


配置kdump服务内核参数后系统无法启动问题总结
发表于 2025/09/11
0
作者 | 谢忠华
一、问题背景
kdump
kdump是一种内核崩溃转储工具,可以在系统发生内核崩溃时将内存转储到硬盘中以便进行分析。
kdump机制在Linux 2.6.38被ARM平台内核主线接纳,它是通过两个内核实现的,在正常使用的系统内核外,通过启动另一个捕获内核来捕获系统内核信息的方法,进行转储操作。
1、系统内核正常启动,包括硬件自检,bootloader加载等常规过程,并预留内存空间给捕获内核。
2、加载捕获内核到预留内存空间。
3、系统发生崩溃,触发panic,捕获内核启动。捕获内核采用的是kexec机制,可以跳过硬件自检的环境,快速启动内核。
4、捕获内核通过/proc/vmcore内存镜像文件,收集系统内核信息。
5、将系统内核信息经过压缩,生成转储文件,写到磁盘中。
Kdump的配置文件位于:/etc/kdump.conf,可以配置转储文件的存储位置:NFS,SSH或者本地。
crashkernel
crashkernel是用于保存系统崩溃信息的内存区域,它的大小通常为系统内存的一小部分,一般为auto/512M/1024M(一般设置为auto即可,对于大内存系统,如512G内存,可以手动配置为1024M,防止进入捕获内核时发生OOM)。
在Linux系统中,crashkernel的内存分配是通过在启动时传递内核参数来实现的。具体来说,需要在grub或者其他引导程序中添加crashkernel参数,指定crashkernel的大小,crashkernel=<范围1>:<大小1>[,<范围2>:<大小2>,...][@偏移量],例如: crashkernel=128M@16M表示将从物理地址16MB处开始分配128MB的内存用于crashkernel。
在分配内存时,需要注意crashkernel的大小不能超过系统实际可用(系统保留的内存)的内存大小,否则会导致系统崩溃或者无法启动。同时,crashkernel的分配也会占用一部分系统内存,可能会影响系统性能。因此,需要根据实际情况合理设置crashkernel的大小。
通过dmesg | grep crashkernel查看crashkernel保存的位置。
客户在使用《鲲鹏技术疑难问题分析》配置kdump服务和内核参数后,重启服务器发现无法正常启动。
二、问题复现
1、复现环境
使用旗舰店裸金属服务器复现,系统配置如下:
| 硬件 | 配置信息 |
|---|---|
| 服务器型号 | TaiShan 200K(Model 2280K) |
| CPU型号 | Kunpeng 5231K |
| 内存 | 32G*12 @2933 |
| 网卡 | TM280 4*25GE |
| 硬盘 | 12*1.1T HDD |
| Raid卡 | SAS 3508 |
| GPU卡 | NA |
操作系统如下:
| 操作系统名称 | 版本 |
|---|---|
| CentOS | 7.6 |
| openEuler | 22.03 LTS |
2、复现步骤
启动kdump服务
一般操作系统默认是开启kdump服务的,可以通过systemctl status kdump查看服务的状态,处于“active (exited)”即是已启动。如未启动,则可以通过以下步骤进行启动:(以CentOS 7.6为例)
1、安装kdump工具。
yum install crash kexec-tools -y
2、配置grub参数并更新。
vim /etc/default/grub
grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfg
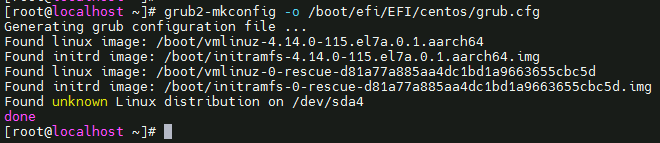
可以查看/boot/efi/EFI/centos/grub.cfg验证是否修改成功。
