


区块链平台性能调优实践
发表于 2025/09/09
0
作者 | 刘坤
1 实践背景概述
某区块链平台A采用POS+POT (Proof of Space + Proof of Time)时空证明机制,借助廉价、冗余且高度分散的未使用硬盘存储空间来验证其区块链,从而创造一款优于比特币的数字货币。相比于比特币POW(Proof of work)通过算力来证明工作量的方式,某区块链平台A更加绿色、减少资源的浪费。
2 运行机制分析
某区块链平台A通过时间与空间的结合,构造了这样一种挖矿场景:用户将数据存储在硬盘驱动器上一段时间,而赢得区块记账权利的机会与分配的空间大小成正比。该机制通过与彩票中奖类似的方式,允许所有普通用户均可参与其中,而不需要任何特殊硬件、资金以及注册才可加入。
农场
农场像采矿,通过对硬盘驱动器上可用的闲置储存空间进行快照(播种),创建区块;个人收益根据个人农场存储空间占网络上总农场存储空间的百分比来决定,当你分配给农场的存储空间越多时,其收益越大。相对于比特币而言,平台A使用的带宽、空间都是闲置的,其所消耗的能量可以忽略不计,成为优于比特币的矿池、矿工、ASIC等根本所在。
播种
在平台A农场中,播种是一个过程,最初的播种过程通过随机输入的证明来填充农场空间,然后通过直接访问API读取驱动器,进行排序以快速的查找所得到的证明。对于普通的农民而言在最初设置时可以选择播种24h-48h。
平台A挖矿过程大致可分为两部分:挖矿和P图
挖矿:对于平台A来说,挖矿这一步其实非常轻松,重要的是容量,而不是速度,甚至对挖矿的主机也低到几乎没有任何要求。因为挖矿的过程就是等着网络广播一串数字,然后跟硬盘里的哈希值比较即可。哈希的比较运算是极快的,并不需要把数以T计的数据读进内存进行运算。这也确实符合平台A的出发点——绿色。任何人都可以使用闲置的存储容量加入平台A网络,挖矿几乎没有额外消耗能源,只要开着机,连着网络,就可以享受每天4608次的抽奖,而且是永久的。
