


ARM 架构中的 SVE 扩展
发表于 2025/06/27
0
作者:杨少雷,崔玉杰
1 向量化趋势
1.1 SIMD提供更强算力
数据中心业务对处理器的算力要求越来越高,SIMD(Single Instruction Multiple Data)成为提升算力的重要方向。SIMD技术通过单条指令同时处理多个数据流,不需要增加太多的额外硬件,就能对HPC等特定应用带来显著的性能提升,提高数据处理的性能。图 1展示了SIMD相较于传统的SISD的区别,SISD 是传统串行计算架构,一次处理一个数据;SIMD 是并行计算架构,一条指令能同时处理多个数据项,非常适合大规模数据处理任务。
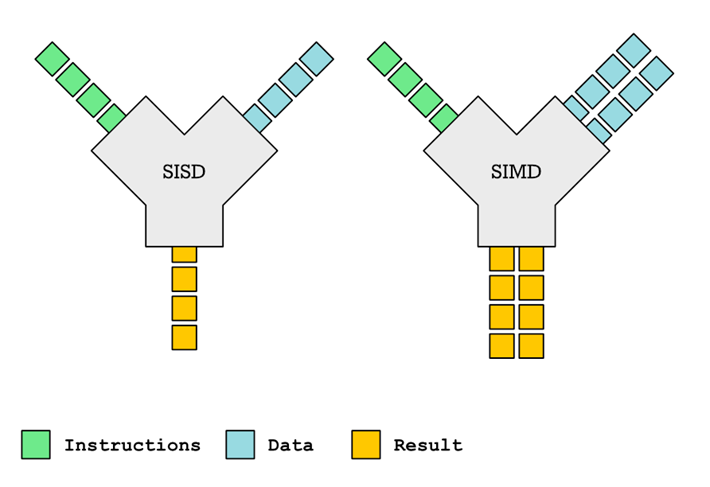
图 1 SIMD与SISD对比
如图 2所示,Intel在二十多年来通过增加寄存器的位宽来提高指令级并行度,负责处理许多高级计算任务,能够并行地对大量整数或浮点数执行算术运算,满足多媒体、大数据、人工智能、HPC等业务对处理器算力日益增加的需求。
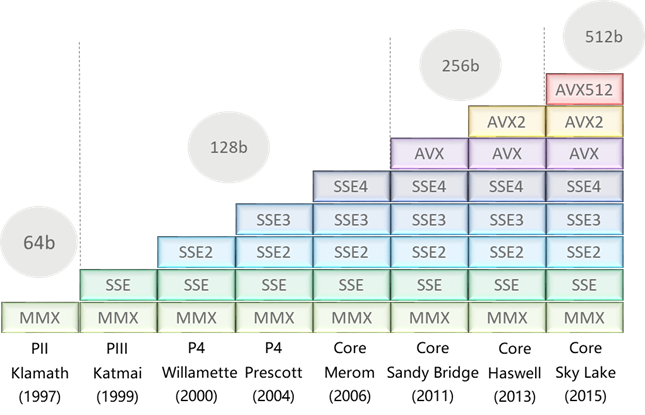
图 2 Intel在向量化指令上的布局
1.2 SIMD指令集架构演进
NEON技术为指令集架构提供了专用扩展,提供可在多个数据流上并行执行数学运算的附加指令。但是NEON指令向量寄存器位宽固定,为满足新应用场景,增加位宽需要重新定义指令集扩展,重写代码,因此可扩展性差,可扩展矢量扩展 (SVE) 是“ARMv8.2-A 及更新架构的可选扩展”,专为高性能计算科学工作负载的矢量化而开发。作为AArch64的下一代SIMD扩展,该扩展是对NEON扩展的补充,而非替代。Armv9可扩展矢量扩展指令集版本2 (SVE2) 为AArch64系统提供了可变长度SIMD功能。SVE 的问题在于,新的可变长度 SIMD 指令集的首次迭代范围有限,并且更侧重于 HPC 工作负载,缺少 NEON 中许多更通用的指令。SVE2旨在通过为新的可扩展SIMD指令集添加所需指令来解决此问题,以服务于目前使用NEON的更多样化的类DSP工作负载。SVE2是SVE和 NEON的超集。SVE2允许在数据级并行中支持更多函数域。 SVE2 继承了SVE的概念和寄存器。图 3展示了ARM处理器SIMD指令集架构演进路线。
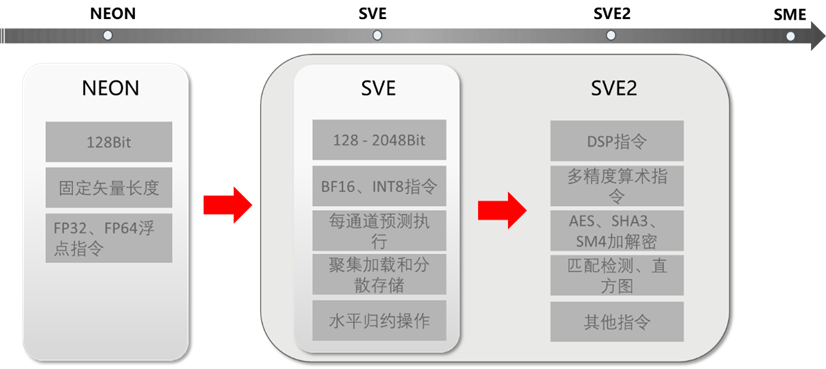
图 3 ARM处理器SIMD指令集架构演进
2 SVE特性介绍
