Milvus HNSW索引算法基于鲲鹏服务器的调优实践
发表于 2025/08/11
0
一、Milvus介绍
Milvus是业界领先的一款高性能、高扩展性的向量数据库,提供强大的数据建模功能,能够将非结构化或多模式数据组织成结构化的Collections。支持多种数据类型,适用于不同的属性模型。Milvus支持多种索引算法,其中就包括HNSW(Hierarchical Navigable Small World Graph)。
 HNSW是一种基于图结构的索引算法,通过构建多层图结构来加速向量检索。它的核心思想是在不同层次上进行跳跃搜索,快速缩小候选向量的范围,从而提高检索效率。
HNSW是一种基于图结构的索引算法,通过构建多层图结构来加速向量检索。它的核心思想是在不同层次上进行跳跃搜索,快速缩小候选向量的范围,从而提高检索效率。
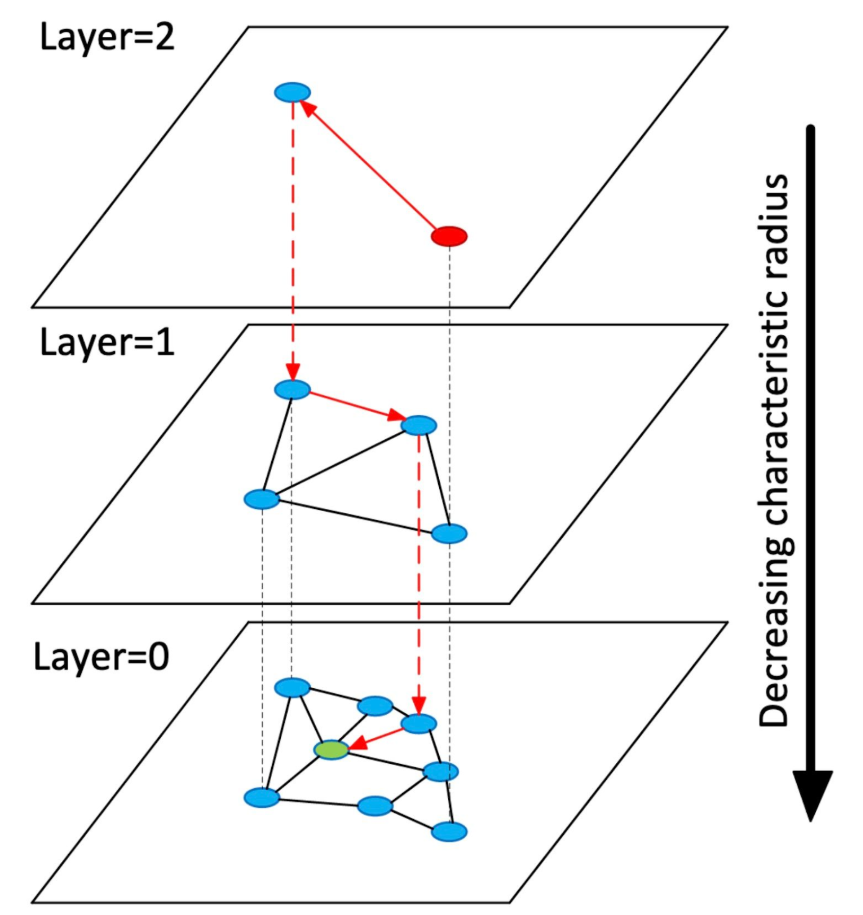
HNSW构建多层图结构,每一层的节点数量逐渐减少。最高层的节点数量最少,连接最稀疏;最低层的节点数量最多,连接最密集。每个节点在每一层中连接到多个邻居节点,这些连接是根据向量相似性建立的。
在搜索过程中,HNSW会从最高层的某个节点开始搜索。在当前层中,选择最接近查询向量的节点,然后跳到下一层继续搜索。在最低层中,进行局部搜索,直到找到最相似的向量。
优点:
- 高效搜索:通过层次跳跃,快速缩小搜索范围,提高检索效率。
- 动态更新:支持动态插入和删除向量,适用于实时性要求较高的场景。
- 可扩展性:适用于大规模数据集,能够处理数百万甚至数亿的向量。
缺点:
- 内存占用:多层图结构需要较多的内存来存储节点和连接信息。
- 构建时间:构建索引的时间较长,特别是在数据量较大时。
二、业务模型分析
Milvus请求的处理流程可简单拆解为以下阶段:
1、请求的接收和路由
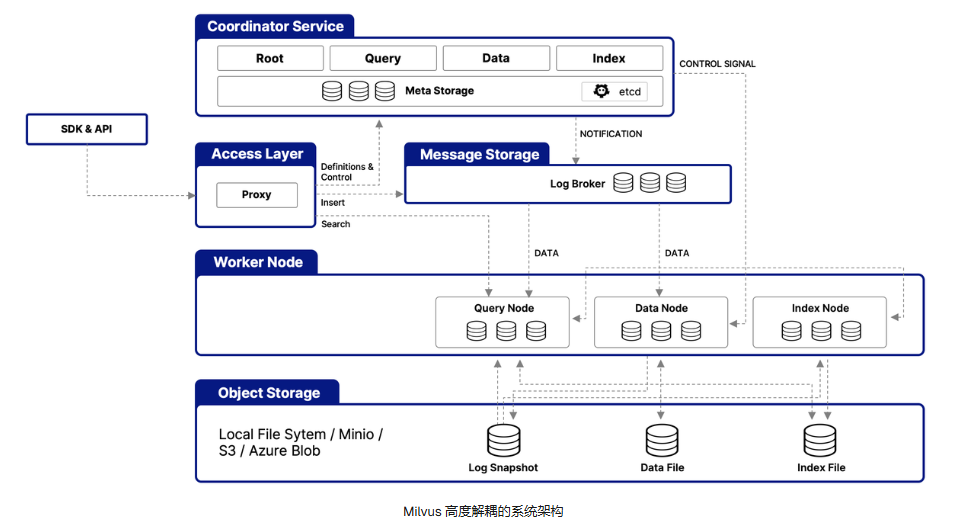
客户端通过gRPC发送请求到Milvus的访问层(Access Layer),访问层由一组无状态代理(Proxy)组成。Proxy会先进行预处理,验证集合是否存在,数据类型是否匹配等,并为操作分配全局唯一的时间戳来保证顺序性。
此外,对于数据的写入/删除请求,Proxy会根据主键哈希值计算目标分片,将请求路由至对应的虚拟通道。每个虚拟通道会被分配给一个物理通道用于日志持久化。
2、日志持久化与数据提交
Proxy将请求序列化后写入分布式消息队列(例如Pulsar/Kafka/RocksDB),形成按虚拟通道分区的日志流,此时日志代理(Log Broker)会确保日志的顺序性和持久化。
