


鲲鹏平台上的PaddlePaddle推理效率问题定位总结
发表于 2025/09/12
0
作者 | 李璐
环境信息
|
硬件配置 |
鲲鹏ARM平台 |
|
内核 |
Linux4.19.90-52.22.sm3.04.v2207.ky10.aarch64 |
|
CPU |
256 核 |
|
架构 |
aarch64 |
|
NUMA节点 |
8 |
|
主频 |
2.6GHz |
|
算法推理时间 |
单次推理10秒以上,有时超过700秒。 |
测试步骤
下载测试镜像。
在浏览器打开:http://intelliw-console.oss-cn-beijing.aliyuncs.com/AI-CONSOLE/downloads/infer-service.tgz。
设置环境。
进入镜像后设置环境变量:
export PYTHONPATH=/root
进入工作目录:
cd /root/packages/paddlener-norm-merge-onpremise-V3R6_arm_20240712_arm/
配置测试脚本。
编辑algorithm.py文件,增加以下代码:
aa = Algorithm({'framework_log': ""})
aa.load('')
data = {"data": {"text": "我预计7月 16 日从北京出发,乘坐火车去南昌参加调研,7月20 日返回。”}}
result = aa.bertcrf_ner_service(data)
print(result)
执行测试。
python algorithm.py
测试期望
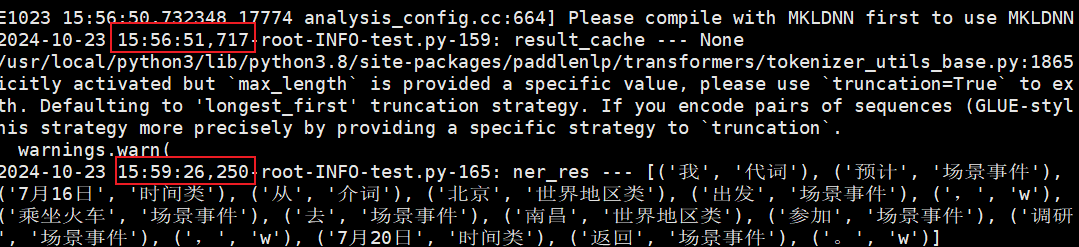
模型的推理时间进入毫秒级。
执行结果:
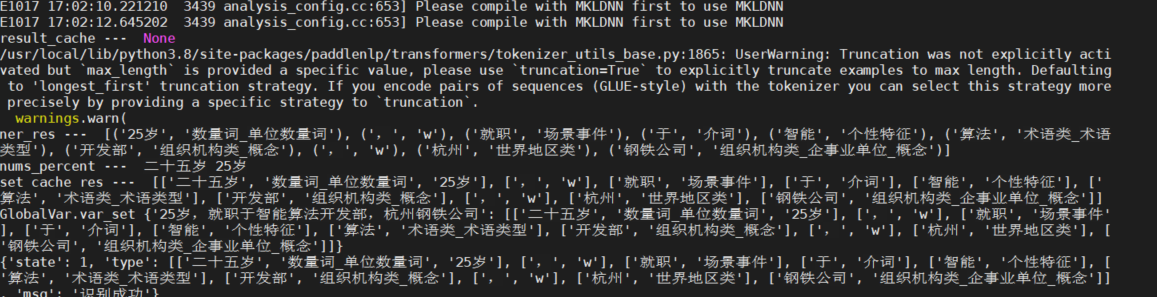
性能分析
对IO、网络和内存分析
推理部分没有使用IO,网络和内存也变化不大。
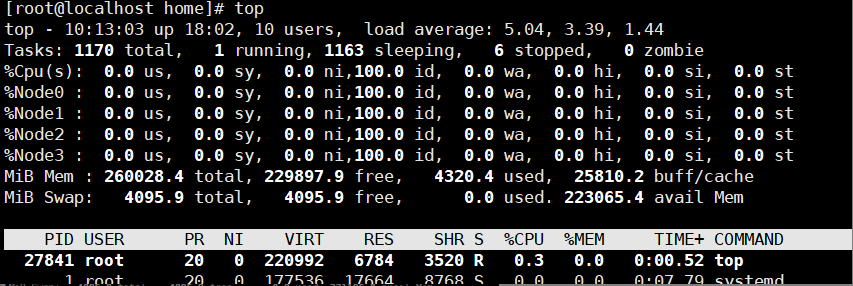
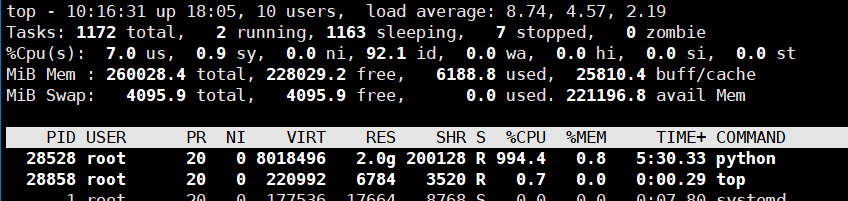
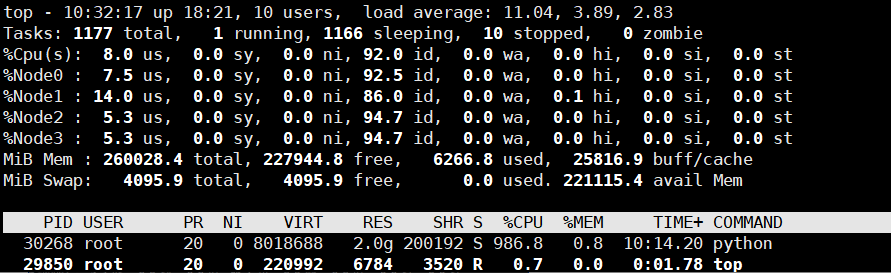
使用鲲鹏服务器麒麟物理机分配10核试验,模型运行前的资源使用情况如下:
模型运行时的资源使用情况:
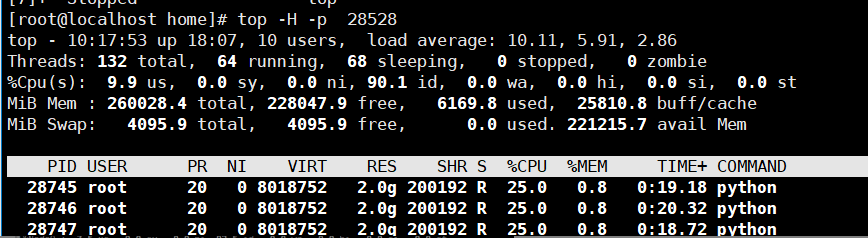
