPI_Isend(&leftMat[rowB * (m / rowBlock) * n], rowStride * n, MPI_FLOAT,
sendto, 0, MPI_COMM_WORLD, &sendRequest[sendto]);
MPI_Isend(&rightMat[colB * (k / colBlock) * n], colStride * n,
MPI_FLOAT, sendto, 1, MPI_COMM_WORLD,
&sendRequest[sendto + worldsize]);
}
}
for (int rowB = 0; rowB < rowBlock; rowB++) {
for (int colB = 0; colB < colBlock; colB++) {
int recvfrom = rowB * colBlock + colB;
if (recvfrom == 0)
continue;
MPI_Wait(&sendRequest[recvfrom], &status[recvfrom]);
MPI_Wait(&sendRequest[recvfrom + worldsize],
&status[recvfrom + worldsize]);
}
}
res = new float[(m / rowBlock) * (k / colBlock)];
} else {
if (rank < worldsize) {
MPI_Status status[2];
rowStride = ((rank / colBlock) == rowBlock - 1)
? m - (rowBlock - 1) * (m / rowBlock)
: m / rowBlock;
colStride = ((rank % colBlock) == colBlock - 1)
? k - (colBlock - 1) * (k / colBlock)
: k / colBlock;
if (rank != 0) {
leftMat = new float[rowStride * n];
rightMat = new float[colStride * n];
}
if (rank != 0) {
MPI_Recv(leftMat, rowStride * n, MPI_FLOAT, 0, 0, MPI_COMM_WORLD,
&status[0]);
MPI_Recv(rightMat, colStride * n, MPI_FLOAT, 0, 1, MPI_COMM_WORLD,
&status[1]);
}
res = new float[rowStride * colStride];
}
}
MPI_Barrier(MPI_COMM_WORLD);
if (rank < worldsize) {
rowStride = ((rank / colBlock) == rowBlock - 1)
? m - (rowBlock - 1) * (m / rowBlock)
: m / rowBlock;
colStride = ((rank % colBlock) == colBlock - 1)
? k - (colBlock - 1) * (k / colBlock)
: k / colBlock;
if (!blas)
openmp_sgemm(rowStride, n, colStride, leftMat, rightMat, res);
else
blas_sgemm(rowStride, n, colStride, leftMat, rightMat, res);
}
MPI_Barrier(MPI_COMM_WORLD);
if (rank == 0) {
MPI_Status status;
float *buf = new float[(m - (rowBlock - 1) * (m / rowBlock)) *
(k - (colBlock - 1) * (k / colBlock))];
float *temp_res;
for (int rowB = 0; rowB < rowBlock; rowB++) {
for (int colB = 0; colB < colBlock; colB++) {
rowStride = (rowB == rowBlock - 1) ? m - (rowBlock - 1) * (m / rowBlock)
: m / rowBlock;
colStride = (colB == colBlock - 1) ? k - (colBlock - 1) * (k / colBlock)
