


ClickHouse应用调优实践
发表于 2025/09/11
0
作者 | 方原
1 实践背景介绍
基于鲲鹏920 5220/5250处理器对ClickHouse应用进行调优。
环境信息
硬件环境信息
|
CPU类型 |
鲲鹏920 5220处理器(32C*2) |
鲲鹏920 5250处理器(48C*2) |
|
CPU个数 |
2 |
2 |
|
内存 |
DDR4 32G*16 |
DDR4 32G*16 |
|
硬盘 |
SSD:447G SSD *2; HDD:14.6TB 7.2k SATA*28 |
SSD:447G SSD *2 HDD:14.6TB 7.2k SATA*28 |
|
Raid卡 |
12Gb RAID*1,Support RAID0/1/5/6/10/50/60 |
12Gb RAID*1,Support RAID0/1/5/6/10/50/60 |
|
网卡 |
10GE*2;1GE*4 |
10GE*2;1GE*4 |
|
说明 |
安装并测试用户ClickHouse应用。 |
安装并测试用户ClickHouse应用。 |
软件环境信息
|
软件名称 |
版本号 |
软件用途及简介 |
|
openEuler |
22.03 LTS |
鲲鹏920 5220/5250处理器操作系统。 |
|
ClickHouse |
22.8.13.20 23.3.4.17 |
用于查询和入库的测试。现网版本为22.8.13.20,同步也对23.3.4.17版本进行测试。 |
|
Java |
19.0.2 |
用于发包程序。 |
环境组网
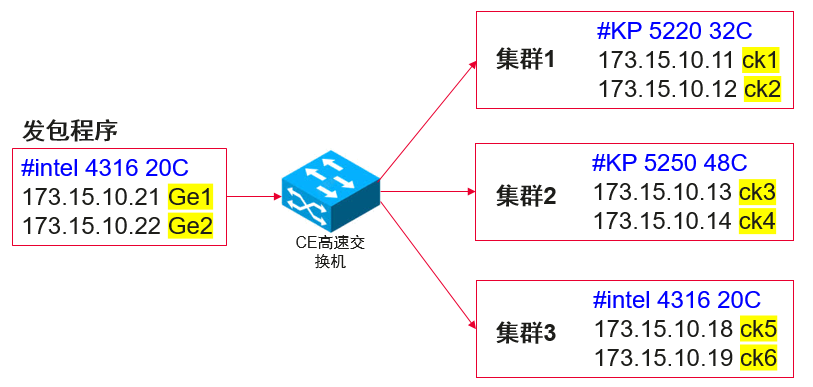
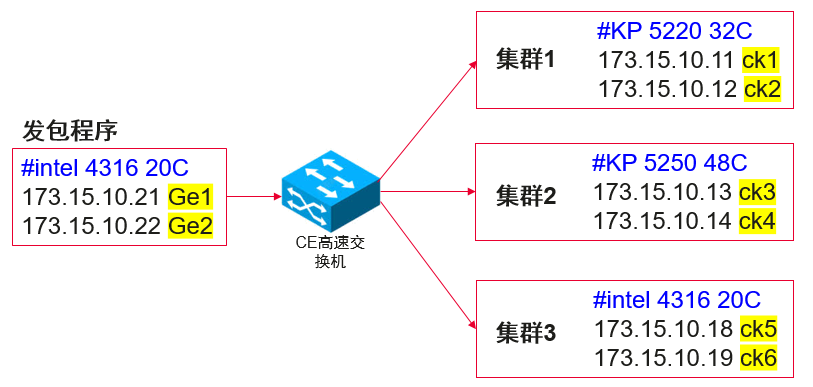
2 测试策略及用例
2.1 测试策略
测试观察指标为ClickHouse集群的数据入库速率和查询耗时性能。
测试的策略为动态入库-查询测试。
具体的测试方法为:华为编写并启动数据发包程序,向ClickHouse集群发送数据包。随着数据包的累计到达,ClickHouse集群利用定时任务进行数据的入库和数据库的查询,入库和查询同时进行,入库和查询脚本由用户提供。每天进行入库速率和每小时查询耗时的数据统计并绘制统计图,分析入库速率和查询耗时性能。查询所用SQL如下表。
|
测试SQL |
业务解析 |
|
select toDateTime(session_start_time / 1000000) as start_date,url,* from all_seg_ods_ipdr_mobile where toStartOfDay(toDateTime(session_start_time / 1000000)) >now()-interval 1 day and multiSearchAny(url,['550926','653313']) limit 100 format CSVWithNames; |
详单:关键字查询 从all_seg_ods_ipdr_mobile表中筛选符合条件的近一小时的数据。 |
|
select toStartOfFiveMinutes(start_date) t,count (*) c1,max(start_date) c2 from ( select toDateTime(session_start_time / 1000000) start_date from dae.all_seg_ods_ipdr_mobile where start_date>now()-interval 1 hour ) group by t order by t asc; |
详单:数据debug 从dae.all_seg_ods_ipdr_mobile表中提取过去一小时内的session_start_time记录,按时间升序排列。查询涉及子查询和max聚合操作,排序操作等。 |
|
