虚拟机场景nginx HTTP转发性能调优记录
发表于 2025/07/07
0
作者 | 谢忠华
问题背景
某场景进行Nginx HTTP转发性能测试时发现,虚拟机TPS(每秒转发数)性能不达预期,需要调优,且火焰图中osq-lock热点占比较高。
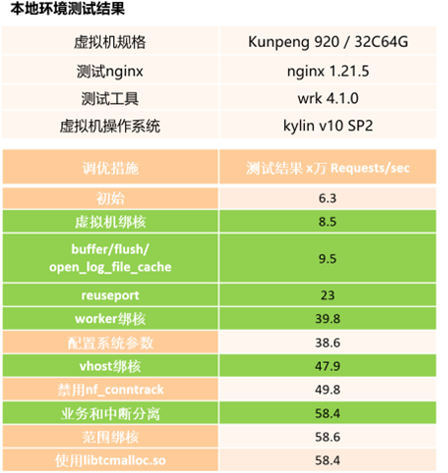
软硬件配置:

osq-lock热点分析优化
问题现象
从测试获取的perf数据和火焰图中发现,虚拟机上的osq-lock热点占比较高。
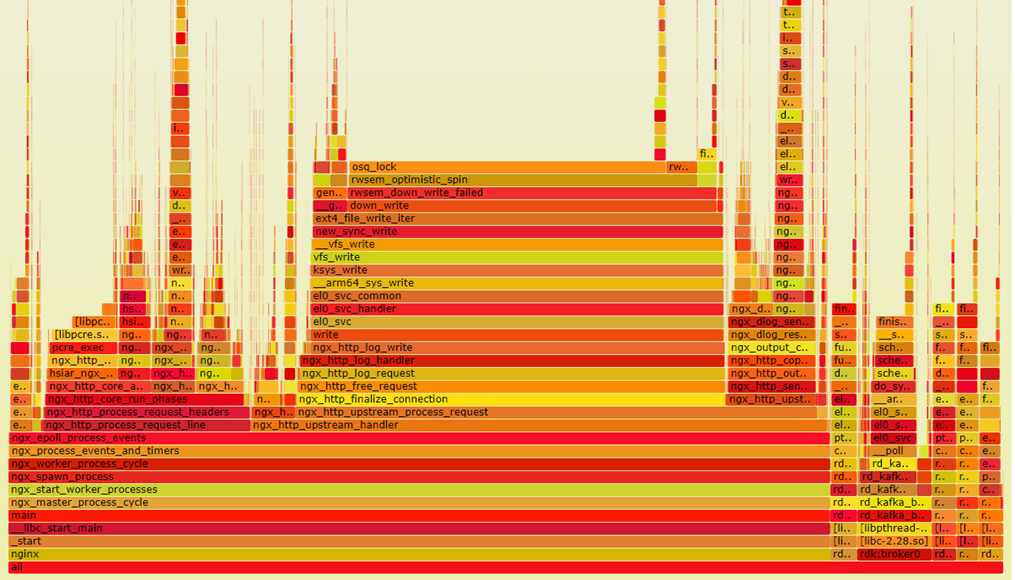
问题分析
热点分析思路
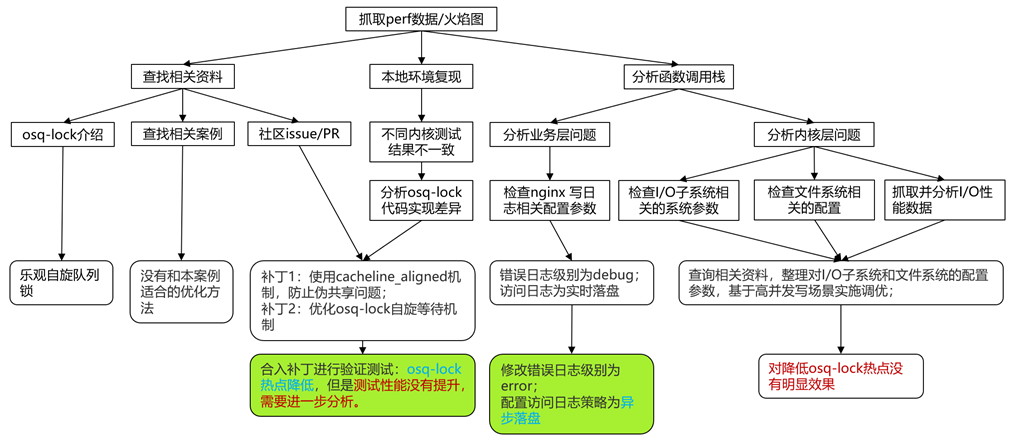
经过查询相关资料、搭建模拟环境复现和分析osq-lock函数调用栈:
1. osq-lock是一种乐观自旋队列锁,在此场景下,是多个线程对同一个文件进行写操作(nginx服务写访问日志)导致的,所以本地使用unixbench 工具的 fscopy 测试多线程写同一个文件模拟实际场景。
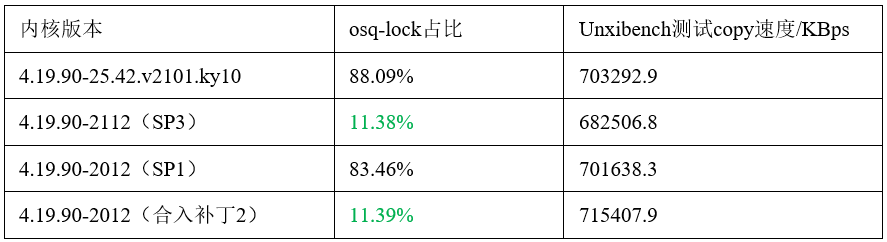
2. 经过在同一个虚拟机环境上,安装不同版本内核测试发现,openEuler20.03 LTS SP3的内核(内核版本为4.19.90-2112)没有osq-lock热点过高的问题(osq-lock热点为10-20%),与麒麟v10 SP1/SP2(分别基于openEuler 20.03 LTS(内核版本为4.19.90-2003)和 openEuler 20.03 LTS SP1(内核版本为4.19.90-2012))(osq-lock热点占比为80%+)对比,有明显差异,对比几个内核版本的osq-lock源码,也发现SP3内核有添加过相关补丁。
3. osq-lock函数的上层是nginx的ngx_http_log_write,经检查nginx配置文件,发现:错误日志级别为debug;访问日志为实时落盘模式,没有添加缓存。
4. 获取系统环境上的IO子系统相关数据,整理出适合高并发写场景下的环境参数配置。
问题验证
更新内核
