


基于鲲鹏CPU推理服务器部署DeepSeek 70B模型的方案及CPU侧调优指南
发表于 2025/06/02
0
介绍
本文档详细介绍了在鲲鹏CPU推理服务器上部署vLLM等部署框架的操作步骤,包括DeepSeek 70B模型的运行和CPU侧调优方法。
面对AI算力的快速增长和客户对高性能计算的需求,推理服务器一体机性能竞争力不够,因此需要对推理性能进行优化。本文以DeepSeek 70B大语言模型为例,该模型通过DeepSeek R1对LLaMA 70B模型进行蒸馏而得,先介绍了如何通过vLLM等常用大语言模型部署框架进行部署运行,最后说明如何实施CPU侧的调优手段。
本文提供的CPU侧调优方法需结合性能分析工具(如perf/profile)的采集数据及调优前后的测试结果,根据硬件实际情况和性能结果叠加不同的优化手段。在这里所使用硬件设施为Atlas 800I A2推理服务器,其包含一个鲲鹏920 7265处理器和8张昇腾910B4 NPU。若使用其他厂商NPU,则需要将大语言模型部署框架做相应替换。
环境要求
硬件要求
| 项目 | 说明 |
|---|---|
| 推理服务器 | Atlas 800I A2推理服务器 |
| CPU | 鲲鹏920 7265处理器 |
| NPU | 昇腾910B4 * 8 |
操作系统要求
| 项目 | 版本 | 说明 |
|---|---|---|
| openEuler | 22.03 LTS SP4 | 经过验证可用的Linux版本,部分优化选项依赖该版本 |
软件要求
配置部署环境
安装基础软件包
步骤1 安装基础软件包
yum install -y gcc-c++ make zlib-devel openssl-devel readline-devel git wget sqlite-devel openssl-devel libffi-devel unzip pciutils net-tools blas-devel gcc-gfortran openblas-devel libxml2-devel libxml2 vim-enhanced sudo flex bison perl-Digest-MD5 perl cronie curl步骤2 将基础环境变量写入“~/bashrc”中
xport GIT_SSL_NO_VERIFY=1
export LD_LIBRARY_PATH=/usr/local/Ascend/driver/lib64/driver:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/usr/local/Ascend/driver/lib64/common:$LD_LIBRARY_PATH