select 'ipdr' xdrName, operator_name, round(msisdn_num*100.0/n,2) as "msisdn回填率", round(imsi_num*100.0/n,2) as "imsi回填率", round(imei_num*100.0/n,2) as "imei回填率", round(cgi_ecgi_num*100.0/n,2) as "cgi_ecgi回填率", round(app_feature_id_num*100.0/n,2) as "app_feature_id回填率" from ( select dictGetString('default.dict_operator', 'name', dictGetString('default.dict_probe', 'operator_code', ul_probe_id)) operator_name, count(*) n, sum(case when msisdn>0 then 1 else 0 end) msisdn_num, sum(case when imsi>0 then 1 else 0 end) imsi_num, sum(case when imei>0 then 1 else 0 end) imei_num, sum(case when cgi_ecgi>0 then 1 else 0 end) cgi_ecgi_num, sum(case when app_feature_id>0 then 1 else 0 end) app_feature_id_num from all_seg_ods_ipdr_mobile where toDateTime(toDateTime(session_start_time / 1000000)) >now()-interval 1 hour group by operator_name ) order by operator_name asc format CSVWithNames; |
详单:数据质量 计算并输出过去一小时内all_seg_ods_ipdr_mobile表中各运营商的不同字段的回填率,并按运营商名称升序排列。涉及子查询,获取字典字符串,count,sum等聚合操作,排序操作等。 |
|
SELECT uniqMerge(user_count) AS user_count, app_id, dictGetString('default.dict_app', 'name', app_id) AS app_name, operator_service_code, app_category_id FROM st_ipdr_app_user_day WHERE report_time >= today() --AND (operator_service_code = '2') AND (app_category_id = '4') GROUP BY app_id,operator_service_code,app_category_id ORDER BY user_count DESC LIMIT 100; |
报表:用户数 从st_ipdr_app_user_day表中提取当天的数据,按app_id、operator_service_code和app_category_id分组,计算每组的用户数量,并按用户数量降序排列,返回前100条结果。涉及uniqMerge聚合,分组,排序等操作。 |
|
select report_time, operator_service_code, operator_code, province, city, rat, pgw_ggsn, site_id, probe_id, sumMerge(total_ul_bytes) as total_ul_bytes, sumMerge(total_dl_bytes) as total_dl_bytes, sumMerge(total_ul_packets) as total_ul_packets, sumMerge(total_dl_packets) as total_dl_packets, sumMerge(total_ul_packet_loss) as total_ul_packet_loss, sumMerge(total_dl_packet_loss) as total_dl_packet_loss, sumMerge(total_internal_rtt_ms) as total_internal_rtt_ms, sumMerge(total_external_rtt_ms) as