在本地环境上,基于openEuler 20.03 LTS SP1内核,打上和SP3内核osq-lock相关有差异的补丁之后,重新编译构建出新内核。使用新内核重新测试结果显示,osq-lock热点明显降低,和SP3内核的数据一致,osq-lock热点问题消失,但是性能没有明显变化。测试结果如下:
本地使用unixbench测试结果:
修改nginx配置文件
查看nginx配置文件发现:错误日志级别为debug;访问日志为实时落盘模式。
修改之后:错误日志级别为error;添加访问日志的buffer和flush参数;配置日志文件缓存。


Buffer和flush参数控制日志刷盘策略。
Buffer参数: buffer参数指定了日志写入缓冲区的大小。当日志数据达到设定的缓冲区大小时,才会一次性写入磁盘。
Flush参数:flush参数指定了日志缓冲区的刷新时间间隔。即是如果日志缓冲区没有在指定时间内写满,也会进行强制写入磁盘。
修改以上nginx配置参数有以下的影响:
正面影响:不会每次请求都立即写入磁盘,特别是在高并发场景下,可以显著降低写入日志对性能的影响,降低IO负担。
可能发生的负面影响:当Nginx服务崩溃或者系统发生非正常关机(极小概率事件),仍然缓存在内存中未被刷到磁盘中的日志会丢失,例如以上参数设置的“buffer=32k flush=1s”,则最多丢失32k或者1s时间内的日志。日志数据丢失的风险主要来自系统级的异常,确保系统稳定,合理设置buffer和flush参数,可以降低这种风险。
修改完成之后,重新测试发现:osq-lock热点降低到0,找不到osq-lock的热点,在nginx性能上也有一定的提升。
本地nginx服务测试结果:

修改系统参数
查询相关资料,整理对I/O子系统和文件系统的配置参数,基于高并发写场景实施调优;修改kunpeng测试机的系统参数。
本地测试结果发现,均没有对osq-lock热点高的问题造成明显影响。
根因分析
更新内核
对于更新内核之后,osq-lock热点降低,但是TPS性能没有提升的现象,深入补丁和源码进行分析发现:
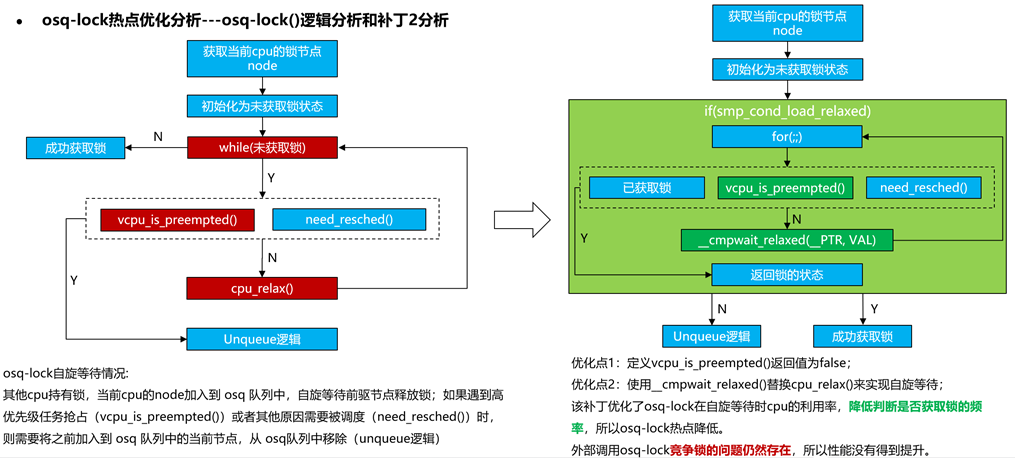