之后,数据节点(Data Node)会订阅虚拟通道,解析请求,将向量/标量数据转换为内存格式,在生成增量数据快照(binlog)之后,持久化至对象存储中(例如S3/MinIO)。当segment的数据量达到阈值时,还会触发Segment Seal,节点将其标记为只读。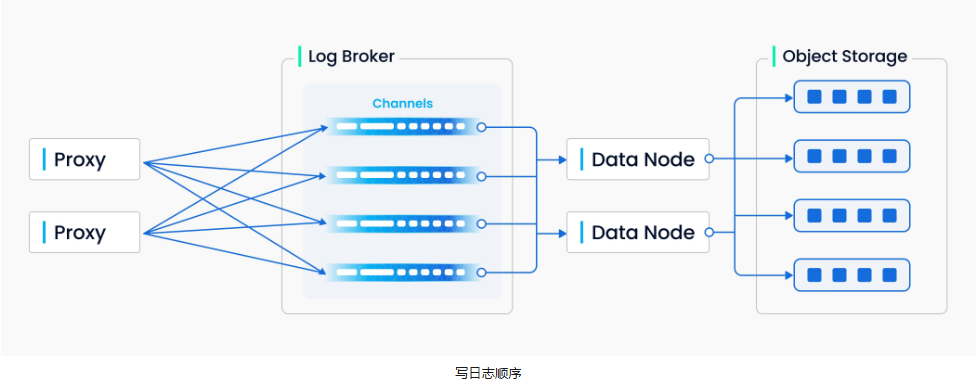 3、索引构建
3、索引构建
数据协调器(Data Coordinator)会监测Sealed Segment,向索引协调器(Index Coordinator)提交索引任务。索引协调器会将任务分配给空闲的索引节点(Index Node),索引节点从对象存储中加载数据,然后调用索引算法库,对数据进行索引构建,之后将构建好的索引序列化,同时存回对象存储。
当索引构建完成之后,元存储(Meta Store,例如etcd)就会记录Segment与索引的映射关系。
索引构建主要涉及向量和矩阵操作,因此是计算和内存密集型操作,建立向量索引可以大大受益于 SIMD(单指令、多数据)加速。Milvus支持各个平台的SIMD指令集,包括SSE、AVX2、AVX512和NEON。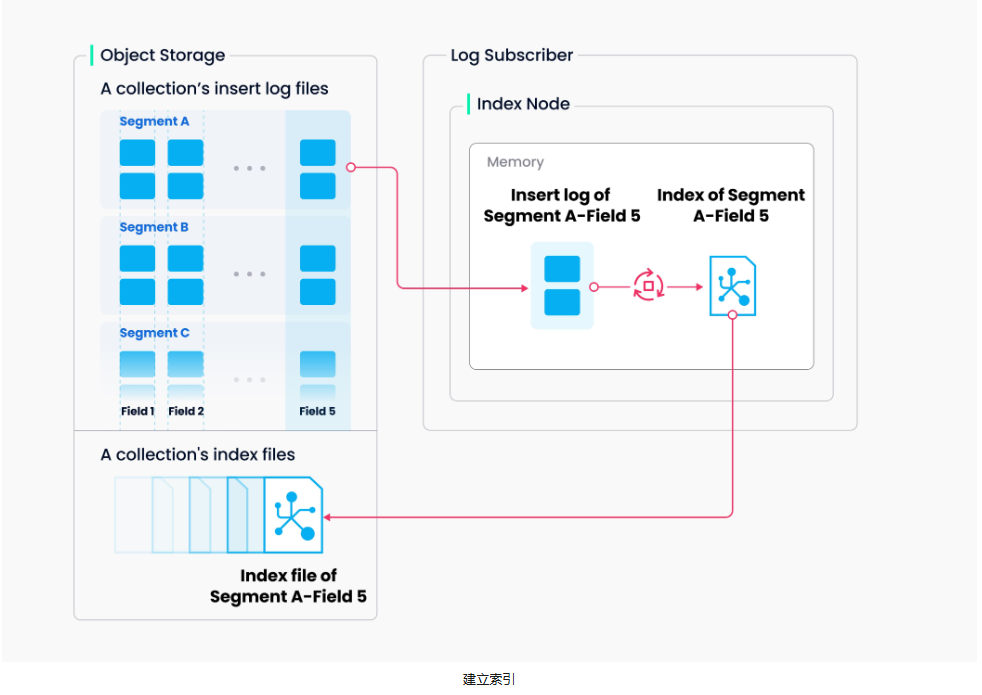 4、向量查询
4、向量查询
在查询之前,一般用户需要调用 load_collection() 函数。此时,查询协调器(Query Coordinator)就会从元存储中获取集合的所有Segment及索引位置,并根据负载策略将Segment分配给查询节点(Query Node),查询节点接着就会根据信息加载数据、加载索引,将它们缓存到内存中。