total_external_rtt_ms, sumMerge(session_count) as session_count, sumMerge(total_session_count) as total_session_count, sumMerge(xdr_count) as xdr_count from st_ipdr_probe_hour WHERE report_time >= today() group by report_time, operator_service_code, operator_code, province, city, rat, pgw_ggsn, site_id, probe_id order by report_time desc limit 100; |
报表:多维度多指标 从st_ipdr_probe_hour表中提取当天的数据,按多个字段分组,计算每组的各种总和,并按report_time降序排列,返回前100条结果。涉及sunMerge聚合,分组,排序等操作。 |
2.2 测试用例及测试结果
入库速率测试为记录下列语句的执行时间t,计算speed = size/t得到当前时刻t1的插入速度,其中size为插入数据的大小(MB)具体逻辑详见用户插入脚本。
tar -Oxzf $f | gnckbase client $opt --format_csv delimiter="$del" -query="INSERT INTO $table FORMAT CSV" $db $auth
查询耗时测试所用SQL见上,每小时分别在ck2,ck4和ck6上执行一次select.sql,统计查询结果。
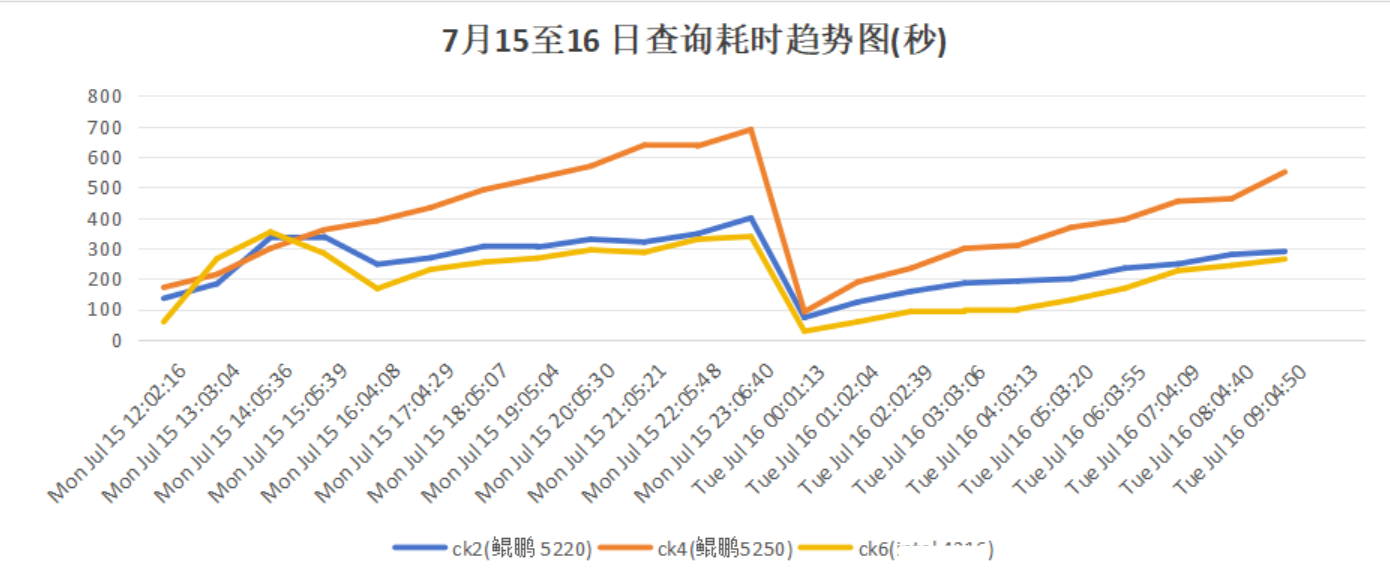
2.3 初始测试性能结果
查询情况:
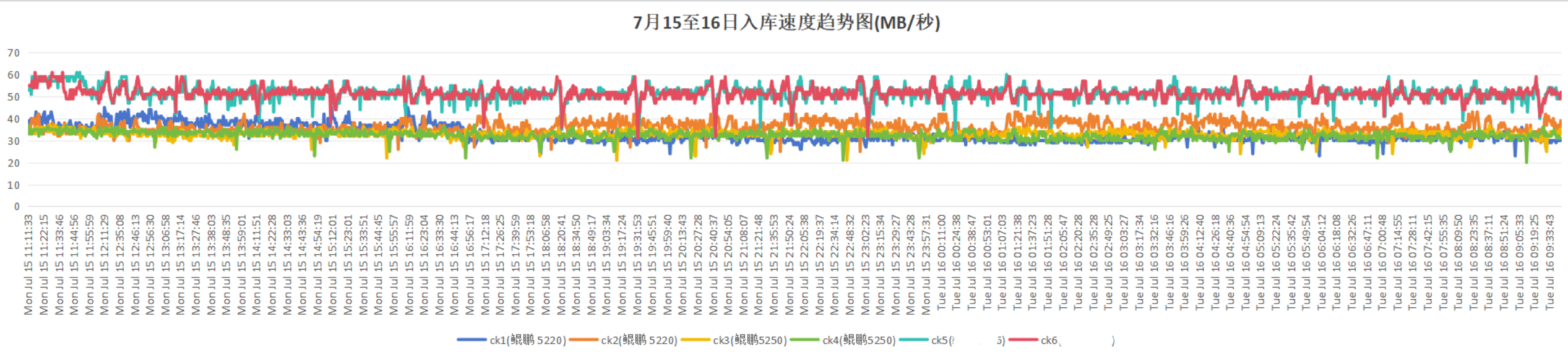
入库情况:
-
查询耗时:鲲鹏920 5220处理器<鲲鹏920 5250处理器。
-
入库速率:鲲鹏920 5220处理器≈鲲鹏920 5250处理器。
3 性能瓶颈分析
3.1 nmon分析
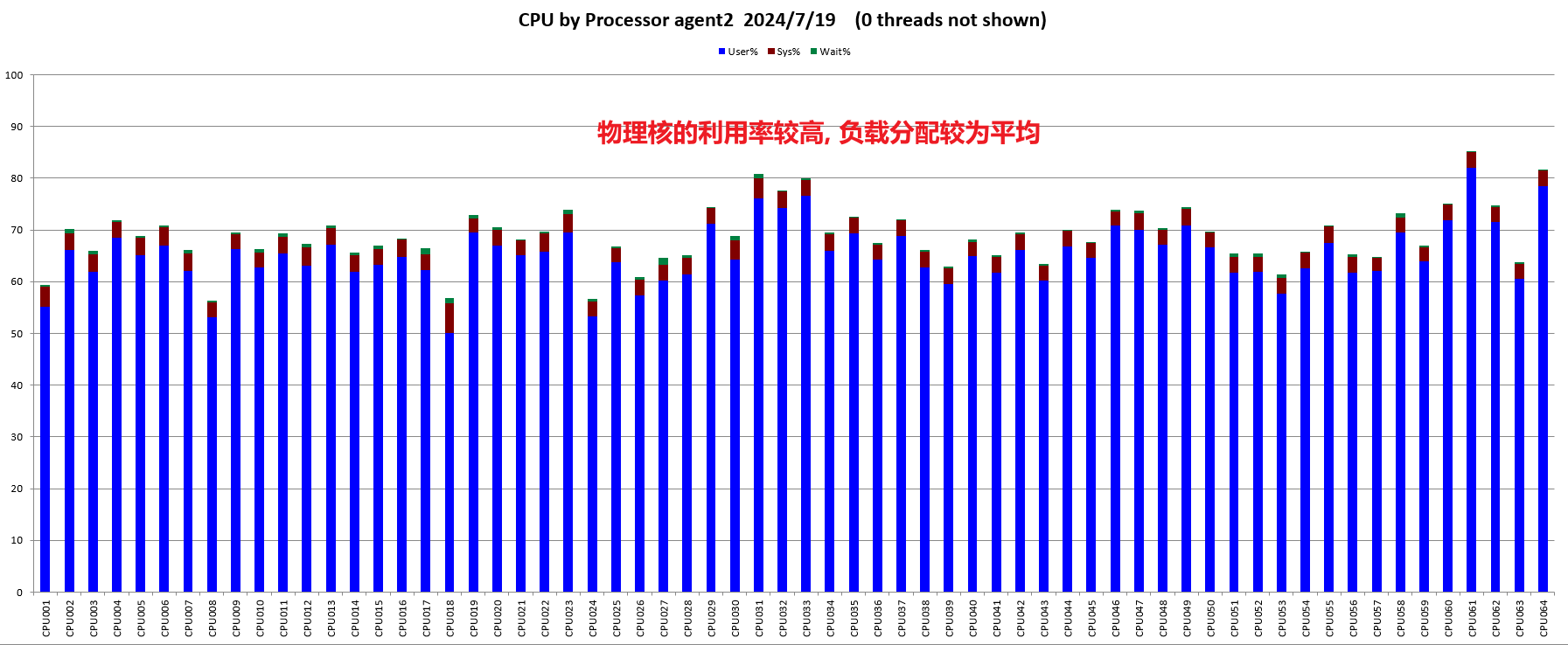
CPU:
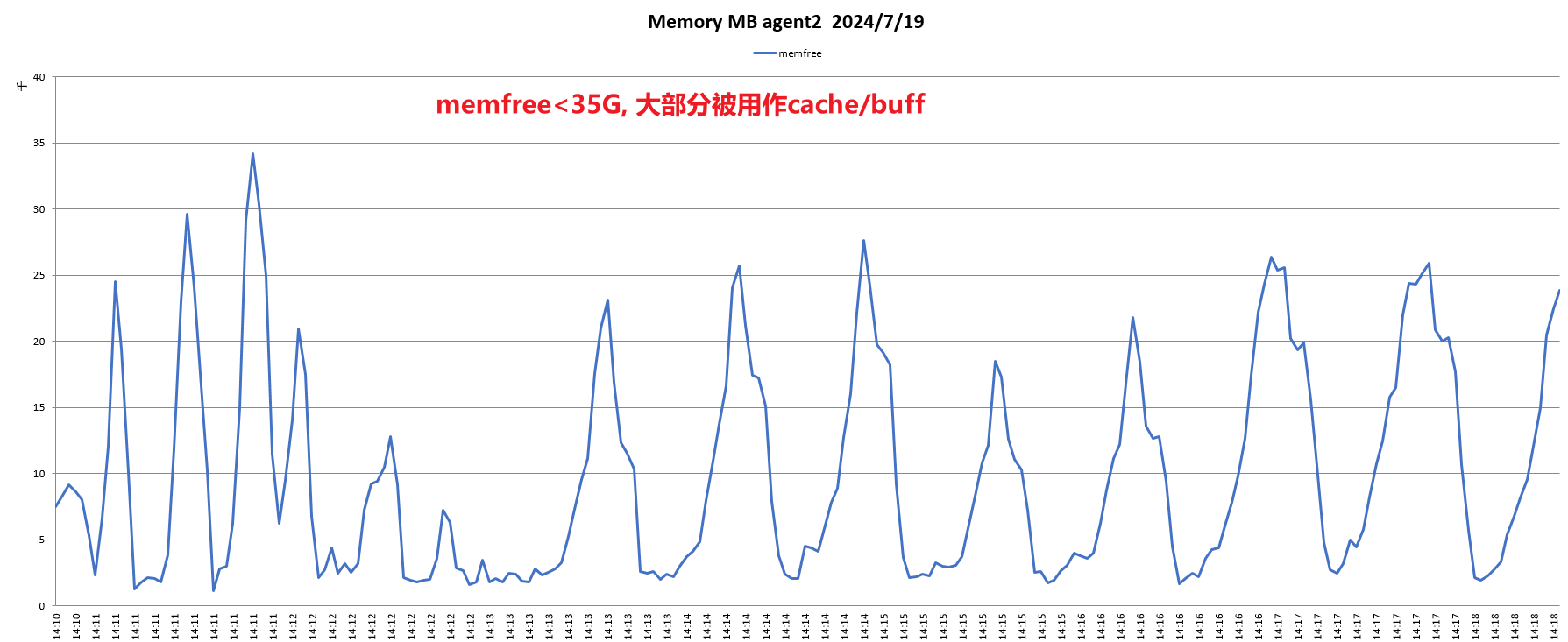
内存:
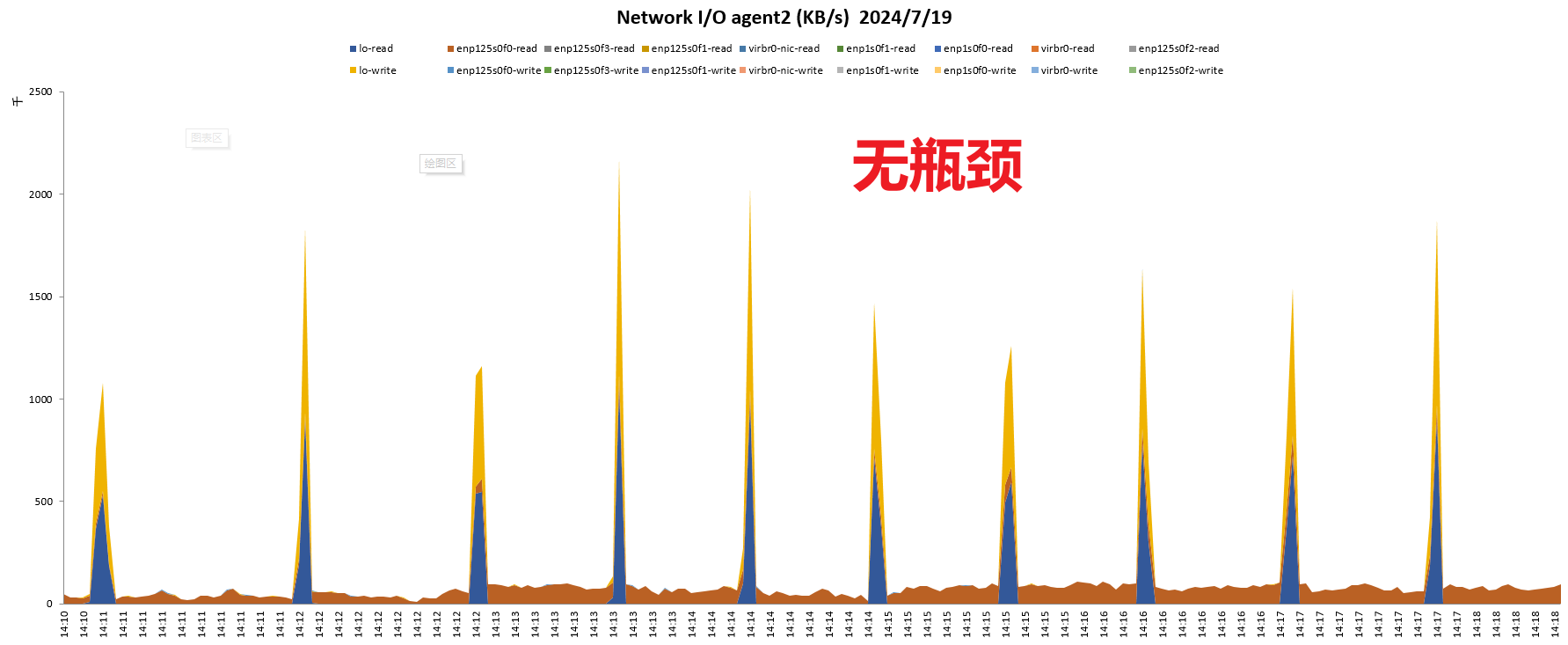
网络
I/O
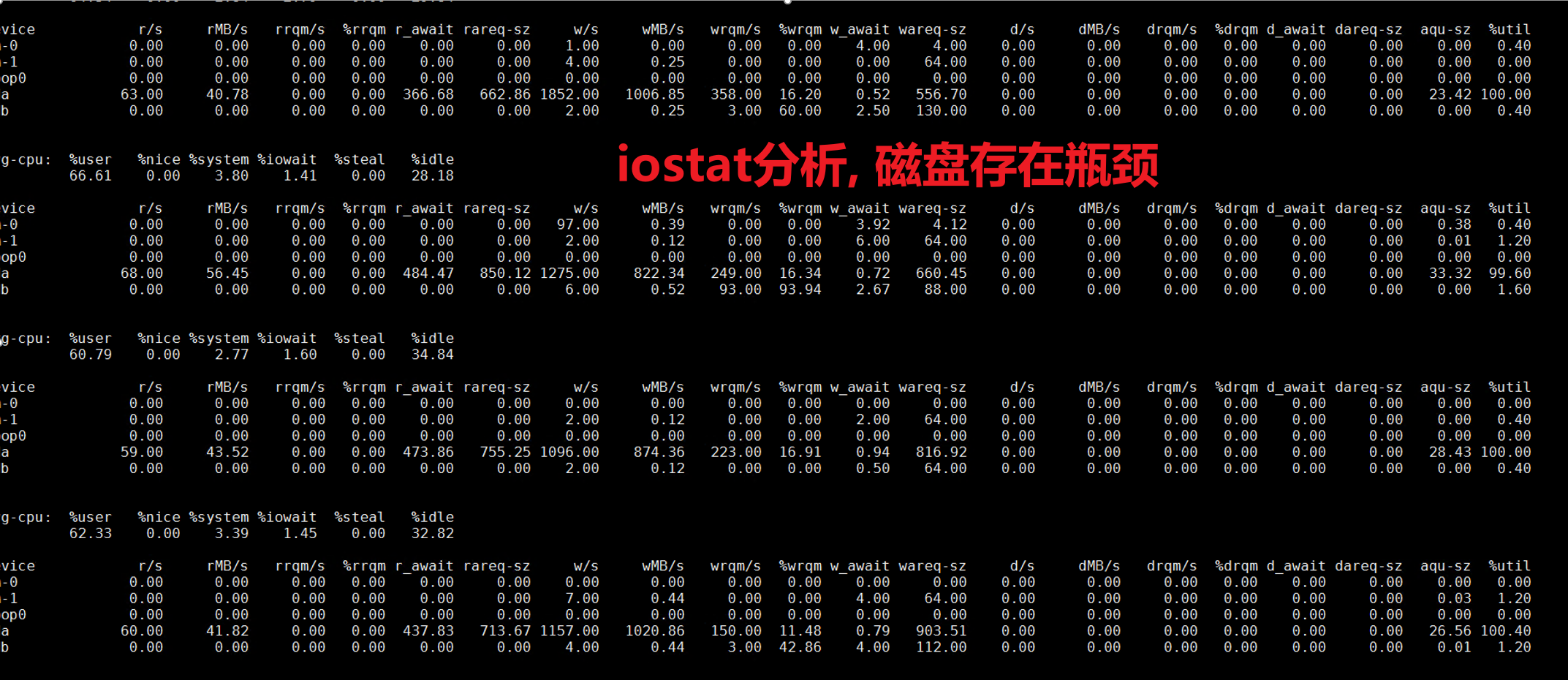
结论:鲲鹏920 5220处理器网络,内存均无瓶颈,IO过程中存在一定瓶颈。
3.2 perf分析
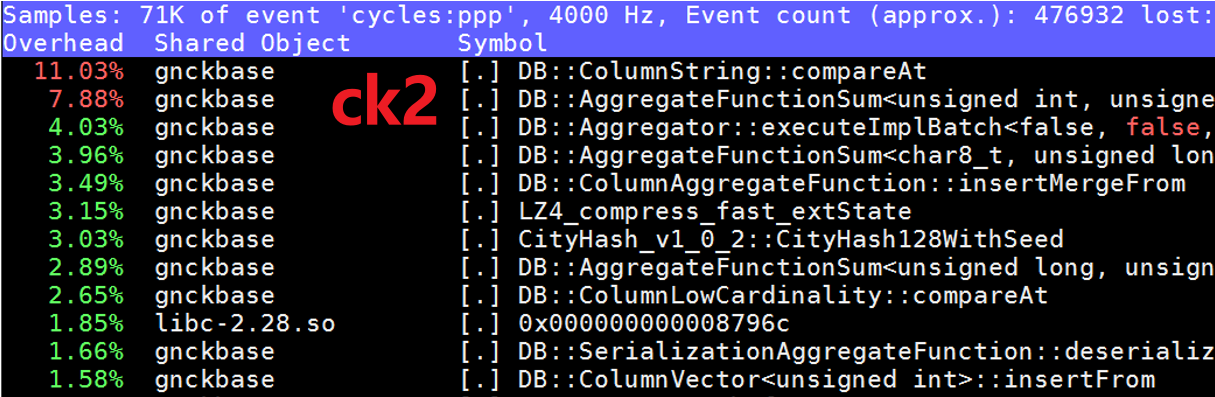
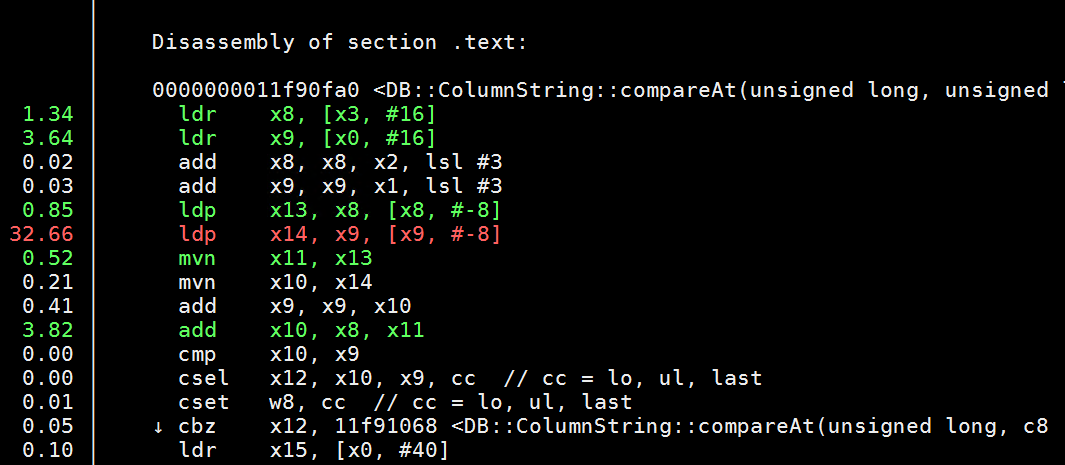
ck2中热点函数ColumnString::compareAt中有大量load指令,可以通过开启预取进行优化。
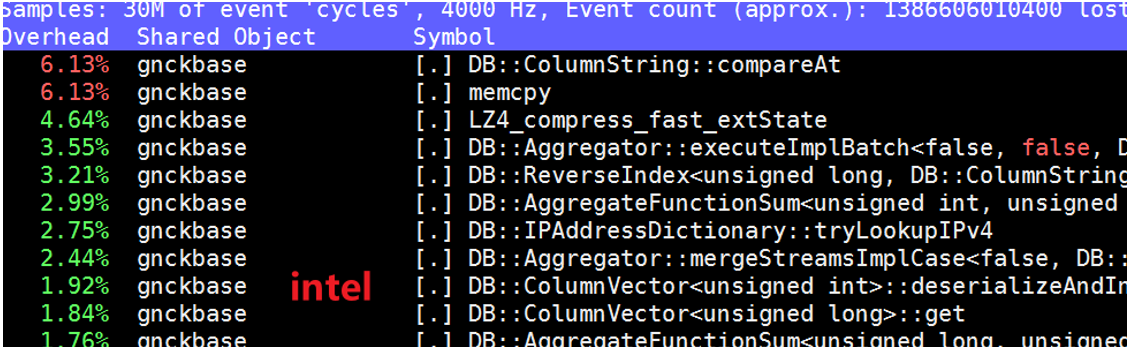
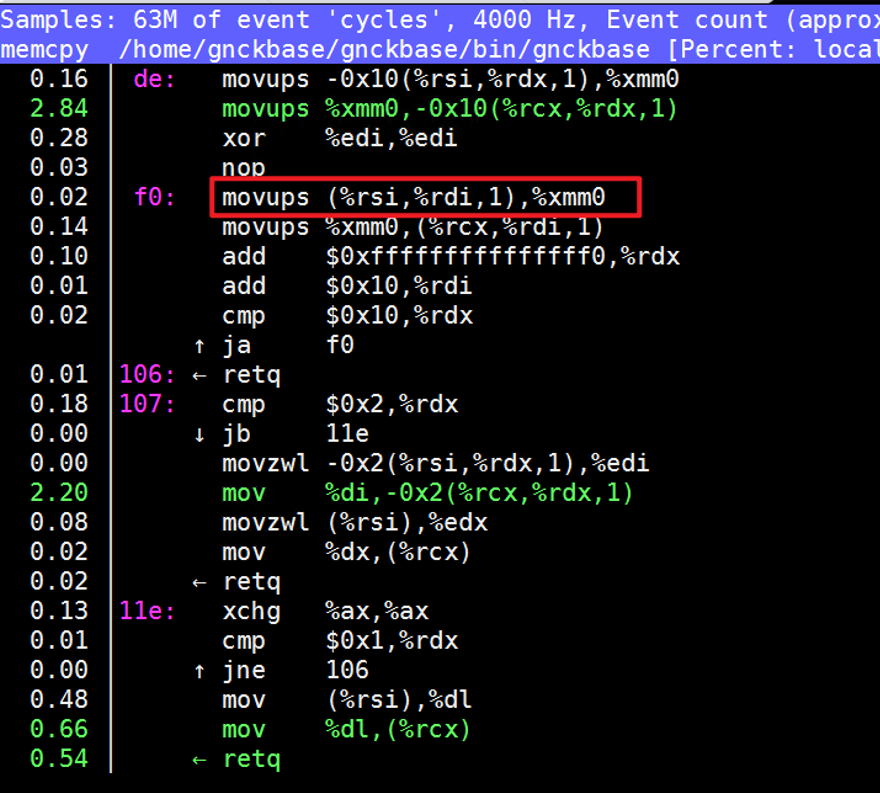
友商处理器中有一些热点,如memcpy,clickhouse此版本已经在底层适配过友商处理器的SSE指令集,如下图的movups,已作过一些向量化适配,运行速度更快,可以通过升级版本进行优化。
友商处理器中有一些热点,如memcpy,clickhouse此版本已经在底层适配过友商处理器的SSE指令集,如下图的movups,已作过一些向量化适配,运行速度更快,可以通过升级版本进行优化。
3.3 Topdown分析
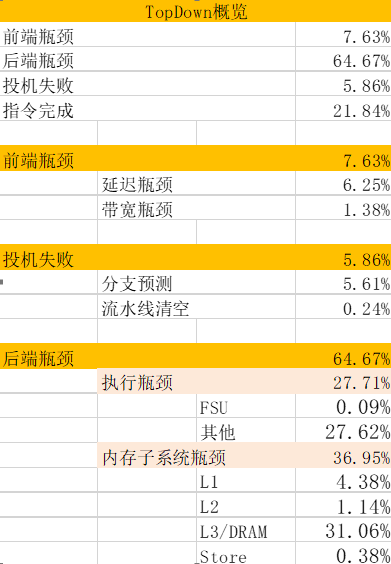
瓶颈主要在后端,可通过预取优化(预取参数,预取距离),向量化优化,循环优化(循环展开)等改善。
3.4 写放大问题分析
经分析,openEuler 20.03 LTS SP3版本存在写放大问题,通过升级OS内核到SP4进行优化(建议生产中直接使用更高版本的openEuler系统,如openEuler 22.03 LTS SP4等)。
当page_size>blk_size的时候可能会有写放大问题。dd测试写放大:
1. 在需要测试的磁盘上新建一个空白文件(本文是在“/data1”下新建test文件)。