: k / colBlock;
int recvfrom = rowB * colBlock + colB;
if (recvfrom != 0) {
temp_res = buf;
MPI_Recv(temp_res, rowStride * colStride, MPI_FLOAT, recvfrom, 0,
MPI_COMM_WORLD, &status);
} else {
temp_res = res;
}
for (int r = 0; r < rowStride; r++)
for (int c = 0; c < colStride; c++)
resultMat[rowB * (m / rowBlock) * k + colB * (k / colBlock) +
r * k + c] = temp_res[r * colStride + c];
}
}
} else {
rowStride = ((rank / colBlock) == rowBlock - 1)
? m - (rowBlock - 1) * (m / rowBlock)
: m / rowBlock;
colStride = ((rank % colBlock) == colBlock - 1)
? k - (colBlock - 1) * (k / colBlock)
: k / colBlock;
if (rank < worldsize)
MPI_Send(res, rowStride * colStride, MPI_FLOAT, 0, 0, MPI_COMM_WORLD);
}
MPI_Barrier(MPI_COMM_WORLD);
return;
}
int main(int argc, char *argv[]) {
if (argc != 5) {
cout << "Usage: " << argv[0] << " M N K use-blas\n";
exit(-1);
}
int rank;
int worldSize;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &worldSize);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int m = atoi(argv[1]);
int n = atoi(argv[2]);
int k = atoi(argv[3]);
int blas = atoi(argv[4]);
float *leftMat, *rightMat, *resMat;
struct timeval start, stop;
if (rank == 0) {
randMat(m, n, leftMat);
randMat(n, k, rightMat);
randMat(m, k, resMat);
}
gettimeofday(&start, NULL);
mpi_sgemm(m, n, k, leftMat, rightMat, resMat, rank, worldSize, blas);
gettimeofday(&stop, NULL);
if (rank == 0) {
cout << "mpi matmul: "
<< (stop.tv_sec - start.tv_sec) * 1000.0 +
(stop.tv_usec - start.tv_usec) / 1000.0
<< " ms" << endl;
for (int i = 0; i < m; i++) {
for (int j = 0; j < k; j++)
if (int(resMat[i * k + j]) != n) {
cout << resMat[i * k + j] << "error\n";
exit(-1);
}
// cout << resMat[i * k + j] << ' ';
// cout << endl;
}
}
MPI_Finalize();
}
2.2.2 创建卷积操作源码
实验说明:实现卷积计算操作,卷积核的大小为4*4,卷积算法种类很多,在这里我们主要使用img2col算法来加速卷积算法,img2col算法原理为利用数据的重排布把卷积转化为矩阵乘法。
以下步骤均以openEuler用户执行。
执行以下命令,进入matrix目录(2台开发板都执行)
cd /home/openEuler/matrix执行以下命令,创建卷积操作源码conv.cpp(2台开发板都执行)
