


使用DevKit矩阵化检查工具优化应用,端到端性能提升26%
发表于 2025/09/11
0
作者 | 熊绍奎
一、介绍
背景介绍
高性能计算应用代码中存在大量的循环,这些循环通常会包含N维数组、向量的计算,以及一些其他可向量化、可优化访存局部性的部分,通常编译器难以识别且无法对其进行自动优化,难以发挥鲲鹏920系列新型号处理器的硬件特性。部分鲲鹏920系列新型号处理器支持Matrix computation、Vector computation指令,这些指令发布时间短,用户学习成本高。
矩阵化检查工具通过对源码分析检查,识别矩阵计算、类矩阵计算、可向量化计算以及其他可以提升计算效率的计算模式,并对源代码的片段提供修改优化方案或建议,帮助用户使用Matrix computation、Vector computation指令提升应用性能,使应用亲和鲲鹏硬件。
工具介绍
矩阵化检查工具检查应用源码,对源码进行静态分析,目前只支持C/C++、Fortran应用的源码检查。工具基于源文件的抽象语法树进行识别,在进行C/C++相关的高性能计算应用的识别时,应用需要在鲲鹏平台编译通过。由于依赖工具的限制,目前仅支持f2003、f2008标准的Fortran文件识别。
矩阵化检查工具的安装及使用指导请参见《鲲鹏DevKit 用户指南(IDE插件)》。
二、应用案例
以应用“妈祖·海浪”为例说明工具的使用,妈祖·海浪”是一个高性能计算应用,详细介绍请参见“妈祖·海浪”。
1、安装
服务器配置信息
-
CPU:鲲鹏920系列处理器
-
操作系统:openEuler 22.03 LTS SP4 AArch64
环境搭建及安装
1、安装HPCKit组件。
最新版本HPCKit组件,详细安装过程参考官网:《HPCKit 安装指南》
其中关键安装命令:
sh HPCKit_xx.xx.xx_Linux-aarch64/install.sh -y --prefix=/path/to/INSTALL_HPCKit --hmpi_type=mlnx|rdma
xx.xx.xx表示版本号,请以实际软件包的版本为准。
2、安装依赖ZLIB库。
下载路径:ZLIB库下载地址
详细安装过程参考:《CESM 2.1.1 移植指南(openEuler 21.03)》中的“配置编译环境>安装ZLIB”。
3、安装依赖HDF5库。
下载路径:HDF5库下载地址
详细安装过程参考:《CESM 2.1.1 移植指南(openEuler 21.03)》
4、安装依赖NetCDF-C、NetCDF-Fortran库。
-
NetCDF-C下载路径:NetCDF-C库下载地址
详细安装过程参考:《CESM 2.1.1 移植指南(openEuler 21.03)》中的“配置编译环境>安装NETCDF-C”。
-
NetCDF-Fortran下载路径:NetCDF-Fortran库下载地址
详细安装过程参考:《CESM 2.1.1 移植指南(openEuler 21.03)》中的“配置编译环境>安装NETCDF-Fortran”。
5、安装FVWAM。
-
设置HPCKit组件环境变量。
source /path/to/INSTALL_HPCKit/HPCKit/latest/setvars.sh --use-bisheng
export CC=/path/to/INSTALL_HPCKit/HPCKit/xx.xx.xx/compiler/bisheng/bin/clang
export CXX=/path/to/INSTALL_HPCKit/HPCKit/xx.xx.xx/compiler/bisheng/bin/clang++
export FC=/path/to/INSTALL_HPCKit/HPCKit/xx.xx.xx/compiler/bisheng/bin/flang
export MPICC=/path/to/INSTALL_HPCKit/HPCKit/xx.xx.xx/hmpi/bisheng/hmpi/bin/mpicc