3、重启服务器。
reboot
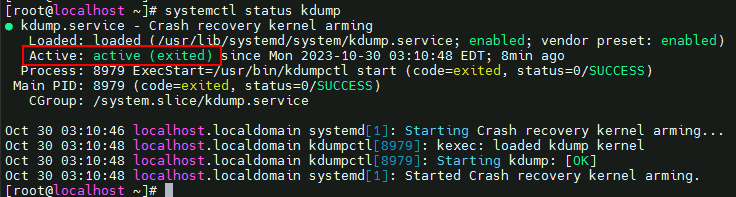
4、查看kdump服务。
systemctl status kdump
显示“active”时即为启动成功。
配置内核参数
将以下配置写入/etc/sysctl.conf文件:
kernel.hung_task_panic=1
kernel.hung_task_timeout_secs=60
kernel.softlockup_panic=1
vm.panic_on_oom=1
kernel.panic_on_warn=1
重启
重启后,旗舰店服务器系统无法正常启动,通过iBMC进入虚拟控制台,发现系统在选择完内核之后卡住在启动界面,如下图:
三、问题分析
1、收集系统日志。
登录iBMC后,下载维护诊断系统日志和系统串口日志,查看最近一次的启动日志,发现以下内容: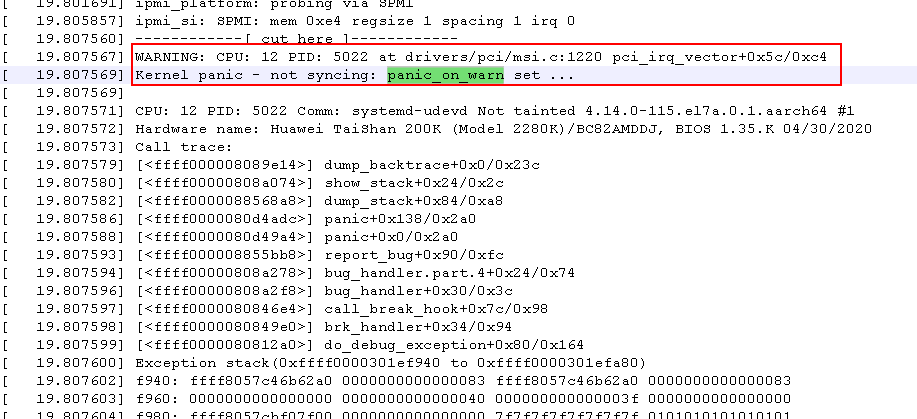
2、分析日志。
当内核发出WARNING后,由于配置了“kernel.panic_on_warn=1”参数,所以内核立即发生了“Kernel panic”,最终导致了系统无法正常启动。
查阅相关资料,“kernel.panic_on_warn=1”参数的作用是:在内核发生警告时,强制系统崩溃。这样可以确保在发生严重问题时系统能够及时停止运行,避免进一步的损坏或数据丢失。但是,这也会导致系统的可用性降低,因为即使是一些较小的问题也会导致系统崩溃。因此,建议仅在必要时才启用该参数。
查阅相关资料,上面的“WARNING:CPU:12 PID:5022 at drivers/pei/msi.c:1220 pci_irq_vector+0x5c/0xc4”告警通常表示:在drivers/pei/msi.c文件的第1220行中,pci_irq_vector 函数的执行出现了一些问题,具体来说,这个函数可能在尝试获取PCI设备的中断向量时遇到了一些错误或异常情况。可能就是硬件或驱动没有和系统完全适配,导致了内核发出告警。
3、复原系统验证。
复原系统之后,将/etc/sysctl.conf文件中的“kernel.panic_on_warn=1”参数删除,然后重新启动服务器,发现能够正常启动。同样查看系统启动日志: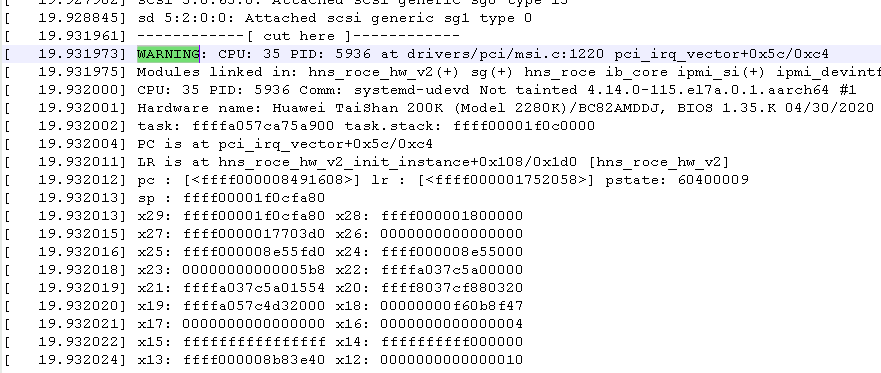
发现该“WARNING”仍然存在,但是系统能够正常启动。也验证了该“WARNING”不会导致系统启动失败,但是如果添加“kernel.panic_on_warn=1”参数则会导致内核发生panic,从而无法正常启动。
4、在openEuler上分析。
在同一个环境上安装有openEuler 22.03 LTS系统,启动后,查看相应的启动日志,发现没有产生WARNING告警。在/etc/sysctl.conf文件中添加“kernel.panic_on_warn=1”参数后,重启服务器也能正常启动,并无异常。
四、问题总结
修改内核参数
将/etc/sysctl.conf文件中的“kernel.panic_on_warn=1”参数删除。
由于原来系统启动时本身就有WARNING告警,且没有影响正常启动,所以可以不配置上述参数,另外根据经验,上述配置在内核出现问题时,能够帮助定位的信息不多,所以可以不配置上述参数。
保证软硬件的兼容性
如3-问题分析中所述,同一个环境,在openEuler 22.03 LTS上没有发生问题,而在CentOS 7.6的启动日志中有WARNING告警信息。
可能是因为CentOS 7.6很久之前就停止更新了,对一些新的硬件或驱动适配性没有那么好,而openEuler 22.03 LTS有更新的内核,在鲲鹏服务器上有更好的兼容性,所以没有告警信息,在配置了“kernel.panic_on_warn=1”参数后也能正常启动。