


Doris性能调优实践
发表于 2025/09/09
0
作者 | 韩炯
1 实践背景介绍
客户大数据团队基于开源Apache Doris进行自研,现在鲲鹏服务器上有性能诉求,目标性能相对鲲鹏性能基线提升10%。
2 基础软硬件信息
2.1 硬件配置
|
鲲鹏硬件 |
配置信息 |
|---|---|
|
服务器型号 |
Taishan 2280*4 |
|
CPU型号 |
Kunpeng 5250 |
|
内存 |
128G*4 @2933 |
|
网卡 |
TM280 4*25GE |
|
硬盘 |
10*7.1T HDD |
|
RAID卡 |
NA |
|
GPU卡 |
NA |
2.2 设备组网
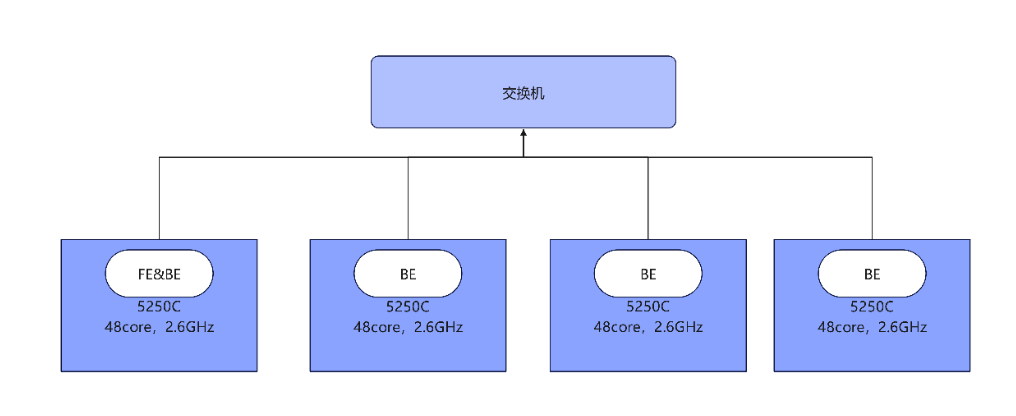
4台鲲鹏服务器连接到同一台支持交换机上,4台鲲鹏服务器的IP地址最后一位分别是1,2,3,4,因此下面用IP地址指代不同的鲲鹏服务器。
|
节点角色 |
主机节点名称 |
IP地址 |
说明 |
|---|---|---|---|
|
FE和BE |
1 |
192.xx.xx.1 |
主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作 |
|
BE |
2 |
192.xx.xx.2 |
|
|
3 |
192.xx.xx.3 |
||
|
4 |
192.xx.xx.4 |
主要负责数据存储、查询计划的执行 |
2.3 操作系统与软件信息
表2-1 操作系统与软件信息
|
名称 |
版本 |
说明 |
|---|---|---|
|
ctyunos |
2.0.1 |
客户现网环境OS |
|
Doris |
2.1.2 |
- |
3 性能调优实践
3.1 测试场景
在FE所在服务器上安装TPC-H工具包,该工具包在Doris源码的tools目录下,根据开源文档进行测试,整个测试模拟生成TPCH 500G的数据导入到Apache Doris 2.1.2-rc04。
3.2 调优前性能数据
使用鲲鹏5250自身对比测试数据库读写性能,主要测试500G数据量读写耗时,其性能指标如下表所示:
|
查询语句 |
第一次查询耗时(ms) |
|---|---|
|
q1 |
6239 |
|
q2 |
575 |
|
q3 |
5780 |
|
q4 |
3502 |
|
q5 |
8456 |
|
q6 |
916 |
|
q7 |
4347 |
|
q8 |
4326 |
|
q9 |
15572 |
|
q10 |
6642 |