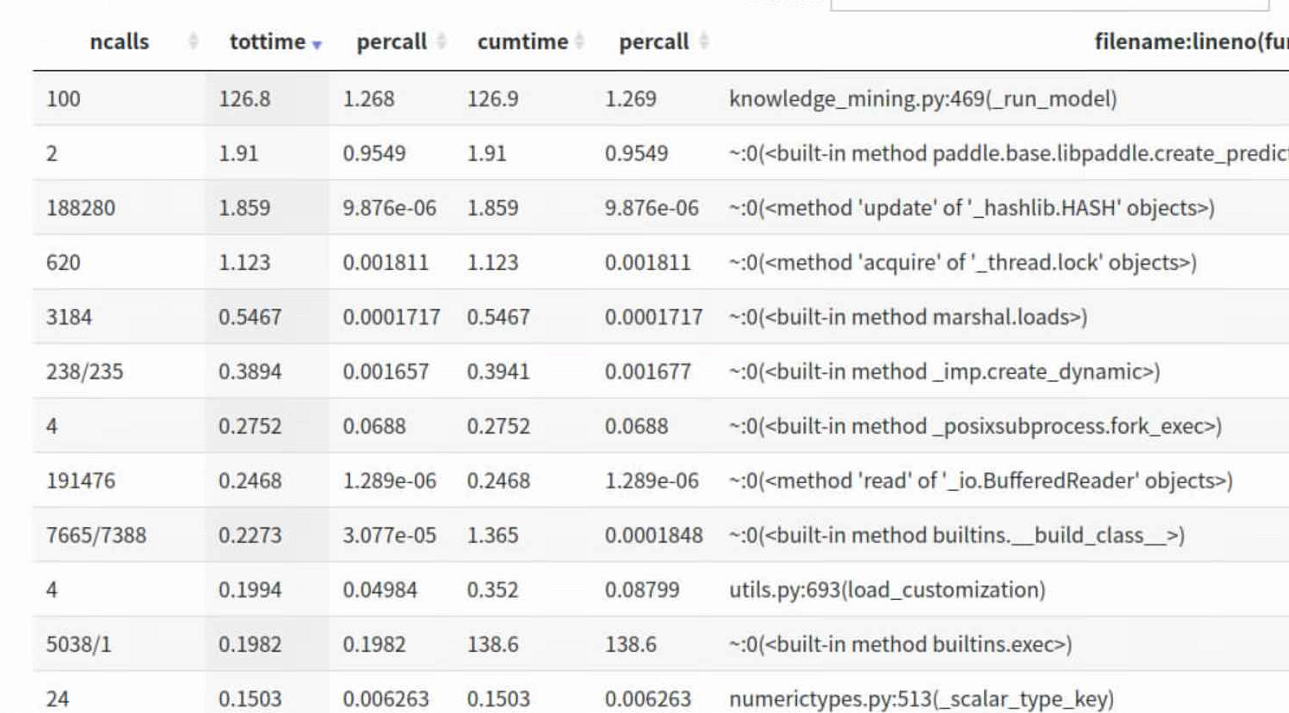
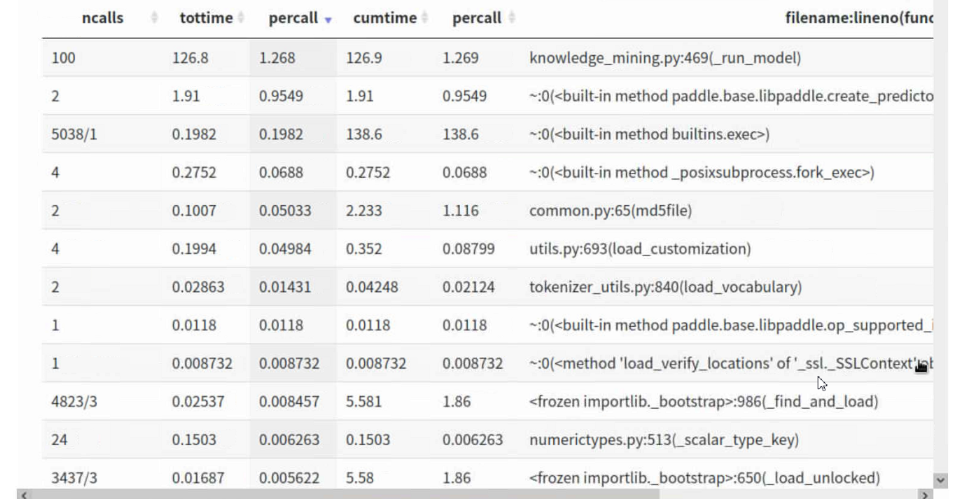
使用python标准库内建的分析工具cProfile进行性能分析,并使用第三方工具snakeviz进行可视化。在冰柱图中,可以看到最上面的根函数是algorithm_new.py,往下依次调用了taskflow.py函数、task.py函数等,并且占用时间也最长。

从统计表中可看出,ncalls表示函数调用次数,调用次数较多的均是paddle内部函数,说明性能瓶颈主要在调用开源的paddle代码内部。
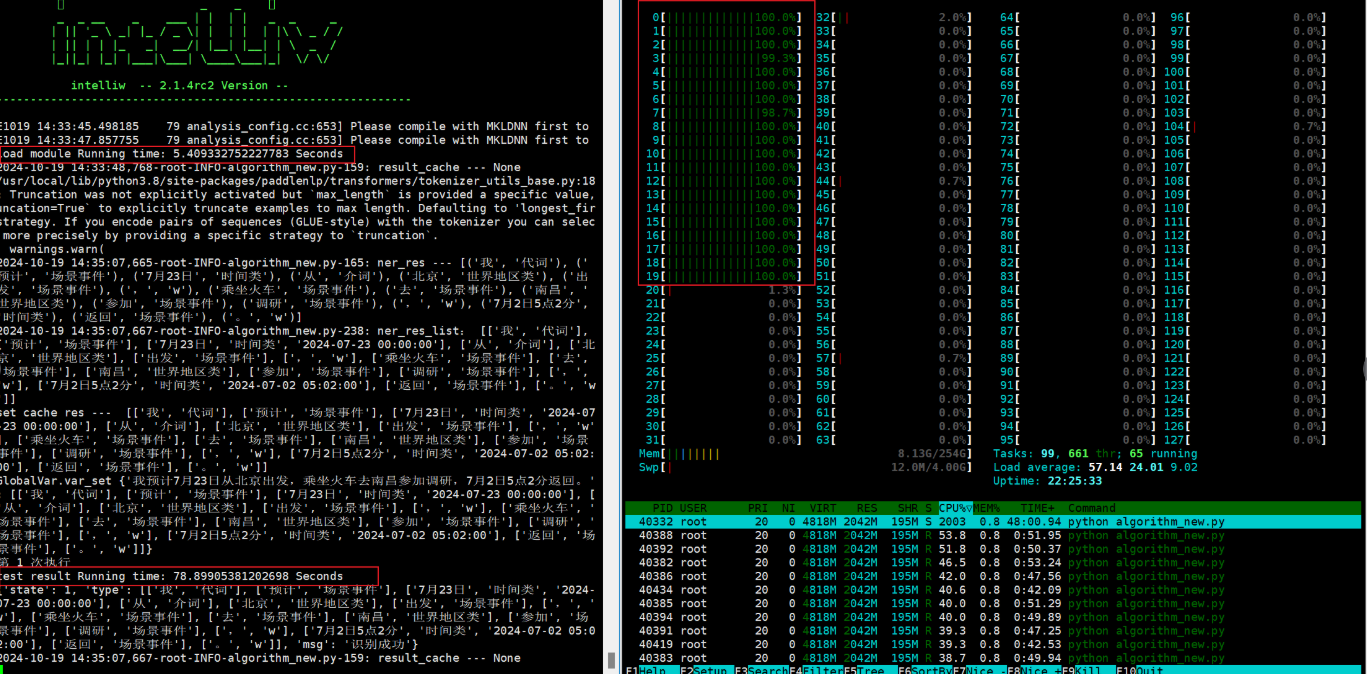
分配不同内存
相同CPU核(0-19)分配下,分别测试内存为5G,20G和50G的情况,性能无明显提升。
-
分配5G内存。
docker run -it --cpuset-cpus 0-19 --memory 5G reg.yyuap.local:81/yonbip/infer-service2112685969237868553-ktpaz59z:20241017154720 bash
-
分配20G内存。
docker run -it --cpuset-cpus 0-19 --memory 20G reg.yyuap.local:81/yonbip/infer-service2112685969237868553-ktpaz59z:20241017154720 bash
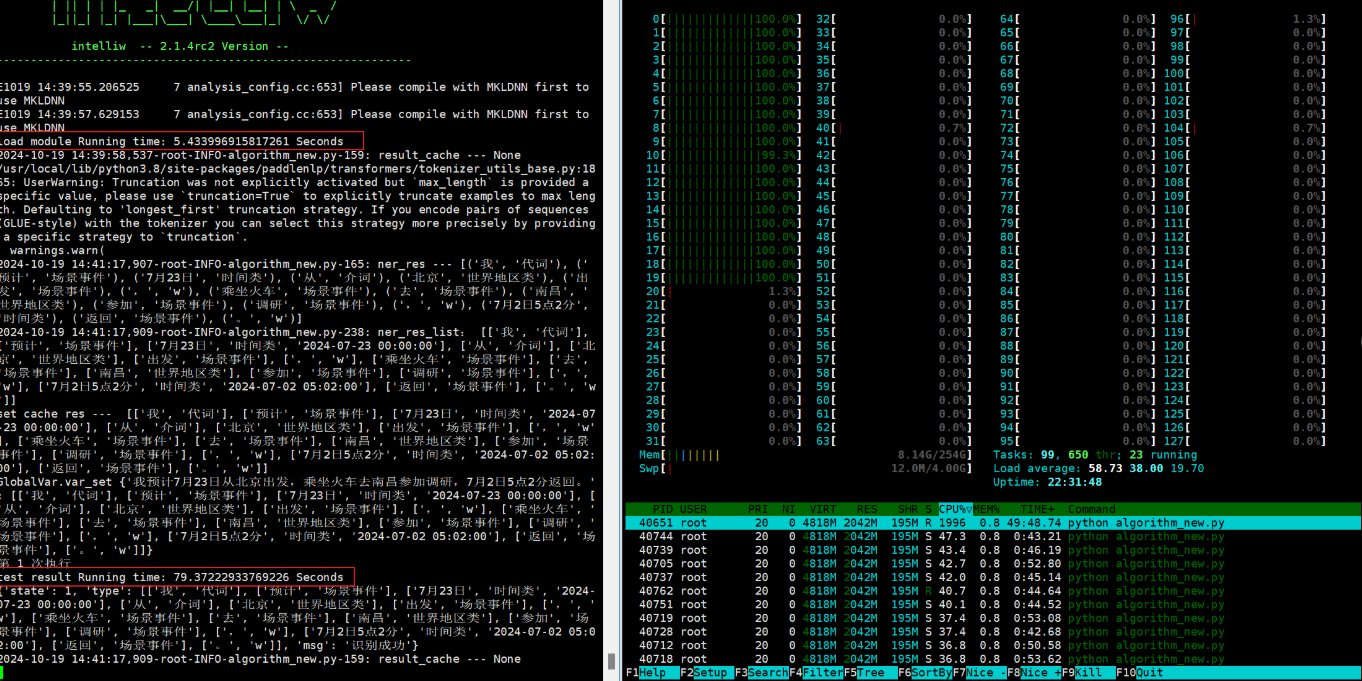
-
分配50G内存。
docker run -it --cpuset-cpus 0-19 --memory 50G reg.yyuap.local:81/yonbip/infer-service2112685969237868553-ktpaz59z:20241017154720 bash
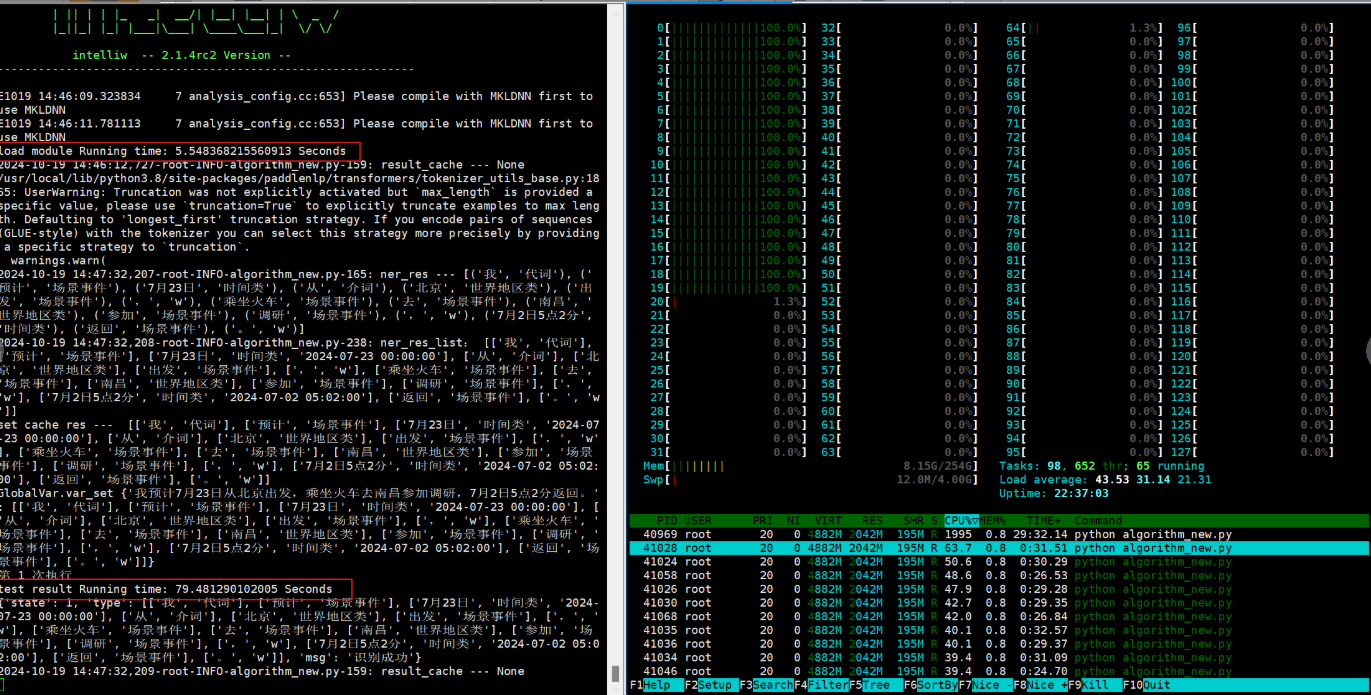
虚拟机上测试镜像
48核虚拟机性能无明显提升。
-
48核的虚拟机
执行时绑定CPU核(0-19):性能20s左右
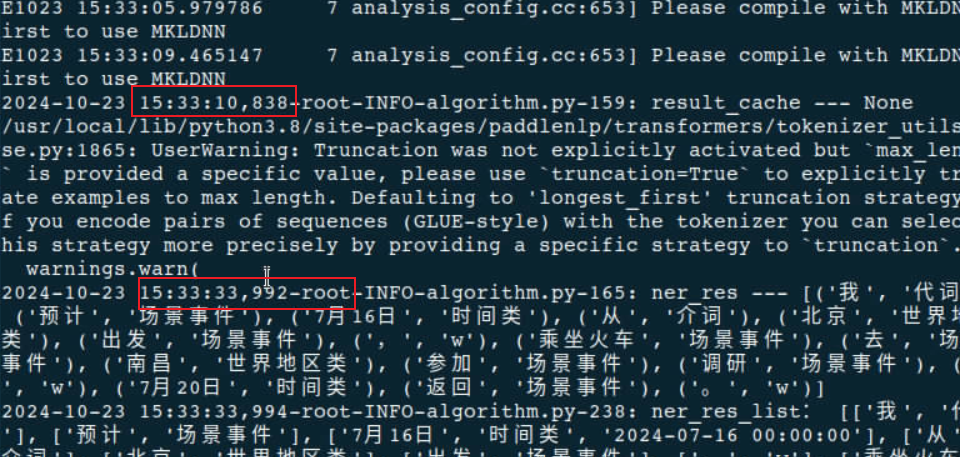
-
24核的虚拟机
