


通过优化BroadcastHashJoin和优化网络解决spark慢查询
发表于 2025/08/27
0
作者|吕庆祥
问题背景
应用软件
|
软件名称 |
版本 |
|
Hadoop |
3.3.0 |
|
Spark |
2.12-3.1.3 |
|
Hive |
3.1.3 |
测试组网
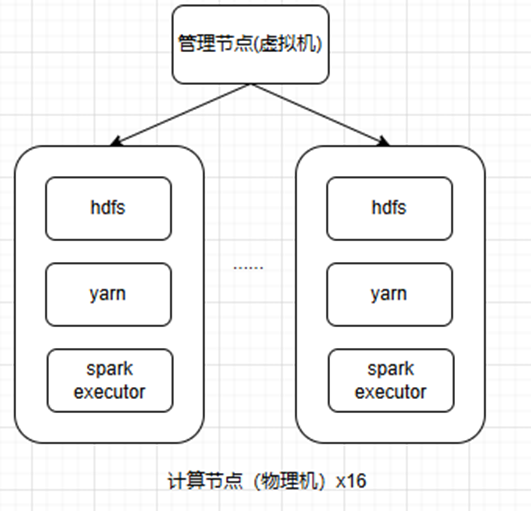
问题分析
分析思路
运行测试时首先排查是否有硬件资源使用的瓶颈(cpu、网络、磁盘等),本次测试时排查发现计算节点硬件的资源使用率都处于较低的状态,因此开始对软件层面进行排查。
执行计划分析

查看执行计划发现在大表join小表时使用的是SortMergeJoin,且存在数据倾斜导致所有数据大多集中在一个task上处理,运行缓慢,如下图。

task负载不均衡,单个task占用cpu很多,其他的则比较空闲
而查看基准环境上的执行计划发现使用的BroadcastHashJoin无数据倾斜情况,运行速度要更快。
使用BroadcastHashJoin的条件是有表大小小于spark.sql.autoBroadcastJoinThreshold(默认10M)时会使用BroadcastHashJoin。查看join的表大小已经小于10M,BroadcastHashJoin仍然没有生效。
查询资料发现使用BroadcastHashJoin时需要通过hive表元数据获取表大小是否小于 spark.sql.autoBroadcastJoinThreshold,以此来判断是否使用BroadcastHashJoin。使用DESCRIBE FORMATTED命令查看hive表元数据发现元数据中确实没有记录表大小,而基准环境中有记录表大小。
执行ANALYZE TABLE xxx COMPUTE STATISTICS命令获取所有hive表大小,执行DESCRIBE FORMATTED再次查看hive表元数据成功查询到表大小。再次跑任务查看执行计划成功使用BroadcastHashJoin。
且查询耗时明显下降,从9.3分钟下降至3分钟,如下图:

网络连接中断报错
使用BroadcastHashJoin后发现有其他查询耗时增加,如下图:

查看下面stage的task发现耗时都花费在cpu计算上,如下图:

绿色是cpu计算时间。
但是查看计算节点该stage执行时的cpu总体利用率较低,并没有达到292个task同时运行该有的cpu利用率。
因此查看yarn日志该时间段内是否有有效信息可以分析运行缓慢原因。发现如下报错,使用BroadcastHashJoin后从driver读取广播变量耗时过长花费了5分钟且出现连接中断的报错,如下图:

在管理节点和计算节点使用netstat查看网络发送接收队列,判断是由为网络问题导致上面的网络连接中断报错。
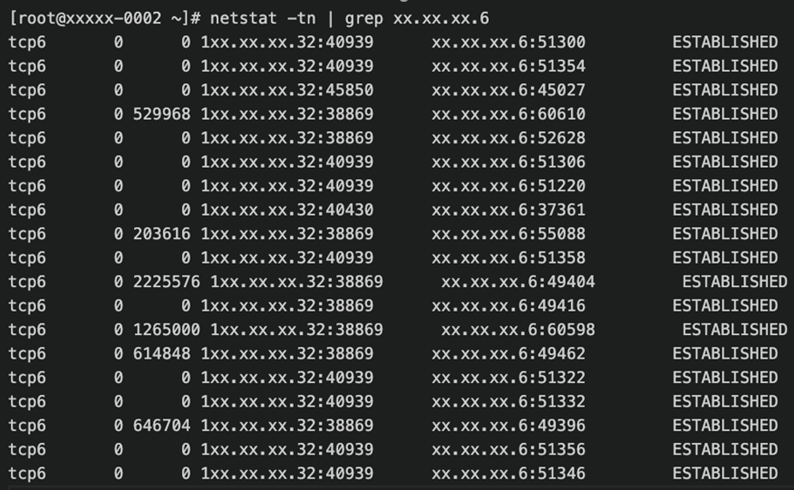
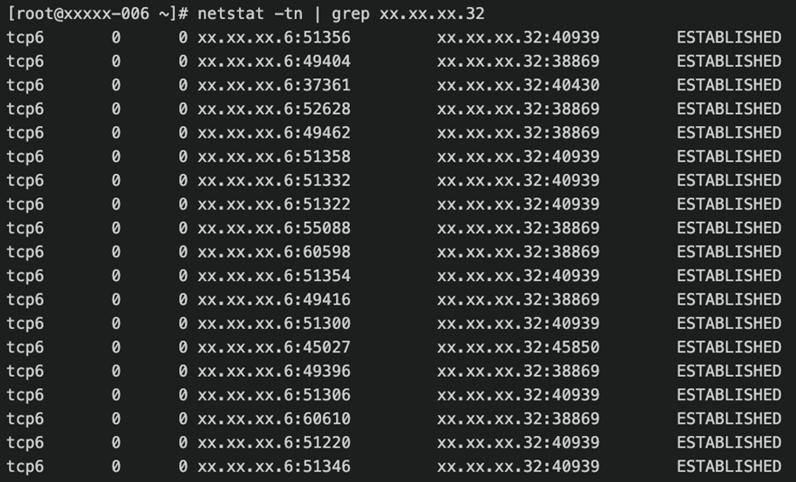
根据上面两张图可以看出计算节点的接收队列一直都为0,说明计算节点没有瓶颈,程序可以很快取到数据进行处理。而driver端的发送队列一直有大量未发送数据,说明可能网络到达瓶颈。(xx.xx.xx.6为其中一台计算节点,xx.xx.xx.32为driver节点)
查看driver节点网络流量经常在10MB/s左右,询问该虚拟机带宽只有50m,已经达到瓶颈。将虚拟机带宽提升后测试这两个查询最终耗时下降至25s。


最终优化后性能spark任务耗时缩短45%
总结
本次测试时只收集了计算节点的物理机信息,而没有去收集关注spark driver节点的虚拟机配置信息和资源使用情况,导致driver节点出现了网络瓶颈。因此性能优化前需要收集好硬件/软件配置,测试组网等信息,避免后续不必要的问题排查。