vim conv.cpp代码内容如下:
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <string.h>
#include <iostream>
#include "mpi.h"
#include <cblas.h>
#include <assert.h>
using namespace std;
void randMat(int rows, int cols, float *&Mat) {
Mat = new float[rows * cols];
for (int i = 0; i < rows; i++)
for (int j = 0; j < cols; j++) Mat[i * cols + j] = 1.0;
}
int get_steps(int kernel, int step, int len) {
if (kernel > len) return 0;
return (len - kernel) / step + 1;
}
inline void img2col_conv_kernel(int leftAnchorX, int leftAnchorY, int rightAnchorX,
int rightAnchorY, const int xKernel, const int yKernel, const int xStep,
const int yStep, float *&img, float *&kernel, float *&conv) {
int imgRows = rightAnchorX - leftAnchorX,
imgCols = rightAnchorY - leftAnchorY;
int convRows = get_steps(xKernel, xStep, imgRows);
int convCols = get_steps(yKernel, yStep, imgCols);
float *flattenImg = new float[convRows * convCols * xKernel * yKernel];
// #pragma omp parallel for
// for (int i = leftAnchorX; i < rightAnchorX - xKernel; i += xStep) {
// for (int r = 0; r < xKernel; r++) {
// for (int j = leftAnchorY; j < rightAnchorY - yKernel; j += yStep) {
// int pos = (i - leftAnchorX)/xStep * convCols + (j - leftAnchorY) / yStep;
// memcpy(&flattenImg[pos * xKernel * yKernel + r * yKernel], &img[(i + r) * imgCols + j], sizeof(float) * yKernel);
// }
// }
// }
// #pragma omp parallel for
// for (int i = 0; i < convRows * convCols; i++) {
// conv[i] = 0.0;
// for (int j = 0; j < xKernel * yKernel; j++) {
// conv[i] += flattenImg[i*xKernel*yKernel + j] * kernel[j];
// }
// }
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans, convRows * convCols, 1, xKernel * yKernel, 1.0, flattenImg, xKernel * yKernel, kernel, 1, 0.0, conv, 1);
// cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasTrans, convRows * convCols, 1, xKernel * yKernel, 1.0, flattenImg, xKernel * yKernel, kernel, convRows * convCols, 0.0, conv, 1);
delete[] flattenImg;
}
inline void naive_conv_kernel(int leftAnchorX, int leftAnchorY, int rightAnchorX,