P图:实际的挖矿过程中,P图阶段才是资源大量消耗的过程,只是消耗的并非集中在电力,而是SSD盘,通过算法在磁盘中写满算法计算而来的数据块,占满相应磁盘空间,高速大容量固态硬盘成为了真正的消耗品。这要归功于(是归功还是归咎,且看对存储行业的影响吧)平台A设计的计算机制。为了最终达到既能提供Proof of Space证明,又能足够快的进行检索这一目标,平台A制作plot的过程实际上分为四步(通常称为P1-P4阶段)。
a. 阶段1:这一阶段的工作为数据填充,平台A矿机需要消耗高速磁盘,将平台A程序自动生成的表格数据填写进高速磁盘。这一阶段主要受两个因素影响,一个是CPU、一个是磁盘速度。官方推荐用固态硬盘,普通硬盘也可以,但P盘效率会很低。该过程主要是7张表的计算生成。
b. 阶段2:数据计算,把第一阶段中生成的文件进行处理,生成新的文件。按照倒序,对数据表7到1逐个进行扫描和排序。
c. 阶段3:文件压缩,将第二阶段的数据压缩生成一个文件。
d. 阶段4:文件存储,将第三阶段中的压缩文件存储到硬盘之中。
整体运行流程图如下:
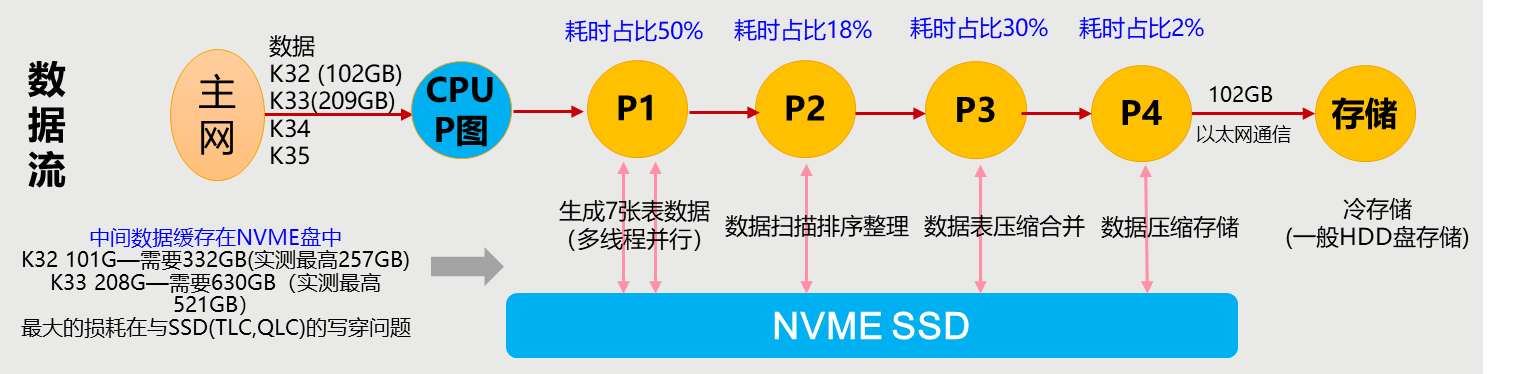
1. P1计算生成7张哈希表,主要使用的算法是前向传播。P1要处理大量的运算,占用CPU最为密集。其实这一步已经生成了足以支持Proof of Space的全部数据,只是效率欠佳,所以还需要后续步骤处理。--可多线程运行
2. P2用反向传播算法来清理一遍上面的7张哈希表,去除不必要的哈希值,并给表排序。这一步占用CPU也较为密集。--单线程运行
3. P3对上一步的结果进行压缩,并将大部分表合并起来。从这一步开始,对CPU的消耗降到了较低水平,对内存的占用仍维持在高位,但缓存盘的占用开始逐步下降,无关数据会自行删除。--单线程运行
4. P4把剩余的表继续压缩成最终的文件格式,并把文件从缓存盘转移到目标位置。这一步是唯一对目标磁盘进行IO操作的。--单线程运行
3 调优实践
3.1 基础调优实践
3.1.1 BIOS层优化