echo 'export GIT_SSL_NO_VERIFY=1' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/Ascend/driver/lib64/driver:$LD_LIBRARY_PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/Ascend/driver/lib64/common:$LD_LIBRARY_PATH' >> ~/.bashrc安装CMake
步骤1 下载CMake稳定版本的.sh文件(版本推荐>=3.27.1)
使用下述命令在服务器上直接下载(以3.31.5 Arm版本为例)
wget --no-check-certificate https://github.com/Kitware/CMake/releases/download/v3.31.5/cmake-3.31.5-linux-aarch64.sh步骤2 通过如下指令安装CMake,并将可执行文件设置为开机启动
bash cmake-3.31.5-linux-aarch64.sh --prefix=/usr/bin
export PATH=/usr/bin/cmake-3.31.5-linux-aarch64/bin:${PATH}
echo 'export PATH=/usr/bin/cmake-3.31.5-linux-aarch64/bin:${PATH}' >> ~/.bashrc安装CANN
说明
安装前请通过npu-smi info指令查看有无正常回显,以确认Ascend NPU固件驱动已经安装,如果没有安装请先安装NPU驱动。驱动安装方法参考https://www.hiascend.com/document/detail/zh/canncommercial/81RC1/softwareinst/instg/instg_0005.html?Mode=PmIns&InstallType=local&OS=Ubuntu&Software=cannToolKit
步骤1 进入CANN软件包下载页面
选择配套资源如下图所示
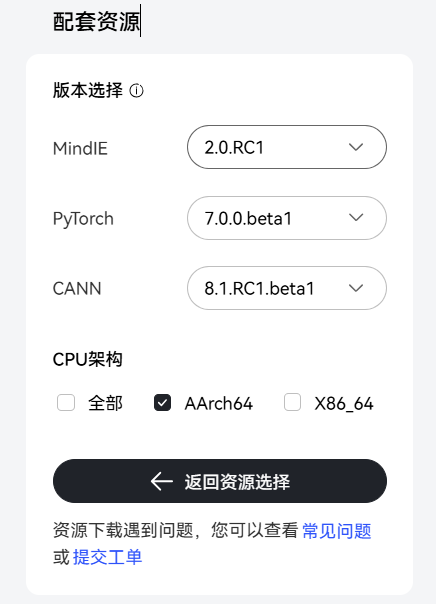
步骤2 下载CANN软件安装包
下载下图中选中的三个文件,并上传至服务器的"/home/packages"目录下
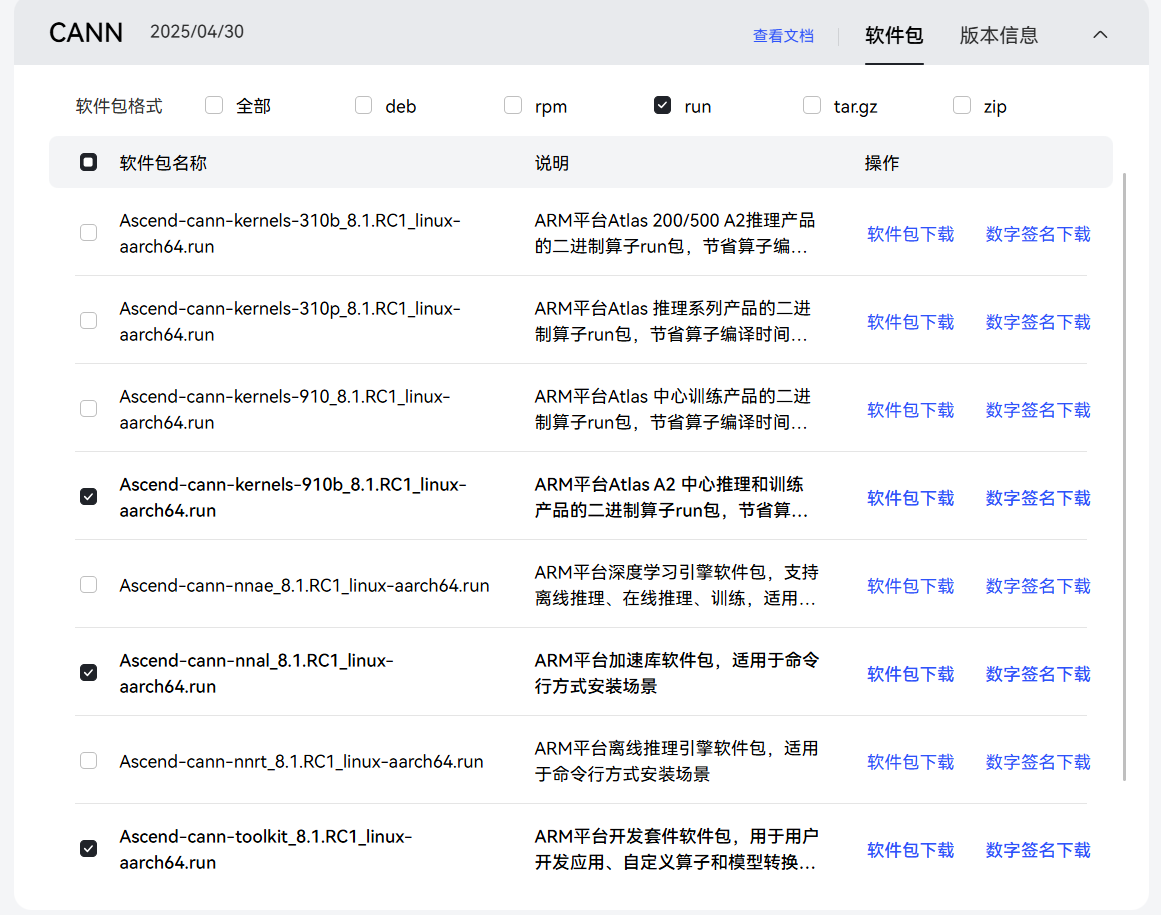
步骤3 进入安装包存放路径并安装CANN
执行以下命令
cd /home/packages
chmod -R 755 .