当查询节点接收到查询请求之后,会先使用索引过滤无关向量,然后计算目标向量与候选向量的距离(例如L2/IP),选出相似度最高的Top K个向量,并将其结果返回至Proxy。Proxy会合并所有向量并重新排序,最后返回给客户端。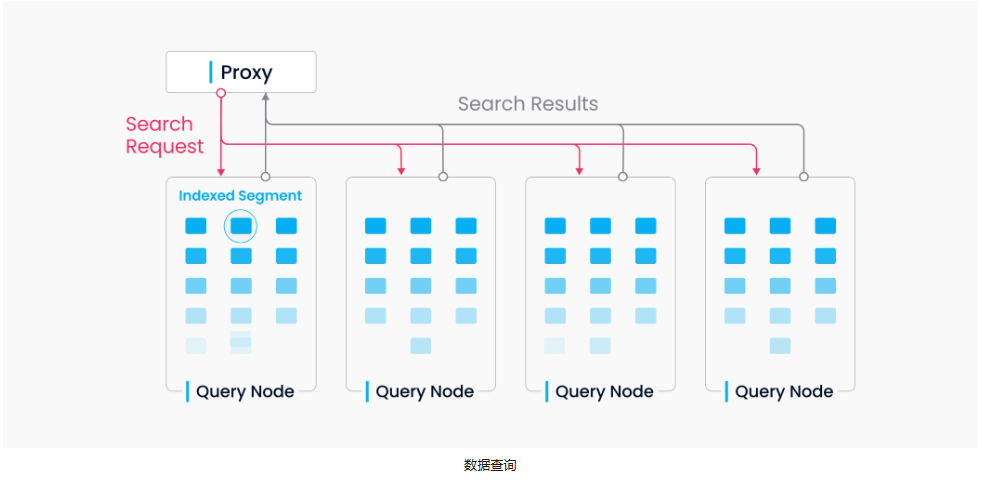 向量数据库最重要是向量查询的性能,在向量查询阶段,大部分时间都是在做向量距离计算,计算目标向量和候选向量的距离,不论使用哪种索引算法,这一步计算都是不变的。接下来的瓶颈点分析,也会更加关注这一部分。
向量数据库最重要是向量查询的性能,在向量查询阶段,大部分时间都是在做向量距离计算,计算目标向量和候选向量的距离,不论使用哪种索引算法,这一步计算都是不变的。接下来的瓶颈点分析,也会更加关注这一部分。
三、业务瓶颈分析优化实践
环境条件
| 项目 | 说明 |
|---|---|
| CPU | 鲲鹏920新型号处理器 |
| 操作系统 | openEuler 22.03 LTS SP4 |
| Milvus | v2.4.5 |
| gcc | v10.3.1 |