2. 使用dd命令写数据。
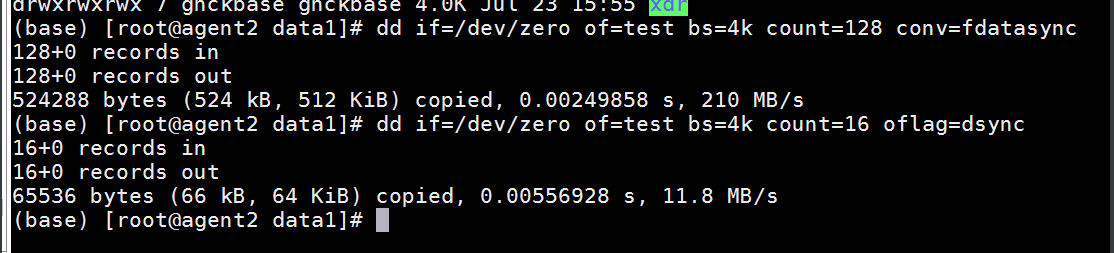
3. 在另一个窗口运行blktrace -d /dev/sdc。
4. 在之前的窗口运行dd命令。
5. dd命令运行完后Ctrl+c退出。
6. 使用blkparse -i sda> log。
blktrace -d /dev/sda blkparse -I sda > log
7. 查看结果,是否有写放大。
cat log | grep dd | grep Q | grep -v M
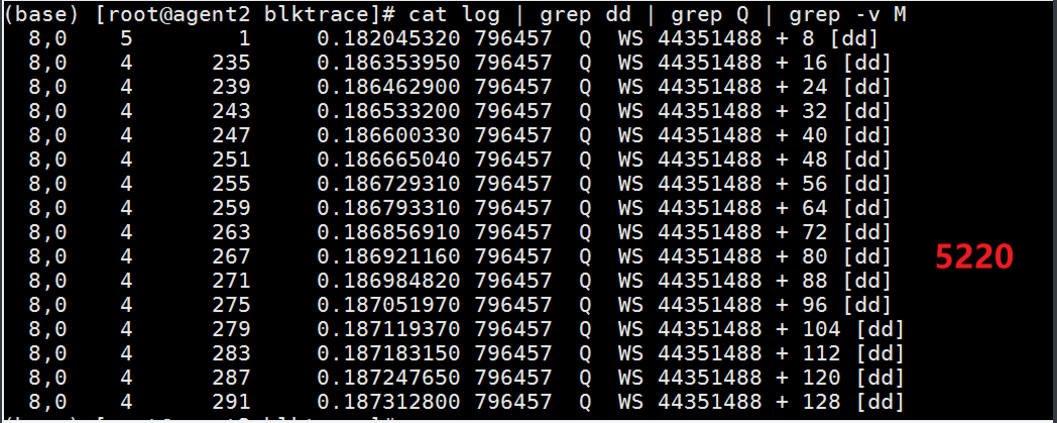
结果显示鲲鹏920 5220处理器确实存在写放大问题。
3.5 磁盘限速分析
限速测试思路
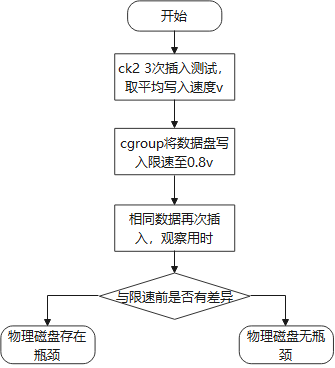
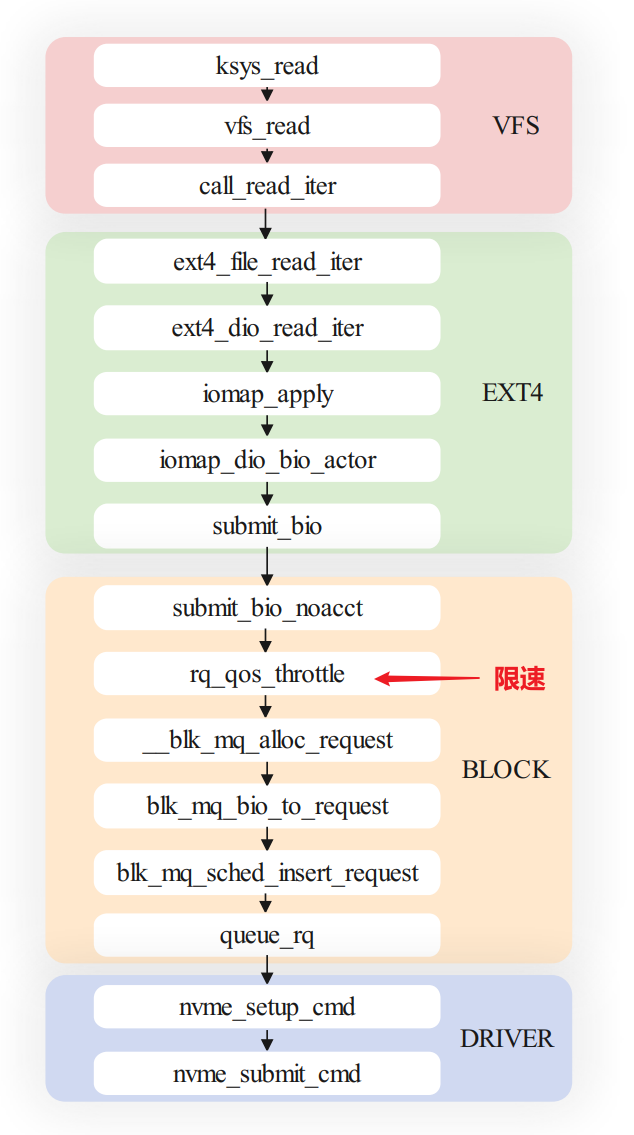
利用cgroup对磁盘进行限速,限速发生在rq_qos_throttle函数,如果限速前后插入耗时有较大变化,则物理磁盘存在速度瓶颈,否则物理磁盘无瓶颈,需要考虑其他因素的限制。
经测试,限速前后插入耗时无大幅变化,则插入过程中物理磁盘无瓶颈。
cgroup的版本有v1和v2的区别,本文使用v1。
-
pwd到当前目录下。

-
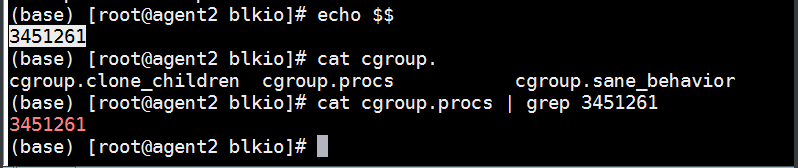
查看当前shell进程是否在cgroup限速文件中。
-
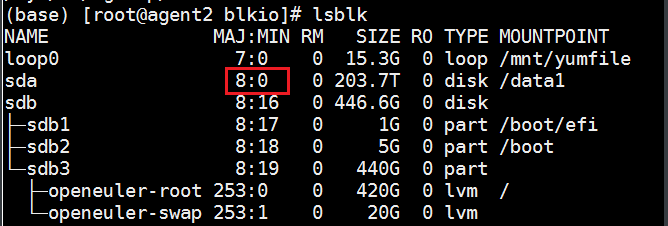
查看要限速的磁盘的识别号。
-
写入限速。
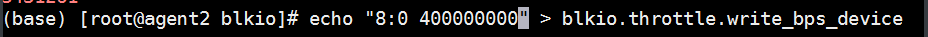
-
在当前端口下运行业务,观察IO情况。
-
解除限速。
echo “0” > blkio.throttle.write_bps_device
3.6 SQL分析
鲲鹏在SQL1查询性能领先友商,在SQL2,3查询性能落后友商,在SQL4,5查询性能接近友商。
经分析,在有子查询、有聚合操作、有dictGetString操作的情况下,鲲鹏的查询性能落后友商,在这类场景中,ck版本对友商的底层有更好的适配,在执行SQL时能够利用到更多的CPU,查询性能更好。
4 性能调优实践
升级64k内存页
鲲鹏920 5250处理器的操作系统为默认为openEuler 22.03 LTS,默认为4k内存页,升级64k内存页可以通过减少TLB开销,减少内存碎片,减少I/O次数等从而提升性能。
关闭SMMU
关闭SMMU可减少内存访问延迟,降低开销,简化内存管理。
开启64ms内存刷新频率
适当调低内存刷新频率可以提高内存工作效率。
开启CPU性能模式
适用于CPU性能算力相关应用场景。
关闭透明大页
通过查看Linux官方指导文档,建议使用低版本内核时关闭透明大页。
如果您使用旧版的Linux内核,请禁用透明大页面。它会干扰内存分配器,从而导致性能显著下降。在新版Linux内核上,开启透明大页面是可以的。
echo 'madvise' | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
如果需要永久修改透明大页设置,请编辑“/etc/default/grub”文件,并将“transparent_hugepage=madvise”添加到“GRUB_CMDLINE_LINUX_DEFAULT”选项中:
GRUB_CMDLINE_LINUX_DEFAULT="transparent_hugepage=madvise ..."
绑核(numafast绑核&手动绑核)
此场景CPU利用率超过50%,绑核预计无明显收益,经过手动绑核和numafast绑核验证无明显受益。
开启CPU预取
根据热点函数分析和后端瓶颈分析,开启CPU预取可进行优化。
升级内核版本解决写放大问题
鲲鹏920 5220集群(ck1,ck2)操作系统为openEuler 20.03 LTS,经验证有写放大问题,升级至openEuler 20.03 LTS SP4后经验证无写放大问题。
5 性能调优效果
调优后查询性能对比如下:
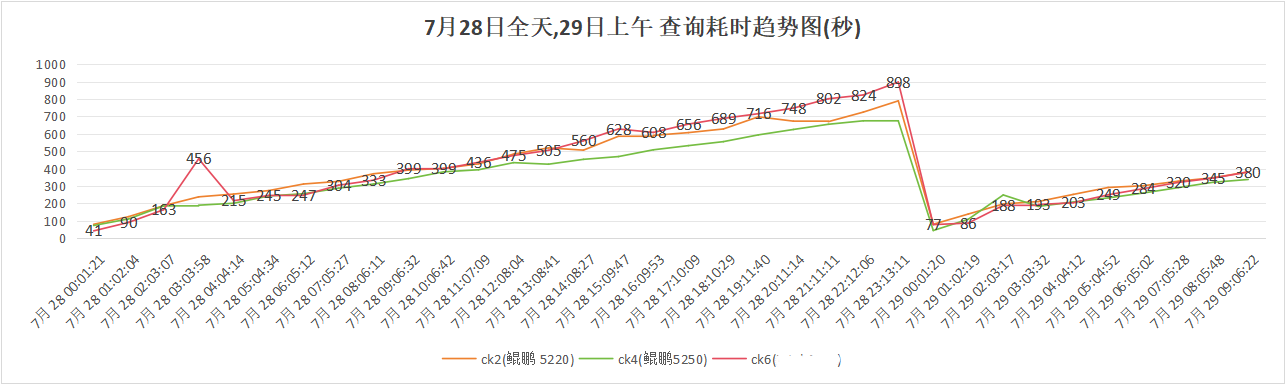
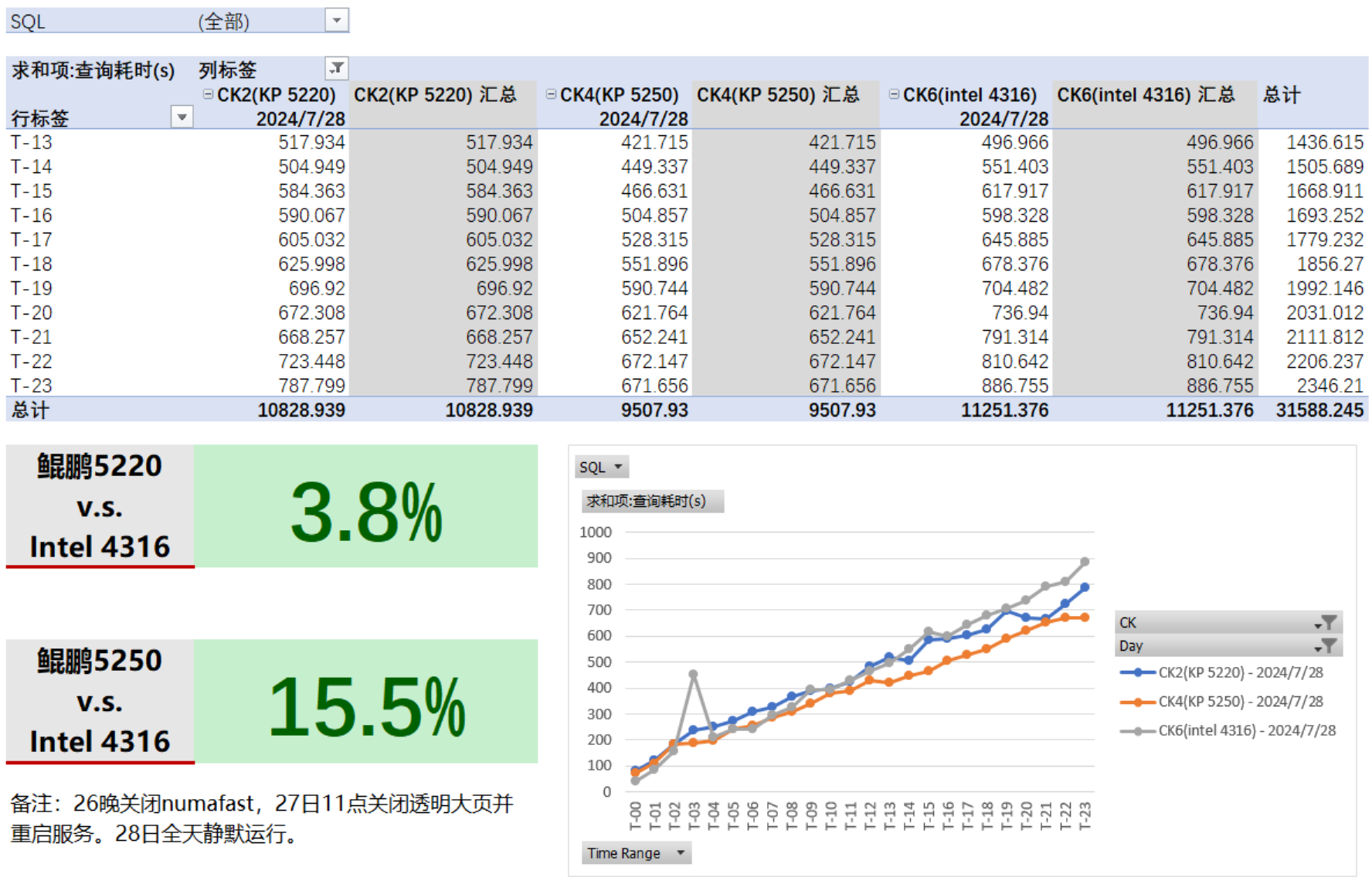