./Ascend-cann-toolkit_8.1.RC1_linux-aarch64.run --install
source /usr/local/Ascend/ascend-toolkit/set_env.sh
echo 'source /usr/local/Ascend/ascend-toolkit/set_env.sh' >> ~/.bashrc
./Ascend-cann-kernels-910b_8.1.RC1_linux-aarch64.run --install
./Ascend-cann-nnal_8.1.RC1_linux-aarch64.run --install
source /usr/local/Ascend/nnal/atb/set_env.sh
echo 'source /usr/local/Ascend/nnal/atb/set_env.sh' >> ~/.bashrc安装Ascend Extension for PyTorch
步骤1 下载Torch软件包
wget https://download.pytorch.org/whl/cpu/torch-2.5.1-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl --no-check-certificate步骤2 执行安装命令
pip install torch-2.5.1-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl步骤3 下载Torch_NPU插件包
wget https://gitee.com/ascend/pytorch/releases/download/v7.0.0-pytorch2.5.1/torch_npu-2.5.1-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl --no-check-certificate步骤4 执行安装命令
pip install torch_npu-2.5.1-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl部署vLLM-Ascend和MindIE Turbo推理框架
部署vLLM-Ascend和MindIE Turbo推理框架包括安装大语言模型推理加速框架vLLM、实现vLLM在Ascend NPU上无缝运行的vLLM-Ascend和高性能推理引擎MindIE Turbo。
步骤1 拉取vLLM仓库安装0.7.3版本
git clone -b v0.7.3 https://github.com/vllm-project/vllm.git
cd vllm
pip install -r requirements-build.txt
VLLM_TARGET_DEVICE=empty pip install -v -e .步骤2 安装vLLM-Ascend
git clone -b v0.7.3-dev https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend
pip install -v -e .步骤3 参见“2-软件要求”,下载对应版本的MindIE Turbo软件包,并上传到"/home/packages"下
下载如下图所示选中的软件包

步骤4 解压并安装MindIE Turbo
cd /home/packages
tar -xvzf Ascend-mindie-turbo_2.0.RC1_py311_linux_aarch64.tar.gz
cd Ascend-mindie-turbo_2.0.RC1_py311_linux_aarch64
pip install mindie_turbo-2.0rc1-cp311-cp311-linux_aarch64.whl步骤5 执行以下命令验证是否安装成功
pip show mindie_turbo出现以下回显则表示安装成功
Version: 2.0rc1
Summary: MindIE Turbo: An LLM inference acceleration framework featuring extensive plugin collections optimized for Ascend devices.
...CPU侧性能调优
绑核优化
适用于运行过程中出现跨NUMA访问较多、线程切换开销大、Host下发任务慢等场景。此处推荐使用方法三。
方法一:使用taskset进行绑核
启时直接绑定进程,如下启动app.py所示。
taskset -c 0-31 python3 app.py方法二:粗粒度绑核
将所有任务绑定在NPU对应NUMA的CPU核心上,避免跨NUMA节点的内存访问,并支持粗粒度绑核上的自定义绑核。
export CPU_AFFINITY_CONF=1方法三:细粒度绑核