在16U64G的容器场景下,使用Ann-benchmark性能测试工具选择Milvus-HNSW算法和Gist数据集进行性能测试。通过perf top可以很容易发现热点函数fvec_L2sqr_neon,为了进行更仔细地观察,可以直接使用perf命令和FlameGraph工具抓取火焰图。如下图所示,此函数热点占整体CPU消耗90%+。 结合HNSW算法向量查询的逻辑:
结合HNSW算法向量查询的逻辑:
1、当进行向量查询时,HNSW算法首先会在最高层选择一个点作为起始查找点,并计算起始查找点与待查询向量之间的距离;2、遍历当前查找点的N个邻居,计算各邻居与待查询向量之间的距离;3、如果存在某个邻居与待查询向量距离与起始查找点更近,则继续遍历该邻居的N个邻居,重复步骤2的操作,直到找到当前层与待查询向量距离最近的图节点,然后跳转到下一层,将当前节点作为下一层的起始查找点,重复步骤1-3;4、查询到第0层时,保存与待查询向量之间最近的N个点,即为与待查询向量相似度最高的N个向量。
从HNSW算法查询流程中可以看出,在查询过程中核心是两个向量之间的距离计算,即函数fvec_L2sqr_neon,因此该函数在perf top中的热点占比超过了90%,此函数的代码逻辑为欧式距离计算,源码中针对此部分计算已使用了neon指令的进行向量化优化,对应的代码如下: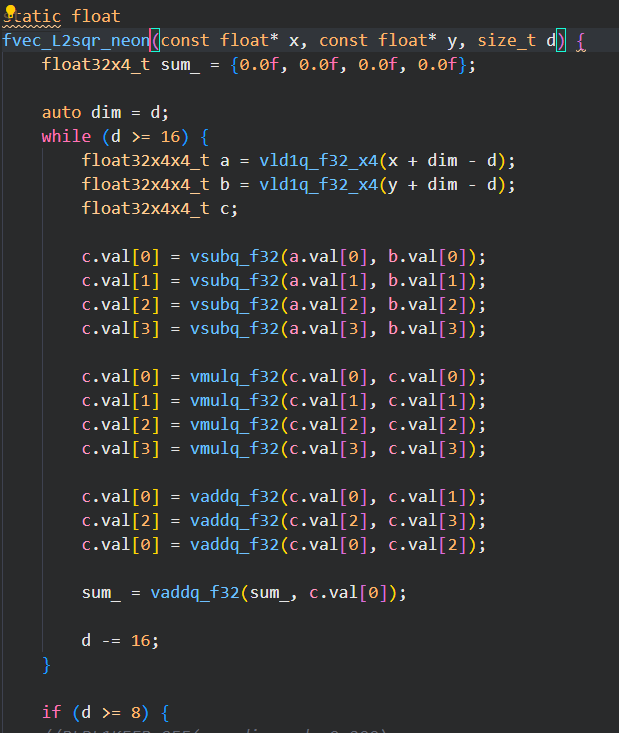 继续通过处理器微架构分析工具kperf抓取了向量查询操作时的topdown指标,发现CPU的后端Memory Bound严重,其中主要Bound在L3及DRAM。