简单来说就是cmpwait模式是被动等待,而cpu-relax模式是主动判断,cmpwait模式降低了osq-lock自旋等待的消耗。所以osq-lock的热点降低了。另外由于多worker对同一个日志文件进行写的竞争没有缓解,所以系统性能没有得到提升。
修改nginx配置文件
由于访问日志为异步落盘模式之后,worker下发写操作之后就返回了,不会阻塞worker。所以osq-lock热点随之消失,nginx性能也有一定的提升。
TPS性能优化
性能瓶颈分析
从外部网络环境,宿主机,测试虚拟机,业务系统等角度进行详细分析:
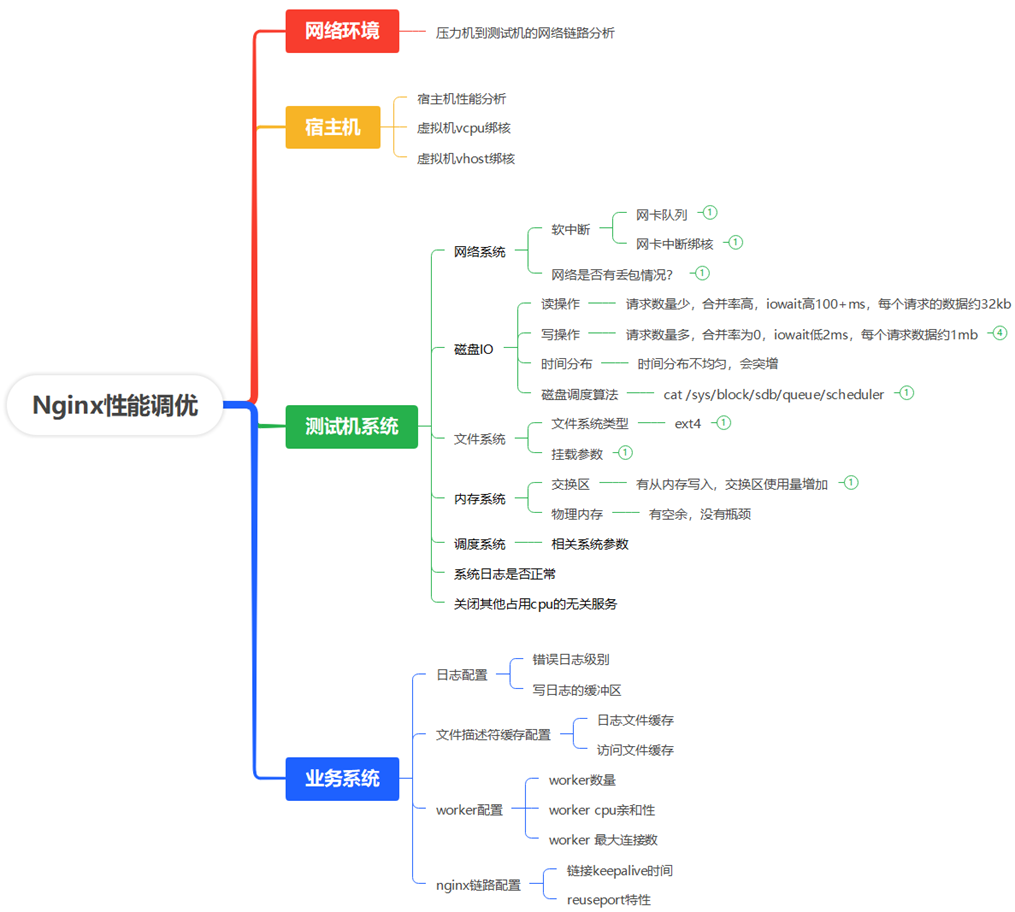
调优方向分析
宿主机
现状:宿主机上还有其他业务/虚拟机同时工作,且不能停止其他业务;
目标:在鲲鹏宿主机上实施虚拟机的vhost和vcpu绑核;
测试机系统
现状1:网口速率没有达到瓶颈;网络没有丢包;网卡中断固定在某些vcpu上,vcpu利用率si占比不高;
现状2:磁盘IO,内存使用量没有达到瓶颈;文件系统是ext4;挂载参数为default;
现状3:交换区有少量使用;
现状4:部分系统参数配置不合理;
现状5:系统日志没有报错,但有较多audit日志;
目标:由于测试数据没有显示有明显瓶颈,只对部分不合理的系统参数进行调整;配置关闭audit服务;根据通用调优经验,关闭irabalance,selinux,nf-conntrack等服务
业务系统
现状1:错误日志级别为debug,且日志中有error-log输出;访问日志采用实时落盘策略;
现状2:没有配置文件描述符的缓存;
现状3:worker数量为auto,没有配置亲和性,最大连接数满足要求;
现状4:压测发现nginx worker压力分布不均匀,只有部分worker有压力。
目标:调整错误日志级别为error;访问日志添加配置buffer和flush参数;配置文件描述符的缓存;配置业务和网络中断分离;启用reuseport特性
调优实施
步骤一:鲲鹏宿主机vcpu绑核
在宿主机的虚拟化平台管理界面进行操作,分别对测试虚拟机的vcpu一一绑核。