在粗粒度绑核的基础上进一步优化,将主要任务锚定在NUMA节点的某固定CPU核心上,减少核间切换的开销。
export CPU_AFFINITY_CONF=2方法四:自定义绑核
自定义NPU的绑核范围。
-
取值表示第value1张卡绑定在value2到value3的闭区间CPU核心上。例如,npu0:0-2表示运行在编号为0的NPU上的进程会绑定到编号为 0、1、2 的CPU核心。
-
mode=1时此项设置生效,mode=1时可以缺省该项。
-
支持部分NPU卡自定义绑核。
例如,有两张卡npu0和npu1,对于设置CPU_AFFINITY_CONF=1,npu0:0-0,绑核策略中0卡会被覆写为绑定0核,而1卡则保持mode=1的绑核策略。
export CPU_AFFINITY_CONF=1,npu0:0-1,npu1:2-5,npu3:6-6OS性能优化
适用于需要频繁进行内存操作,存在较多TLB Miss和缺页中断的场景。主要优化手段包括:使用大页内存池、引入高性能内存分配库、malloc分配时使用大页、Glibc动态库使用大页(仅在特定系统支持)。一般来说,在优化中通常不建议叠加使用多种优化方式,以避免引入额外复杂性和潜在冲突。若运行环境为 openEuler 22.03 LTS SP4 操作系统,可考虑 叠加使用Glibc动态库的大页特性,以进一步提升性能。
使用大页内存池
在Linux操作系统上运行内存需求量较大的应用程序时,由于其采用的默认页面大小为4KB,因而将会产生较多TLB Miss和缺页中断,从而大大影响应用程序的性能。当操作系统使用大页内存时,将会大大减少TLB Miss和缺页中断的数量,显著提高应用程序的性能。
大页内存分为两种,一种是标准大页,适合需要高性能和细粒度控制的应用程序,适用于对内存管理和性能有严格要求的场景。另一种是透明大页,适合希望简化配置并自动优化内存使用的应用程序,尤其适用于大多数通用场景,可根据需要来选择开启哪种大页。
标准大页
临时启用标准大页内存池
推荐采用此方法,不需要重启机器:
sysctl -w vm.nr_hugepages=1024使用下述命令可以检查是否成功启用:
cat /proc/meminfo | grep -i huge出现如下图所示回显,即为启用成功。
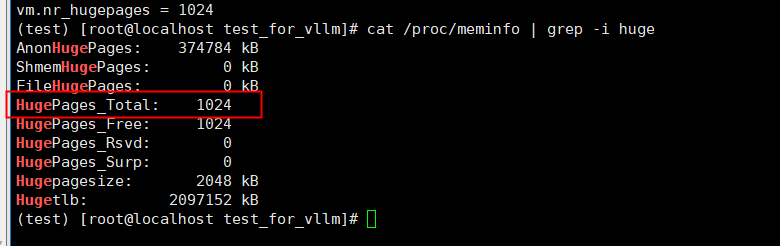
“vm.nr_hugepages”的值即为2M标准大页的数量,申请标准大页会导致OS内存相应减少,建议按需设置对应大小。
透明大页
执行以下指令
cat /sys/kernel/mm/transparent_hugepage/enabled确认透明大页是否启动,若回显结果为[always]则表明已开启透明大页。一般透明大页默认开启。
如果未开启,则使用以下命令开启大页。
echo always > /sys/kernel/mm/transparent_hugepage/enabled高性能内存库
使用tcmalloc(推荐使用该方式,安装较为方便)
步骤1 安装gperftools
yum install gperftools步骤2 获取软件包并进行安装
wget https://github.com/gperftools/gperftools/releases/download/gperftools-2.16/gperftools-2.16.tar.gz --no-check-certificate
tar -xf gperftools-2.16.tar.gz && cd gperftools-2.16
./configure --prefix=/usr/local/lib --with-tcmalloc-pagesize=64
make
make install步骤3 确认tcmalloc动态库的文件位置
find /usr -name libtcmalloc.so*步骤4 使用方法(仅在当前指令使用),/usr/lib64/libtcmalloc.so为上一步查询获得的实际路径
LD_PRELOAD=`/usr/lib64/libtcmalloc.so` python3 app.pymalloc使用大页
要求:Glibc版本大于等于2.34。
输入下列选项中的一个以启用大页,其中1表示Glibc的malloc函数会使用透明大页,2表示Glibc的malloc函数会使用标准大页。
-
使用透明大页
export GLIBC_TUNABLES=glibc.malloc.hugetlb=1-
使用标准大页
export GLIBC_TUNABLES=glibc.malloc.hugetlb=2Glibc动态库使用大页
openEuler提供的Glibc加载动态库方案默认映射大页则可以减少内存开销,同时加快进程启动速度,最终能达到降低iTLB cache miss以提升性能的结果。首先确认Glibc和Glibc-devel是否安装,版本是否满足要求。