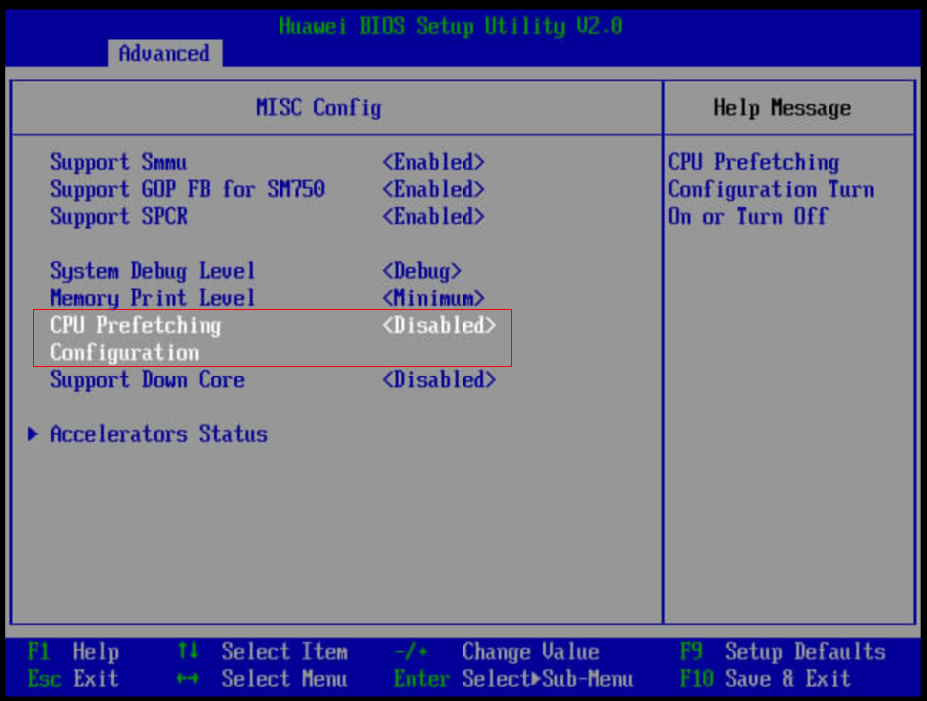
3.1.1.1 开启CPU预取
分析:结合微架构分析,平台A运行过程中在P1阶段,前端瓶颈30%,可以考虑开启CPU预取功能提升性能。
实施方法:依次进入“Advanced > MISC Config > CPU Prefetching Configuration”,将“CPU Prefetching Configuration”设置为“Enabled”。按F10保存BIOS配置。
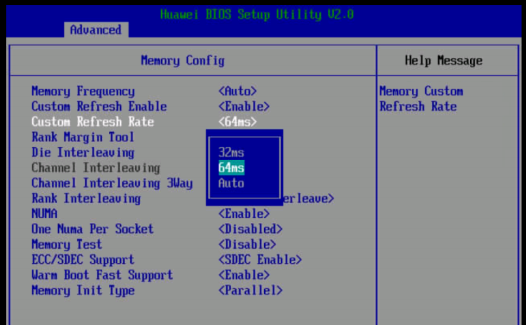
3.1.1.2 修改内存刷新频率为64ms
分析:内存刷新频率越高,在内存读写的时候stall的频率也越高,会影响数据的读写性能,平台A在P图过程中存在大量的数据与内存、磁盘IO的交付,通过降低刷新频率提升内存读写性能。
实施方法:依次进入“Advanced ->Memory Config-> Custom Refresh Rate”,将“Custom Refresh Rate”修改为“64ms”。按F10保存BIOS配置。
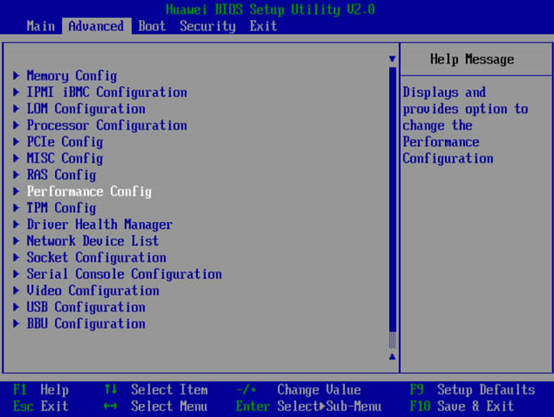
3.1.1.3 开启performance性能模式
分析:性能模式可以使整机工作在最佳的性能工况下,但同时会增加部分耗电,本测试场景可通过提升到performance模式获取最大的P图效率。
实施方法:开启CPU的performance模式(重启生效,也可在BIOS内配置永久生效)。
方法一:在OS层进行临时配置。
cpupower frequency-set -g performance
方法二:在BIOS层设置。
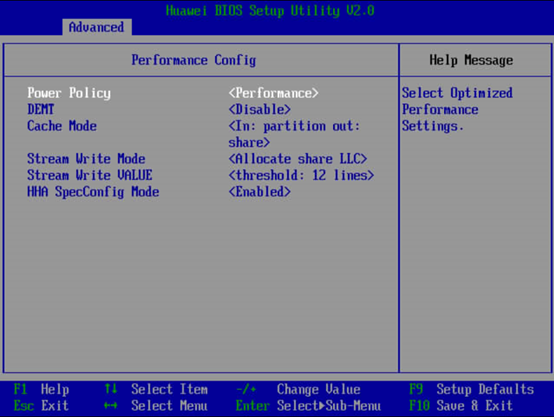
依次进入“Advanced ->Performance Config-> Power Policy”,将“Power Policy”修改为“Performance”。按F10保存BIOS配置。