为了和网卡中断在同一个numa上,还需要先查看宿主机使用的网卡所在numa 节点。
在宿主机命令行界面,先确定虚拟机使用是哪个网口,然后查看网口所在pci号,最后查看/sys/bus/pci/devices中相应的pci所在的numa node。例如:假设当前使用的网口是enp125s0f0
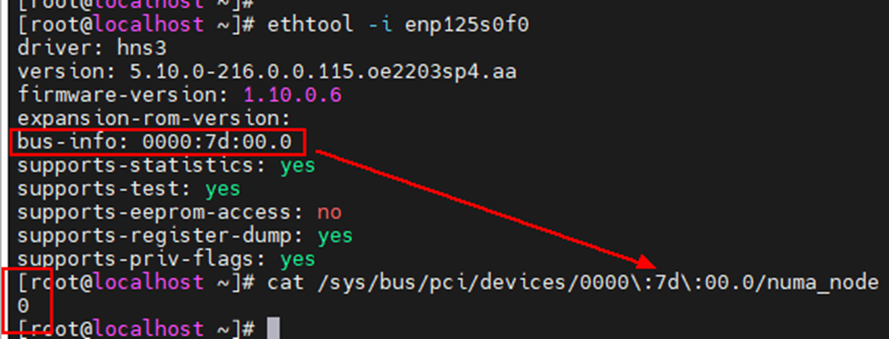
在鲲鹏920 7260 cpu上,一个物理cpu有两个numa node(0/1 或者 2/3),每个numa node 32个逻辑核;
由于虚拟机需要32个vcpu cores,为了和下面的网卡绑核不冲突,这里选择网卡所在cpu的另一个numa node进行绑核(这个例子中即是numa node 1);
确定改绑在哪个numa node之后,就可以进行绑核了,使用虚拟化管理平台的虚拟化配置界面进行绑核。
对于一般的kvm-qemu虚拟机
可以通过修改虚拟机配置文件(virsh edit [vm-name])进行绑核:例如下图所示,对每一个vcpu,绑定到cpuset指定的cpu(s)上。下图中的是一一绑定,如果cpuset指定的是一个cpu范围,则是范围绑定。
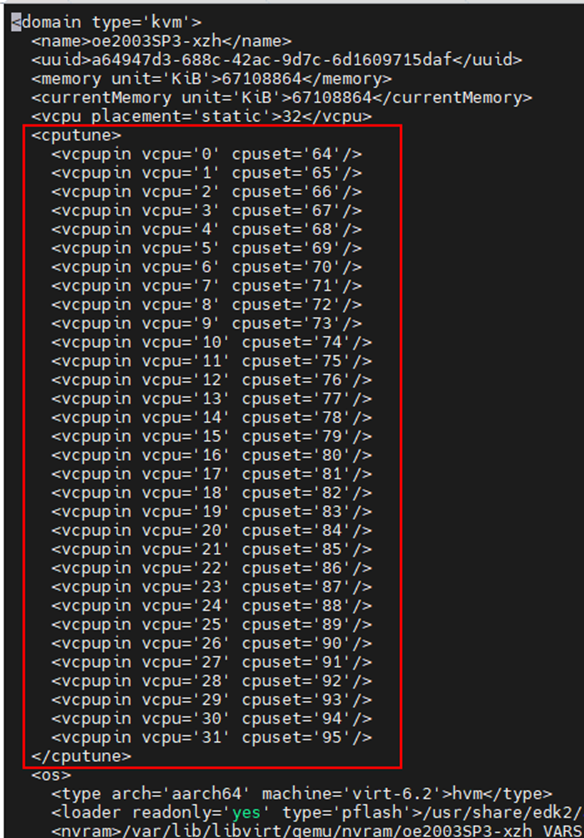
配置完成之后,:wq 保存退出。
然后关闭虚拟机后启动(不能直接reboot重启,需要下电虚拟机,然后启动)。
virsh shutdown [vm-name]
virsh start [vm-name]
重新启动之后可以通过“virsh vcpupin [vm-name]”查询是否绑定成功
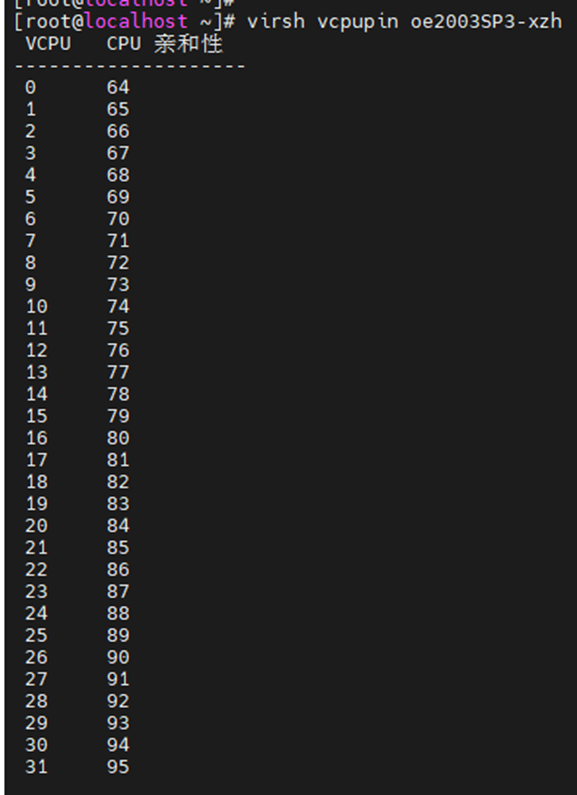
步骤二:鲲鹏宿主机vhost绑核
上一步中已经确定网卡所在numa node,这里将虚拟机相应的vhost进程绑定到网卡所在numa node。
环境上,虚拟测试机有8个网卡队列,对应的,就有8个vhost进程,则将vm1的所有vhost进程绑定到cpu 0-7上。
修改虚拟机配置文件(virsh edit [vm-name])可以配置虚拟机的网卡队列:找到网卡配置的字段,添加网卡队列配置。默认是只有一个网卡队列。