int rightAnchorY, const int xKernel, const int yKernel, const int xStep,
const int yStep, float *&img, float *&kernel, float *&conv) {
int imgRows = rightAnchorX - leftAnchorX,
imgCols = rightAnchorY - leftAnchorY;
int convRows = get_steps(xKernel, xStep, imgRows);
int convCols = get_steps(yKernel, yStep, imgCols);
#pragma omp parallel for
for (int i = leftAnchorX; i < rightAnchorX - xKernel; i += xStep) {
for (int j = leftAnchorY; j < rightAnchorY - yKernel; j += yStep) {
// to[i / xStride * to_n + j] = 0.0;
int pos = (i - leftAnchorX)/xStep * convCols + (j - leftAnchorY) / yStep;
conv[pos] = 0.0;
for (int r = i; r < i + xKernel; r++)
for (int c = j; c < j + yKernel; c++) {
conv[pos] += img[r * imgCols + c] *
kernel[(r - i) * yKernel + (c - j)];
}
}
}
}
void mpi_convolution(int m, int n, int xKernel, int yKernel, int xStep,
int yStep, float *&img, float *&kernel, float *&conv,
int rank, int worldsize, bool img2col) {
const int total_xsteps = get_steps(xKernel, xStep, m);
const int total_ysteps = get_steps(yKernel, yStep, n);
const int xsteps_per_proc = total_xsteps / worldsize;
const int last_xsteps = total_xsteps - xsteps_per_proc * (worldsize - 1);
int steps;
if (rank == 0) {
MPI_Request *sendRequest = new MPI_Request[worldsize];
MPI_Status *status = new MPI_Status[worldsize];
for (int i = 1; i < worldsize; i++) {
steps = (i == worldsize - 1) ? last_xsteps : xsteps_per_proc;
MPI_Isend(&img[i * xsteps_per_proc * xStep * n],
(steps * xStep + xKernel - xStep) * n, MPI_FLOAT, i, 0,
MPI_COMM_WORLD, &sendRequest[i]);
}
for (int i = 1; i < worldsize; i++) {
MPI_Wait(&sendRequest[i], &status[i]);
}
delete[] sendRequest;
delete[] status;
} else {
MPI_Status status;
steps = (rank == worldsize - 1) ? last_xsteps : xsteps_per_proc;
img = new float[(steps * xStep + xKernel - xStep) * n];
MPI_Recv(img, (steps * xStep + xKernel - xStep) * n, MPI_FLOAT, 0, 0,
MPI_COMM_WORLD, &status);
conv = new float[steps * total_ysteps];
}