入库速率对比如下:
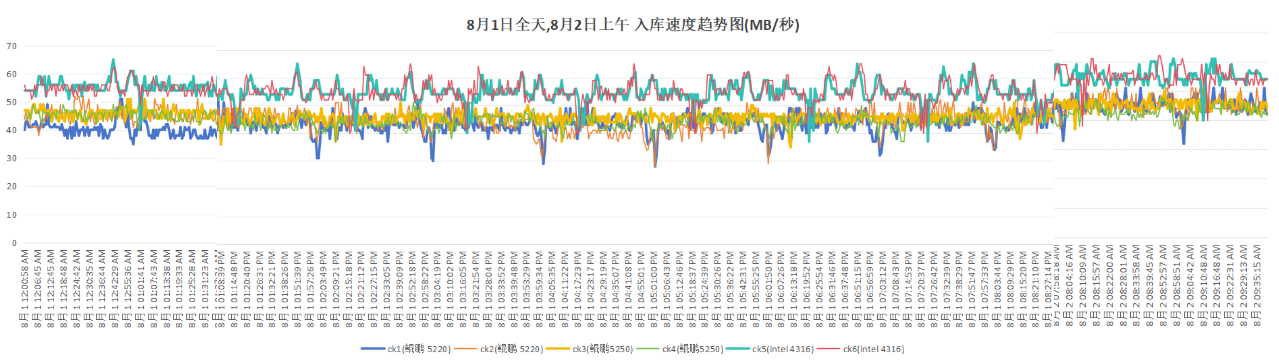
经调优,鲲鹏920 5220集群(ck1,ck2),鲲鹏920 5250集群(ck3,ck4)查询性能分别领先3.8%和15.5%,入库速率均较低。且ck3,ck4的入库速率曲线不重合,不符合理论预期,需要分析入库速率落后原因,并且需要拉齐ck3,ck4的入库速率曲线。
6 入库速率调优方案分析与测试
6.1 入库速率落后与ck3、ck4入库速率曲线不重合分析
升级操作系统前,入库速率方面的快慢情况为:ck5 ≈ ck6 > ck3 > ck4 > ck2 ≈ ck1
经检查,ck1~ck3在配置方面存在差异:
|
对比项 |
ck1 |
ck2 |
ck3 |
ck4 |
|
文件系统 |
xfs |
xfs |
xfs |
Ext4 |
|
操作系统 |
openEuler 20.03 LTS SP4 |
openEuler 20.03 LTS SP4 |
openEuler 22.03 LTS |
openEuler 22.03 LTS |
其中ck4的文件系统与ck3不同,ck1、ck2操作系统与ck3不同。经分析,xfs文件系统的理论性能优于Ext4,并且openEuler 22.03相对于20.03版本在IO的多个方面,包括xfs文件系统做了优化。
6.2 优化方案
优化方案为拉齐ck1~ck4的操作系统、文件系统与磁盘结构,优化后配置如下:
|
对比项 |
ck1 |
ck2 |
ck3 |
ck4 |
|
文件系统 |
xfs |
xfs |
xfs |
xfs |
|
操作系统 |
openEuler 22.03 LTS |
openEuler 22.03 LTS |
openEuler 22.03 LTS |
openEuler 22.03 LTS |
6.3 优化测试结果
查询性能:
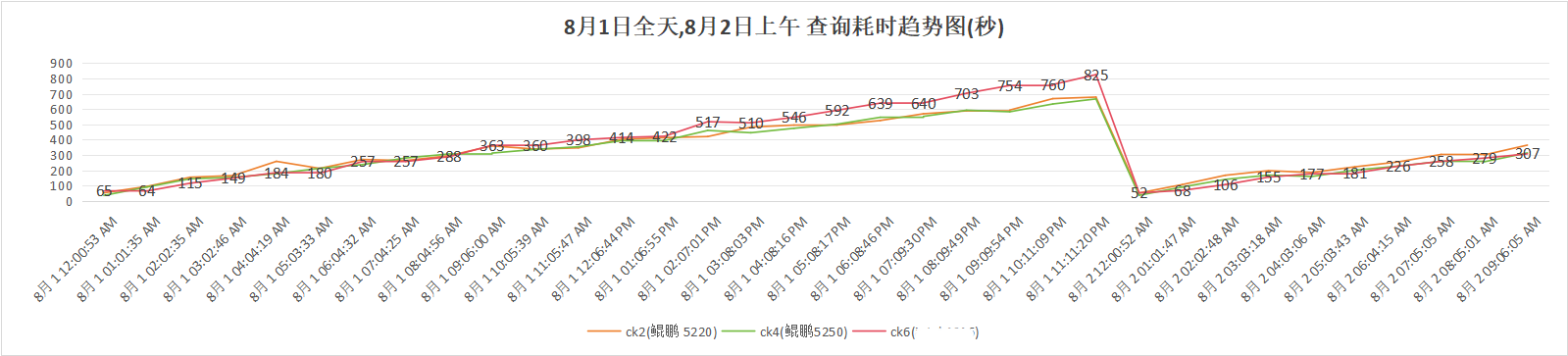
查询性能保持稳定,鲲鹏5220和5250集群均优于友商集群。
入库速率:

入库速率方面ck1~ck4入库速率曲线已拉齐,入库速率仍落后于友商集群。
以ck1为例,OS升级前后的入库平均速率如下(2024.8.1):
|
OS升级前(2024.7.28) |
OS升级后(2024.8.1) |
提升 |
|
37.40 MB/s |
44.82 MB/s |
19.84% |
升级OS对提升入库速率有一定效果。调优后鲲鹏集群ck1与友商集群ck6入库速率对比:
|
ck1 |
ck6 |
落后 |
|
44.82 MB/s |
58.76 MB/s |
23.72% |
6.4 版本升级测试
现网版本为ClickHouse 22.8.13.20,8月6日上午十点半升级至23.3.4.17,观察升级后的查询性能与入库速率。
查询性能(总耗时):
|
对比项 |
ck2 |
ck4 |
ck6 |
|
升级前(2024.8.5) |
9406s |
8691s |
9975s |
|
升级后(2024.8.7) |
9041s |
7928s |
8455s |
|
升级前后提升 |
4.03% |
9.62% |
17.99% |
版本升级后对查询性能有不同程度提升,对友商集群的提升最大。
经验证,升级对入库速率没有提升作用。
入库速率(ck1全天平均入库速率):
|
对比项 |
ck1 |
|
升级前(2024.8.5) |
48.88MB/s |
|
升级后(2024.8.7) |
42.03MB/s |
|
升级前后提升 |
-14% |
7 测试结论与建议
7.1 测试结论
经OS调优以及升级操作系统等措施,鲲鹏5220 ClickHouse集群的查询性能领先友商3.8%,作为对比,鲲鹏5250 ClickHouse集群的性能优于鲲鹏5220集群,符合理论预期。全部调优措施如下表:
|
集群类型 |
鲲鹏5220集群(ck1,ck2) |
鲲鹏5250集群(ck3,ck4) |
|
BIOS调优 |
|
|
|
OS调优 |
|
|
经调整,入库速率鲲鹏集群最终达到一致,速率方面落后于友商。经分析,用户入库的方式为读取csv文件并进行插入操作,在此场景下为单线程顺序读取并插入数据,友商具备超线程能力,单线程读取性能优于鲲鹏,而在此场景下鲲鹏的多核能力没有得到充分发挥。