export MPICXX=/path/to/INSTALL_HPCKit/HPCKit/xx.xx.xx/hmpi/bisheng/hmpi/bin/mpicxx
export MPIFC=/path/to/INSTALL_HPCKit/HPCKit/xx.xx.xx/hmpi/bisheng/hmpi/bin/mpifort
-
由于运行平台为鲲鹏920系列处理器,需要去除编译选项中的无关项(-traceback仅支持x86机器,需要去除),并增加Matrix computation、Vector computation相关选项,编译选项修改后如下:
-DSINGLE -g -O3 -ffree-form -ffree-line-length-none -mcpu=hip11 -ffp-model=fast -fno-math-errno -fstack-arrays -fveclib=KPL_SVML_SVE -lm -lksvml
修改后执行编译命令,生成一个.exe文件。基线和优化后应用需要使用相同的编译选项编译。
6、以官网自带算例wind_temp_2024111212.nc进行测试验证。
1)链接分区文件。
ln -sf ./graph_NANHAI.info.part.128 tmppartition
使用n个核运行FVWAM模式时,需要先链接对应的后缀为n的分区文件。
2)运行。
mpirun -np 128 --report
2、运行
采集热点
修改配置文件namelist.wave,使用南海算例,并把字段run_hours的值改为2。
运行时,使用perf命令采集热点函数:
perf record -g command
从采集到的热点图中大致分析热点占比情况,其中,wave_propag_mod模块占比50%左右,wave_source_module模块占比35%左右。这两个文件占比较高,因此,需要重点关注这两个文件的优化。
矩阵化检查扫描
在采集热点的同时,可以对应用进行全量扫描,二者不冲突。扫描结果如下:
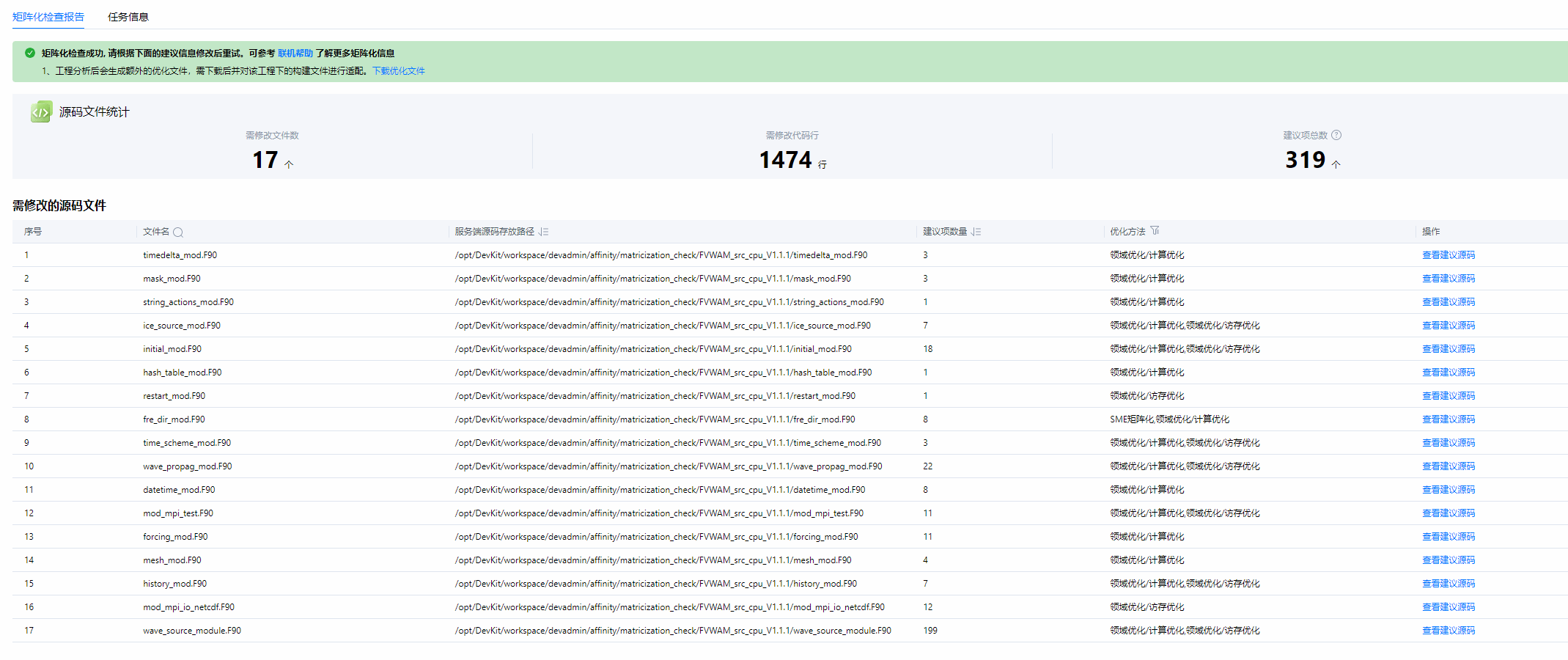
基线性能测试
基线性能采用原始应用的文件进行编译,编译选项参考“5、安装FVWAM”,进程数为607个。基线性能测试运行时间为38mins。
3、优化
优化与测试
根据热点分析结果,以及矩阵化检查扫描结果,首先对wave_propag_mod.F90文件进行优化。

从扫描结果来看,识别出的技术点类型有领域优化/计算优化、领域优化/访存优化。
查看源代码,可以看到识别出的类型有单位阶跃计算优化、制导语句优化、数学恒等变换等领域优化技术。具体优化技术的细节可以参考鲲鹏官网:《鲲鹏DevKit 用户指南(IDE插件)》中的“亲和分析工具>矩阵化检查”。
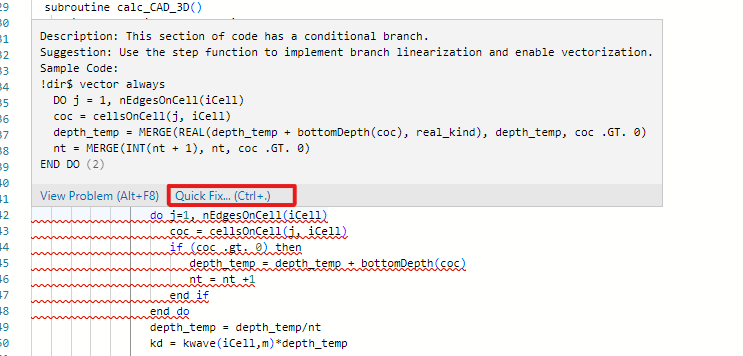
点击“Quick Fix”并选择替换成优化后代码或者一键修改该文件所有可自动优化的代码。
为了确保高热点函数所在文件优化完全,可以对该文件再次进行扫描,并确认优化。
修改完wave_propag_mod.F90文件后,保存并下载优化后的文件。将原始文件替换为优化后的文件,并进行编译测试,除优化文件外,其他需要与基线性能测试保持一致。优化后测试运行时间为29min。
然后,以同样的方式对 wave_source_module.F90文件进行优化,优化后测试运行时间为28min。
优化结果对比
FVWAM模式使用南海算例运行,测试基线时间为38min,使用DevKit矩阵化检查工具进行优化后,运行时间为28min,优化达到26.3%。
| 算例 | 基线用时 | 自动优化用时 | 性能提升 |
|---|---|---|---|
| 南海算例-40GB | 38min | 28min | 26.3% |
此数据为现网测试数据,由于现网提前做了编译器向量化,未能完全体现DevKit矩阵化检查工具优化带来的收益。若单独使用DevKit矩阵化检查工具进行优化,将带来的收益更大(自测数据为37%)。