MPI_Barrier(MPI_COMM_WORLD);
steps = (rank == worldsize - 1) ? last_xsteps : xsteps_per_proc;
if (img2col)
img2col_conv_kernel(0, 0, steps * xStep + xKernel - xStep, n, xKernel, yKernel,
xStep, yStep, img, kernel, conv);
else
naive_conv_kernel(0, 0, steps * xStep + xKernel - xStep, n, xKernel, yKernel,
xStep, yStep, img, kernel, conv);
MPI_Barrier(MPI_COMM_WORLD);
if (rank == 0) {
MPI_Status status;
for (int i = 1; i < worldsize; i++) {
steps = (i == worldsize - 1) ? last_xsteps : xsteps_per_proc;
MPI_Recv(&conv[i * xsteps_per_proc * total_ysteps],
steps * total_ysteps, MPI_FLOAT, i, 0, MPI_COMM_WORLD,
&status);
}
} else {
MPI_Send(conv, steps * total_ysteps, MPI_FLOAT, 0, 0, MPI_COMM_WORLD);
}
MPI_Barrier(MPI_COMM_WORLD);
return;
}
int main(int argc, char *argv[]) {
if (argc != 4) {
cout << "Usage: " << argv[0] << " M N enabled-img2col";
exit(-1);
}
int rank;
int worldSize;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &worldSize);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int m = atoi(argv[1]);
int n = atoi(argv[2]);
int img2col = atoi(argv[3]);
int xKernel = 3, yKernel = 3;
int xStep = 1, yStep = 1;
float *Img, *Conv;
struct timeval start, stop;
if (rank == 0) {
randMat(m, n, Img);
randMat(get_steps(xKernel, xStep, m), get_steps(yKernel, yStep, n),
Conv);
}
float *Kernel = new float[xKernel*yKernel];
for (int i = 0; i < xKernel*yKernel; i++) Kernel[i] = 1.0;
gettimeofday(&start, NULL);
mpi_convolution(m, n, xKernel, yKernel, xStep, yStep, Img, Kernel, Conv,
rank, worldSize, img2col);
gettimeofday(&stop, NULL);
if (rank == 0) {
cout << "mpi convolution: "
<< (stop.tv_sec - start.tv_sec) * 1000.0 +
(stop.tv_usec - start.tv_usec) / 1000.0
<< " ms" << endl;
for (int i = 0; i < min(10, m); i++) {
for (int j = 0; j < min(10, n); j++)
cout << Conv[i * n + j] << ' ';
cout << endl;
}
}
delete[] Img;
delete[] Conv;
MPI_Finalize();
} 2.2.3 创建池化操作源码
实验说明:基于乘法的程序实现池化计算操作,池化使用的kernel大小为4*4,池化操作与卷积操作类似,更为简单,只需取每一个感受野内的最大值。
以下步骤均以openEuler用户执行。
执行以下命令,进入matrix目录(2台开发板都执行)