3.1.2 OS层优化
分析:通过perf事件分析,TLB MISS较高,客户环境当前内存页为4K页,通过使用64K页提升TLB的命中率,进而提升业务性能。
3.1.2.1 调整内核Page Size为64KB
如果已经是64K页可跳过此优化措施。
步骤 1 查询当前内核Page Size。
[root@localhost linux-4.14.0-115.el7.0.1.aarch64]# getconf -a | grep PAGE
步骤 2 编译配置.config文件,更改页大小。
1. cd /root/rpmbuild/BUILD/kernel-alt-4.14.0-115.el7a/linux-4.14.0-115.el7.0.1.aarch64 (以实际机器上的kernel源码路径为准)。
2. make menuconfig
3. Kernel Features-->Page size (4KB)--> Page size (64KB) 保存 #Page size调整为4K。
步骤 3 参考华为云论坛进行编译和安装内核。
步骤 4 重新查询内核Page Size。
----结束
3.1.2.2 磁盘IO优化
分析:平台A业务场景中P2-P4都存磁盘IO的操作,通过IO脏页刷新等优化提升IO性能,进而优化P图效率。
1. /proc/sys/vm/dirty_expire_centiseconds:此参数表示脏数据在缓存中允许保留的时长,即时间到后需要被写入到磁盘中。此参数的默认值为30s(3000个1/100秒)。如果业务的数据是连续性的写,可以适当调小此参数,这样可以避免IO集中,导致突发的IO等待。可以通过echo命令修改。