要求:需要openEuler sp4 update 2.34-161版本以上的Glibc(依赖于openEuler 22.03 LTS SP4系统)。
使用LD_HUGEPAGE_LIB环境变量,会让可执行程序依赖的所有动态库都尝试映射大页。变量值为动态库的大页模式:
-
配置为2,使用动态库大页模式(支持透明大页)
-
配置为1,使用动态库大页模式(支持标准大页)。
-
配置为0,动态库不使用大页。
该环境变量不会被复制到子进程,建议在运行程序入口配置,在外部shell脚本(非程序入口)设置不会生效。
使用方法示例:
export LD_HUGEPAGE_LIB=1
torchrun --nnodes=1 --nproc_per_node=8 --master-port 61888 scripts/train.py \
configs/opensora-v1-1/train/stage1.py流水优化
一级流水优化是一种通用有效的优化方法,主要是将部分算子适配任务迁移至二级流水,使两级流水负载更均衡,并减少dequeue唤醒时间。
使用方法如下:
export TASK_QUEUE_ENABLE=2其他相关优化
其他相关优化包括OpenMP、BIOS、vLLM、Mindie等优化。
OpenMP相关优化
在OpenMP并行计算优化中,通过合理配置环境变量可显著提升多线程任务的执行效率。如下表所示两个关键环境变量同时设置后,可以实现线程资源分配与负载均衡的协同优化。
| 环境变量 | 功能说明 | 推荐参数 |
|---|---|---|
| OMP_PROC_BIND | 控制OpenMP线程是否绑定到特定CPU核心。false表示允许线程迁移以实现动态负载均衡 | false |
| OMP_NUM_THREAD | 设置OpenMP并行计算的最大线程数。值为100表示最多使用100个线程进行并行计算 | 100 |
示例优化指令
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=100vLLM模型推理优化
在vLLM模型推理性能调优中,通过环境变量组合配置可显著提升吞吐量和资源利用率。如下表所示两个优化选项添加后可以显著提升推理性能。
| 环境变量 | 功能说明 | 推荐参数 |
|---|---|---|
| VLLM_USE_V1 | 启用V1推理模式,启用时需额外添加VLLM_WORKER_MULTIPROC_METHOD环境变量 | 1 |
| VLLM_OPTIMIZATION_LEVEL | 控制vLLM推理的优化级别,值越高优化越激进,可能提高性能但增加显存资源的消耗 | 3 |
示例优化指令
export VLLM_WORKER_MULTIPROC_METHOD=spawn
export VLLM_USE_V1=1
export VLLM_OPTIMIZATION_LEVEL=3MindIE Turbo相关优化
当前MindIE Turbo中的部分性能调优特性有一定的场景限制,因此针对这部分特性,采用环境变量的方式控制是否开启,请根据具体使用场景进行选择。
| 环境变量 | 功能说明 | 推荐参数 |
|---|---|---|
| USING_SAMPLING_TENDOE_CACHE | 是否启用vLLM后处理部分的张量缓存功能 chunked-prefill和beam search场景下暂不支持 |
在greedy、topk和topp后处理场景下,建议设为"1"开启,提升性能 在chunked-prefill和beam search场景下设为"0"关闭 |
| USING_LCCL_COM | 是否启用LCCL通信库进行通信操作 多机场景下的跨机通信暂不支持 |
单机场景下建议设为"1"开启,提升性能 多机场景下设为"0"关闭 |
| USING_PP_MATMUL | 使用ping-pang matmul算子进行浮点数的矩阵乘计算,在长序列场景下性能更优。由于使用了不同的算子,可能会叠加造成MindIE Turbo后vllm-ascend的精度发生变化 如果需要精度和vllm-ascengd完全对齐,请关闭该变量 |
在严格要求叠加MindIE Turbo后精度不发生变化的场景下,请设为"0"关闭 其他场景下建议设为"1"开启,提升性能 |
示例优化指令
export USING_SAMPLING_TENSOR_CACHE=1
export USING_LCCL_COM=1
export USING_PP_MATMUL=1BIOS优化
| 选项名称 | 功能说明 | 推荐选项 |
|---|---|---|
| Power Policy | 调整系统性能与功耗之间的平衡模式 | Performance |
| Support Smmu | 启用系统内存管理单元,增强虚拟化环境安全,提升效率 | Disabled |
| CPU Prefetching Configuration | 配置CPU硬件预取,提升指令处理速度 | Disabled |