


分布式银行核心系统物理机并发数阈值低问题定位与解决指导
发表于 2025/09/09
0
作者 | 雷庆
1 项目简介
某金融科技公司(下文统称开发者)的分布式银行核心系统业务部署在物理机上,压测时延、tps远低于业务部署在虚拟机时的压测性能,且并发数达到10之后,性能已达瓶颈,提高并发数无法提供性能。希望PAE协助开发者定位物理机性能差的原因。2 基础环境信息
2.1 软硬件配置
所有物理机硬件配置及OS相同,所有虚拟机规格、OS一致。表2-1 物理机配置
| 服务器 | TaiShan 200 2280 |
| CPU | 2*7260(64cores,2.6GHz) |
| 内存 | 16*32GB |
| 硬盘 | SATA SSD2(2*960GB)+SATA HDD(4*10TB) |
| 网卡 | 4*GE+4*10GE |
| 操作系统 | Kylin V10 SP3 |
|
CPU |
32C |
|
内存 |
64G |
|
硬盘 |
120G |
|
网卡 |
与宿主机10GE网卡桥接 |
|
操作系统 |
Kylin V10 SP3 |
2.2 设备组网
xx.xx.xx.193及xx.xx.xx.194为虚拟机,其余机器皆为物理机。2.2.1 物理机环境组网
压测端在xx.xx.xx.189,注册中心(xx.xx.xx.192:8118)和网关都部署在192,和v8应用分开部署,数据库和虚拟机环境共用。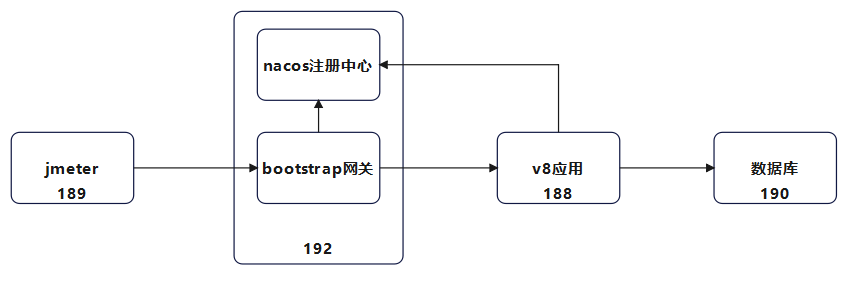
2.2.2 虚拟机环境组网
压测端部署在虚拟机193,网关和业务应用部署在同一台虚拟机194,193和194的宿主机为同一台物理机188,数据库与物理机环境共用,注册中心为xx.xx.xx.192:8228。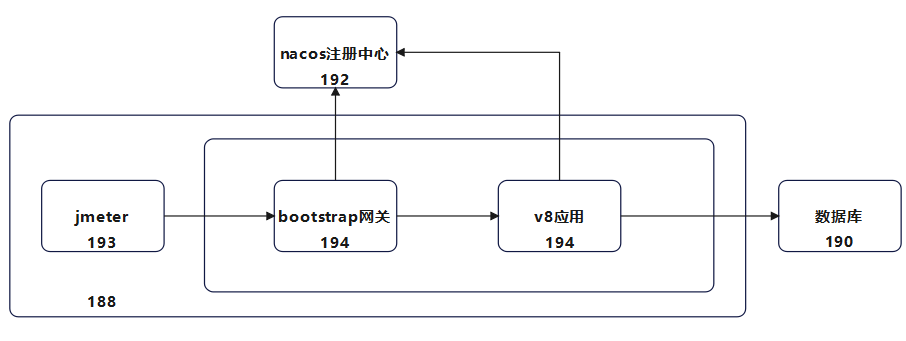
3 业务流信息