2.1 SVE实现机制
SVE(Scalable Vector Extension)是Arm在Neon后推出的下一代SIMD指令集。SVE指令集允许向量宽度不可知的编码风格,其可以动态地适应硬件实现的向量宽度。相比Neon支持的64-bit/128-bit的向量宽度,SVE的向量宽度根据实现的不同,可以选择128-bit到2048-bit范围内,128的整数倍且要求为2的幂次的向量宽度。SVE面向HPC场景设计,支持多种reduction操作、gather/scatter、per-lane predication,从而相比Neon支持更多的矢量化场景,通过SVE指令集的使能,可以进一步挖掘应用代码中存在的并行机会。SVE2是SVE的超集,支持更多的整型操作(为大部分DSP(Digital Signal Processing)、媒体处理的Neon指令添加了VLS(Vector-Length Agnostic Scalable)版本),从而增强了对机器视觉,多媒体,数据库等场景的支持。
SVE包含32个向量寄存器,Z0-Z31,其大小如前文所述是128-bit的整数倍且要求为2的幂次。SVE向量寄存器的低128位与SIMD向量(对应neon指令集)/浮点寄存器重合,如图 2所示。这使得SVE指令与neon指令可以互换地使用,特定寄存器可以使用SVE指令写入后使用neon指令读取,反之亦然。当neon指令或者浮点指令写入SIMD向量/浮点寄存器时,对应的SVE向量寄存器会被清空。向量寄存器包含的数据会被视为若干个元素,向量元素的宽度可以是8-bit,16-bit,32-bit或64-bit。
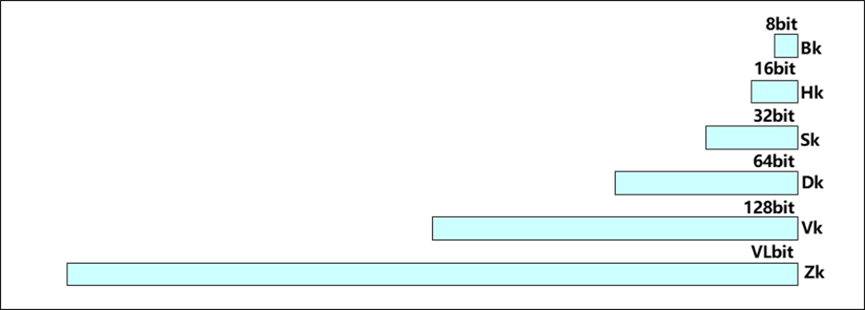
图 4 SVE向量寄存器与SIMD向量/浮点寄存器
SVE引入了predicate寄存器,用于确定与其一同使用的向量寄存器的相应的向量元素是否是有效的,SVE共包含15个predicate寄存器:P0-P15。predicate寄存器的宽度是向量寄存器宽度的1/8,即n*16-bit,predicate寄存器的每个bit对应向量寄存器的一个字节。predicate寄存器的元素宽度可以是1-bit,2-bit,4-bit或是8-bit,尽管predicate寄存器的元素最长可以达到8-bit,但只有该元素中的最小的1bit会决定对应的向量寄存器中的向量元素是否是有效的(bits[0]=1表示有效,bits[0]=0表示无效)。