


JIT介绍与分析
发表于 2025/09/19
0
1. 相关概念介绍
早期JIT概念
1). 及时化生产技术(英语:Just in time,缩写为jit),又称及时生产,是一种生产管理的方法学,源自于丰田生产方式。通过减少生产过程中的库存和相关的顺带成本,改善商业投资回报的管理战略。2). 及时制度(JIT)的想法很简单:库存是资源浪费。JIT库存系统认为,库存带来了隐含的成本,因此高效率的企业应该不存在库存。公司需要采取一系列新的管理办法,进行变革。需要采取统计学、工业工程学、生产管理和行为科学中的管理办法。及时库存逻辑阐述了库存的内涵以及与管理的关系。
3). 库存会带来成本以及浪费,而不是增加或储存价值,这与传统会计学不同。这不是说,及时系统不需要对生产好的商品进行储存。而是鼓励企业逐步消除库存,以便削减生产流程中的成本。其次,在管理中逐渐适应“零库存”的状态。库存会带来很多附加成本,例如需要建立新的仓库、需要更新设备、减少流程的可变性、缺乏工人和设备灵活性、以及影响产量等。
4). 简单来说,及时制度主要的核心是“让正确的物资,在正确的时间,流动到正确的地方,数量是刚刚好的数量”。
JIT在MKL中的概念
最常用的性能关键型英特尔®数学核心函数库(英特尔®MKL)函数是通用矩阵乘法(GEMM)函数。英特尔®MKL 2019通过引入实时(JIT)代码生成功能,扩展了早期针对小问题规模(MKL直接调用、批处理API、紧凑API)的优化。D}GEMM在英特尔®高级矢量扩展2(英特尔®AVX2)和英特尔®高级矢量扩展512(英特尔®AVX-512)架构上运行。新的Just-In-Time (JIT)功能在运行时生成优化的GEMM内核,根据您提供的输入进行定制。英特尔®MKL 2019引入JIT功能,可显著加速小矩阵乘法。它支持JIT内核生成,用于:
1. 实际精度(SGEMM和DGEMM);
2. m, n, k ≤ 16,任意α和β,以及A矩阵和B矩阵的转置;
3. 英特尔®高级矢量扩展2(英特尔®AVX2)和英特尔®高级矢量扩展512(英特尔®AVX-512)架构。
英特尔®MKL 2019 Update 3扩展了上述功能,支持JIT内核生成
1. 实数和复数精度({S,D,C,Z}GEMM);
2. 任意矩阵大小,只要m, n, k中的一个小于128;任意α和β;A和B矩阵的转置;
3. 英特尔®高级矢量扩展(英特尔®AVX)、英特尔®高级矢量扩展2(英特尔®AVX2)和英特尔®高级矢量扩展512(英特尔®AVX-512)架构。
使用英特尔®MKL的JIT功能的应用程序将在所有架构上运行;如果当前架构或问题规模不支持JIT,英特尔®MKL将透明地回退到标准GEMM例程。
JIT在LLVM中的概念
LLVM Just-in-Time (JIT)编译器是一个基于函数的动态翻译引擎。为了理解什么是JIT编译器,让我们回顾原始的术语。这个术语来自Just-in-Time制造,一种商业策略,即工厂按需制造或者购买物资,而不引入库存。在编译过程中,这个比喻很合适,因为JIT编译器不会将二进制程序存储到磁盘(库存),而是在你需要它们的时候开始编译程序部分。尽管人们接受了业内行话,你可能还困惑于其它的名字,例如延时(late)或者懒惰(lazy)编译。JIT策略的优势在于知道将运行程序的精确的机器和微架构。这让JIT系统能够为特定的处理器微调代码。而且,有的编译器只有在运行时知道其输入,因而只能实现为JIT系统,除此之外别无选项。例如,GPU驱动程序即时编译着色语言,互联网浏览器处理JavaScript也是如此。
2. 区别
Intel MKL(Math Kernel Library)中的JIT(Just-In-Time Compilation)和LLVM中的JIT尽管都属于JIT编译技术,但它们的用途、实现和目标有所不同。1. 用途和目标:
- Intel MKL 的 JIT:- 用途: Intel MKL 的 JIT 编译器主要用于生成针对特定矩阵大小和结构优化的代码。例如,在执行矩阵乘法或卷积操作时,JIT 会根据输入的大小和形状生成专门优化的代码。
- 目标:主要目标是提升性能,特别是对于需要反复调用的特定大小或结构的数学运算。通过 JIT,MKL 可以生成高度优化的代码,利用特定硬件的指令集(如 AVX、AVX-512)来实现高效计算。
- LLVM 的 JIT:
- 用途: LLVM 的 JIT 编译器广泛用于许多编程语言和应用程序中,它可以在运行时将中间代码(如 LLVM IR)编译为机器码。LLVM 的 JIT 被用于通用目的,如动态语言解释器、即时编译器(如 JavaScript 引擎)、和某些高性能计算应用中。
- 目标: 主要目标是提供灵活、高效的动态编译能力,允许程序在运行时根据需求生成高效的机器代码。LLVM 的 JIT 通常用来支持动态语言或需要运行时优化的应用。
2. 实现方式
Intel MKL 的 JIT:实现方式:MKL 的 JIT 是针对特定数学运算的优化器和代码生成器。它通常生成特定运算(如矩阵乘法)的专用代码,以充分利用处理器的硬件特性。JIT 编译器会根据输入矩阵的尺寸和布局,选择最优的实现策略,并在运行时生成最合适的机器码。
例子:在执行矩阵乘法时,MKL JIT 可以根据矩阵大小和硬件特性动态选择或生成最优的矩阵乘法实现,减少内存访问、提升缓存利用率等。
LLVM 的 JIT:
实现方式:LLVM 提供了一个通用的 JIT 编译框架,它可以处理 LLVM IR(中间表示)并生成机器码。LLVM 的 JIT 支持多种优化技术,如内联、循环展开、指令选择等,并且可以在不同的处理器架构上生成高效代码。
例子: LLVM JIT 通常用于动态语言解释器中,如在执行 Python、Ruby 或 JavaScript 代码时,将高层次的字节码或中间代码在运行时编译为高效的本地机器码。
3. 适用领域:
Intel MKL 的 JIT:主要适用于科学计算和高性能计算领域,尤其是在特定硬件上进行优化的数学库中,如矩阵运算、卷积、傅里叶变换等。LLVM 的 JIT: 适用于广泛的领域,包括编译器、虚拟机、解释器、高性能计算、游戏引擎、图形渲染等。LLVM 的 JIT 是一个通用的编译框架,不局限于特定的应用领域。
4. 灵活性:
Intel MKL 的 JIT: 相对较少的灵活性,主要专注于数学运算的优化,不支持通用编译任务。LLVM 的 JIT: 高度灵活,可以处理广泛的编译任务,适用于多种编程语言和不同的计算需求。
总结:
Intel MKL 的 JIT 专注于数学库中的高性能运算优化,生成特定任务的高效代码;而 LLVM 的 JIT 是一个通用的 JIT 编译框架,广泛应用于各种需要动态编译的领域。两者在用途、实现方式和适用领域上都有显著的差异。3. JIT使用方法
MKL
英特尔MKL v.2019提供了**两个接口**供用户访问JIT功能。1. 第一个对用户是完全透明的,并通过现有MKL_DIRECT_CALL接口的扩展激活(有关更多详细信息,请参阅MKL_DIRECT_CALL文档)。
2. 第二个接口涉及新的专用应用程序编程接口(API),供愿意更改其代码的高级用户使用,并提供了通过消除大部分相关的调用开销来获得更高的性能的能力。
隐式用法
MKL_DIRECT_CALL_JIT
利用英特尔®MKL 2019新的JIT GEMM功能的最简单方法是定义预处理器宏MKL_DIRECT_CALL_JIT。不需要其他更改。(如果以顺序模式使用MKL,请改为定义MKL_DIRECT_CALL_SEQ_JIT。)当MKL_DIRECT_CALL_JIT处于活动状态并且用户调用GEMM时,MKL将决定JIT代码生成是否对给定的GEMM问题有利。如果是这样,它将生成特定于大小和架构的内核,根据给定的参数(layout、transa、transb、m、n、k、alpha、lda、ldb、beta、ldc)进行定制。然后每次使用同一组参数调用GEMM时,这些内核都会被缓存和重用。如果MKL判定JIT不是有益的,则将照常调用标准GEMM例程。
MKL_DIRECT_CALL_JIT和MKL_DIRECT_CALL_SEQ_JIT预处理器宏允许您快速评估JIT功能是否为您的应用程序提供了性能优势,特别是那些为小问题大小多次调用GEMM的应用程序。
假设GEMM在bench.c源文件中被调用,那么可以用如下的编译指令构建应用,其指定了宏MKL_DIRECT_CALL_SEQ_JIT开启了JIT特征。
icc bench.c –o bench -DMKL_ILP64 -I${MKLROOT}/include -L${MKLROOT}/lib/intel64 -lmkl_intel_ilp64 -lmkl_sequential -lmkl_core -lpthread -lm –ldl –DMKL_DIRECT_CALL_SEQ_JIT在英特尔®AVX2或英特尔®AVX-512系统上运行生成的可执行基准时,循环的第一次迭代将生成一个特定于大小和架构的专用GEMM内核并存储它。随后的循环迭代检索存储的内核并重用它。
总之,MKL_DIRECT_CALL_JIT允许用户加速小矩阵乘法,而无需修改代码。然而,缓存内核并在运行时查找它们确实会产生一些开销。要获得最佳性能,用户应该求助于“英特尔MKL”专用的JIT API,如下节所述。
显式用法
Just-In-Time (JIT) GEMM API
mkl_jit_create_{s,d,c,z}gemm (creates a JIT kernel)
mkl_jit_get_{s,d,c,z}gemm_ptr (gets a pointer to the kernel function)
mkl_jit_destroy (destroys a JIT kernel)
GEMM JIT内核和所需的运行时代码生成器通过调用mkl_jit_create_{s,d,c,z}gemm来生成和存储,它将标准GEMM输入参数(除了指向矩阵A,B,C的指针)作为输入,和C)和一个指针(一个不透明的指针),其中将存储代码生成器的句柄mkl_jit_create_{s,d,c,z}gemm函数返回一个mkl_jit_status_t类型的状态码,其值可以是以下之一:
MKL_JIT_SUCCESS – indicates that a GEMM kernel has been generated;
MKL_NO_JIT – a GEMM kernel was not generated and standard GEMM will be used instead;
MKL_JIT_ERROR – an error occurred due to lack of memory.