配置完成之后,:wq 保存退出。
然后关闭虚拟机后启动(不能直接reboot重启,需要下电虚拟机,然后启动)。
virsh shutdown [vm-name]
virsh start [vm-name]
重新启动之后可以通过“ps -ef |grep vhost”查询被配置的虚拟机是否有指定数量的vhost进程
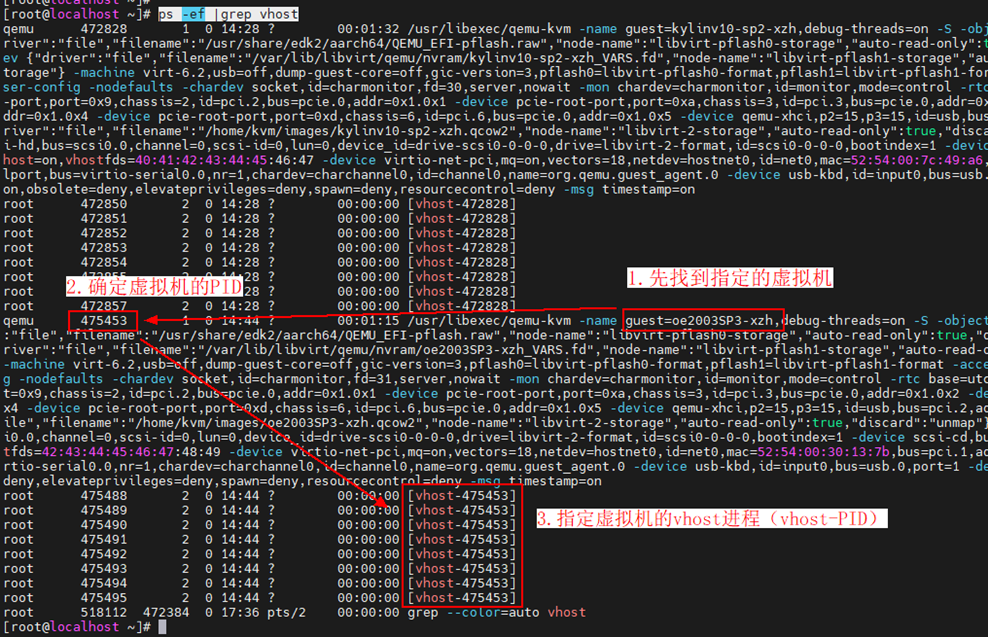
找到vhost进程之后,通过脚本或者手动执行“taskset -pc $CPU_NUM $VHOST_PID”命令将vhost进程绑定到预设的cpu core上。
测试机系统
1、由于测试数据没有显示有明显瓶颈,只对部分设置不合理系统参数进行调整;
在/etc/sysctl.conf文件中添加如下参数:
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.tcp_mem = 786432 2097152 3145728
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 131072 16777216
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_keepalive_time = 60
net.ipv4.tcp_fin_timeout = 1
net.ipv4.tcp_max_tw_buckets = 5000
net.core.somaxconn = 65535
net.ipv4.tcp_max_syn_backlog = 262144
net.core.netdev_max_backlog = 262144
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.nf_conntrack_max = 0
fs.aio-max-nr = 1048576
kernel.sched_wakeup_granularity_ns = 15000000
kernel.sched_latency_ns = 24000000
