


鲲鹏服务器在仅CPU情况下使用VLLM推理框架推理的操作指导
发表于 2025/08/18
0
本文档主要为在鲲鹏服务器,仅有 CPU 情况下部署运行推理服务 参考资料:CPU — vLLM
环境
| 软件 | 版本 |
|---|---|
| OS | openEuler 22.03 sp 4 |
| anaconda | python 3.12 |
| gcc | 12 |
| cmake | 3.26 |
由于vllm社区更新比较频繁,该版本主要对应为v0.8.5时的操作,更高版本如v0.11.1rc5前可参考使用,更新版本请参考vllm官方社区
操作步骤
下载并安装 Anaconda 软件包
wget -k https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-aarch64.sh
# 安装Anaconda
bash Anaconda3-2022.05-Linux-aarch64.sh
source /root/anaconda3/etc/profile.d/conda.sh
# 创建环境并激活环境
conda create --name vllm python=3.12 -y
conda activate vllm
# 补充依赖
yum install scons numactl-devel更新 cmake 版本
cd /home
wget https://github.com/Kitware/CMake/releases/download/v3.26.3/cmake-3.26.3-linux-aarch64.sh
sh cmake-3.26.3-linux-aarch64.sh
# 选择y统一安装
# 设置临时变量,将新下载的作为cmake路径
export PATH=/home/cmake-3.26.3-linux-aarch64/bin:$PATH下载大模型(可选)
这里可以不下,因为之后推理服务中可以指定模型进行推理,此时会自动下载
pip install modelscope
# 下载整个模型repo(到默认/root/.cache地址)
modelscope download --model Qwen/Qwen3-0.6B
# 下载整个模型repo到指定目录
mkdir -p /home/model
modelscope download --model Qwen/Qwen3-0.6B --local_dir /home/model编译和安装 vllm
运行 vllm(CPU)benchmark 测试可用性
git clone https://github.com/vllm-project/vllm.git vllm_source
cd vllm_source
#清除缓存
rm -rf build
python -m pip cache purge
pip install --upgrade pip
pip install "cmake>=3.26" wheel packaging ninja "setuptools-scm>=8" numpy
pip install -v -r requirements/cpu.txt --extra-index-url https://download.pytorch.org/whl/cpu
# 构建和安装vllm
VLLM_TARGET_DEVICE=cpu python setup.py install运行 vllm(CPU)benchmark 测试可用性
VLLM_CPU_KVCACHE_SPACE=64 vllm bench throughput --model Qwen/Qwen3-0.6B --dataset-name sonnet --dataset-path benchmarks/sonnet.txt --num-prompts 10 --max-model-len 4096 --dtype float32正确应显示如下:

验证推理服务
命令行运行
服务器窗口 A 下运行
# 部署推理服务
VLLM_CPU_KVCACHE_SPACE=64 vllm serve Qwen/Qwen3-0.6B -tp=1 --distributed-executor-backend mp --host 127.0.0.1 --port 8000 --max-model-len 4096 --max_num_batched_tokens=8192 --dtype float32
在服务器窗口 B 下运行
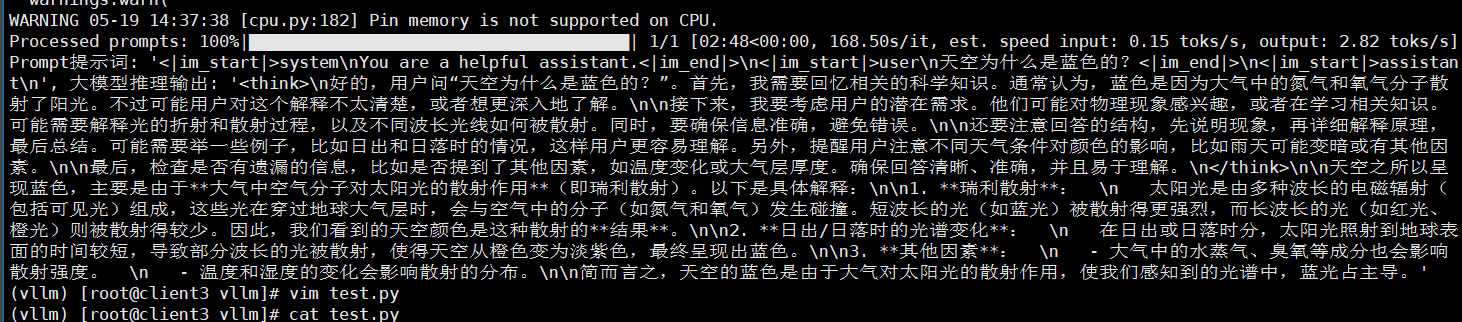
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "天空为什么是蓝色的?"}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
卸载框架
# 首先进入自己的conda环境
conda env list # 查看当前环境
# 如我的环境为 /home/test/llm/envs/vllm
conda activate /home/test/llm/envs/vllm# 进入完成后
pip uninstall vllm其他
解决模型下载环境设置问题
Python 下载网站内容时遇到 urllib3.exceptions.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self-signed
home/test/llm/envs/vllm/lib/python3.11/site-packages/requests/sessions.py
:set nu # 设置行号
:500 # 跳转到500行
i # 修改文件信息
:wq # 保存修改并退出
大概在500行左右的位置,找到 request 函数,将传参 verify 的默认值由 None 改为 False,保存。
NotImplementedError: "reshape_and_cache_cpu_impl" not implemented for 'BFloat16'
输入下面命令时,报错 `NotImplementedError: "reshape_and_cache_cpu_impl" not implemented for 'BFloat16'`
VLLM_CPU_KVCACHE_SPACE=64 vllm bench throughput --model Qwen/Qwen3-0.6B --dataset-name sonnet --dataset-path benchmarks/sonnet.txt --num-prompts 10 --max-model-len 4096 --dtype float32
原因是因为 CPU 不支持 BFloat16 特定操作,这里需要加上参数,强制转,在原有命令中添加 `--dtype float32` 参数,强制模型使用 FP32 精度,避免 BFloat16 相关操作。
conda 无法下载
将conda的下载替换至清华源
[anaconda | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror](https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/)