Jmeter同时起50个VUser向网关发送HTTP请求,网关将请求转发到业务应用,业务应用读取请求进行业务处理后,调用数据库执行对应的sql语句。压测请求为读写混合(7:3),业务应用正常会以集群方式部署,网关转发请求时会保证负载均衡,此次问题定位业务应用以单机模式部署,注册中心在网关和业务应用启动时,记录地址、端口等信息,并定期进行健康检测,不影响压测。
4 问题现象
开发者在调测压测脚本时,物理机环境tps远低于虚拟机环境,提高VUser数量tps差距更加明显。图4-1 物理机环境调测数据
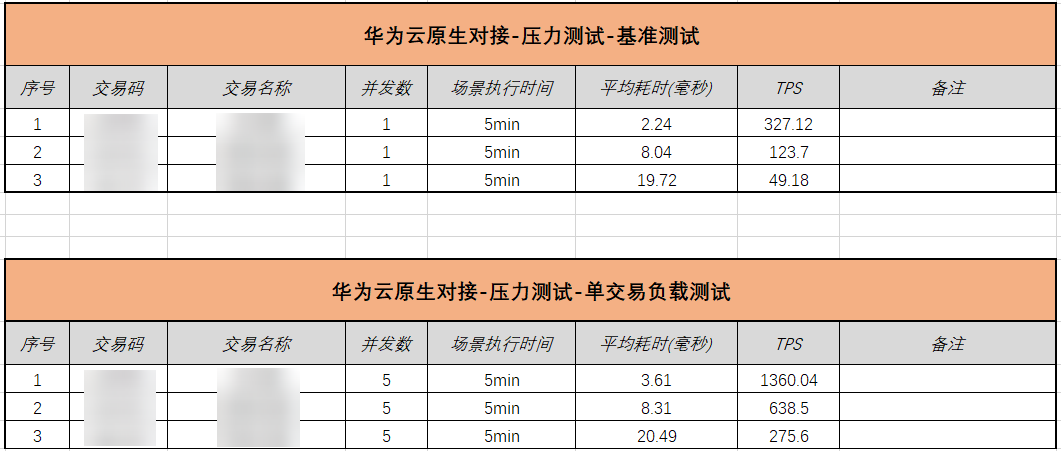
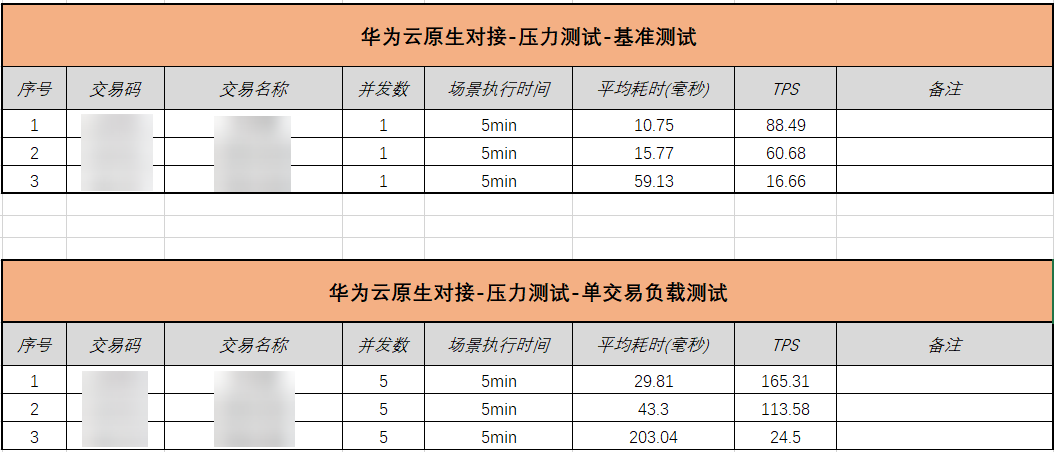 图4-2 虚拟机环境调测数据
图4-2 虚拟机环境调测数据
5 定位过程
通过对比物理机和虚拟机的OS参数、内核参数、jdk版本、jvm参数、活跃连接数等配置,尝试找出导致性能差异的关键因素。由于数据库为公用,且开发者反馈网关对压测性能影响不大,因而主要对xx.xx.xx.188(应用物理机)和xx.xx.xx.194(应用虚拟机)进行对比。5.1 JDK对比
刚开始,188使用的是openJDK1.8,而194使用的是毕昇JDK1.8,将188上的JDK替换成毕昇JDK1.8后,物理机环境压测性能明显提高,与虚拟机环境基本持平。图5-1 物理机-openJDK-tps
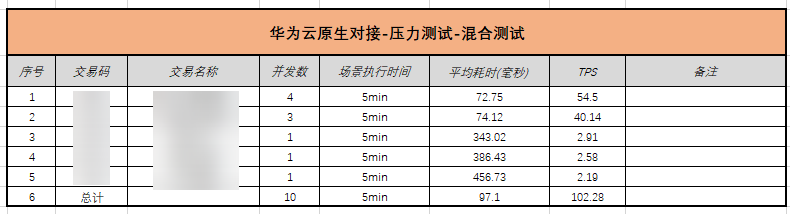
表5-1 毕昇JDK-tps对比
|
并发VUser数 |
虚拟机环境tps/s |
物理机环境tps/s |
|---|---|---|
|
10 |
863.2 |
821.5 |
|
20 |
1546.2 |
962.0 |
|
30 |
2159.2 |
931.1 |
|
50 |
2991.4 |
892.6 |
5.2 操作系统对比
5.2.1 OS版本对比
操作都是kylin v10 SP2。图5-2 物理机(188)