返回MKL_NO_JIT可能的原因如下:
JIT is not available for the current instruction set architecture;
Prior to Intel® MKL 2019 Update 3, the matrices were larger than the maximum supported size;
For Intel® MKL 2019 Update 3, the matrices are large enough that JIT may not be beneficial.
创建代码生成器之后,调用mkl_jit_get_{s,d,c,z}gemm_ptr来检索指向生成的GEMM内核的函数指针。这个函数指针执行所请求的GEMM操作,它带有四个参数:一个指向代码生成器的句柄,以及指向A、B和C矩阵的指针。请注意,即使mkl_jit_create_{s,d,c,z}gemm返回MKL_NO_JIT,也会返回有效的指针;在这种情况下,将使用标准GEMM,而不是JIT生成的内核。
最后,当不再需要内核时,mkl_jit_destroy函数释放与代码生成器和GEMM内核相关联的内存。
declare a handle on the code generator
void* jitter;
// create the code generator and generate the tailored GEMM kernel
// the first parameter is the address of the code generator handle
mkl_jit_status_t status = mkl_jit_create_dgemm(&jitter, CblasColMajor, CblasNoTrans, CblasTrans, 5, 3, 12, 1.0, 8, 8, 0.0, 8);
// check if the code generator has been successfully created
if (MKL_JIT_ERROR == status) {
fprintf(stderr, “Error: insufficient memory to JIT and store the DGEMM kernel\n”);
return 1;
}
// retrieve the function pointer to the DGEMM kernel
// void my_dgemm(void*, double*, double*, double*)
// it is safe to call mkl_jit_get_dgemm_ptr only if status != MKL_JIT_ERROR
dgemm_jit_kernel_t my_dgemm = mkl_jit_get_dgemm_ptr(jitter);
for (it = 0; it < nb; it++) {
…
// replace cblas_dgemm calls by calls to the generated DGEMM kernel
// the first parameter is the handle on the code generator
// followed by the three matrices
my_dgemm(jitter, a[it], b[it], c[it]);
…
}
// when the DGEMM kernel is not needed, free the memory.
// the DGEMM kernel and the code generator are deleted
mkl_jit_destroy(jitter);决定何时使用JIT
- 如果m、n和k都很小(≤32),如果您的代码将重用生成的内核至少100-1000次,则JIT很可能是有益的。由于MKL_DIRECT_CALL_JIT中的开销,建议使用JIT API以获得最佳性能。- 如果m、n、k中的一个或两个较小(≤32),其他较大,MKL_DIRECT_CALL_JIT不会引入太多开销,可以用来快速判断JIT是否有用。如果是这样,您还可以考虑重构您的代码以使用JIT API来获得额外的性能增益。
- 如果m、n和k都较大(>32),则JIT可能提供的加速比很少到中等加速比,具体取决于具体问题。尝试使用MKL_DIRECT_CALL_JIT来判断JIT是否适合您的应用程序。
- MKL_DIRECT_CALL_JIT和JIT API都使用启发式来确定是否生成JIT GEMM内核。MKL_DIRECT_CALL_JIT更保守:它只有在预测JIT会提高性能时才会生成内核。但是,JIT API将生成内核,除非确定JIT不会提高性能。在英特尔®MKL 2019 Update 3中,如果m、n和k都至少为128,则JIT API不会生成内核。
目前,所有的JIT GEMM内核都是单线程的。但是,从多线程代码创建、调用和销毁内核是安全的。如果你有一个GEMM问题,其中m,n和k中的一个非常大,而其他两个很小,那么在多个线程之间划分问题并在子问题上使用JIT可能是值得的。
摊销代码生成时间
由于生成JIT内核需要一些时间,因此通常建议仅在可以多次重用生成的内核时使用JIT;根据经验,可以重用数百次或更多次。(回想一下,本文中的性能图表假定JIT内核生成的成本在对同一GEMM内核的大量调用中摊销。)代码生成时间仅对较小的问题是一个重要的问题,其中单个GEMM调用要比生成JIT内核快数百倍。随着输入矩阵越来越大,单个GEMM调用需要更多的时间,代码生成时间变得越来越不重要。