经调研,ClickHouse没有参数能够将此场景下的文件读取方式调整为多核并发读取。参数input_format_parallel_parsing能够启动数据格式的保序并行分析,经测试进能够将读取的线程数提高至2,没有实质作用。此参数建议开启(默认开启)。
7.2 相关建议
-
调整数据库参数max_execution_time
ClickHouse在预计查询耗时超过此值会引发DB Exception,在超大量数据查询时建议适当调大此值。
-
启用数据库参数max_insert_threads
测试过程中发现max_insert_threads被设置为默认值0,当max_insert_threads=0时,在ClickHouse内部进行insert操作时仅用单核cpu进行插入,在插入场景中对cpu未充分利用,开启此设置可以明显减少ClickHouse内部插入的耗时。建议适当增大此值。
-
采用高版本操作系统
openEuler高版本操作系统对文件系统等均有一系列优化,建议实际使用中采用较高版本的openEuler操作系统。但需注意高版本操作(如测试中用的openEuler 22.03 LTS)系统内存页的大小默认为4k,在ClickHouse应用场景中建议将内存页升级为64k。
-
采用SSD盘,提高IO性能
-
分割数据文件提高入库速率
如上分析,ClickHouse读取文件为顺序读取,开启input_format_parallel_parsing可提高读取并行度,提高读取速率,除此之外,若原始数据文件较大,可采取将大文件分割为多个小文件,启动多个client实例并行插入的方法提高入库速率。
8 调优总结
检查用户应用配置,测试用的查询SQL是否合理等
在运行SQL时会有超时exception。
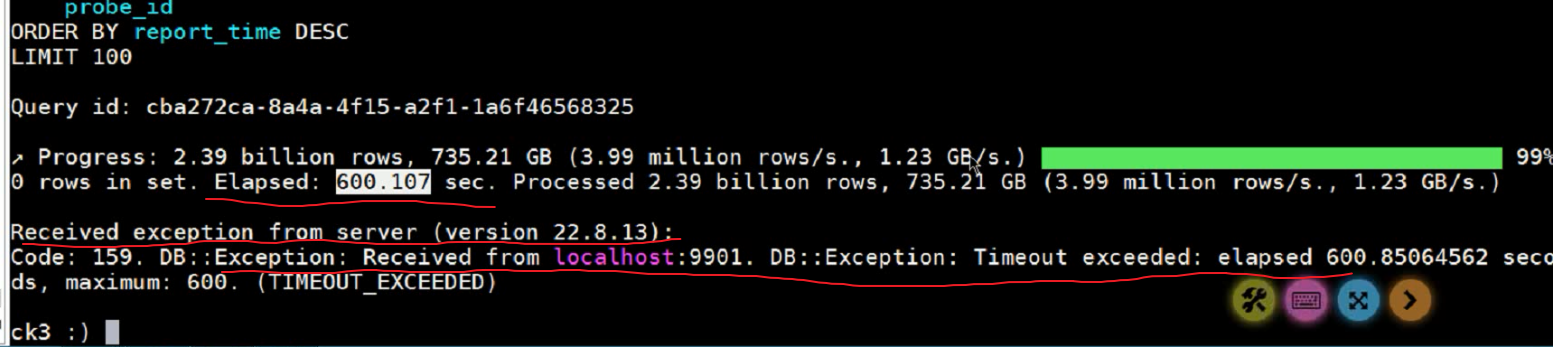
当ck预计SQL执行时间超过Max_excecution_time,即引发此exception,并停止查询。客户原始Max_excecution_time为600,会有超时发生,经讨论修改为0(永不超时)。
由于发包程序一开始有问题,也在不断迭代完善,一开始友商和鲲鹏集群的数据量不一致,而且差距较大(几百G)而客户SQL会查询过往的所有数据,经沟通,客户将查询SQL修改为查询当天和过往一小时。
分析用户SQL
在OS调优效果有限的情况下,重点分析鲲鹏慢于友商的SQL,看能否有突破。经过分析,SQL2中用户子查询可以去掉,直接在select中用函数达到相同逻辑效果,SQL3中字典获取字符串获取了两次,有一次结果始终为空,这些SQL都可以进行优化,对友商和鲲鹏都有收益,用户接收并修改。
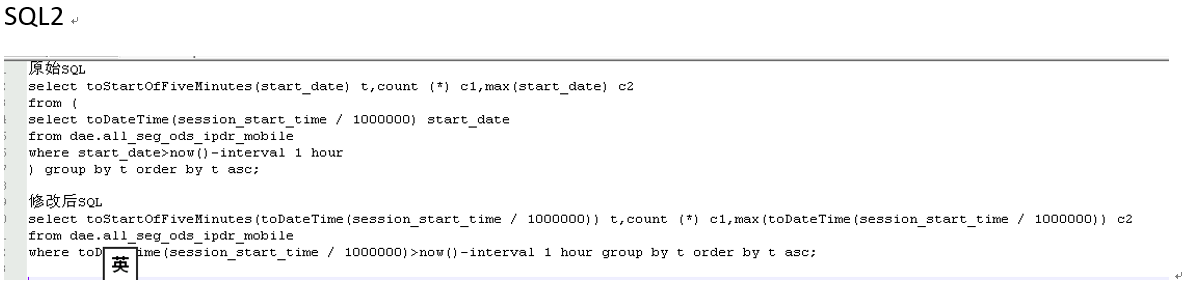

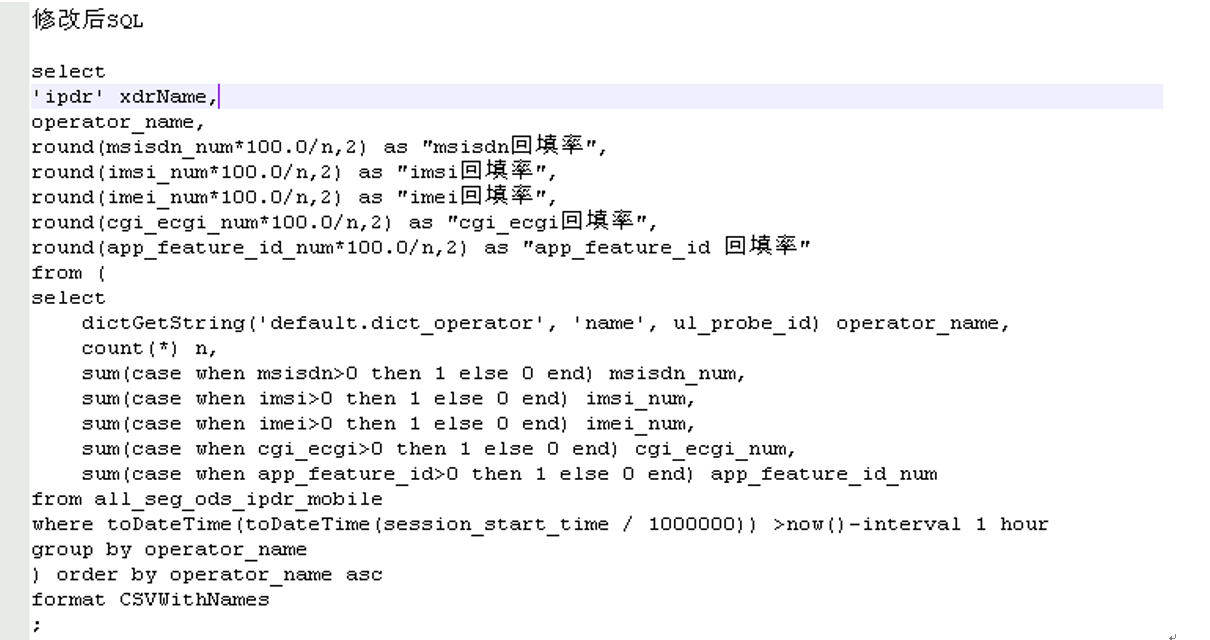
调优措施不要一起全上,因为有些可能造成负优化。
9 故障排除
9.1 升级64k内存页后重启失败,进入保护模式
问题现象描述
下载内核代码,修改pagesize配置,编译安装,重启后,报如下错误:
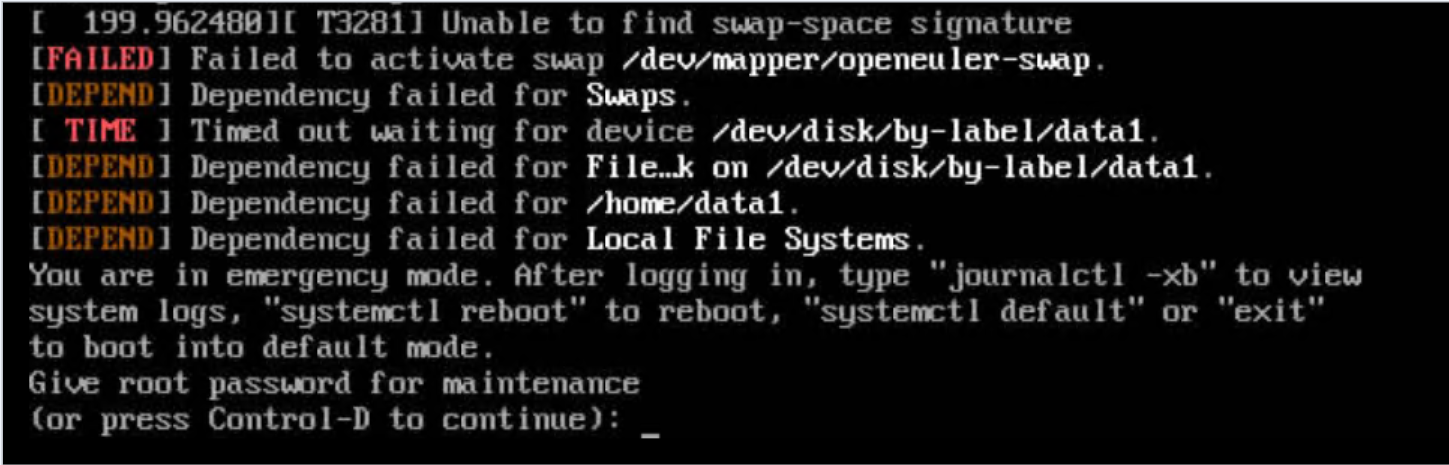
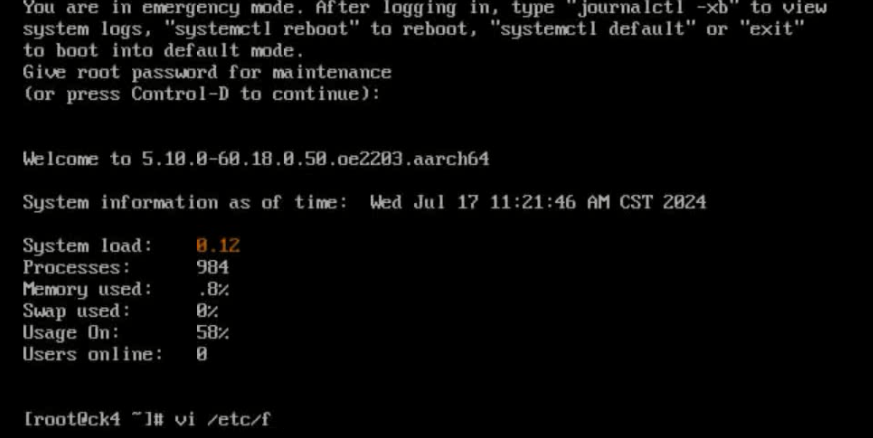
关键过程、根本原因分析
当时看见报错信息中的“Failed to activate swap /dev/mapper/openeuler-swap”,将swap逻辑卷删了,结果造成了更严重的文件系统损伤,原先的文件系统、挂载点等基本都丢失了,许多系统命令也处于不可用状态。
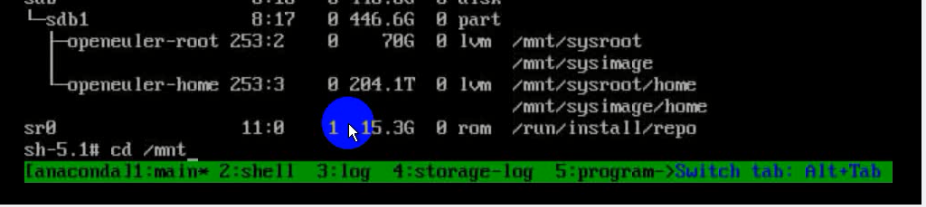
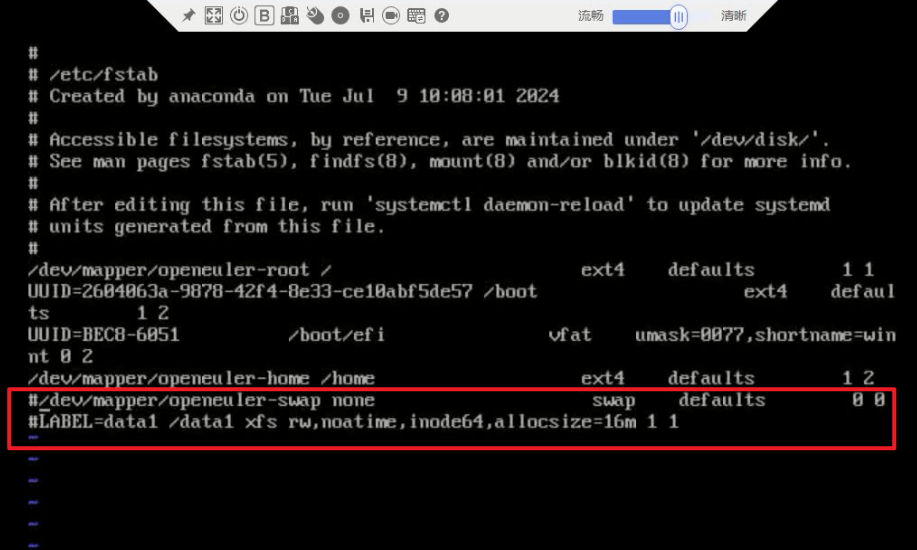
结论、解决方案及效果
遇到这种问题,查看报错定位为系统挂载有问题,应检查“/etc/fstab”文件,注释掉错误的挂载项。
9.2 慎用fio进行磁盘性能测试,很有可能造成磁盘损坏
如果要用fio进行测试,尽量避免裸盘测试。如果需要测试,尽量用文件进行读写测试,或者用dd、hdparm等其他工具进行测试。