结合前面的热点函数,怀疑是欧式距离计算向量化优化后,相较传统的标量计算,在计算过程中需要访问更多的内存数据,而此部分数据没有缓存在L1/L2中,需要从L3/DDR重新加载。
继续通过处理器微架构分析工具kperf抓取了向量查询操作时的topdown指标,发现CPU的后端Memory Bound严重,其中主要Bound在L3及DRAM。结合前面的热点函数,怀疑是欧式距离计算向量化优化后,相较传统的标量计算,在计算过程中需要访问更多的内存数据,而此部分数据没有缓存在L1/L2中,需要从L3/DDR重新加载。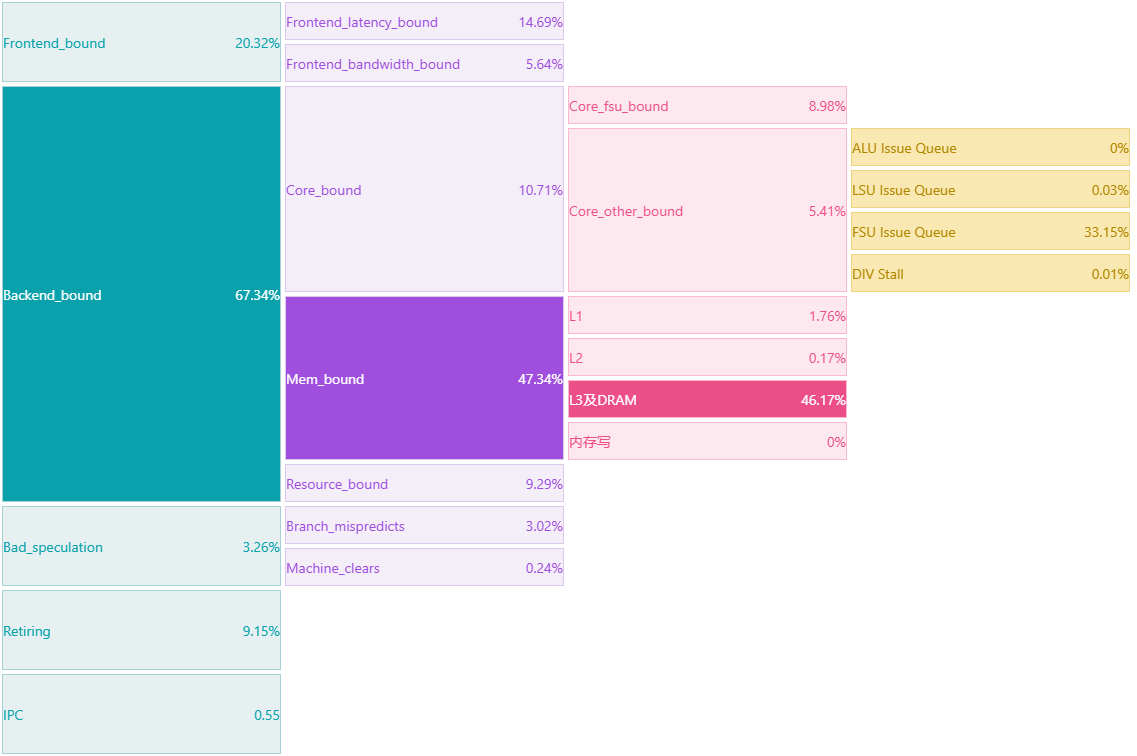
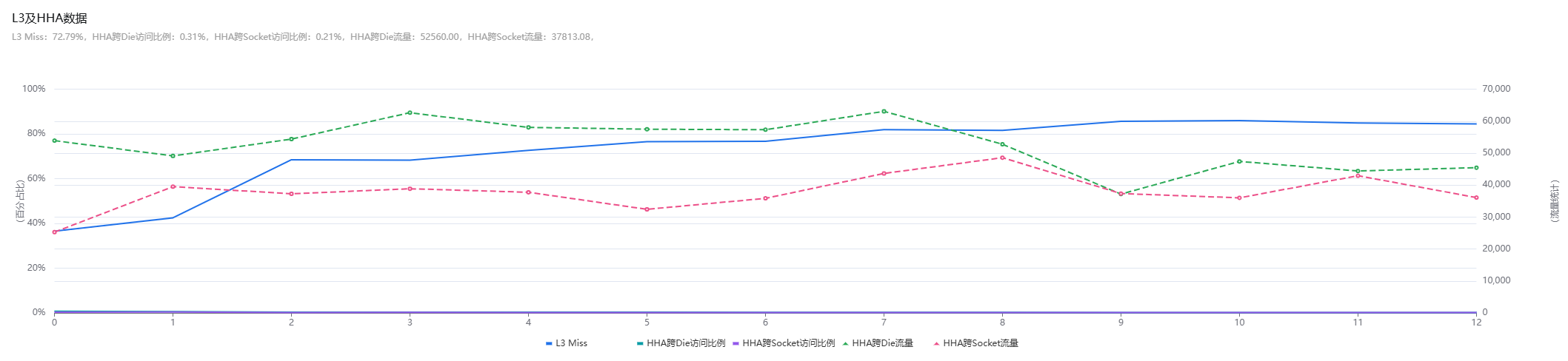
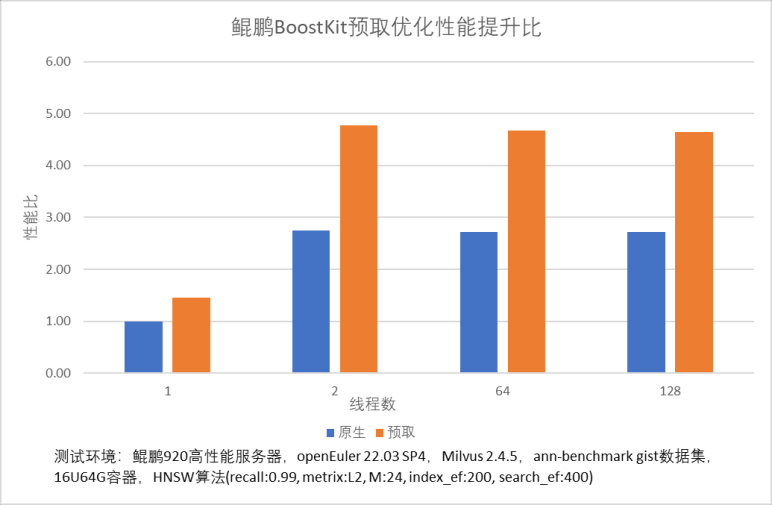
继续使用perf工具根据L3访存事件抓取热点,确认L3访存热点高就是由fvec_L2sqr_neon函数产生。因此我们通过在fvec_L2sqr_neon函数计算中增加数据预取操作,提前将需要访问的数据加载到L1缓存中以提高数据命中率。经过预取优化后,HNSW 算法在0.99精度(metric=L2 M=24 index_ef=200 search_ef=400)下不同并发的查询效率均有40%+的提升。