cd /home/openEuler/matrix执行以下命令,创建卷积操作源码pooling.cpp(2台开发板都执行)
vim pooling.cpp代码内容如下:
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <iostream>
#include "mpi.h"
using namespace std;
void randMat(int rows, int cols, float *&Mat) {
Mat = new float[rows * cols];
for (int i = 0; i < rows; i++)
for (int j = 0; j < cols; j++) Mat[i * cols + j] = 1.0;
}
inline void pooling_kernel(int leftAnchorX, int leftAnchorY, int rightAnchorX,
int rightAnchorY, int xStride, int yStride,
int from_m, int from_n, int to_m, int to_n,
float *&from, float *&to) {
if ((rightAnchorX - leftAnchorX) % xStride != 0 ||
(rightAnchorY - leftAnchorY) % yStride != 0)
exit(-1);
if (leftAnchorX % xStride != 0 || leftAnchorY % yStride != 0) exit(-2);
for (int i = leftAnchorX; i < rightAnchorX; i += xStride) {
for (int j = leftAnchorY; j < rightAnchorY; j += yStride) {
// to[i / xStride * to_n + j] = 0.0;
float temp = to[i / xStride * to_n + j / yStride];
for (int r = i; r < i + xStride; r++)
for (int c = j; c < j + yStride; c++) {
temp = max(temp, from[r * from_n + c]);
}
to[i / xStride * to_n + j / yStride] = temp;
}
}
}
void mpi_pooling(int m, int n, int xstride, int ystride, float *&mat,
float *&res, int rank, int worldsize) {
if (m % xstride || n % ystride) {
cout << "matrix size and stride do not match \n";
return;
}
const int xstrides_per_proc = (m / xstride) / worldsize;
int strides;
if (rank == 0) {
MPI_Request *sendRequest = new MPI_Request[worldsize];
MPI_Status *status = new MPI_Status[worldsize];
for (int i = 1; i < worldsize; i++) {
strides = (i < worldsize - 1)
? xstrides_per_proc
: (m / xstride) - xstrides_per_proc * (worldsize - 1);
MPI_Isend(&mat[i * xstrides_per_proc * xstride * n],
strides * xstride * n, MPI_FLOAT, i, 0, MPI_COMM_WORLD,
&sendRequest[i]);
}
for (int i = 1; i < worldsize; i++) {
MPI_Wait(&sendRequest[i], &status[i]);
}
delete[] sendRequest;
delete[] status;
} else {
MPI_Status status;
strides = (rank < worldsize - 1)
? xstrides_per_proc