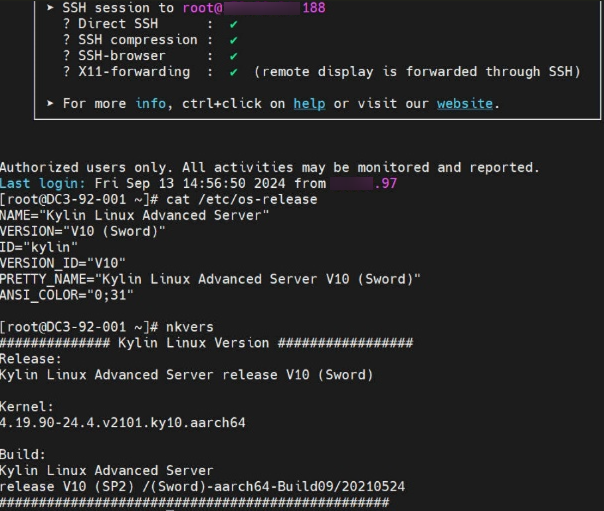
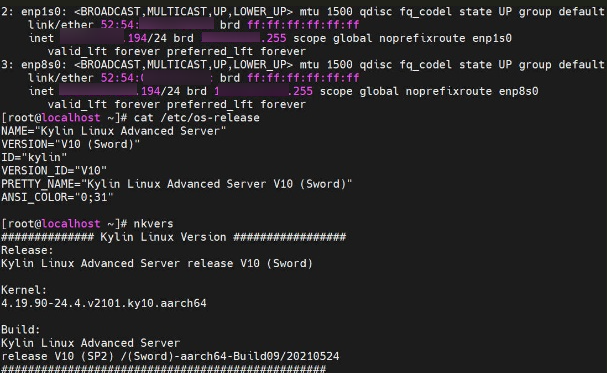
图5-3 虚拟机(194)
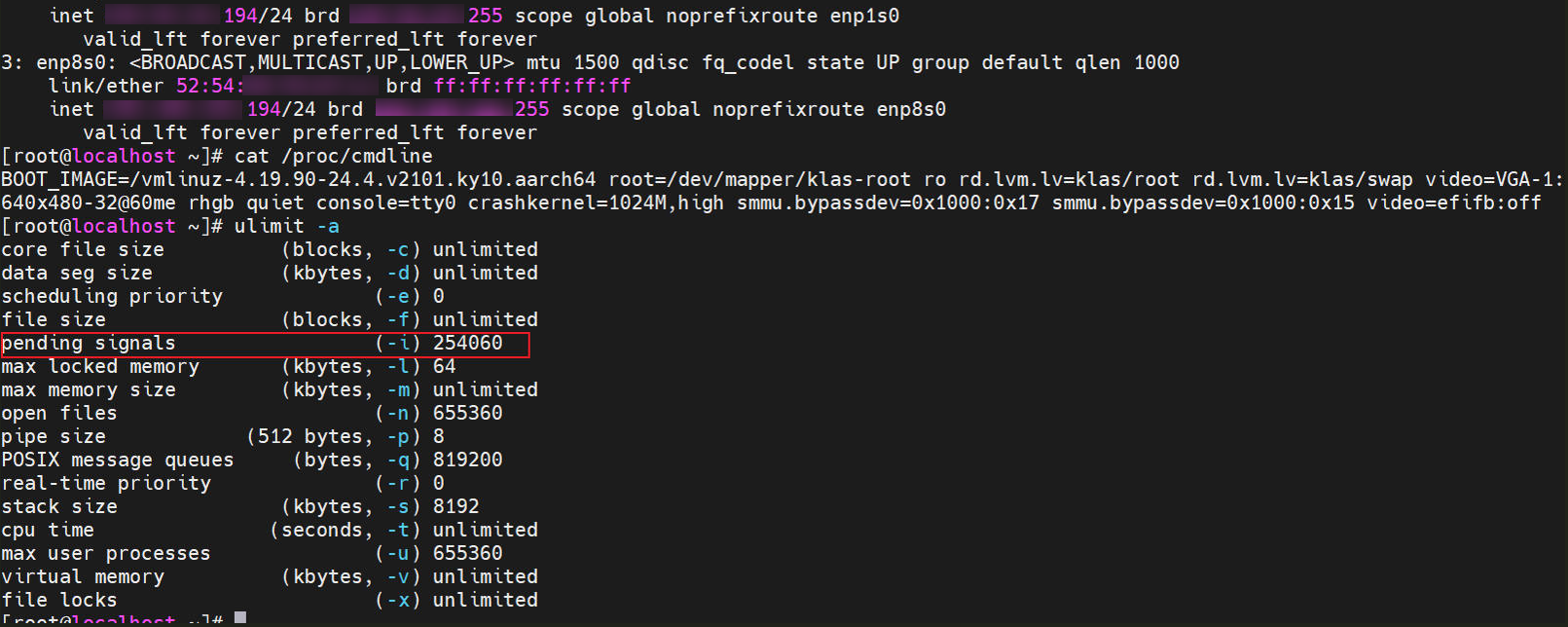
5.2.2 内核参数&&ulimit -a对比
内核参数可通过命令cat /proc/cmdline查看,物理机和虚拟机内核参数无差异,ulimit -a中pending signals参数值,物理机比虚拟机大,调节该参数与虚拟机一致后tps无变化,回退调整。图5-4 物理机
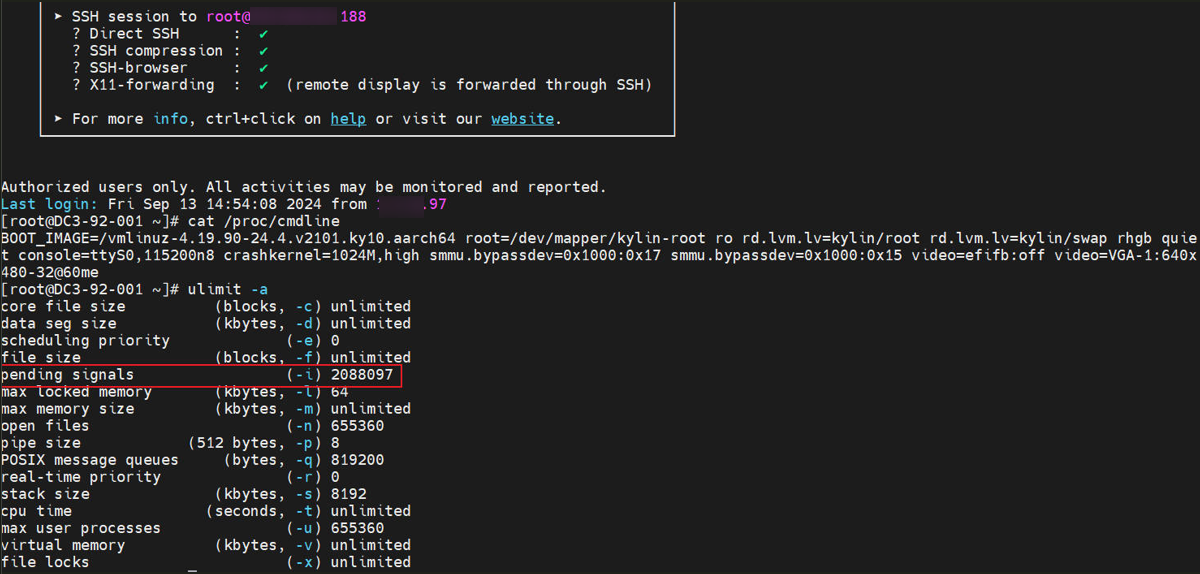 图5-5 虚拟机
图5-5 虚拟机
5.2.3 OS参数对比
操作系统参数可以通过sysctl -a > os参数.txt进行查看,分别导出物理机和虚拟机的OS参数后,用VScode等编辑器打开,可以较为直观的比较二者的差异。os参数对比同步.txt内容如下所示。
https://blog.csdn.net/liangdsh/article/details/51243099
net.ipv4.tcp_limit_output_bytes=1048576 用于限制TCP在发送大量数据时,Qdisc队列(如pfifo_fast)或设备队列中的数据量
net.core.dev_weight = 512 定义了每个CPU(或称为“软中断”)在处理这些数据包时可以“领取”的最大数据包数量
net.core.netdev_budget=1024 增加每次软中断处理的数据包数量
net.core.netdev_max_backlog=8000 指定在接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数。
net.core.optmem_max=524288 每个 socket(包括 TCP/IP 头部选项、路由信息等) 可以使用的最大选项缓冲区大小(以字节为单位)
net.core.rmem_default=2097152 定义了 TCP/IP 套接字接收缓冲区的默认大小(以字节为单位)
net.core.rmem_max=2097152 同上
net.core.somaxconn=512 控制了处于SYN_RECV状态的连接的最大数量,限制socket侦听积压
net.core.wmem_default=2097152 指定了socket发送缓冲区(send buffer)的默认大小(以字节为单位)。这个值影响TCP连接中数据的发送性能
net.core.wmem_max=2097152 同上
ulimit -a
pending signals,物理机2088097 虚拟机254060
tcp相关os参数
net.ipv4.tcp_thin_linear_timeouts 1/0, 启用该参数,低负载场景提高连接稳定性
net.ipv4.tcp_invalid_ratelimit 2000/500, 限制已有连接为了响应无效TCP报文发送重复ack的速率,表示发送重复ACK的间隔,单位是毫秒
物理机多出的参数
net.netfilter.nf_conntrack_tcp_be_liberal = 0 这个参数控制TCP连接的宽松跟踪模式是否启用,0表示不启用
net.netfilter.nf_conntrack_tcp_loose = 1 控制TCP连接的宽松跟踪。当设置为1时,允许conntrack模块在处理TCP连接时更加灵活
net.netfilter.nf_conntrack_tcp_max_retrans = 3 TCP连接重新传输的最大次数,在达到这个次数后,如果还没有收到对方的确认,连接将被认为是失败的
net.netfilter.nf_conntrack_tcp_timeout_close = 10 连接在CLOSE状态下的超时时间(以秒为单位)
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60 TCP连接处于CLOSE_WAIT状态时的超时时间
net.netfilter.nf_conntrack_tcp_timeout_established = 432000 TCP连接处于ESTABLISHED状态时的超时时间
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120 TCP连接处于FIN_WAIT状态时的超时时间。FIN_WAIT,单向关闭,等待确认
net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30 当TCP连接处于LAST_ACK状态时的超时时间,等待确认关闭时长
net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300 TCP连接在达到最大重传次数后,等待对方确认的超时时间
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60 TCP连接处于SYN_RCVD状态时的超时时间。SYN_RCVD状态表示已经收到对方的SYN包,并发送了SYN-ACK包,等待对方的ACK包
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120 当TCP连接处于SYN_SENT状态时的超时时间。SYN_SENT状态表示已经发送了SYN包,等待对方的SYN-ACK包
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120 当TCP连接处于TIME_WAIT状态时的超时时间。TIME_WAIT状态表示本地连接已经关闭
net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300 TCP连接在发送数据包后,如果没有收到对方确认的超时时间,适用于所有TCP数据包
net.netfilter.nf_conntrack_timestamp = 0 是否记录conntrack条目的时间戳。当设置为0时,不记录时间戳
net.netfilter.nf_conntrack_udp_timeout = 30 UDP连接在没有活动时的默认超时时间
net.netfilter.nf_conntrack_udp_timeout_stream = 180 被视为流的UDP连接的超时时间
表5-2 调整前后tps/s
|
并发数 |
调整前 |
调整后 |
|---|---|---|
|
10 |
831.9 |
821.5 |
|
20 |
924.9 |
962.0 |
|
30 |
909.6 |
931.1 |
|
50 |
823.0 |
892.6 |
5.3 应用对比
开发者反馈部署在虚拟机和物理机上的应用版本一致,通过比对关键jar包的MD5值可以验证,应用版本确实一致。Md5值查看方式:md5sum xxx.jar。将虚拟机上的配置文件scp到物理机,再通过如下命令进行比较。
diff 虚拟机应用配置文件 物理机应用配置文件
对比结果显示:应用配置文件不存在差异。
5.4 调用栈时延分析
向开发者了解到压测时的入口函数为xxx.xxx.xxx.util.RestUtils execute,借助arthas分析工具,通过其trace命令和jad命令,逐步分析其耗时较长的调用栈,并与虚拟机应用中相同的方法进行调用耗时对比,若发现明显差异可让开发者排查对应方法的代码是否存在可优化点。最终未发现明显耗时差异较大的方法。5.5 资源占用分析
通过iostat、free和top等命令,发现压测时内存磁盘读写并无瓶颈,虚拟机和物理机上资源使用率都很低。但是top命令对比可以发现几个明显的差异点:1. 虚拟机比物理机多起了一个业务相关应用bootstrap。
2. 物理机主业务进程占用CPU资源在5个左右,虚拟机在20个左右。
针对第一个差异点,询问开发者,开发者反馈不影响压测性能,物理机环境也有bootstrap应用,只是不跟业务应用在同一台虚拟机。
针对第二个差异点,通过pidstat -p {业务应用pid} -t 1 5 > thread.txt命令对比物理机和虚拟机主业务进程下的线程差异(当时未想到添加-u参数对比线程cpu资源使用情况,可以尝试一下),发现物理机多出很多XNIO-task和XNIO-I/O线程,查询资料得知与undertow默认配置有关,XNIO-I/O线程数默认为CPU核数,XNIO-task默认为8*CPU核数,调整配置文件使这两个线程配置与虚拟机一致后压测,性能无明显变化。
于是对网络进行排查,通过sar -n EDEV 1命令发现无丢包错包,通过sar -n DEV 1命令发现网卡利用率都在2%以下,随后,通过netstat -na|grep ESTAB > netstat.txt命令分别对比压测,不压测和刚关闭压测时物理机和虚拟机的活跃连接,发现压测时虚拟机比物理机多出大量活跃连接。
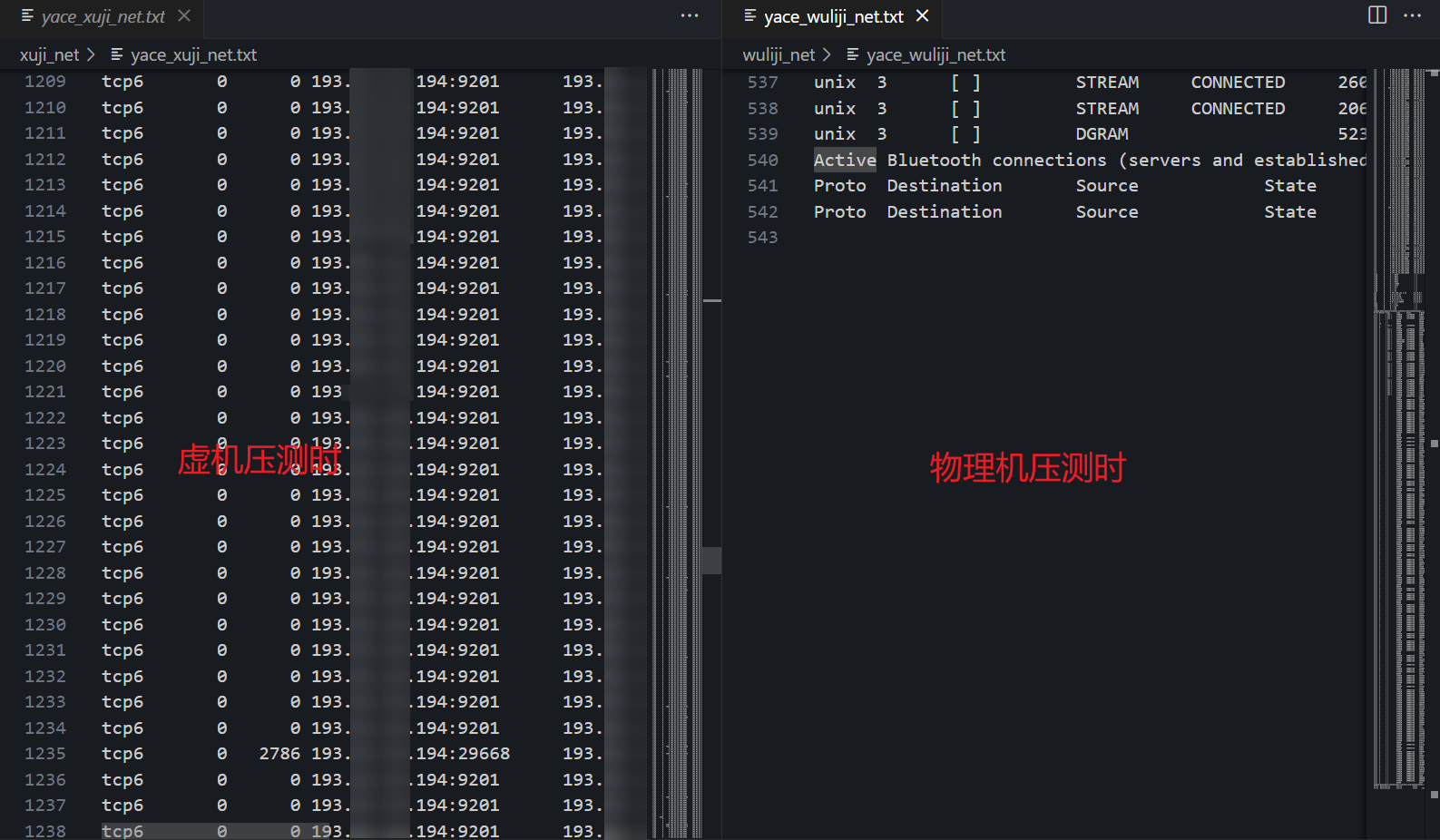
于是通过netstat的-p参数显示pid发现,多出来的连接正是由bootstrap产生的。这与开发者说的第一条差异点不影响压测性能相矛盾。于是又在虚拟机上找到bootstrap相关的应用目录,并将其copy到物理机上,在物理机上启动它,并相应的修改jmeter的压测脚本和bootstrap的配置文件,尝试修正组网,随后重新进行测试。最终结果,50并发下物理机压测的tps达到了4000+,优于虚拟机(3000左右)。
6 总结思考
1. 进行问题定位前,要先明确组网和压测时的业务流,如有不清楚的地方应及时与开发者沟通。2. 类似这种物理机与虚拟机性能存在明显差异的问题,在定位时,可以多将两套环境的资源使用情况,参数配置进行对比,寻找导致性能差异的关键gap。