|
q11 |
745 |
|
q12 |
1482 |
|
q13 |
6297 |
|
q14 |
591 |
|
q15 |
988 |
|
q16 |
1146 |
|
q17 |
2316 |
|
q18 |
16009 |
|
q19 |
3839 |
|
q20 |
1912 |
|
q21 |
9592 |
|
q22 |
1444 |
3.3 性能瓶颈分析
分析步骤如下所示。
步骤 1 在使用TPC-H测试Doris时,通过top指令排查网络、IO、内存等指标,并未发现性能瓶颈。
步骤 2 通过DevKit工具中NUMA精细化分析查看Doris应用进程,发现存在跨NUMA问题。通过NUMA绑核,进行TPC-H测试,发现性能不升反降。通过分析发现,是由于客户环境服务器内存共128G,进程绑核内存利用率降低,导致性能下降,故恢复NUMA绑核操作。
步骤 3 通过火焰图分析Doris应用调用栈情况,发现bshuf_shuffle_bit_eightelem_NEON占比高达59%。
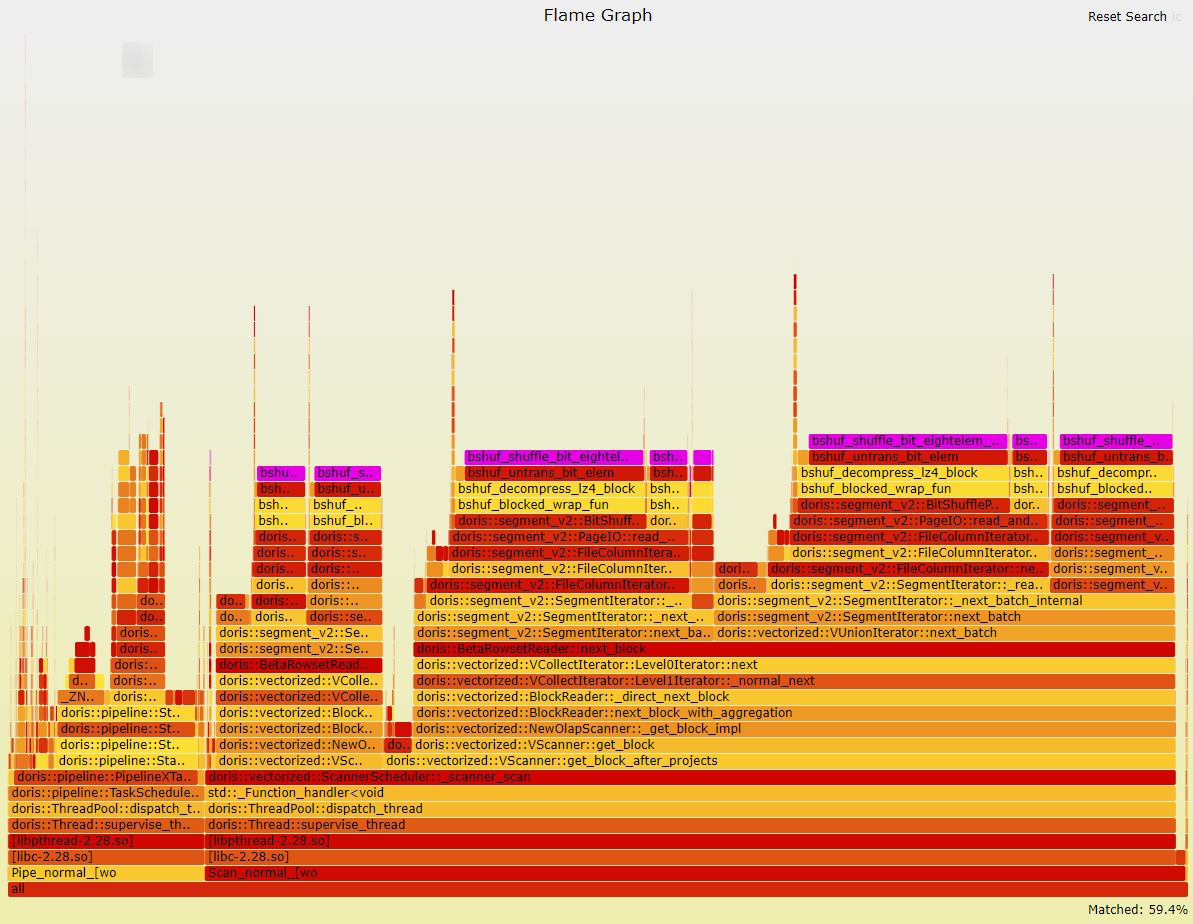
步骤 4 通过修改bitshuffle_core.c文件中的bshuf_shuffle_bit_eightelem_NEON,TPC-H整体性能提升了20%,火焰图占比也减少了83%。
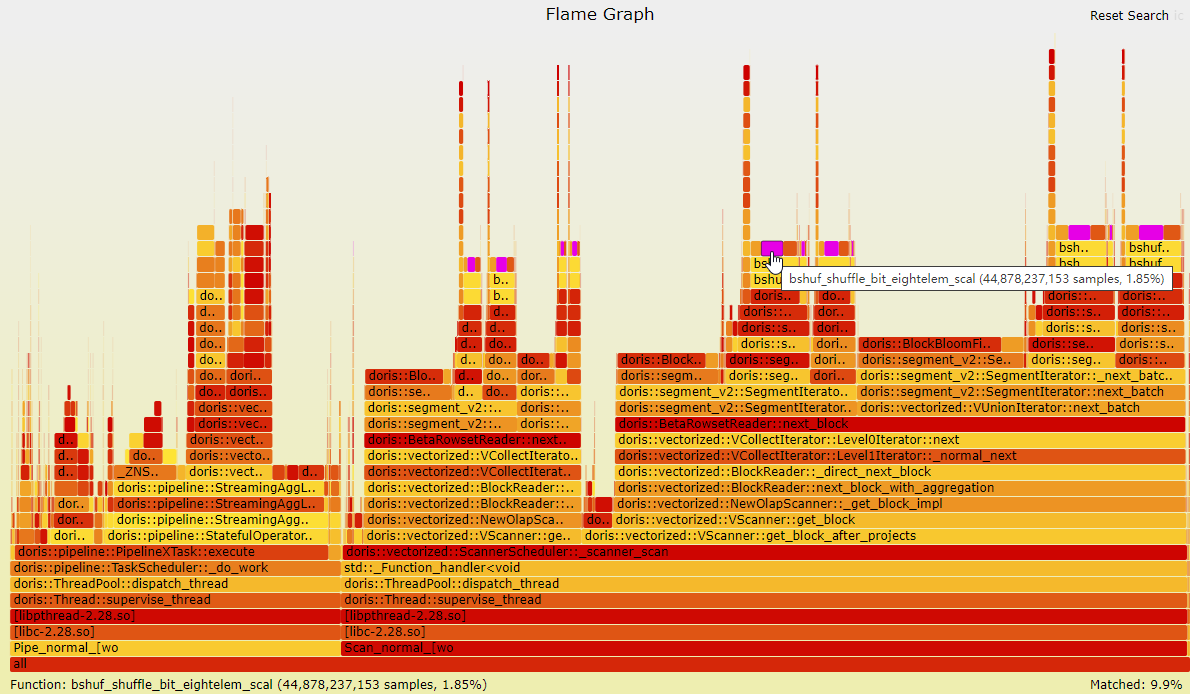
----结束
3.4 调优实施
3.4.1 BIOS参数调优
以下是BIOS参数的通用调优,建议在大数据调优前统一设置。
|
参数 |
调优步骤 |
默认值 |
调优值 |
参数解释 |
|---|---|---|---|---|
|
性能模式 CustomPowerPolicy |
1. 服务器重启,进入BIOS,依次选择“BIOS->Advanced->Performance Config->Power Policy”。 2. 设置“Power Policy”选项为“Performance”,按F10保存BIOS配置。 |
Efficiency |
Performance |
设置CPU为性能模式,提高主频,发挥CPU最大性能。 |
|
CPU预取 CPUPrefetchConfig |
1. 服务器重启,进入BIOS,依次选择“BIOS->Advanced->MISC Config->CPU Prefetching Configuration”。 2. 设置“CPU Prefetching Configuration”选项为“Disabled”,按F10保存BIOS配置。 |