: (m / xstride) - xstrides_per_proc * (worldsize - 1);
mat = new float[strides * xstride * n];
MPI_Recv(mat, strides * xstride * n, MPI_FLOAT, 0, 0, MPI_COMM_WORLD,
&status);
res = new float[strides * (n / ystride)];
}
MPI_Barrier(MPI_COMM_WORLD);
strides = (rank < worldsize - 1)
? xstrides_per_proc
: (m / xstride) - xstrides_per_proc * (worldsize - 1);
// pooling_kernel(rank * xstrides_per_proc * xstride, 0,
// (rank * xstrides_per_proc + strides) * xstride, n,
// xstride, ystride, m, n, strides, n / ystride, mat, res);
pooling_kernel(0, 0, strides * xstride, n, xstride, ystride,
strides * xstride, n, strides, n / ystride, mat, res);
MPI_Barrier(MPI_COMM_WORLD);
if (rank == 0) {
MPI_Status status;
for (int i = 1; i < worldsize; i++) {
strides = (i < worldsize - 1)
? xstrides_per_proc
: (m / xstride) - xstrides_per_proc * (worldsize - 1);
MPI_Recv(&res[i * xstrides_per_proc * (n / ystride)],
strides * (n / ystride), MPI_FLOAT, i, 0, MPI_COMM_WORLD,
&status);
}
} else {
MPI_Send(res, strides * (n / ystride), MPI_FLOAT, 0, 0, MPI_COMM_WORLD);
}
MPI_Barrier(MPI_COMM_WORLD);
return;
}
int main(int argc, char *argv[]) {
if (argc != 3) {
cout << "Usage: " << argv[0] << " M N";
exit(-1);
}
int rank;
int worldSize;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &worldSize);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int m = atoi(argv[1]);
int n = atoi(argv[2]);
int xstride = 4, ystride = 4;
float *Mat, *resMat;
struct timeval start, stop;
if (rank == 0) {
randMat(m, n, Mat);
randMat(m / xstride, n / ystride, resMat);
}
gettimeofday(&start, NULL);
mpi_pooling(m, n, xstride, ystride, Mat, resMat, rank, worldSize);
gettimeofday(&stop, NULL);
if (rank == 0) {
cout << "mpi pooling: "
<< (stop.tv_sec - start.tv_sec) * 1000 * 1000L +
(stop.tv_usec - start.tv_usec)
<< endl;
// for (int i = 0; i < min(10, m); i++) {
// for (int j = 0; j < min(10, n); j++)
// cout << Mat[i * k + j] << ' ';
// cout << endl;
// }
}
delete[] Mat;
delete[] resMat;
MPI_Finalize();