执行时绑定CPU核(cpu 0-11)的情况和执行时不绑定CPU核(cpu 12)的情况:

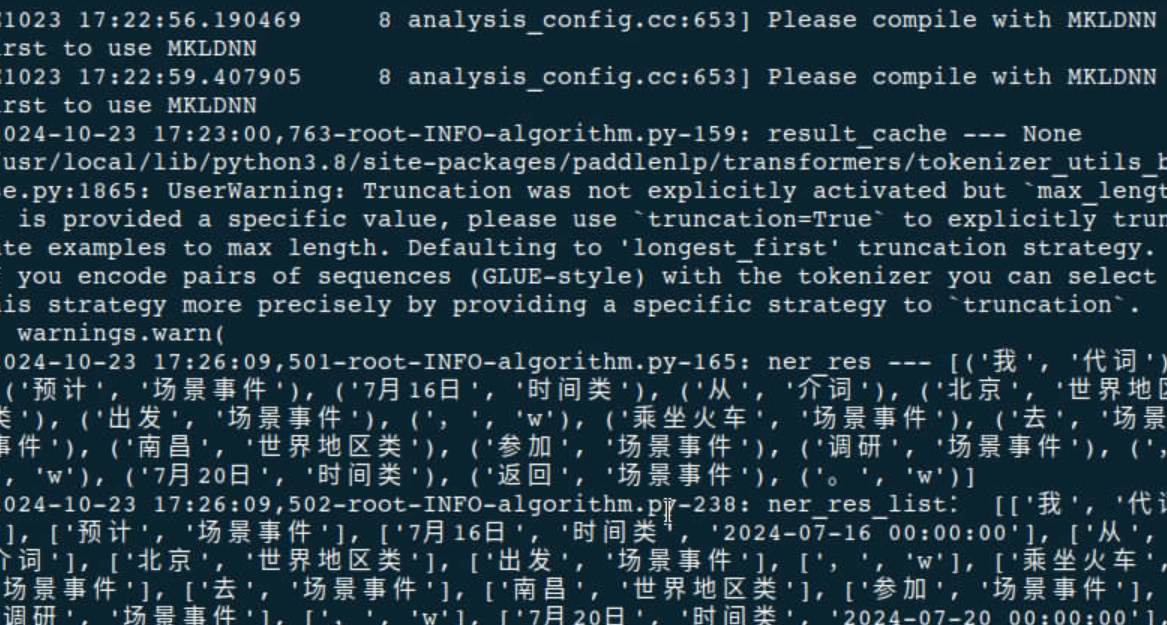
-
8核的虚拟机
执行时绑定CPU核(cpu 0-3)的情况和执行时不绑定CPU核(cpu 4)的情况:
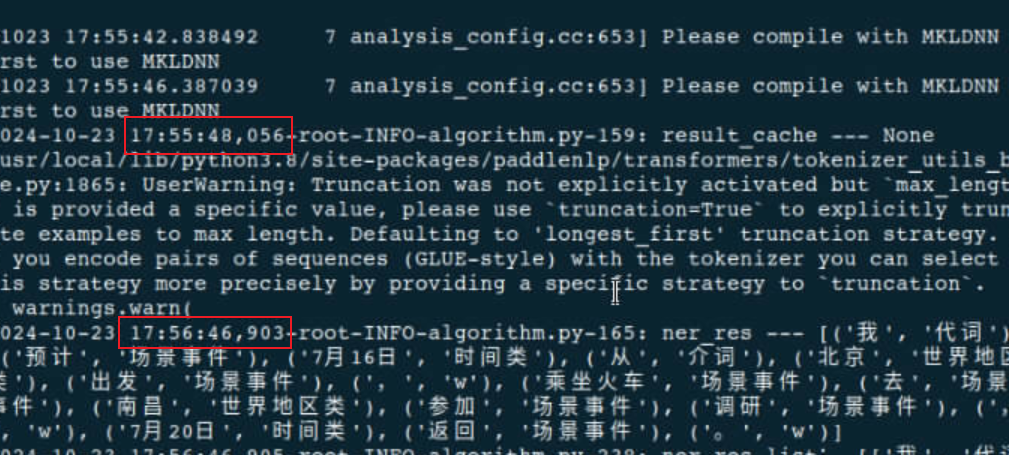
48核虚拟机性能无明显提升。
-
48核的虚拟机
执行时绑定CPU核(0-19):性能20s左右
-
24核的虚拟机
执行时绑定CPU核(cpu 0-11)的情况和执行时不绑定CPU核(cpu 12)的情况:
-
8核的虚拟机
执行时绑定CPU核(cpu 0-3)的情况和执行时不绑定CPU核(cpu 4)的情况:
欧拉物理机上测试镜像
与鲲鹏服务器麒麟物理机结果相比性能无明显提升。
-
查看欧拉系统信息。
uname -a &lscpu
回显如下:
Linux localhost.localdomain 5.10.0 #2 SMP Mon Oct 14 00:48:26 CST 2024 aarch64 aarch64 aarch64 GNU/Linux
架构: aarch64
CPU 运行模式: 64-bit
字节序: Little Endian
CPU: 128
在线 CPU 列表: 0-127
厂商 ID: HiSilicon
BIOS Vendor ID: HiSilicon
型号名称: Kunpeng-920
BIOS Model name: Kunpeng 920-6426
型号: 0
每个核的线程数: 1
每个座的核数: 64
座: 2
步进: 0x1
BogoMIPS: 200.00
标记: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fc
ma dcpop asimddp asimdfhm
Caches (sum of all):
L1d: 8 MiB (128 instances)
L1i: 8 MiB (128 instances)
L2: 64 MiB (128 instances)
L3: 128 MiB (4 instances)
NUMA:
NUMA 节点: 4
NUMA 节点0 CPU: 0-31
NUMA 节点1 CPU: 32-63
NUMA 节点2 CPU: 64-95
NUMA 节点3 CPU: 96-127