kernel.sched_migration_cost_ns = 500000
kernel.sched_min_granularity_ns = 10000000
2、配置关闭audit服务
i. vim /etc/default/grub
ii. 修改GRUB_CMDLINE_LINUX的值,在引号内末尾添加“audit=0”
iii. 更新grub配置(以kylin系统为例):grub2-mkconfig -o /boot/efi/EFI/kylin/grub.cfg
iv. 关闭服务器,然后启动服务器(不要直接reboot)
v. 重新启动后“systemctl status auditd”确认是否关闭

3、关闭irqbalance
systemctl stop irqbalance
systemctl disable irqbalance
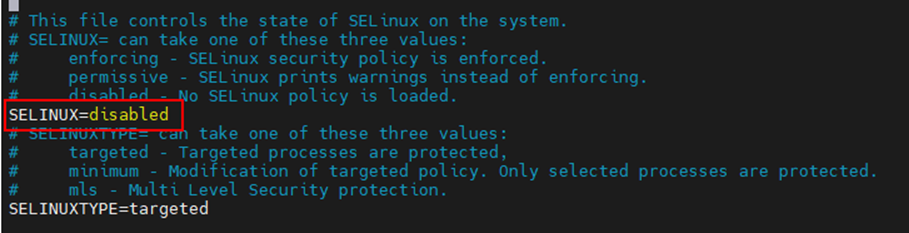
4、关闭SELinux服务
setenforce 0修改/etc/selinux/config文件,将“enforcing”改成“permissive”或者“disabled”
5、关闭nf-conntrack服务
修改/添加 /etc/modprobe.d/blacklist.conf 文件,添加如下参数:
install nf_conntrack /bin/false
blacklist nf_conntrack
blacklist nf_conntrack_ipv6
blacklist xt_conntrack
blacklist nf_conntrack_ftp
blacklist xt_state
blacklist iptable_nat
blacklist ipt_REDIRECT
blacklist nf_nat
blacklist nf_conntrack_ipv4
关闭服务器,然后启动服务器(不要直接reboot)
业务系统
1、调整错误日志级别为error;访问日志添加配置buffer和flush参数;配置文件描述符的缓存;


2、配置业务和网络中断分离;