fio --filename=/dev/sda --size=100G --rw=randwrite --bs=1m --ioengine=libaio --direct=1 --numjobs=1 --iodepth=128 --name=test --group_reporting --runtime=300 --time_based
9.3 fio弄坏磁盘后的修复踩坑
fio将磁盘弄崩之后,采用xfs_repair /dev/sda进行磁盘修复,运行完毕后提示以下截图信息。
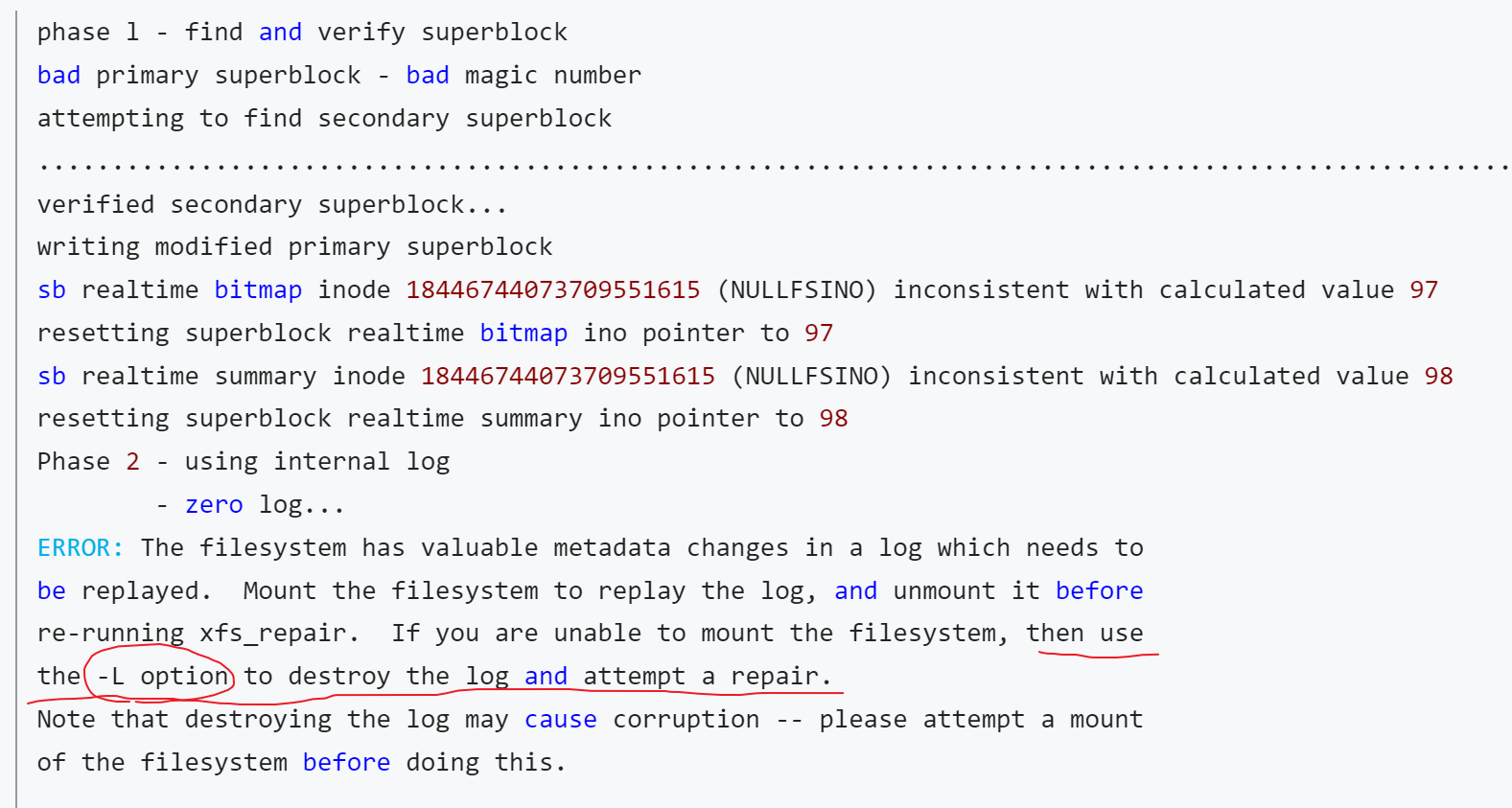
使用-L参数进行修复。修复完成后磁盘可以正常挂载和访问,但是其中的数据全部被挪动到了数字代码文件夹下。这是因为-L参数在修复的过程中会擦除磁盘上的操作log后进行强制的磁盘修复,强制使文件系统达到一致性可用状态,但是原先的目录映射信息全部丢失,不可恢复。
正确的做法是根据提示中操作“Mount the filesystem to replay the log, and unmount it before re-running xfs_repair”,先挂载,后umount,复现log,然后运行xfs_repair。
在挂载和umount过程中可能会失败,这时候可以用lsof或者fuser杀掉正在使用磁盘的进程,然后有些情况下可能需要等待一会等进程释放磁盘,然后进行修复操作,如果对磁盘数据有保留的需求,不能使用-L进行修复。
9.4 测试前全面比较基线配置
|
对比项 |
ck1 |
ck2 |
ck3 |
ck4 |
|
文件系统 |
xfs |
xfs |
xfs |
Ext4 |
|
操作系统 |
openEuler 20.03 LTS SP4 |
openEuler 20.03 LTS SP4 |
openEuler 22.03 LTS |
openEuler 22.03 LTS |
测试前配置比较的不充分,后续还要通过升级操作系统,重做文件系统等来统一。
10 相关资源
10.1 openEuler 22.03 LTS对xfs文件系统的优化
-
日志写入优化:通过减少不必要的缓存刷新和FUA操作,提高了日志写入效率。
-
异步CIL推送:允许更高效的并行处理,减少了等待时间。
-
xlog_write()重构:简化了日志写入过程,提高了效率。
-
CIL提交可扩展性:改进了提交内存日志(CIL)的处理方式,使其更能适应高并发环境。
-
缓存管理优化:更智能地管理缓存刷新,减少了不必要的I/O操作。
-
并发性提升:通过引入每CPU的CIL跟踪结构等方式,提高了并行处理能力。
总的来说,这个补丁集通过优化日志操作、提高并发性、减少不必要的I/O操作等方式,显著提升了XFS文件系统在高负载情况下的性能和可扩展性。性能提升效果:
-
事务率从700k次提交/秒提高到1.7M次提交/秒。
-
在不使用fsync的元数据密集型工作负载上,FUA/flush操作减少了2~3个数量级。
10.2 常用性能监测工具
kperf分析
kperf基础命令:
-
生成kperf结果文件,需要将文件上传至上述“kperf工具下载以及文件上传地址”进行解析后查看结果。
/root/kperf --rawdata --hotfunc --topdown --cache --tlb --imix --uncore --spe --duration 1 --interval 15 --pid 32777 > kperf.out
-
生成excel结果文件。
./kperf --rawdata --hotfunc --topdown --cache --tlb --imix --uncore --spe --duration 1 --interval 15 --pid PID --excel kperf
-
命令行topdown分析。
/root/kperf --topdown --cache --pid <pid> --duration 1 --interval 5
命令中,--interval参数表示取样间隔,--duration表示每次取样持续的时间长度,取样完成ctrl+c退出即可。
nmon分析
nmon可以对CPU,内存,网络,磁盘IO等进行全面的监控分析。详细信息请参见性能监控和分析工具---nmon。
其他命令
-
CPU:top,htop
-
IO:iotop,iostat,dstat
-
网络:sar,ethtool