下表提供了所需函数调用数的估计值,以证明JIT对于一些小问题的前期内核生成成本是合理的,而不是使用传统的英特尔®MKL GEMM。对于每个问题,给出一个范围。范围中的高位数字代表只生成一个GEMM内核的程序。较低的数字代表生成多个GEMM内核的程序。在测试中,所有前导维度都对齐为64字节的倍数。
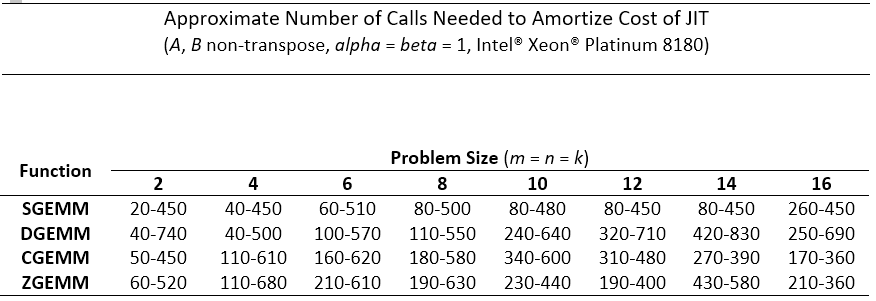
相关开源实现(研究方向)
1. MARLIN
MARLIN考虑了一种独特的代码生成方法,其中数据值作为即时值动态嵌入到指令中,有效地将内存负载转换为即时负载。开源地址:https://github.com/malithj/marlin.git
优化方法
立即数替换load指令

相比之下,MARLIN利用面向数据的代码生成技术,其中数据值作为即时值嵌入到指令中。这种方法消除了与 CPU 发出数据负载相关的开销,从而大大减少了执行的负载指令数量。此外,由于卷积运算中使用的权重数据现在可以表示为直接操作数,因此值实际上通过 L1-icache 而不是 L1-dcache 进行流式传输。最终,当考虑所有级别的缓存(即 L1、L2 和 L3)时,与现有的代码生成技术相比,这将导致缓存行为发生变化。文章假设性能优势来自两个来源:首先,减少缓存未命中将减少整体内存延迟,其次,MARLIN 减轻了 L2 缓存带宽的压力。
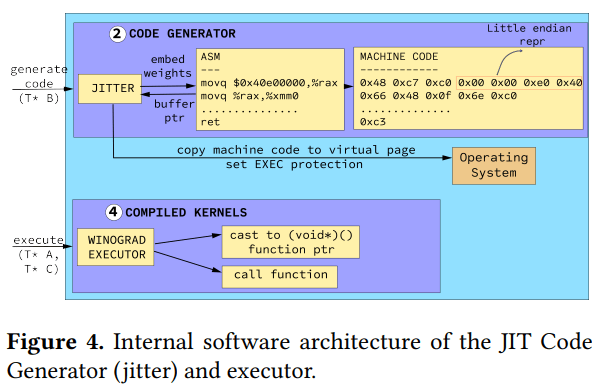
代码生成与执行
通过在缓冲区中动态生成指令,需要与卷积算法无缝集成。与现有解决方案类似,我们首先通过操作系统分配虚拟页面,然后启动代码生成过程以填充代码缓冲区。这些页面稍后被标记为可执行,而不是可读/可写,以允许动态执行。基于算法的执行流程,利用元数据数组,加载并动态执行所需的指令。Implement
关键设计考虑因素之一是易于与现有计算集成。我们通过完全自动化代码生成过程,使用户能够在需要时通过 API 调用①请求代码生成(参见图 3)实现了这个目标。对于整个程序执行,代码生成仅执行一次,之后使用内存引用来触发执行。执行机制类似于现有的最先进的JIT库。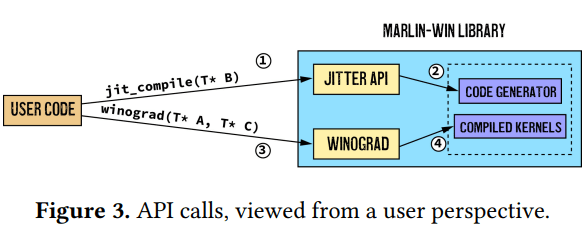
另一个关键考虑因素是利用 SIMD 向量扩展的可用并行性。MARLIN库目前在支持 AVX-512F 标志的 Intel 处理器上受支持,但可以轻松扩展到其他处理器。在实验评估中,使用单插槽 12 核 3.50GHz Intel i9-9920X Skylake CPU,并启用了超线程。每个内核都可以访问两个 AVX-512 混合乘加(FMA) 单元。
关键步骤实现
代码生成函数
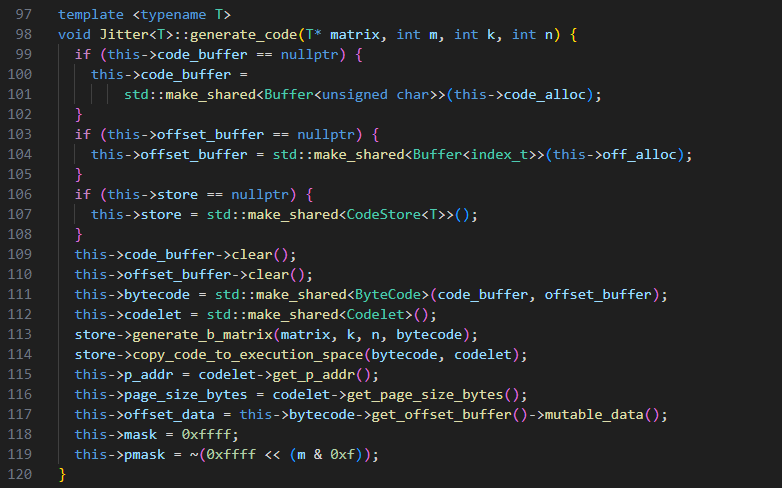
主要步骤
1. 分配code_buffer及其他数据空间2. 生成加载B矩阵value的汇编代码片段generate_b_matrix
3. 将构造的代码片段从ByteCode拷贝到Codelet中的页对齐的内存段,设置memory属性为读/执行
4. Jitter类的p_addr成员存储可执行指令所在内存的起始地址(函数入口),以及其他辅助信息
步骤详情
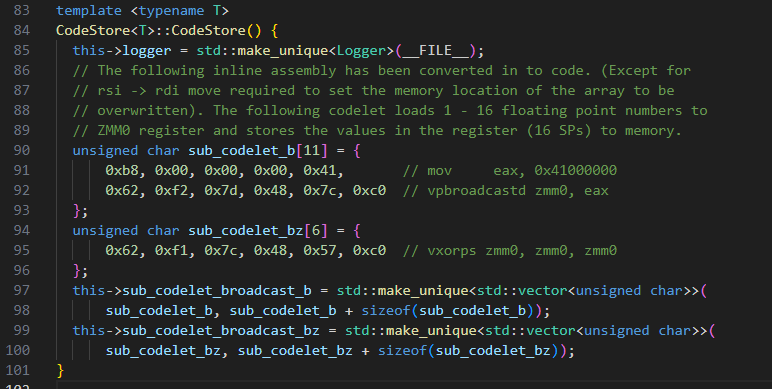
CodeStore类构造函数中生成了三条基本模板指令,分别存储在sub_codelet_b和sub_codelet_bz字符数组中
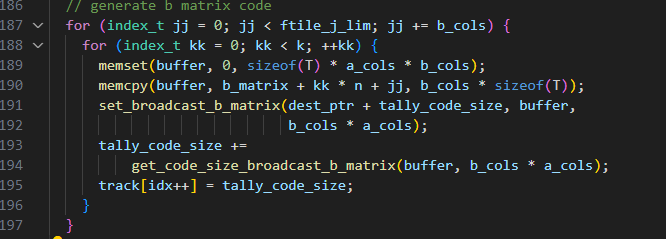
generate_b_matrix函数的核心是一个两层for循环,用于实现B矩阵value转换为汇编指令立即数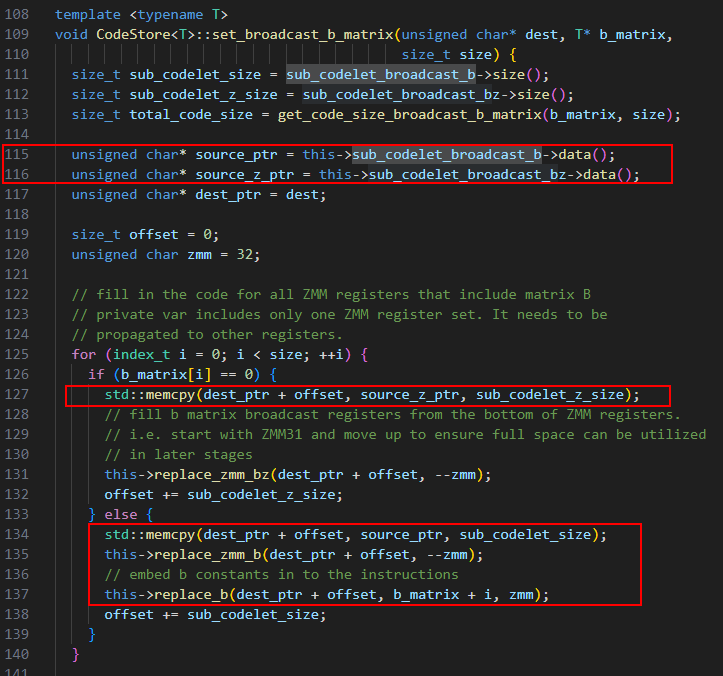
在generate_b_matrix函数中调用set_broadcast_b_matrix函数,将不同类型的指令根据矩阵数据value是不是0而拷贝到code_buffer中
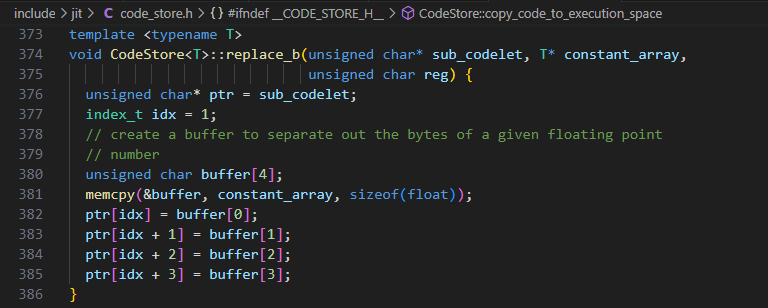
然后调用replace_b,replace_zmm_b和replace_zmm_bz修改code_buffer中的指令的立即数的值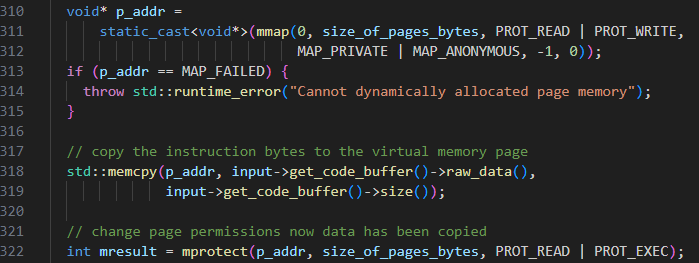
最后调用copy_code_to_execution_space函数,实现内存页面映射,将指令从buffer拷贝到Codelet中的页对齐的内存段,设置memory属性为读/执行。
GEMM函数
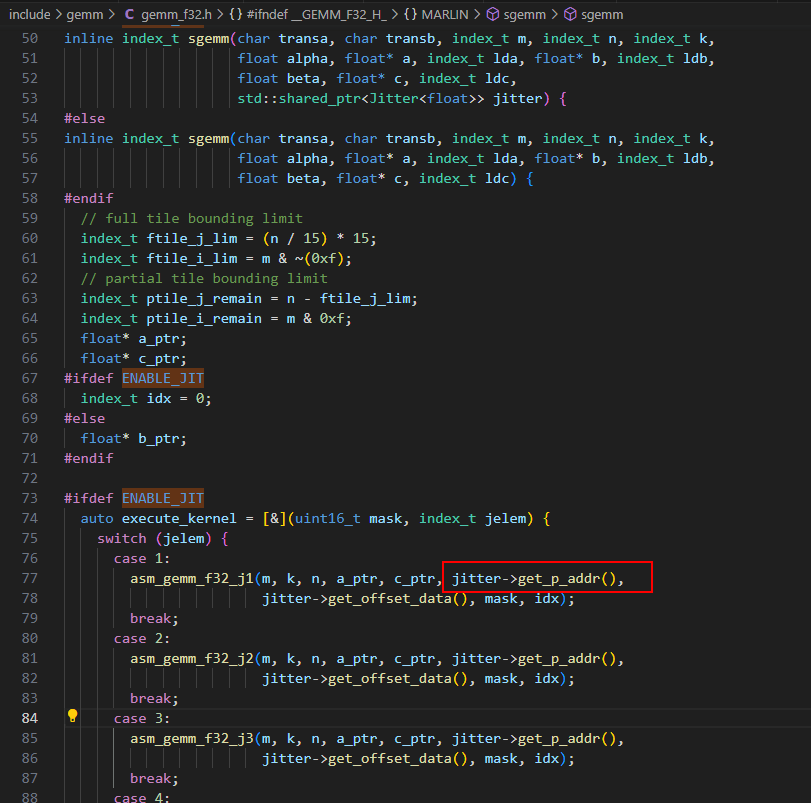
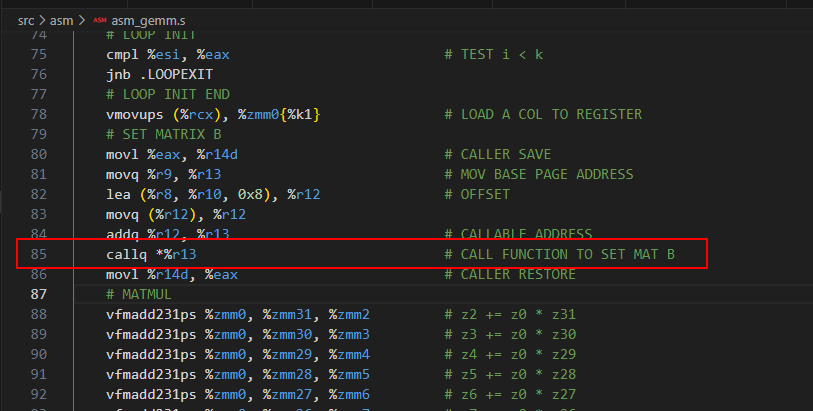
将Jitter的p_addr传入各种gemm函数,在gemm函数中call目标地址p_addr处的函数,执行JIT生成的代码片段,完成B矩阵通过立即数赋值的方式加载到AVX寄存器
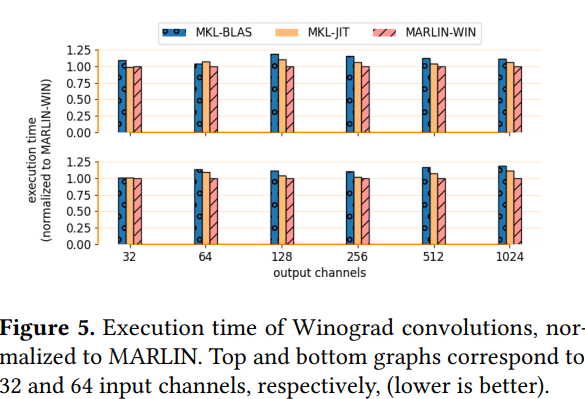
Results
从测试结果观察到,在满足以下情况时,JIT库的性能比传统的BLAS库更好: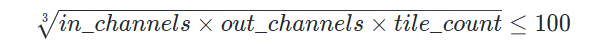
2. LIBXSMM
开源地址:https://github.com/libxsmm/libxsmm.git