# echo 2000 > /proc/sys/vm/dirty_expire_centisecs
2. /proc/sys/vm/dirty_background_ratio:此参数表示脏页面占用总内存最大的比例(以memfree+Cached-Mapped为基准),超过这个值,pdflush线程会刷新脏页面到磁盘。增加这个值,系统会分配更多的内存用于写缓冲,因而可以提升写磁盘性能。但对于磁盘写入操作为主的业务,可以调小这个值,避免数据积压太多最后成为瓶颈,可以结合业务并通过观察await的时间波动范围来识别。此值的默认值是10,可以通过echo来调整。
echo 8 > /proc/sys/vm/dirty_background_ratio
3. /proc/sys/vm/dirty_ratio:此参数表示脏页面占用总内存最大的比例,超过这个值,系统不会新增加脏页面,文件读写也变为同步模式。文件读写变为同步模式后,应用程序的文件读写操作的阻塞时间变长,会导致系统性能变慢。此参数的默认值为40,对于写入为主的业务,可以增加此参数,避免磁盘过早的进入到同步写状态。
3.2 热点函数优化
3.2.1 Glibc系统函数优化
在运行平台A的P图程序时,同步通过perf热点函数分析,发现存在glibc的memcpy等热点函数。
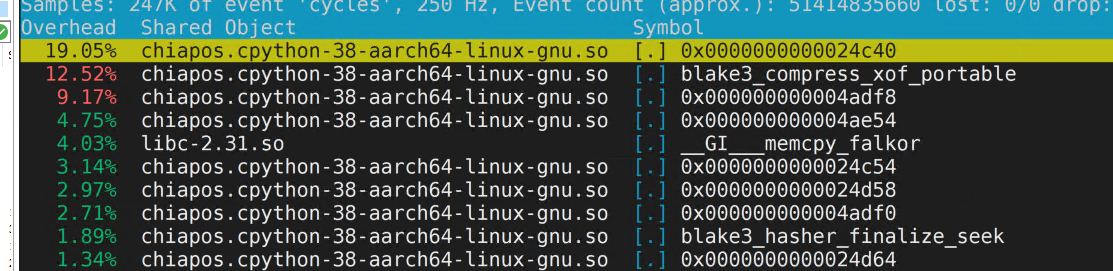
对于openEuler等操作系统的glibc版本>=2.31时已集成该加速库,无需使用该方法优化,可跳过;对于如centos7.6操作系统,其glibc版本为2.17,可使用该方法优化。
可以通过鲲鹏glibc加速库进一步优化,glibc加速库使用方法可参考华为云论坛。
3.3 多实例调优实践
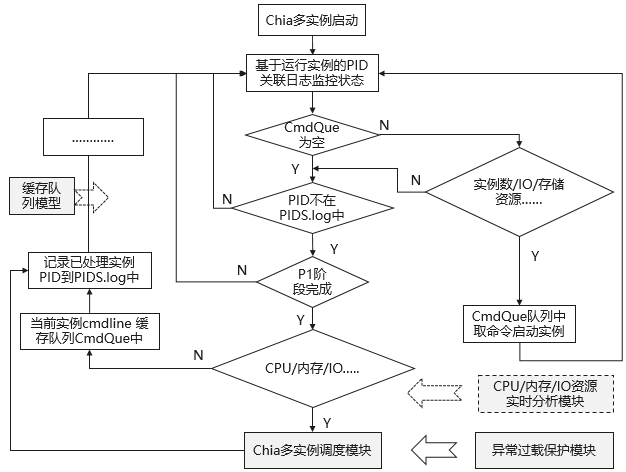
3.3.1 多实例调度方案设计
通过对平台A整个运行周期资源监控分析发现,P图阶段完全串行,唯有P1阶段允许多线程运行,剩余阶段均单线程运行,尝试多实例优化提升并行度,最大化单位时间CPU等资源使用率。
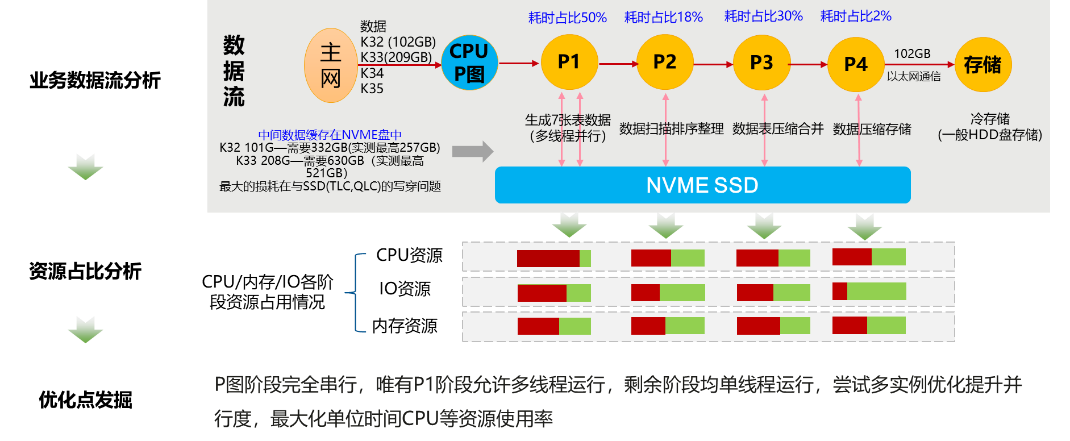
多实例调度优化方案:基于P1阶段运行状态,设计缓存队列模型,实时分析CPU/内存/IO资源,动态启动新实例,同步设计异常检测机制,防止资源过载。