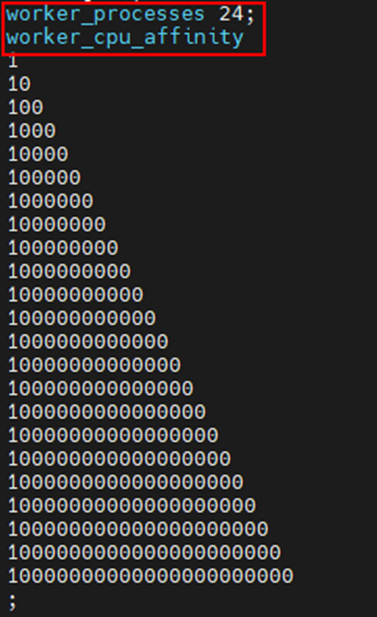
默认配置下,worker数量和虚拟机vcpu数量一致,所以即使做了worker亲和性配置,难免会有worker进程和虚拟机网卡中断在同一个vcpu上,所以手动配置worker数量= 总vcpu数量 – 网卡队列数量,当前用户环境上有32个vcpu,8个网卡队列,所以配置worker数量为24个,绑定到前24个vcpu上,网卡队列绑定到后8个vcpu上,将虚拟机的网卡队列中断依次绑定到vcpu 24-31上。
Worker绑核在nginx.conf配置文件中进行:worker_processes 指定worker数量,auto意为和cpu数量一致;worker_cpu_affinity 配置worker的亲和性,“1”表示绑定到当前位的cpu。
虚拟机内的网卡队列绑核和物理机的操作类似,需要关闭irqbalance服务,然后找到虚拟网卡对应的网卡队列中断号,然后修改中断号的亲和cpu。其中虚拟网卡在中断表中的中断命名规则和物理网卡不一样,虚拟网卡的中断名类似于“virtio0-input.0”和“virtio0-output.0”成对存在(收/发包队列),一对收发包队列的中断可以绑定到同一个vcpu上。
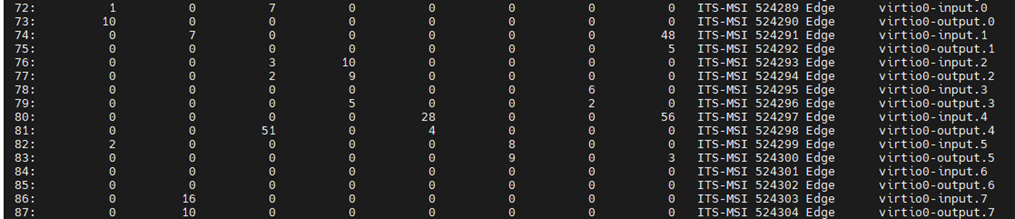
3、启动reuseport特性
SO_REUSEPROT(reuseport)是一个网络的选项设置(内核版本 >= 3.9),它能开启内核功能:网络链接分配内核负载均衡。该功能允许多个进程/线程 bind/listen 相同的 IP/PORT,提升了新链接的分配性能。
该配置项在nginx1.9.1之后支持,nginx配置“reuseport”之后,每个worker可以listen相同的的IP/PORT,并绑定独立的socket,并且内核会在各个worker上进行负载均衡。
打开nginx.conf文件,在所有 server 的 listen 端口后面加上“reuseport”选项,示例如下:
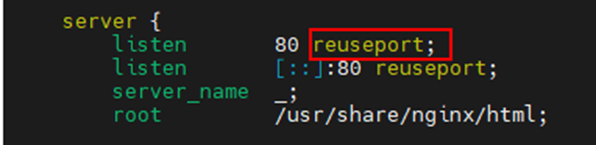
调优后性能数据