动态代码生成推动了其他GEMM库的开发,包括oneDNN和Intel的数学核心函数库。这两个库都遵循LIBXSMM中使用的类似方法,并依赖于通过JIT指令生成进行的性能优化。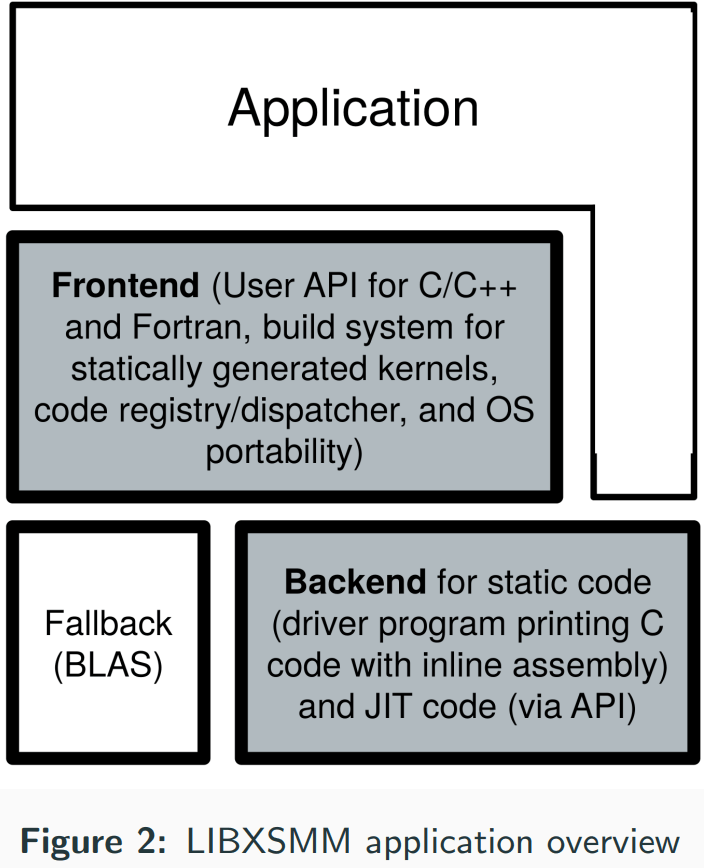
LIBXSMM 是一个用于专用密集和稀疏矩阵运算以及深度学习基元(如小卷积)的库。该库面向英特尔架构,采用英特尔 SSE、英特尔 AVX、英特尔 AVX2、英特尔 AVX-512(带 VNNI 和 Bfloat16)和英特尔 AMX(高级矩阵扩展),并由代号为 Sapphire Rapids 的未来英特尔处理器支持。代码生成主要基于 Just-In-Time (JIT) 代码专用化,以实现独立于编译器的性能(矩阵乘法、矩阵转置/复制、稀疏功能和深度学习)。LIBXSMM 适用于“一次构建,随处部署”,即不需要特殊的目标标志来利用可用的性能。支持的 GEMM 数据类型包括:FP64, FP32, bfloat16, int16, and int8。
interfere
目前,LIBXSMM 支持三个高级前端:
- functions for single and double precision (Fig. 2)
- C++ using polymorphism (overloaded fn., templates)
- FORTRAN using polymorphism (overloaded routines)

除了这个些接口外,LIBXSMM 还提供具有完整 S/DGEMM 接口的调用,以确保非常简单的集成。该接口还支持各种 α 和 β 值以及与 M、N、K 不同的leading dimensions
Implementation
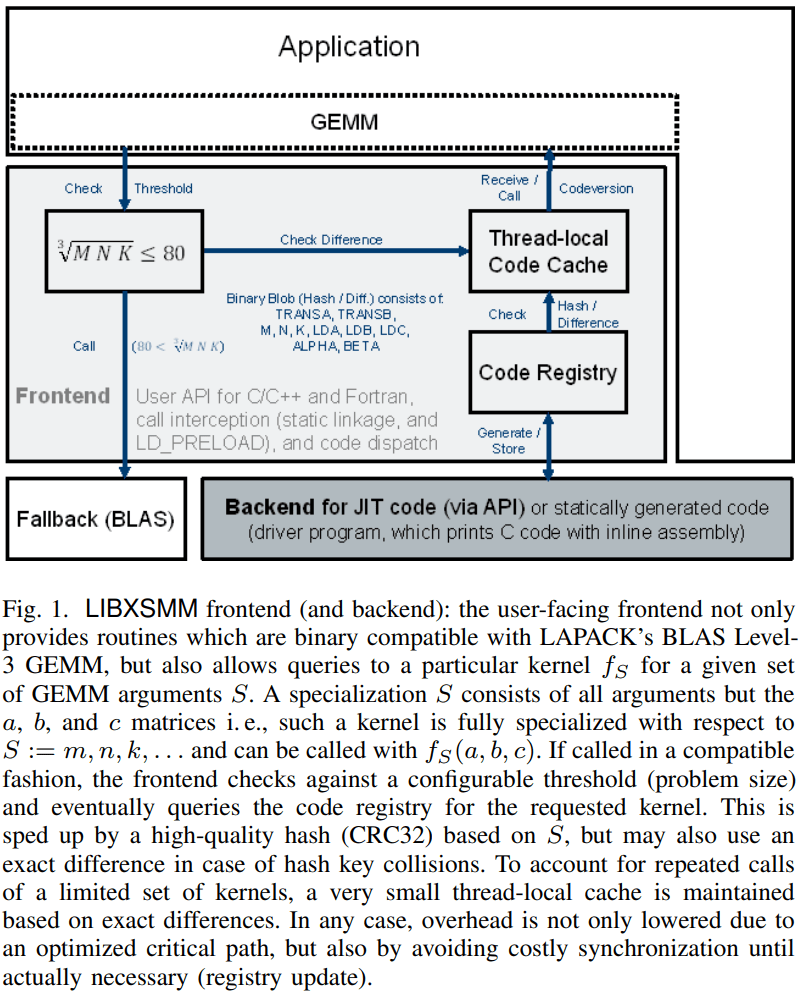
一个小GEMM由相应矩阵-矩阵乘法的M、N和K参数来表示。从示意图可知,JIT的Frontend端通过判断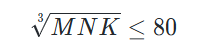
来选择默认的BLAS调用还是使用JIT。
Frontend
LIBXSMM 实现了一个三级调度机制,该机制通过查找特定问题实例 (M,N,K) 的专用代码来帮助执行可能性能最佳的实现:
1. 专用例程(在汇编代码中实现)
2. 可内联的 C/C++ 代码或优化的 FORTRAN 代码
3. BLAS 库调用(回退)
所有三个级别都可以直接访问,允许自定义机制(图 2)。该库还允许在需要具有相同 M、N 和 K 的多个调用时摊销调度成本。此外,可以调整确定何时回退到 BLAS 实现的阈值。
汇编代码选择基于使用 CRC32 校验和的哈希表(其计算可以通过 SSE4.2 指令加速)。此外,前端还具有实验性的自动即时编译选项,允许即时构建所需的内核。这包括实现 JIT 代码缓存,以尽可能降低开销。
代码调度机制
(1) 快速确定(以线程安全的方式)代码版本是否已生成,
(2) 如果代码版本尚未汇编,则进入锁定区域,
(3) 分配可执行缓冲区以保存机器指令,调用后端以实际生成代码版本,以及
(4) 记录代码版本以备将来代码调度
每个阶段都经过优化,使自动代码调度不仅成为可能,而且值得使用(例如,用于与 GEMM 兼容的函数调用)。
为了进一步优化 dispatch 代码版本,该库维护了最近使用的内核的小型缓存。缓存机制还维护上次点击的索引,该索引仅在发生点击时更新,因此,通过仅检查单个描述符,以连续方式调用同一内核将立即点击正确的代码版本。此索引还提供了明智的策略来驱逐条目(因为可以替换最远的条目)。为了避免任何同步原语(包括原子内存操作),缓存对于每个线程都是独立的(线程本地存储)。
虽然 JIT 代码生成是根据 CPUID 标志完成的,但只有在 JIT 已被禁用,或者没有比 (静态) 构建时使用的更好的指令集扩展可用时,才会注册静态生成的内核。
Code Generation
代码生成组件支持三种不同的输出格式:内联汇编(*.h、*.c、*.cpp)、纯汇编(*.s-file)和运行时编码。代码生成器支持任意 M、K、N、lda、ldb 和 ldc。这种灵活性是必需的,以便我们可以混合和匹配 HPC 应用程序中出现的各种不同(子)矩阵形状。为了解决奇形怪状的大小,支持掩码指令。这避免了不需要的应用程序端填充。
AVX2 targeting the Intel Xeon processor
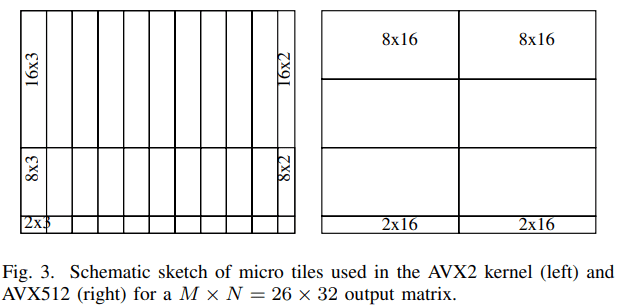
对于小尺寸,微内核的形状对于达到高性能至关重要。这些微内核基于外积公式,该公式针对矩阵 C 中的以下结果块 (Mg × Ng):{16, 12, 8, 4, 2, 1}×{1, 2, 3}。16 × 3 的大小由 AVX2 指令集扩展决定,该扩展提供 16 个四元素宽的矢量寄存器,称为 ymm0-15,假设双精度。要存储此 C-result buffer,需要 16 个 registers 中的 12 (4 · 3)。其他三个寄存器保存 B 的三列的第 k 行的广播。剩余的最后一个寄存器是一个环形缓冲区,包含 4 个条目,用于 A 的 k 列的 16 行。这导致了所有 16 个可用 registers 的最佳使用。由于 AVX2 中的矢量寄存器长度为 4,因此 M mod 4 = 0 的预期效率最佳。因此,对于用于填充最后一行的情况 {12, 1}×{1, 2, 3},由于未对齐的负载,预计会因未对齐的负载而影响性能,参见图 3。GEMM 微内核内部的加载指令性能会因未对齐的负载而降低,因为它们会遭受缓存行拆分(向量加载和跨越缓存行边界的数据存储)的影响。此问题与硬件相关,无法在 LIBXSMM 中解决。为了避免因未对齐的负载而导致的性能下降,应用程序可以使用其数据结构的零填充来强制执行对齐的内核。此 padding 是一种通用的应用程序性能优化技巧。