-
性能数据采集命令
-
nmon采集命令
nmon -f -s 2 -c 1000 -F data.nmonF
-f:按标准格式输出文件:<hostname>_YYYYMMDD_HHMM.nmon
-s 2:每2秒进行一次数据采集
-c 1000:一共采集1000次
-
topdown采集命令
./kperf --rawdata --hotfunc --topdown --cache --tlb --imix --uncore --duration 5 --interval 1 --pid 1338279 > ck_kperf.txt
kperf工具获取地址,采集后数据上传地址。
-
热点函数采集命令
perf record -g -p 431032 -o q4.data -- sleep 10
perf script -i q4.data | /home/clickhouse/FlameGraph/stackcollapse-perf.pl | /home/clickhouse/FlameGraph/flamegraph.pl > q4_x86.svg
FlameGraph工具获取地址
-
cache miss数据采集
perf record -e cache-misses:u -p ${pid}
perf record -e LLC-load-misses -e LLC-loads -o lineorder_flat_4.1.data -p ${pid}
-
perf相关命令
perf stat -ddd ./test.sh
perf record
perf report
perf top
-
查看CPU/IO/Net相关命令
iotop
htop
dstat
iperf3
-
NVME盘参数采集
-
查看磁盘状态
smartctl -a /dev/nvme1n1
-
获取磁盘读取速率
hdparm -Tt /dev/nvme1n1
-
-
查看ClickHouse构建信息
select * from system.build_options;
-
获取ClickHouse堆栈信息
SELECT
count(),
arrayStringConcat(arrayMap(x -> concat(demangle(addressToSymbol(x)), '\n ', addressToLine(x)), trace), '\n') AS sym
FROM system.trace_log
WHERE event_date = today() AND query_id != '' AND trace_type = 'CPU' and query_id='20d5e47d-9846-4163-b217-8355b87885ad'
GROUP BY sym
ORDER BY count() DESC
LIMIT 10
SETTINGS allow_introspection_functions = 1;
-
查询ClickHouse系统表
select query, query_id,columns from system.query_log where databases=['ssb_100'] limit 3;
select name, data_paths from system.tables where database='ssb_100';
SHOW SETTINGS LIKE 'join_algorithm';
select marks, rows, bytes_on_disk, table, disk_name from system.parts where database='tpch';
clickhouse client --database ssb_100 --send_logs_level=trace < sql/q5.sql
clickhouse client --max_threads 32 --max_streams_to_max_threads_ratio 1 --allow_asynchronous_read_from_io_pool_for_merge_tree true --preferred_block_size_bytes 2000000 --join_algorithm parallel_hash
-