Vulnerabilities:
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Retbleed: Not affected
Spec store bypass: Not affected
Spectre v1: Mitigation; __user pointer sanitization
Spectre v2: Not affected
Srbds: Not affected
Tsx async abort: Not affected
-
Docker中运行模型。
docker run -it --cpuset-cpus 0-19 --memory 20G reg.yyuap.local:81/yonbip/infer-service2112685969237868553-ktpaz59z:20241017154720 bash
推理时间为60s左右。
与鲲鹏服务器麒麟物理机结果相比性能无明显提升。
-
查看欧拉系统信息。
uname -a &lscpu
回显如下:
Linux localhost.localdomain 5.10.0 #2 SMP Mon Oct 14 00:48:26 CST 2024 aarch64 aarch64 aarch64 GNU/Linux
架构: aarch64
CPU 运行模式: 64-bit
字节序: Little Endian
CPU: 128
在线 CPU 列表: 0-127
厂商 ID: HiSilicon
BIOS Vendor ID: HiSilicon
型号名称: Kunpeng-920
BIOS Model name: Kunpeng 920-6426
型号: 0
每个核的线程数: 1
每个座的核数: 64
座: 2
步进: 0x1
BogoMIPS: 200.00
标记: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fc
ma dcpop asimddp asimdfhm
Caches (sum of all):
L1d: 8 MiB (128 instances)
L1i: 8 MiB (128 instances)
L2: 64 MiB (128 instances)
L3: 128 MiB (4 instances)
NUMA:
NUMA 节点: 4
NUMA 节点0 CPU: 0-31
NUMA 节点1 CPU: 32-63
NUMA 节点2 CPU: 64-95
NUMA 节点3 CPU: 96-127
Vulnerabilities:
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Retbleed: Not affected
Spec store bypass: Not affected
Spectre v1: Mitigation; __user pointer sanitization
Spectre v2: Not affected
Srbds: Not affected
Tsx async abort: Not affected
-
Docker中运行模型。
docker run -it --cpuset-cpus 0-19 --memory 20G reg.yyuap.local:81/yonbip/infer-service2112685969237868553-ktpaz59z:20241017154720 bash
推理时间为60s左右。
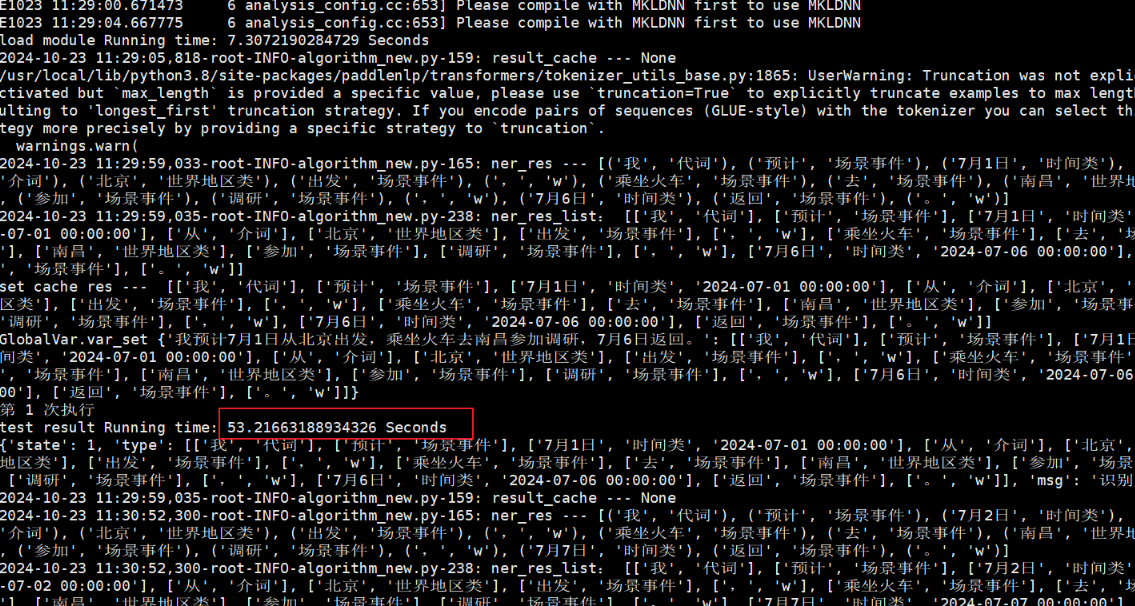
麒麟物理机直接运行模型
在限制CPU前提下无明显提升;在鲲鹏服务器上安装Python 3.8.12,paddlenlp 2.6.1 post版本执行相同模型,命令为:taskset -c 0-3 python3 test.py
-
不限制CPU时,推理时间在2s以内。
-
限制0-3的CPU核,推理时间达到150s左右。
在限制CPU前提下无明显提升;在鲲鹏服务器上安装Python 3.8.12,paddlenlp 2.6.1 post版本执行相同模型,命令为:taskset -c 0-3 python3 test.py
-
不限制CPU时,推理时间在2s以内。
-
限制0-3的CPU核,推理时间达到150s左右。
更新Docker版本
推理性能有部分提升,从70s左右提升到50s左右。
将鲲鹏服务器麒麟操作系统上的Docker版本从20.10.17更新到24.0.9版本。
推理性能有部分提升,从70s左右提升到50s左右。
将鲲鹏服务器麒麟操作系统上的Docker版本从20.10.17更新到24.0.9版本。
指定CPU对性能的影响
跨NUMA或者跨DIE对性能的影响不大,猜测主要还是线程切换的消耗。
不同CPU组合
同一Cluster(0-3)
同NUMA(0,4,8,12)
跨NUMA(0,1,32,33)
跨DIE(0,1,64,65)
不指定CPU
时间(ms)
350
318
326
338
16,481
跨NUMA或者跨DIE对性能的影响不大,猜测主要还是线程切换的消耗。
|
不同CPU组合 |
同一Cluster(0-3) |
同NUMA(0,4,8,12) |
跨NUMA(0,1,32,33) |
跨DIE(0,1,64,65) |
不指定CPU |
|
时间(ms) |
350 |
318 |
326 |
338 |
16,481 |
性能优化
限制程序线程和绑核运行
在8核虚拟机下不同核数的时间:
核数
Result_cache时间
Ner_res时间
推理时间(ms)
0
14:48:00:846
14:48:57,837
56,991
0-1
14:26:45,276
14:27:06,303
21,027
0-2
14:37:04,433
14:37:25,653
21,220
0-3
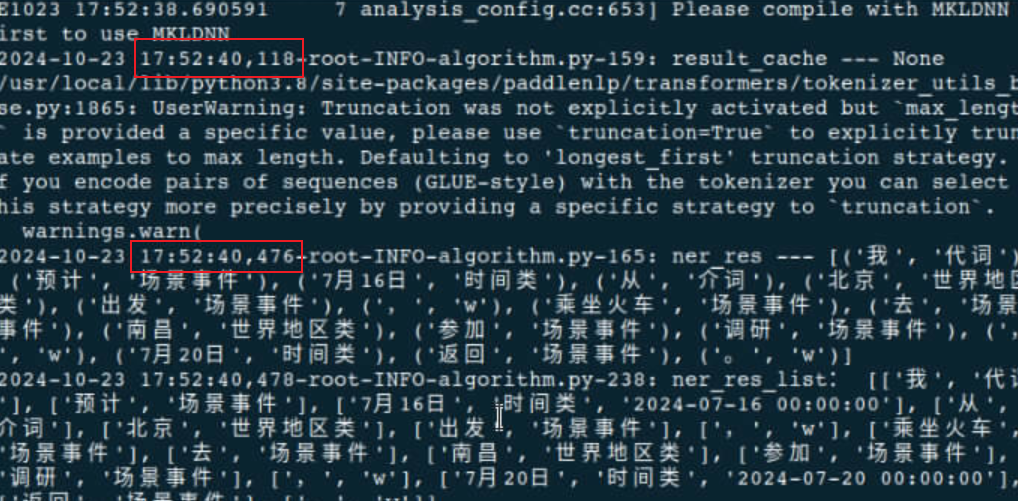
17:52:40,118
17:52:40,476
358
不绑核(4)
14:40:48,036
14:41:46,756
58,720
0-4
14:53:09,888
14:53:10,201
313
0-5
14:34:12,952
14:34:13,258
306
0-6
14:31:16,468
14:31:16,828
360
0-7
14:13:56,367
14:13:56,760
393
不限制(8)
14:45:40,418
14:45:40,719
301
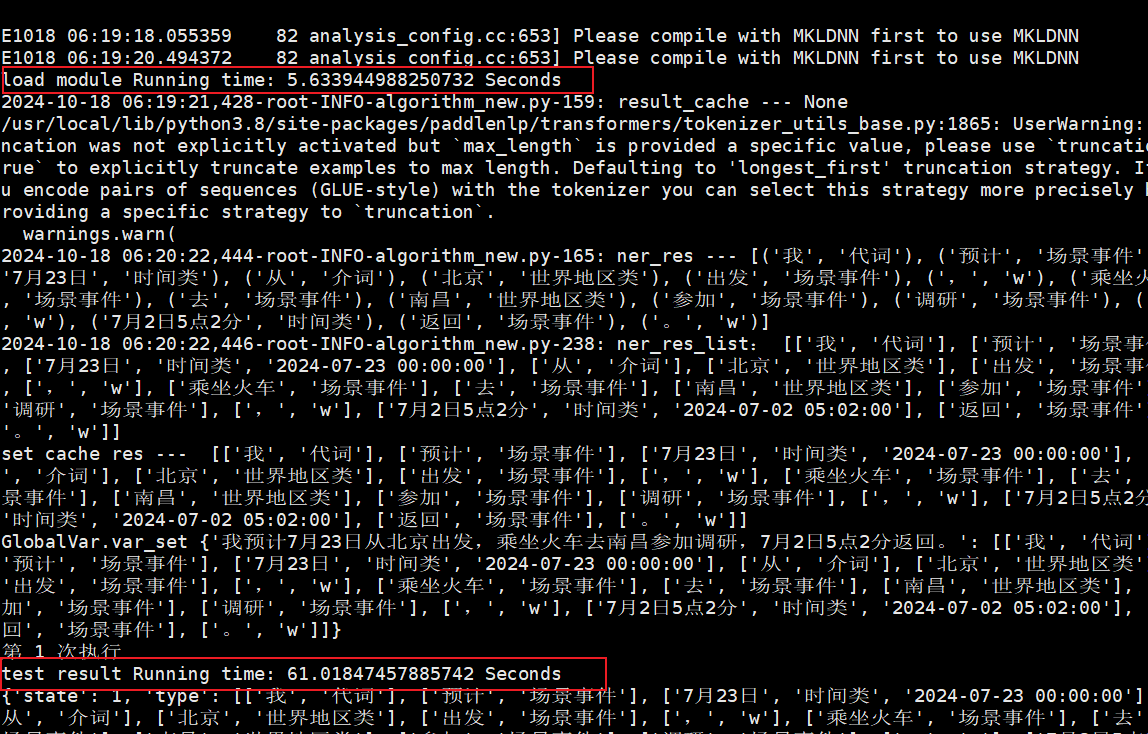
定位后发现开源Paddle框架默认使用物理CPU核数的一半进行推理,应用起了128个线程,但是容器只有4核资源,导致128个线程抢夺4核资源造成性能下降。
测试修改paddle代码self.num_threads=2,重新在鲲鹏服务器上执行4核推理:
核数
Result_cache时间
Ner_res时间
推理时间(ms)
不绑核4
17:18:31,942
17:18:48,670
16,728
绑核4
17:30:34,055
17:30:34,484
429
不绑核情况下仍然存在性能问题,测试跨NUMA或者跨Die对性能的影响不大,猜测主要还是线程切换的消耗。
不同CPU组合
同一Cluster(0-3)
同NUMA(0,4,8,12)
跨NUMA(0,1,32,33)
跨DIE(0,1,64,65)
不指定CPU
时间(ms)
350
318
326
338
16,481
在8核虚拟机下不同核数的时间:
|
核数 |
Result_cache时间 |
Ner_res时间 |
推理时间(ms) |
|
0 |
14:48:00:846 |
14:48:57,837 |
56,991 |
|
0-1 |
14:26:45,276 |
14:27:06,303 |
21,027 |
|
0-2 |
14:37:04,433 |
14:37:25,653 |
21,220 |
|
0-3 |
17:52:40,118 |
17:52:40,476 |
358 |
|
不绑核(4) |
14:40:48,036 |
14:41:46,756 |
58,720 |
|
0-4 |
14:53:09,888 |
14:53:10,201 |
313 |
|
0-5 |
14:34:12,952 |
14:34:13,258 |
306 |
|
0-6 |
14:31:16,468 |
14:31:16,828 |
360 |
|
0-7 |
14:13:56,367 |
14:13:56,760 |
393 |
|
不限制(8) |
14:45:40,418 |
14:45:40,719 |
301 |
定位后发现开源Paddle框架默认使用物理CPU核数的一半进行推理,应用起了128个线程,但是容器只有4核资源,导致128个线程抢夺4核资源造成性能下降。
测试修改paddle代码self.num_threads=2,重新在鲲鹏服务器上执行4核推理:
|
核数 |
Result_cache时间 |
Ner_res时间 |
推理时间(ms) |
|
不绑核4 |
17:18:31,942 |
17:18:48,670 |
16,728 |
|
绑核4 |
17:30:34,055 |
17:30:34,484 |
429 |
不绑核情况下仍然存在性能问题,测试跨NUMA或者跨Die对性能的影响不大,猜测主要还是线程切换的消耗。
|
不同CPU组合 |
同一Cluster(0-3) |
同NUMA(0,4,8,12) |
跨NUMA(0,1,32,33) |
跨DIE(0,1,64,65) |
不指定CPU |
|
时间(ms) |
350 |
318 |
326 |
338 |
16,481 |
其他调优措施
调优措施
更新Docker版本
不使用Docker镜像
增加内存
换操作系统
结果
有10%左右性能提升
无明显提升
无明显提升
无明显提升
总结
线程过多情况下,打印Python运行时的线程上下文切换信息,每秒非自愿上下文切换次数nvcswch/s远大于每秒自愿上下文切换次数cswch/s,说明被调度的任务被强制打断,任务在争抢使用CPU,导致CPU负载增高。
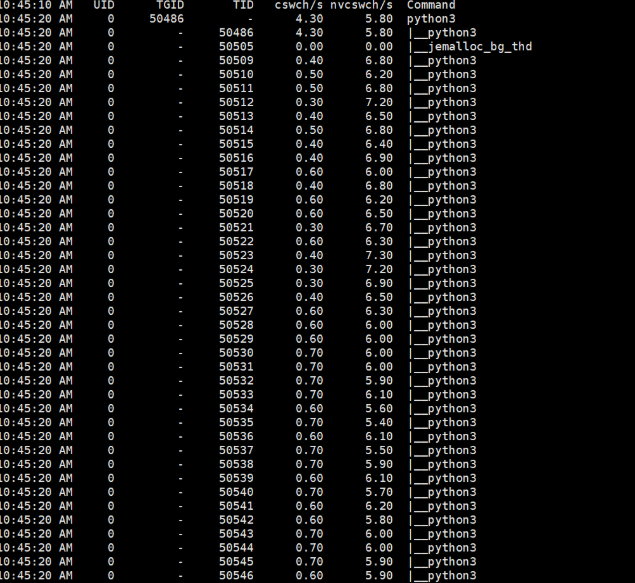 参考资料paddle半核性能提升:
参考资料paddle半核性能提升:
https://github.com/PaddlePaddle/PaddleNLP/issues/5756
https://github.com/PaddlePaddle/PaddleNLP/issues/9308
鲲鹏性能优化十板斧:可通过绑核减少跨numa访问内存。
https://www.hikunpeng.com/document/detail/zh/perftuning/tuningtip/kunpengtuning_12_0014.html
|
调优措施 |
更新Docker版本 |
不使用Docker镜像 |
增加内存 |
换操作系统 |
|
结果 |
有10%左右性能提升 |
无明显提升 |
无明显提升 |
无明显提升 |
总结
线程过多情况下,打印Python运行时的线程上下文切换信息,每秒非自愿上下文切换次数nvcswch/s远大于每秒自愿上下文切换次数cswch/s,说明被调度的任务被强制打断,任务在争抢使用CPU,导致CPU负载增高。 参考资料paddle半核性能提升: https://github.com/PaddlePaddle/PaddleNLP/issues/5756
https://github.com/PaddlePaddle/PaddleNLP/issues/9308
鲲鹏性能优化十板斧:可通过绑核减少跨numa访问内存。
https://www.hikunpeng.com/document/detail/zh/perftuning/tuningtip/kunpengtuning_12_0014.html