AVX512 targeting the Intel Xeon Phi processor
AVX512 中的寄存器数量是原来的两倍,长度是原来的两倍,因此我们的 AVX2 内核可以增加到 48 × 3(最大值)。由于瓦片大小倾斜,无法再有效地阻止此大小。最好在 DGEMM 内核中使用 tall-and-skinny 或 short-and-wide 块,以便只有一个指向 A 或 B 的加载指令,然后是一系列具有融合内存操作数的 Fused-Multiply-Adds。
Just-In-Time compilation
每条 x86 汇编指令都使用一系列十六进制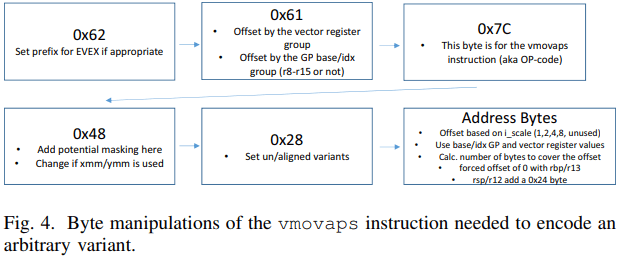
我们考虑对汇编指令进行编码,例如 “vmovaps 256(%rax,%rcx,2), %ymm16” (AVX2)。对于此程序集示例,操作码字节序列长度为 8 个字节,位置为:0x62,0xE1,0x7C,0x28,0x28,0x44,0x48,0x08。图 4 显示了 AVX512 的情况,当使用 zmm 寄存器时,或者使用的至少一个 xmm 和 ymm 寄存器在 16-31 范围内。第二个字节从 0x61 开始,但被调整为 0xE1因为 %ymm16 位于第 3 组八个寄存器中。第三个字节减少了 0x20因为使用了 ymm 寄存器。第 6 个字节及以后的字节将变为 0x44、0x48 和 0x08。之所以使用 0x44,是因为位移 256 可以用单个字节表示。0x48部分反映了 i scale 参数 2 以及使用的 GP 寄存器。0x08解释如下。
我们调用一个例程,该例程采用位移因子 256 或缩放因子 2 等属性,并告诉我们使用哪些整数寄存器和浮点寄存器。任何快速例程都必须至少检查每个参数一次,并调整此参数影响的每个字节。在此示例中,%rax 影响第 7 个字节。将 %rax 更改为 %rcx 会将第七个字节从 0x48 更改为 0x49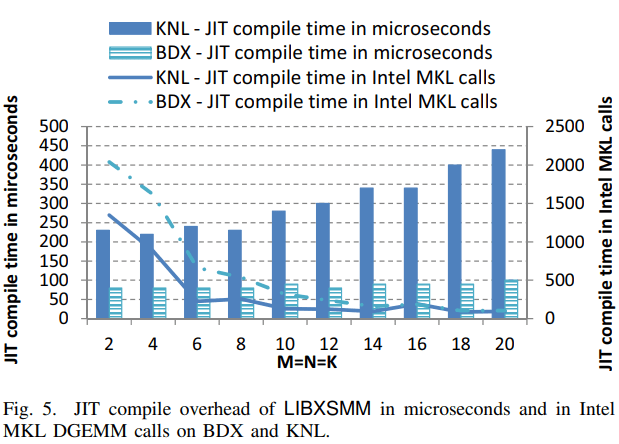
通过检查我们属于哪一组 8 个,以及我们在哪里,我们知道最终的操作码序列。只触及这些参数并且每个参数只询问几个 if 的实现必须是理想的。至少,当一次只考虑一个汇编指令时是理想的,如图 5 所示。在图 5 中,创建 JIT 代码的持续时间显示为使用英特尔 MKL 时可能的 DGEMM 调用次数。如果我们与运行 LIBXSMM 的 DGEMM 内核所需的时间进行比较,结果会更好,并且更早地到达相应的交叉点。
Assembly Backend
汇编生成器的实现遵循了大型 xGEMM 中众所周知的思想,但由于尺寸较小,无法采用复制例程来构建最佳的 A 或 B 面板。因此,它派生出几个高性能的微内核,这些微内核被编排以形成一个小型的 xGEMM 操作。具体来说,后端依赖于 M 的集合 × N = {1S, 0.5V, 1V, 2V, 3V, 4V } × {1, 2, 3, 4} 微内核,在 SSE、AVX 和 AVX2 的情况下。S代表标量执行,V代表向量寄存器长度。这范围从 2 到 8,具体取决于指令集和精度。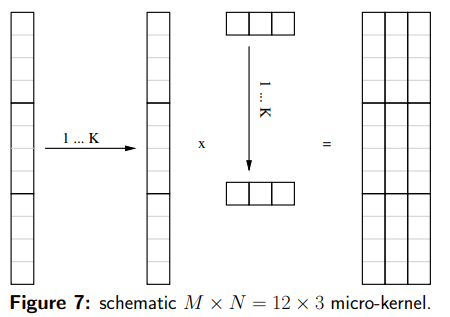
通过在缓冲区中动态生成指令,需要与算法无缝集成。首先通过操作系统分配虚拟页面,然后启动代码生成过程以填充代码缓冲区。这些页面稍后被标记为可执行,而不是可读/可写,以允许动态执行。基于算法的执行流程,利用元数据数组,加载并动态执行所需的指令。对于整个程序执行,代码生成仅执行一次,之后使用内存引用来触发执行。
Result
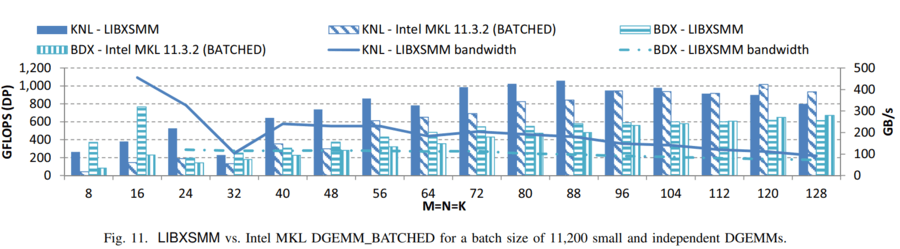
LIBXSMM v2.0
LIBXSMM 2.0 是支持 AArch64 的初始版本(baseline为v8.1),它实际上涵盖了从嵌入式和移动到超级计算机的ARM64位架构。LIBXSMM的构建和安装过程与Intel架构(IA)相同,并且该库可以本地编译或交叉编译。
代码实现
接口实现
libxsmm的用法主要有3个步骤,分别是创建shape,生成函数,执行函数。
在此基础上封装了一些类似于blas gemm的接口,例如libxsmm_dgemm和libxsmm_sgemm,其执行宏函数LIBXSMM_XGEMM
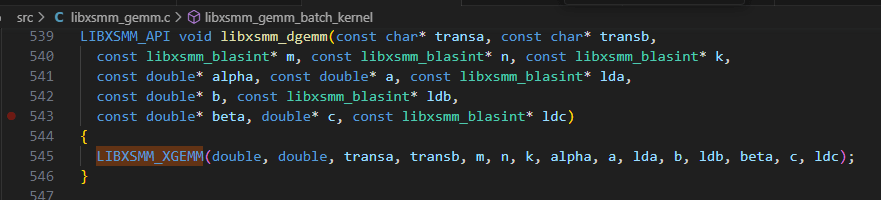
宏函数LIBXSMM_XGEMM中完成下面功能:
1. 处理输入参数
2. 判断gemm的size是否符合JIT适用范围如果符合则执行**3**,否则说明size过大,跳转到**8**
3. 调用libxsmm_create_gemm_shape创建gemm_shape
4. 调用libxsmm_dispatch_gemm,得到JIT生产的函数指针xgemm_function
5. 如果获取的JIT函数指针xgemm_function不为NULL执行**6**,否则跳转到**7**
6. 执行libxsmm_xgemm_function_函数指针所指向的生成的JIT代码,完成gemm功能
7. 执行LIBXSMM_XGEMM_FALLBACK0回退到原生blas
8. 执行LIBXSMM_XGEMM_FALLBACK1回退到原生blas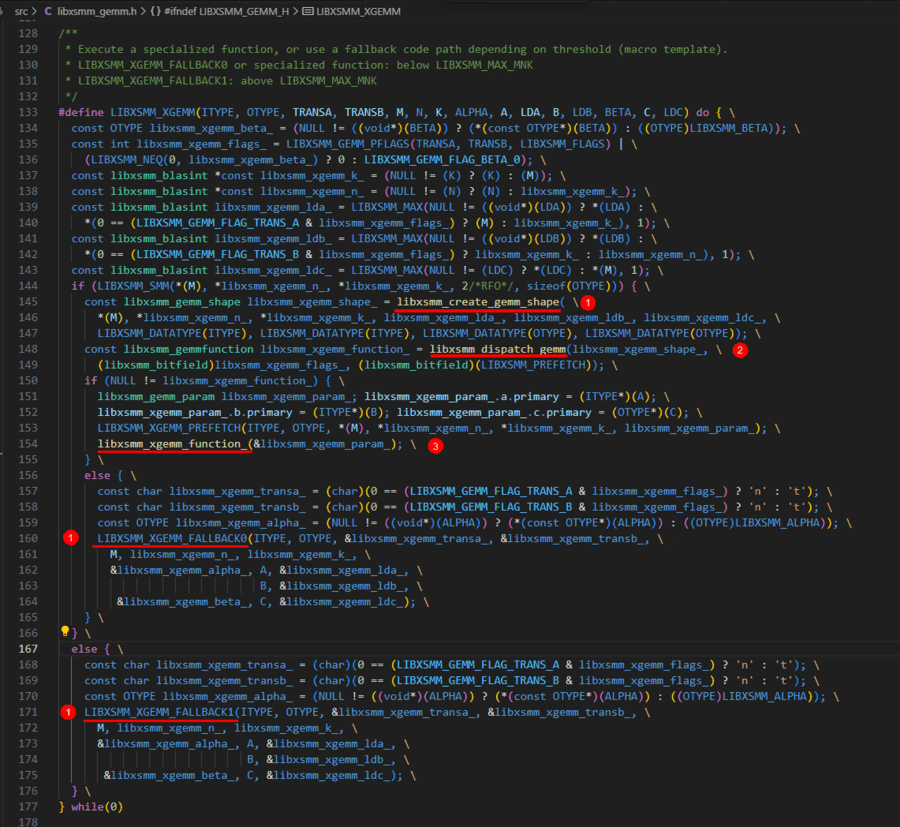
核心函数
libxsmm的关键逻辑位于libxsmm_main.c的函数:
LIBXSMM_API_INLINE libxsmm_code_pointer internal_find_code(libxsmm_descriptor* desc, size_t desc_size, size_t user_size)其在libxsmm_xmmdispatch中被调用,是libxsmm_xmmdispatch的关键部分,其中desc是Matrix Multiply的描述符,其中包含了m,n,k,lda,ldb,ldc,datatype,prefetch等信息,其逻辑是计算并判断请求的函数是否已经JIT生成过,否则生成JIT代码;将代码记录并拷贝存储到cache缓存结构体中;返回libxsmm_code_pointer类型的对象,其中包含了JIT函数入口信息
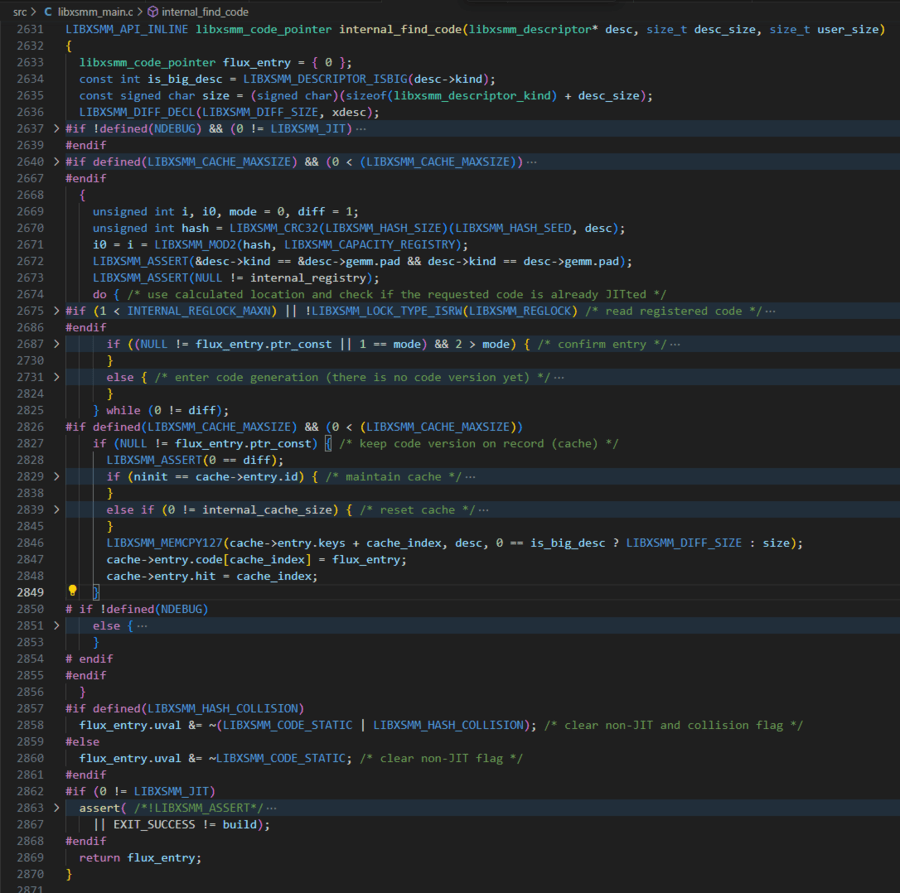
其中enter code generation (there is no code version yet)这一else分支中,如果cpuid在libxsmm支持的范围里,就调用libxsmm_build函数来构建JIT代码,否则返回NULL函数指针
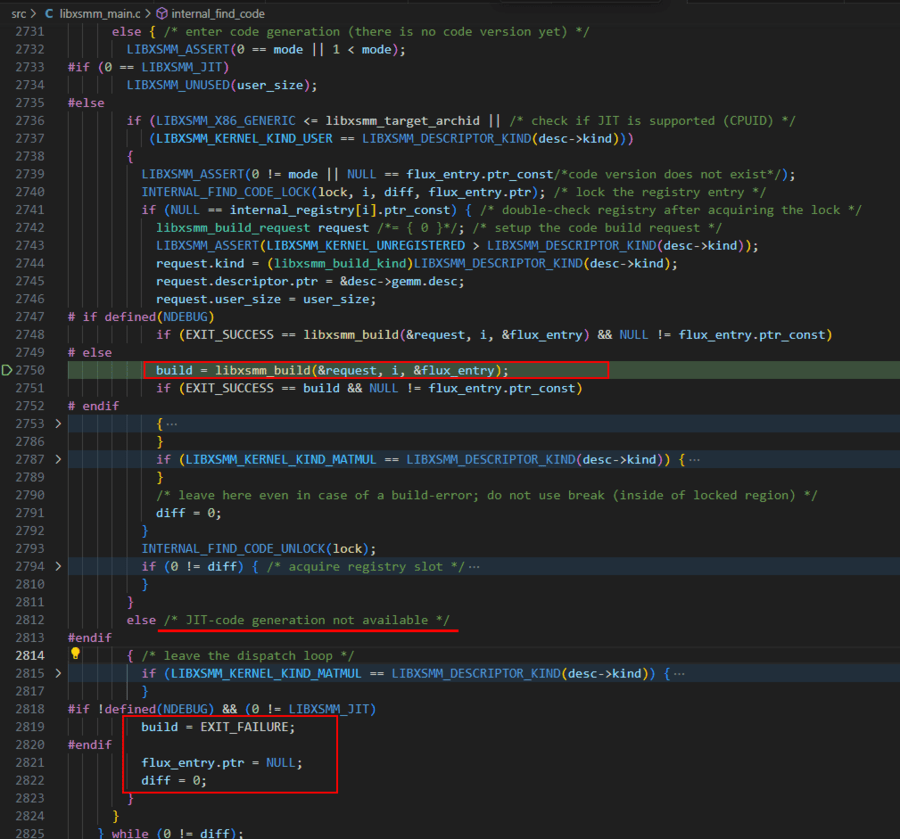
在libxsmm_build函数中,Switch语句判断请求的类型,执行相应分支的JIT代码生成函数,例如普通GEMM类型会执行libxsmm_generator_gemm_kernel函数来生成gemm_kernel,除此外还有packed,sparse,matcopy等类型的kernel。
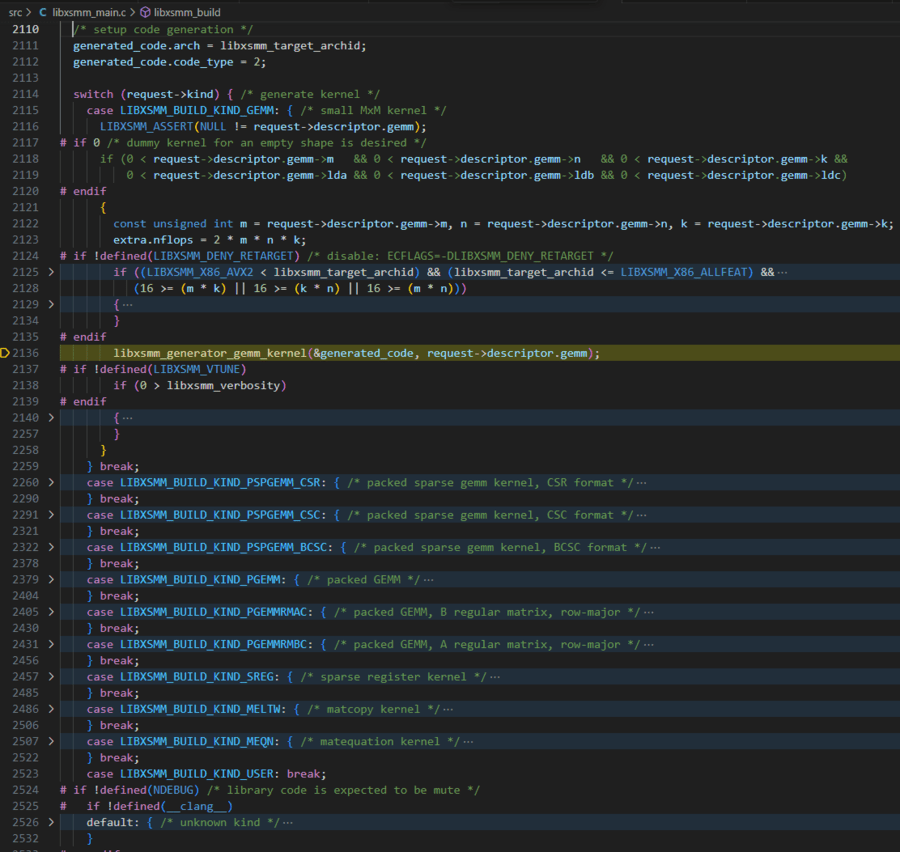
libxsmm_generator_gemm_kernel函数中,根据CPU架构,执行不同的操作。最终调用libxsmm_generator_gemm_aarch64_kernel,libxsmm_generator_gemm_noarch_kernel,libxsmm_generator_gemm_amx_kernel_wrapper或libxsmm_generator_gemm_sse_avx_avx2_avx512_kernel_wrapper进一步实际生成代码
generator_driver
在src目录下有个libxsmm_generator_gemm_driver.c,其中有个main函数,会接受一系列参数,包括gemm参数和体系架构参数。根据输入的参数生成相应的汇编kernel代码输出到文件中
用例
./libxsmm_gemm_generator dense wsm_3x3.asm kernel_3x3 3 3 3 3 3 3 1 0 1 1 wsm nopf DP
改命令生成X86_SSE42架构下3x3x3规模的gemm kernel。
void kernel_3x3(const double* A, const double* B, double* C) {
#ifdef __SSE4_2__
#ifdef __AVX__
#pragma message ("LIBXSMM KERNEL COMPILATION WARNING: compiling SSE42 code on AVX or newer architecture: " __FILE__)
#endif
__asm__ __volatile__("movq %0, %%rdi\n\t"
"movq %1, %%rsi\n\t"
"movq %2, %%rdx\n\t"
"pushq %%rbp\n\t"
"movq %%rsp, %%rbp\n\t"
"subq $168, %%rsp\n\t"
"movq $18446744073709551552, %%r10\n\t"
"andq %%r10, %%rsp\n\t"
"movq $0, %%r11\n\t"
"33:\n\t"
"addq $3, %%r11\n\t"
"movq $0, %%r10\n\t"
"34:\n\t"
"addq $3, %%r10\n\t"
"xorpd %%xmm10, %%xmm10\n\t"
"xorpd %%xmm11, %%xmm11\n\t"
"xorpd %%xmm12, %%xmm12\n\t"
"xorpd %%xmm13, %%xmm13\n\t"
"xorpd %%xmm14, %%xmm14\n\t"
"xorpd %%xmm15, %%xmm15\n\t"
"movddup 0(%%rsi), %%xmm0\n\t"
"movddup 24(%%rsi), %%xmm1\n\t"
"movddup 48(%%rsi), %%xmm2\n\t"
"movupd 0(%%rdi), %%xmm3\n\t"
"mulpd %%xmm0, %%xmm3\n\t"
"addpd %%xmm3, %%xmm10\n\t"
"movupd 0(%%rdi), %%xmm3\n\t"
"mulpd %%xmm1, %%xmm3\n\t"
"addpd %%xmm3, %%xmm12\n\t"
"movupd 0(%%rdi), %%xmm3\n\t"
"mulpd %%xmm2, %%xmm3\n\t"
"addpd %%xmm3, %%xmm14\n\t"
"movsd 16(%%rdi), %%xmm3\n\t"
"mulpd %%xmm3, %%xmm0\n\t"
"addpd %%xmm0, %%xmm11\n\t"
"mulpd %%xmm3, %%xmm1\n\t"
"addpd %%xmm1, %%xmm13\n\t"
"mulpd %%xmm3, %%xmm2\n\t"
"addpd %%xmm2, %%xmm15\n\t"
"addq $24, %%rdi\n\t"
"movddup 8(%%rsi), %%xmm0\n\t"
"movddup 32(%%rsi), %%xmm1\n\t"
"movddup 56(%%rsi), %%xmm2\n\t"
"movupd 0(%%rdi), %%xmm3\n\t"
"mulpd %%xmm0, %%xmm3\n\t"
"addpd %%xmm3, %%xmm10\n\t"
"movupd 0(%%rdi), %%xmm3\n\t"
"mulpd %%xmm1, %%xmm3\n\t"
"addpd %%xmm3, %%xmm12\n\t"
"movupd 0(%%rdi), %%xmm3\n\t"
"mulpd %%xmm2, %%xmm3\n\t"
"addpd %%xmm3, %%xmm14\n\t"
"movsd 16(%%rdi), %%xmm3\n\t"
"mulpd %%xmm3, %%xmm0\n\t"
"addpd %%xmm0, %%xmm11\n\t"
"mulpd %%xmm3, %%xmm1\n\t"
"addpd %%xmm1, %%xmm13\n\t"
"mulpd %%xmm3, %%xmm2\n\t"
"addpd %%xmm2, %%xmm15\n\t"
"addq $24, %%rdi\n\t"
"movddup 16(%%rsi), %%xmm0\n\t"
"movddup 40(%%rsi), %%xmm1\n\t"
"movddup 64(%%rsi), %%xmm2\n\t"
"movupd 0(%%rdi), %%xmm3\n\t"
"mulpd %%xmm0, %%xmm3\n\t"
"addpd %%xmm3, %%xmm10\n\t"
"movupd 0(%%rdi), %%xmm3\n\t"
"mulpd %%xmm1, %%xmm3\n\t"
"addpd %%xmm3, %%xmm12\n\t"
"movupd 0(%%rdi), %%xmm3\n\t"
"mulpd %%xmm2, %%xmm3\n\t"
"addpd %%xmm3, %%xmm14\n\t"
"movsd 16(%%rdi), %%xmm3\n\t"
"mulpd %%xmm3, %%xmm0\n\t"
"addpd %%xmm0, %%xmm11\n\t"
"mulpd %%xmm3, %%xmm1\n\t"
"addpd %%xmm1, %%xmm13\n\t"
"mulpd %%xmm3, %%xmm2\n\t"
"addpd %%xmm2, %%xmm15\n\t"
"addq $24, %%rdi\n\t"
"movupd %%xmm10, 0(%%rdx)\n\t"
"movsd %%xmm11, 16(%%rdx)\n\t"
"movupd %%xmm12, 24(%%rdx)\n\t"
"movsd %%xmm13, 40(%%rdx)\n\t"
"movupd %%xmm14, 48(%%rdx)\n\t"
"movsd %%xmm15, 64(%%rdx)\n\t"
"addq $24, %%rdx\n\t"
"subq $48, %%rdi\n\t"
"cmpq $3, %%r10\n\t"
"jl 34b\n\t"
"addq $48, %%rdx\n\t"
"addq $72, %%rsi\n\t"
"subq $24, %%rdi\n\t"
"cmpq $3, %%r11\n\t"
"jl 33b\n\t"
"movq %%rbp, %%rsp\n\t"
"popq %%rbp\n\t"
: : "m"(A), "m"(B), "m"(C) : "rdi","rsi","rdx","r10","r11","r12","xmm0","xmm1","xmm2","xmm3","xmm4","xmm5","xmm6","xmm7","xmm8","xmm9","xmm10","xmm11","xmm12","xmm13","xmm14","xmm15");
#else
#pragma message ("LIBXSMM KERNEL COMPILATION ERROR in: " __FILE__)
#error No kernel was compiled, lacking support for current architecture?
#endif
#ifndef NDEBUG
#ifdef _OPENMP
#pragma omp atomic
#endif
libxsmm_num_total_flops += 54;
#endif
}代码实现
主要调用两个函数完成
l_xgemm_desc = libxsmm_gemm_descriptor_init(&l_xgemm_blob, LIBXSMM_DATATYPE_F64,
LIBXSMM_DATATYPE_F64, LIBXSMM_DATATYPE_F64, LIBXSMM_DATATYPE_F64,
l_m, l_n, l_k, l_lda, l_ldb, l_ldc, l_flags, l_prefetch);
libxsmm_generator_gemm_inlineasm( l_file_out, l_routine_name, l_xgemm_desc, l_arch );发现这个源文件中支持的arch参数少于libxsmm所支持的类型,此处只有少量X86架构,没有aarch和其他X86架构/* check value of arch flag */
if ( (strcmp(l_arch, "wsm") != 0) &&
(strcmp(l_arch, "snb") != 0) &&
(strcmp(l_arch, "hsw") != 0) &&
(strcmp(l_arch, "skx") != 0) &&
(strcmp(l_arch, "clx") != 0) &&
(strcmp(l_arch, "cpx") != 0) &&
(strcmp(l_arch, "noarch") != 0) ) {
print_help();
return EXIT_FAILURE;
}在include\libxsmm_cpuid.h和src\libxsmm_cpuid_x86.c中的libxsmm_cpuid_name函数里定义了所有的架构和对应代码,远多于这里的类型,估计是这个源码缺少维护,没有更新,考虑补充完善它,以实现所有架构的代码生成导出。
#define LIBXSMM_TARGET_ARCH_UNKNOWN 0
#define LIBXSMM_TARGET_ARCH_GENERIC 1
#define LIBXSMM_X86_GENERIC 1002
#define LIBXSMM_X86_SSE3 1003
#define LIBXSMM_X86_SSE42 1004
#define LIBXSMM_X86_AVX 1005
#define LIBXSMM_X86_AVX2 1006
#define LIBXSMM_X86_AVX2_ADL 1007
#define LIBXSMM_X86_AVX2_SRF 1008
#define LIBXSMM_X86_AVX512_VL128_SKX 1041
#define LIBXSMM_X86_AVX512_VL256_SKX 1051
#define LIBXSMM_X86_AVX512_VL256_CLX 1052
#define LIBXSMM_X86_AVX512_VL256_CPX 1053
#define LIBXSMM_X86_AVX512_SKX 1101
#define LIBXSMM_X86_AVX512_CLX 1102
#define LIBXSMM_X86_AVX512_CPX 1103
#define LIBXSMM_X86_AVX512_SPR 1104
#define LIBXSMM_X86_AVX512_GNR 1105
#define LIBXSMM_X86_ALLFEAT 1999
#define LIBXSMM_AARCH64_V81 2001 /* Baseline */
#define LIBXSMM_AARCH64_V82 2002 /* A64FX minus SVE */
#define LIBXSMM_AARCH64_APPL_M1 2101 /* Apple M1 */
#define LIBXSMM_AARCH64_SVE128 2201 /* SVE 128 */
#define LIBXSMM_AARCH64_NEOV2 2202 /* Neoverse V2, NVIDIA Grace, Graviton 4 */
#define LIBXSMM_AARCH64_SVE256 2301 /* SVE 256 */
#define LIBXSMM_AARCH64_NEOV1 2302 /* Neoverse V1, Graviton 3 */
#define LIBXSMM_AARCH64_SVE512 2401 /* SVE 512 */
#define LIBXSMM_AARCH64_A64FX 2402 /* A64FX */
#define LIBXSMM_AARCH64_ALLFEAT 29993. JITSPMM
简介
本文讨论了在多核CPU上加速稀疏矩阵乘法(SpMM)的问题,尤其是在应用程序如图形神经网络(GNNs)中输入数据量巨大的情况下。目前,大多数现有的SpMM计算解决方案采用预先编译(AOT)方法,即在执行程序之前完全编译程序。但是,AOT编译SpMM面临三个关键限制:
1. 非必要访存。由于C/C++编译器依赖于基于启发式规则的寄存器分配方案,这些方案无法获得SpMM计算的内存访问模式特征(运行时),从而导致对内存的不必要访问。
2. 额外的分支开销。AOT方法的一个固有限制是它无法利用运行时信息,因此需要引入额外的分支指令来处理不同的输入数据。
3. 冗余指令。由于不必要的内存访问(如寄存器溢出和内存加载)和分支控制操作(如比较和条件跳转),引入了冗余汇编指令,导致执行的指令过多。
JITSPMM,一种实时(JIT)汇编代码生成框架来克服以上AOT的限制:
1. JITSPMM分配寄存器来缓存频繁访问的数据,以最大限度地减少内存访问,并使用特定的SIMD指令来提高算术吞吐量
2. JITSPMM结合运行时信息,提出coarse-grain column merging方法,通过展开性能关键循环(可以减少分支指令)来最大限度地提高指令级并行性。
3. JITSPMM还将JIT汇编代码生成技术集成到三种广泛使用的SpMM工作负载划分方法中,做了一些CPU线程之间的负载均衡的工作。