一个完整初始化的predicate寄存器可以同时用于控制不同元素宽度的向量寄存器的操作,如图 4所示,同一个predicate寄存器(p0)可以用作控制元素宽度packed 8-bit的向量寄存器(z0),也可以用作控制元素宽度packed 64-bit的向量寄存器(z1),此时每个元素除最小的1bit外的bit是无意义的。同一个predicate寄存器(p0)也可以同时用作控制元素宽度packed 64-bit的向量寄存器(z1)与元素宽度unpacked 32-bit的向量寄存器(z2),用于循环中同时包含64-bit与32-bit操作的情况。
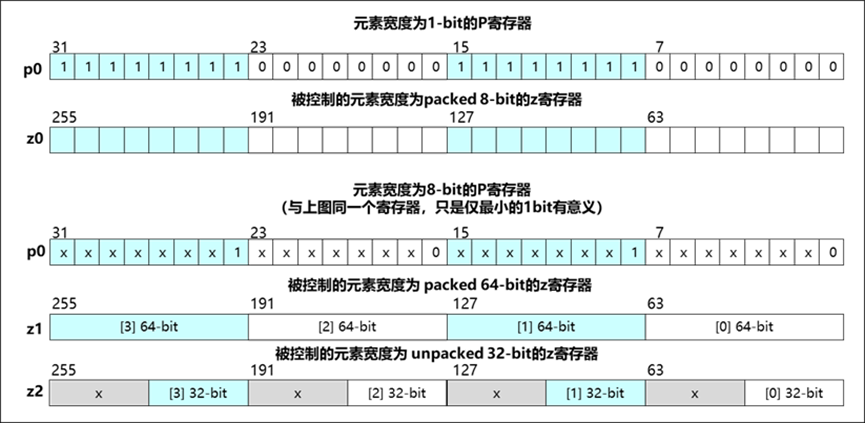
图 5 predicate寄存器使用示例
2.2 SVE支持向量长度无关特性
2.2.1 逐通道进行预测
通过预测寄存器控制每一个通道的操作,如图 6所示。
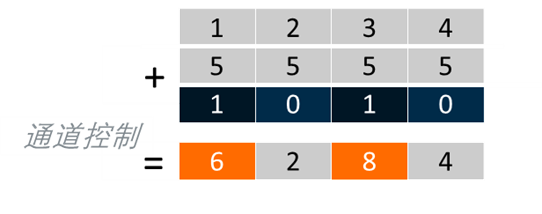
图 6 逐通道预测
2.2.2 预测P寄存器驱动的循环控制
消除了针对循环头和尾部的标量处理的额外开销,如图 7所示。
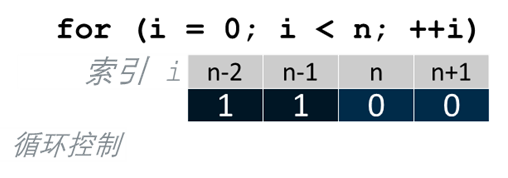
图 7 预测P寄存器驱动的循环控制
2.2.3 软件管理推测的向量分区
SVE 引入了first-fault向量加载指令,以及first-fault预测寄存器 (FFR) 以允许向量访问跨入无效页面,如图 8所示。
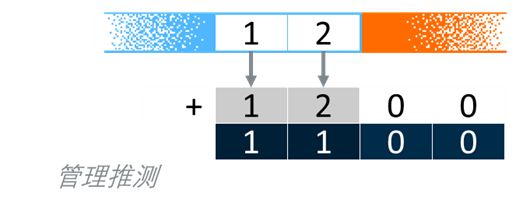
图 8 软件管理推测的向量分区
2.3 SVE支持复杂代码的自动向量化
2.3.1 Gather-load and scatter-store
SVE 中灵活的寻址模式允许向量基于地址或向量偏移量,这样可以从非连续内存位置加载或者存储单个Zn寄存器,如图 9所示。
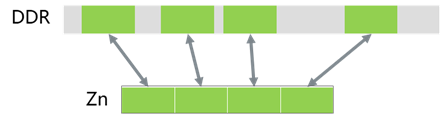
图 9 聚集加载和分散存储
2.3.2 增强的浮点水平规约操作
指令可能具有按顺序(从低到高)或基于树(成对)的浮点归约排序,不同的操作排序可能会导致不同的舍入结果,这些操作权衡可重复性和性能,如图 10所示。
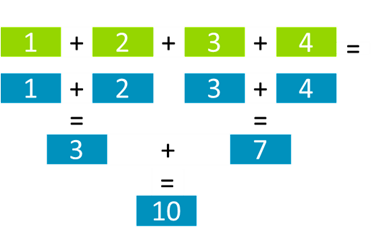
图 10 增强的浮点水平规约操作
2.4 SVE生态使能
SVE在GCC,LLVM中均实现支持,如图 11所示。

图 11 SVE生态使能