Enabled |
Enabled |
CPU将内存中的数据读到CPU的高速缓冲Cache时,会根据局部性原理,除了读取本次要访问的数据,还会预取本次数据的周边数据到Cache里面,如果预取的数据是下次要访问的数据,那么性能会提升,如果预取的数据不是下次要取的数据,那么会浪费内存带宽。 |
|
内存刷新 DdrRefreshRate |
1. 服务器重启,进入BIOS,依次选择“Advanced->Memory Config->Custom Refresh Rate”。 2. 设置“Custom Refresh Rate”选项为“Auto”,按F10保存BIOS配置 |
32ms |
Auto |
设置该参数之后,会使85°C下刷新率为64ms,减少刷新频率会提升内存性能,85°C上将为32ms。 |
|
是否开启SMMU EnableSMMU |
1. 服务器重启,进入BIOS,依次选择“BIOS->Advanced->MISC Config->Support Smmu” 2. 设置“Support Smmu”选项为“Disabled”,按F10保存BIOS配置 |
Enabled |
Disabled |
服务器上的SMMU一般用来完成设备的地址转换,并且可以实现设备隔离,在虚拟化中很实用,但是在物理机测试场景下,SMMU可能会导致性能下降,尤其对于小包网络场景,因此建议关闭该功能提升服务器性能。 |
|
是否使能DIE交织 Die Interleaving |
1. 服务器重启,进入BIOS,依次选择“BIOS->Advanced->Memory Config -> Die Interleaving”。 2. 设置“Die Interleaving”选项为“Disable”,按F10保存BIOS配置。 |
Disabled |
Disable |
使能DIE交织能充分利用系统的DDR带宽,并尽量保证各DDR通道的带宽均衡,提升DDR的利用率,开启后进行细粒度化绑Numa会存在跨CPU die的时延。 |
|
单CPU单Numa One Numa Per Socket |
1. 服务器重启,进入BIOS,依次选择“BIOS->Advanced->Memory Config->One Numa Per Socket”。 2. 设置“One Numa Per Socket”选项为“Disable”,按F10保存BIOS配置。 |
Disabled |
Disable |
“Die Interleaving”参数为开启状态时,CPU下内存形成对称配置,CPU会自动整合成一个Numa,细粒度化绑Numa会存在跨CPU die的时延。 |
3.4.2 OS参数调优
以下是OS参数的通用调优,建议在调优前统一设置。
|
参数 |
调优命令 |
|---|---|
|
关闭并禁止内存大页 |
echo never > /sys/kernel/mm/transparent_hugepage/enable |
|
关闭SWAP(已默认关闭) |
swapoff -a |
|
设置系统最大打开文件句柄数 |
vi /etc/security/limits.conf |
3.4.3 毕昇编译器使用编译选项优化
由于Doris的开源版本较高,使用的Clang 16编译,所以需要使用毕昇较新版本4.0.0(对应Clang 17)去编译,使用O3、pgo、thinlto等编译选项结合使用,相对鲲鹏性能基线性能提升5%。
3.4.4 bitshuffle非向量化切换方案
步骤 1 修改“apache-doris-XXX-src/thirdparty/src/bitshuffle-0.5.1/src/bitshuffle_core.c”文件,修改1808行和1827行,将USEARMNEON判断去掉,使代码走非向量化分支。
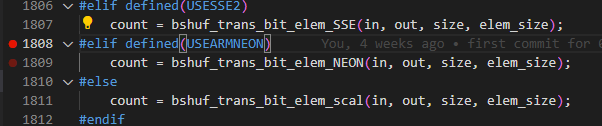

修改后:
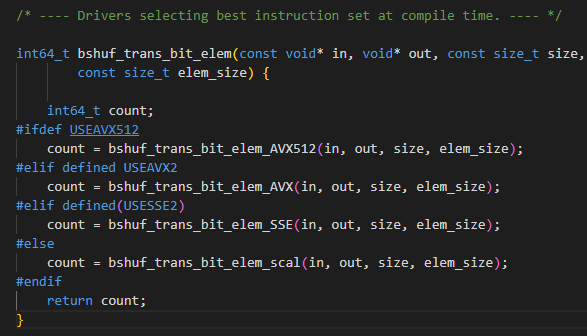
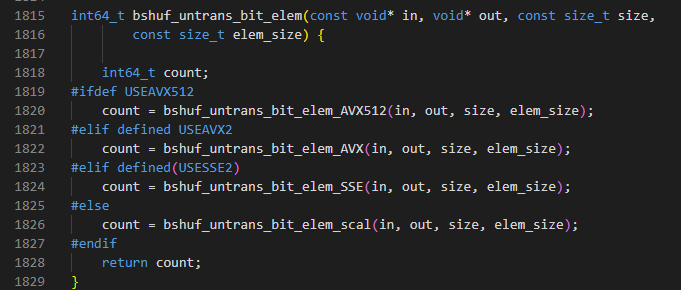
步骤 2 重新运行“apache-doris-xxx-src/thirdparty/build-thirdparty.sh”,重新编译第三方依赖。
步骤 3 重新按照官方文档运行build.sh编译Doris包。
步骤 4 使用编译出来包将环境上的包进行替换。
----结束
4 实践总结
经过调优后,Doris软件在鲲鹏集群上,相对鲲鹏性能基线整体提高20%+。
表4-1 性能提升比率
|
查询语句 |
基线数据(ms) |
优化后耗时(ms) |
性能提升比率 |
|---|---|---|---|
|
q1 |
6239 |
4610 |
26.11% |
|
q2 |
575 |
406 |
29.39% |
|
q3 |
5780 |
3933 |
31.96% |
|
q4 |
3502 |
2519 |
28.07% |
|
q5 |
8456 |
8176 |
3.31% |
|
q6 |
916 |
347 |
62.12% |
|
q7 |
4347 |
3508 |
19.30% |
|
q8 |
4326 |
2206 |
49.01% |
|
q9 |
15572 |
12885 |
17.26% |
|
q10 |
6642 |
5627 |
15.28% |
|
q11 |
745 |
487 |
34.63% |
|
q12 |
1482 |
805 |
45.68% |
|
q13 |
6297 |
5271 |
16.29% |
|
q14 |
591 |
533 |
9.81% |
|
q15 |
988 |
870 |
11.94% |
|
q16 |
1146 |
985 |
14.05% |
|
q17 |
2316 |
1094 |
52.76% |
|
q18 |
16009 |
14244 |
11.03% |
|
q19 |
3839 |
1677 |
56.32% |
|
q20 |
1912 |
1403 |
26.62% |
|
q21 |
9592 |
6882 |
28.25% |
|
q22 |
1444 |
1277 |
11.57% |
|
总计 |
102716 |
79745 |
22.36% |
5 故障排查
5.1 毕昇编译时链接错误
问题现象
环境上安装了开源Clang 16及毕昇编译器,并配置了全局环境变量,客户用毕昇编译器编译Doris时,无法找到libstdc++.so.6。
可能原因
怀疑是环境问题,通过全局搜索libstdc++.so.6,发现存在该文件,后面又看了环境变量,发现搜索的路径下没有该文件,于是通过创建软链接,找到该文件。
解决方法
重新编译Doris,libstdc++.so.6文件找不到的问题已解决。
5.2 lz4加速库替换后性能未提升
问题现象
Doris代码中通过替换lz4加速库,数据导入测试压缩性能未提升。
可能原因
通过火焰图分析,并未调用到lz4加速库优化的接口,通过咨询lz4开发团队,客户替换的文件不对,需要把kzl.a放到lz4根目录下,并且修改build.sh后重新编译,会生成新的liblz4.a,并把该文件替换到第三方库中。
解决方法
1. 替换kzl.a放到lz4根目录下,修改build.sh,把图中方框内容注释掉。
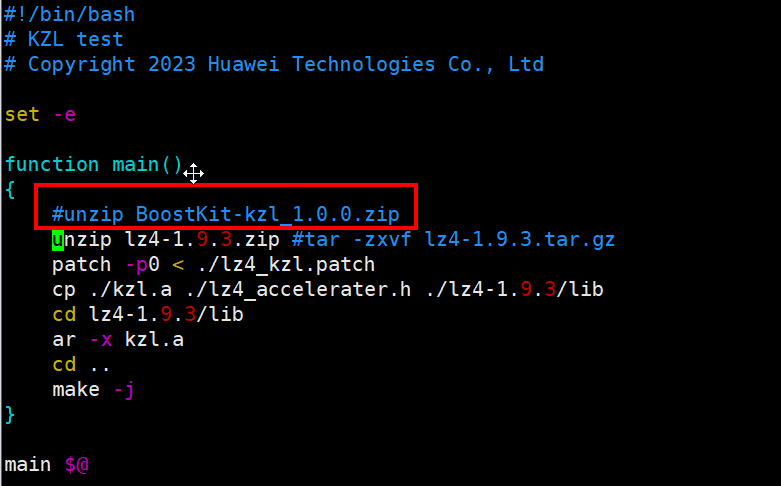
2. 重新编译,生成liblz4.a。
3. liblz4.a放到Doris第三方库中,并且重新编译Doris。
4. 通过火焰图查看压缩接口调用,已经替换为加速接口。
5. 通过TPCH导入数据到Doris,压缩性能提升5%。