在P2、P3、P4的IO、内存所需资源是明确的,在每个实例P1结束后,可以计算剩余的IO、内存资源,预留少量buffer后即可从缓存队列中启动平台A的新实例进行P图,周而复始,实现资源最大复用。
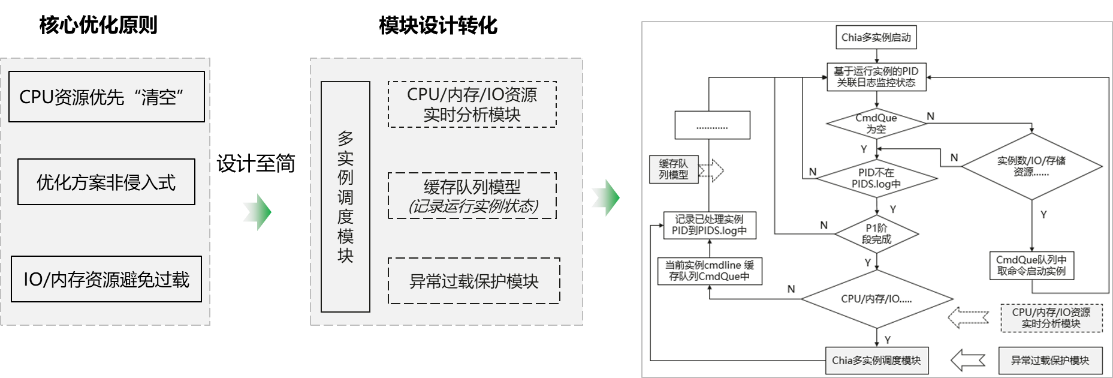
整体实现流程图如下:
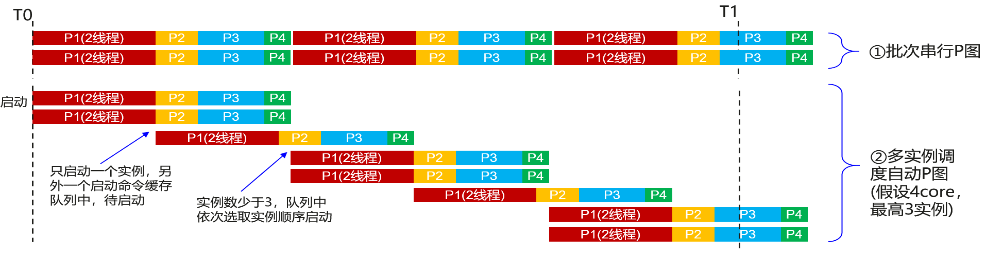
效果分析:假设4core资源,调度程序设定单盘最大实例数3。批次串行P图,T0-T1时间段完成实例数4,大部分时间CPU资源只使用了一半。多实例调度自动P图完成实例数6,CPU资源得到充分利用,P图效率得到提升。多实例自动调度优化方案无需代码修改,现网业务不中断,无感知动态优化。
3.3.2 硬件配置推荐说明
高性价比推荐Kunpeng 5220机型配置,普通型配置可使用Kunpeng 3210机型配置。
表3-1 Kunpeng 5220机型配置
|
配置项目 |
配置要求 |
|---|---|
|
处理器 |
Kunpeng 920 5220*2 32Cores 2.6GHz |
|
内存 |
总容量512GB(单条2933MHz 32GB*16条) |
|
NVMe SSD |
4*3.2TB |
|
P图结果存储盘 |
1.2TB*8 |
表3-2 Kunpeng 3210机型配置
|
配置项目 |
配置要求 |
|---|---|
|
处理器 |
Kunpeng 920 3210*2 24Cores 2.6GHz |
|
内存 |
总容量512GB(单条2933MHz 32GB*16条) |
|
NVMe SSD |
4*3.2TB |
|
P图结果存储盘 |
1.2TB*8 |
4 调优效果总结
本优化方案中提升最明显的为多实例优化方案,将Kunpeng 5230下整机资源利用率提升到90%,业务性能提升33.3%。综合基础性能优化、源码层级优化,整体业务性能提升45%。