}
2.2.4 创建makefile
执行以下命令,创建Makefile(2台开发板都执行)
vim Makefile代码内容如下:
CC = mpic++
CCFLAGS = -O2 -fopenmp
LDFLAGS = -lopenblas
all: gemm conv pooling
gemm: gemm.cpp
${CC} ${CCFLAGS} gemm.cpp -o gemm ${LDFLAGS}
conv: conv.cpp
${CC} ${CCFLAGS} conv.cpp -o conv ${LDFLAGS}
pooling: pooling.cpp
${CC} ${CCFLAGS} pooling.cpp -o pooling ${LDFLAGS}
clean:
rm gemm conv pooling 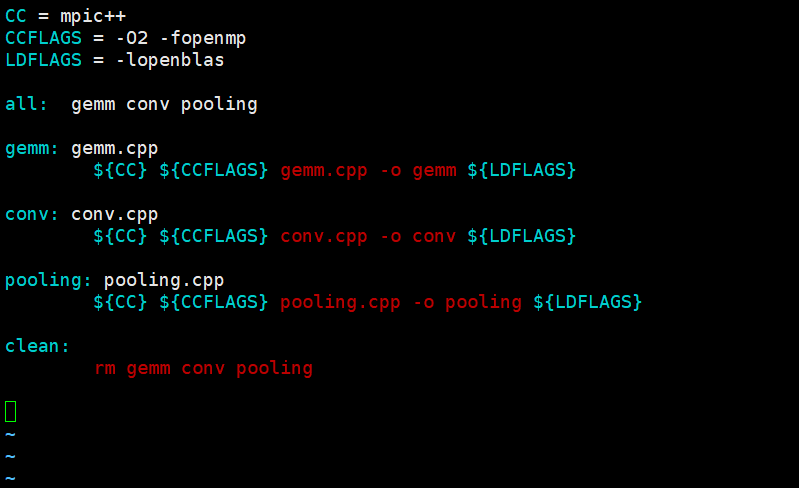
执行以下命令,进行编译(2台开发板都执行)
make 
2.2.5 建立主机配置文件
执行以下命令,建立主机配置文件(2台开发板都执行)
vim hostfile添加内容如下:
kp-pro1:2
kp-pro2:2

可通过more命令查看文件内容:
more hostfile
2.2.6 运行监测
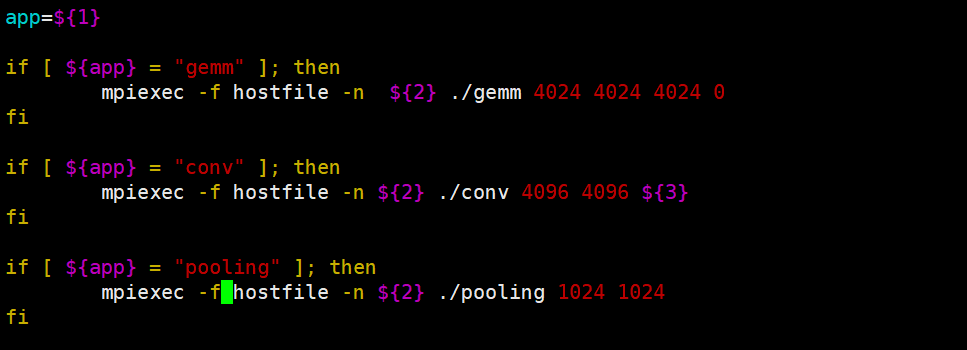
创建run.sh脚本。(2台开发板都执行)
vim run.sh内容如下:
app=${1}
if [ ${app} = "gemm" ]; then
mpiexec -f hostfile -n ${2} ./gemm 4024 4024 4024 0
fi
if [ ${app} = "conv" ]; then
mpiexec -f hostfile -n ${2} ./conv 4096 4096 ${3}
fi
if [ ${app} = "pooling" ]; then
mpiexec -f hostfile -n ${2} ./pooling 1024 1024
fi
(1)分别执行以下命令,查看矩阵乘法运行结果(只需要在kp-pro1上执行)
bash run.sh gemm 1
bash run.sh gemm 2
bash run.sh gemm 3
bash run.sh gemm 4
1-4数字表示启动处理的进程数量。
结果如下:
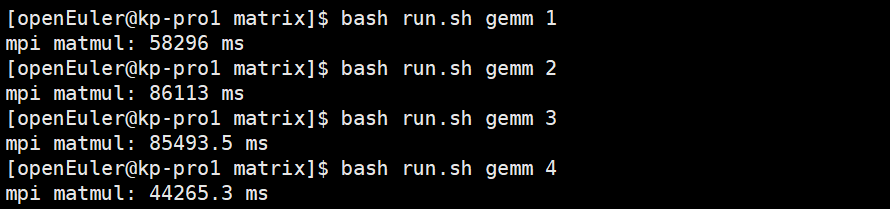
由于存在通信开销,且计算的数据量太小,通过上述运行,从整体大致可以看出,随着进程数量的增加,由进程数量为1时候耗时58296ms到进程数量为4耗时44265.Sms,耗时减少。
(2)分别执行以下命令,查看卷积运行结果(只需要在kp-pro1上执行)
bash run.sh conv 1 0
bash run.sh conv 2 0
bash run.sh conv 3 0
bash run.sh conv 4 0
bash run.sh conv 1 1
bash run.sh conv 2 1
bash run.sh conv 3 1
bash run.sh conv 4 1
conv后面的1-4数字表示启动处理的进程数量。最后面的0表示vanilla convolution kernel,1表示img2col kernel。结果如下:
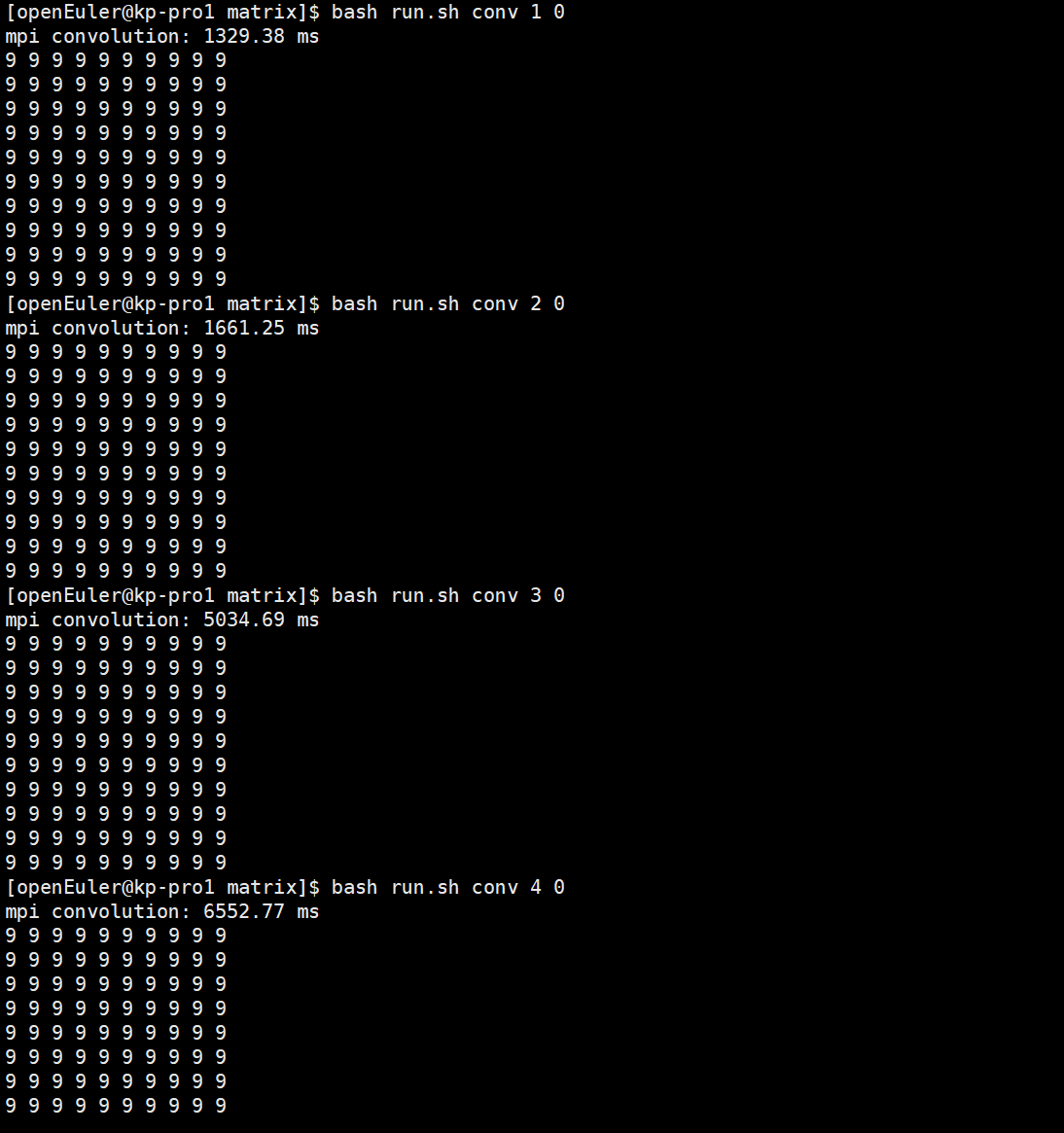
由于存在通信开销,且计算的数据量太小,通过上述运行,从整体大致可以看出,随着进程数量的增加,耗时减少。
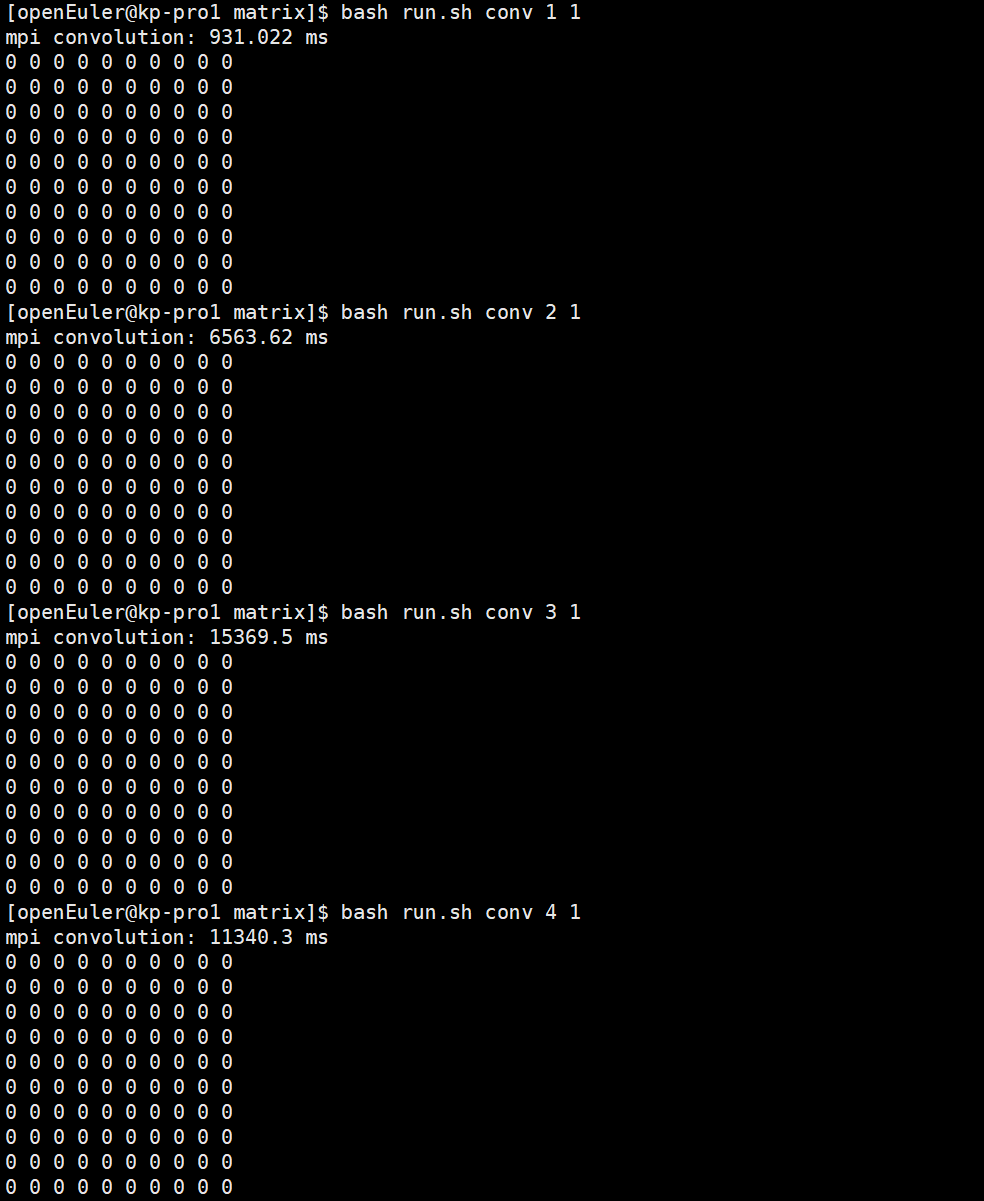
由于存在通信开销,且计算的数据量太小,通过上述运行,从整体大致可以看出,随着进程数量的增加,耗时减少。
(3)分别执行以下命令,查看池化运行结果(只需要在kp-pro1上执行)
bash run.sh pooling 1
bash run.sh pooling 2
bash run.sh pooling 3
bash run.sh pooling 4
1-4数字表示启动处理的进程数量。
结果如下:
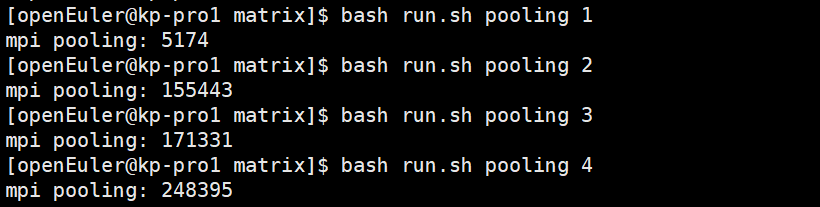
由于存在通信开销,且计算的数据量太小,通过上述运行,从整体大致可以看出,随着进程数量的增加,耗时减少。
至此,矩阵运算实验完成。
3.更多学习资源
更多学习内容和资源请扫码报名参加 “鲲鹏技术学习加油站”及浏览鲲鹏开发板专区。
1)香橙派鲲鹏Pro开发板技术学习加油站:

2)香橙派鲲鹏Pro开发板专区二维码:
