


高性能计算之MPI——集合通信漫谈
发表于 2025/09/22
0
去年8、9月份,我写了一篇关于MPI的介绍文章《高性能计算之MPI--10分钟超越99%的程序员》。
该文章收到较多反馈与催更,因此抽空更新MPI系列第二篇帖子。
P2P的暴雷:集合通信
在上一期MPI介绍的时候,提到了Send(发送)和Recv(接收)。Send/Recv有个专门的名字:P2P。这里的P2P可不是前些年在金融界暴雷的P2P借贷,虽然它们来源于同一个英文单词:Peer-To-Peer。
Peer-To-Peer,翻译成中文就是"点对点"。
这很容易理解,因为Send和Recv本身就是从一个进程把数据发送给另外一个进程,即从一个点到另外一个点。
上一期中我们假设了这样一个场景:进程0如果要把数据发送给其他三个进程:进程1、进程2和进程3。
这种情况就不单单是一个进程和另外一个进程之间的互操作了,而是一系列进程之间的互操作。
这种有别于P2P的、涉及到多个进程之间的通信叫做:集合通信(Collective Communication).
集合通信:先从广播开始
对于上述情况,如果使用P2P的Send/Recv来表达,大概长下面这个样子。/* File Name: mpi_naive_bast.c
the MPI bast example (naive vesion) */
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
int main(int argc, char **argv) {
MPI_Init(NULL, NULL);
/* tag */
int tag = 10086;
int count = 1;
MPI_Status status;
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) {
int *sendbuff = (int *)malloc(sizeof(int) * count);
sendbuff[0] = 100;
/* rank0 -> rank 1/2/3: sendbuff */
for (int recvrank = 1; recvrank < 4; recvrank++) {
MPI_Send(sendbuff, count, MPI_INT, recvrank, tag, MPI_COMM_WORLD);
}
}
if (rank != 0) {
int *recvbuff = (int *)malloc(sizeof(int) * count);
/* rank 1/2/3 receive buffer from rank 0 */
MPI_Recv(recvbuff, 1, MPI_INT, 0, tag, MPI_COMM_WORLD, &status);
printf("I'm rank #%d, recvbuf[0] = %d \n", rank, recvbuff[0]);
}
MPI_Finalize();
return 0;
}
最终打印的结果是:I'm rank #1, recvbuf[0] = 100I'm rank #3, recvbuf[0] = 100I'm rank #2, recvbuf[0] = 100
虽然达到了最终的目的,但这种naive的写法简直是老太婆的裹脚布——又臭又长。
事实上,MPI标准中提供了一个非常完美的集合通信接口来表示上述的操作,这个操作叫做Broadcast(广播)int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)
这些入参中buffer、count、datatype、comm的概念我们前面都提及过,重点说说这里的root的含义。
上述例子中,是进程0发给了所有进程,所以root=0. 如果是进程1发给其他进程,则root=1. 以此类推。
所以,Bcast中的root进程就是发起广播通信的进程。
话不多说,直接上代码吧。
/* File Name: mpi_bcast.c
the MPI Bcast example */
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
int main(int argc, char **argv) {
MPI_Init(NULL, NULL);
int count = 1;
MPI_Status status;
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int *buf = (int *)malloc(sizeof(int) * count);
if (rank == 0) {
buf[0] = 100;
}
/* Before Broadcast, only rank 0 has buffer value: 100 */
printf("I'm rank #%d, Before Bcast: buffer value: %d\n", rank, buf[0]);
MPI_Bcast(buf, count, MPI_INT, 0, MPI_COMM_WORLD);
/* After Broadcast, all ranks has buffer value: 100 */
printf("I'm rank #%d, After Bcast: buffer value: %d\n", rank, buf[0]);
MPI_Finalize();
return 0;
}
打印结果如下:I'm rank #2, Before Bcast: buffer value: 439634824I'm rank #3, Before Bcast: buffer value: 1004776328I'm rank #0, Before Bcast: buffer value: 100I'm rank #1, Before Bcast: buffer value: 752221064
I'm rank #0, After Bcast: buffer value: 100I'm rank #2, After Bcast: buffer value: 100I'm rank #1, After Bcast: buffer value: 100I'm rank #3, After Bcast: buffer value: 100
可以看到:在调用Bcast之前,除了进程0之外,其他进程都是随机数。
经过Bcast之后,所有数字统一变成了100.
使用MPI_Bcast语义最显著的好处是:代码行数由原来的34行缩短到了24行,代码行数降低了29.4%,意味着开发效率直接提升29.4%。
不好意思,看到数字就想算个百分数,职业病犯了属于是。
显然,集合通信接口的诞生不仅是为了提升代码简洁度,而是为了提升代码效率。
或者更确切地说法是:将把优化工作由MPI的使用者抛给了计算机科学家。
至于为啥要这么做,我在本文的最后一章里会重点说明。
先回到代码效率提升这个问题,其实只要稍加分析,就明白:用Send/Recv描述出来的Bcast是个相当低效。
因为进程0在发送给进程1、2、3的同时,啥也没做。
为了更好地量化这个过程,假设一次发和收的时间为t
在上面过程中,我们完成了:Step 1: rank 0 -> rank 1Step 2: rank 0 -> rank 2Step 3: rank 0 -> rank 3
三次的发包和收包的过程,所以耗时一共是3t
既然大家发送和接受的信息是一样的,那么在进程1接受到进程0发的信息时,能不能用作发包呢?
听上去这个主意不错,上面这个过程就改造成了:Step 1: rank 0 -> rank 1Step 2: rank 0 -> rank 2Step 3: rank 1 -> rank 3
虽说还是三步走,但刚才那个已经是"老三步", 现在我们要走的是"新三步".
"新三步"和"老三步"最大的不同是:
Step2 和 Step3是可以并行执行的!
也就是说,rank 0->rank 2, rank 1->rank 3是可以同时进行的。
这样一来:Bcast总的耗时由原来3t的变成了2t
时间缩短1/3,性能提升1/3啊。
不好意思,看到数字就想算个百分数的职业又犯了。
其实,无论是上述的"老三步"还是"新三步",都是MPI_Bcast的算法。
"老三步"的术语名称叫做:Flat-Tree,翻译成中文:平坦的树。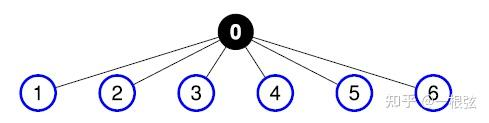
Flat Tree算法示意图,图片来源参考文献[1].
刚才的例子中只有4个进程,有很多Tree算法都可以实现上面说的"新三步"的逻辑,比如:Binary Tree、K-Chain Tree等等。具体参考文献[1].
文字太麻烦,不如直接上图:
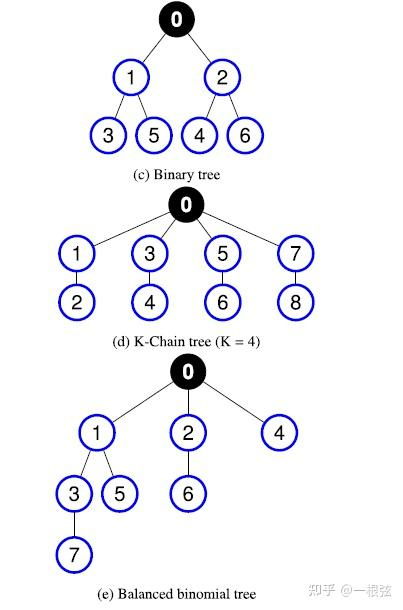
不同Tree算法示意图,图片来源参考文献[1].
性能分析与测试基准
前面一章,提到了Bcast和实现Bcast的不同算法。这里面天然地引入两个问题:
1、如何评估一个Bcast算法的好坏?
2、如何实测一个Bcast算法的好坏?
对于第一个问题,评价通信的具体模型很多,这里不做展开。
评价通信时间开销,最核心的是这样一个公式。
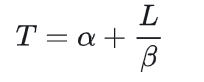
其中,T表示通信总时间,α表示通信时延(Latency),L表示通信量,β表示带宽(Bandwidth)。
这个公式是评价通信时间开销/通信复杂度最重要的公式,其地位与算法复杂度分析的大O模型相当。
这个公式表明,当通信量不大时(即L比较小时),时延是影响通信总耗时的关键因素;当通信量很大时(即L比较大时),带宽是影响通信总耗时的关键因素。
对于第二个问题,业界有很多测评MPI性能的Benchmark和测试集(Test Suite),参考文献[2].
使用最多的是OSU Benchmark,官网参考:https://mvapich.cse.ohio-state.edu/benchmarks/
冷知识:OSU是Ohio State University(俄亥俄州立大学)的简称。这是因为OSU benchmark是一位来自俄亥俄州立大学的教授Dhabaleswar Panda(熊猫教授)提出的。
使用次多的是IMB,是Intel MPI Benchmark的简称:https://www.intel.com/content/www/us/en/developer/articles/technical/intel-mpi-benchmarks.html
从名字上不难发现,这是Intel公司提出的一套测试集。
集合通信の分类
除了Bcast外,还有那些集合通信语义呢?有很多,比如Scatter、Gather、Allgather
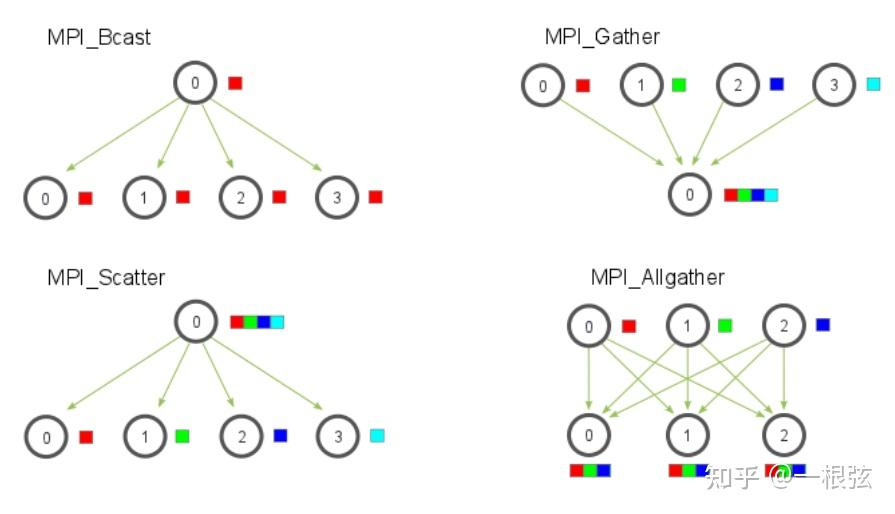
从上图中可以看出:
Scatter的含义是:进程0原来有一段数据,要把数据Scatter到其他进程。
Gather的含义则恰好相反——所有的进程把数据汇总到进程0中。
所以Gather和Scatter是互为逆操作。
观察一下,MPI_Allgather的操作可以看做是:Gather+Bcast. 即: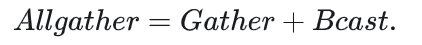
再比如,Reduce和Allreduce.
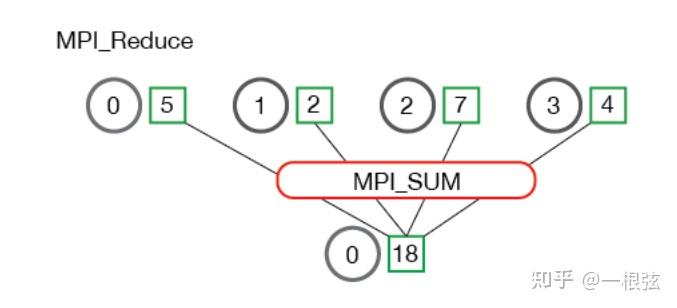
Reduce(规约)操作:就是把所有进程的求和(SUM)、乘积(Prod)、最大值(Max)或最小值(Min)从各个进程求解出来,最终结果放在进程0.
上图例子,进程0/1/2/3在Reduce前分别拥有的数字是5、2、7、4,在进过Reduce操作后,这四个数字的之和18就会放在进程0中。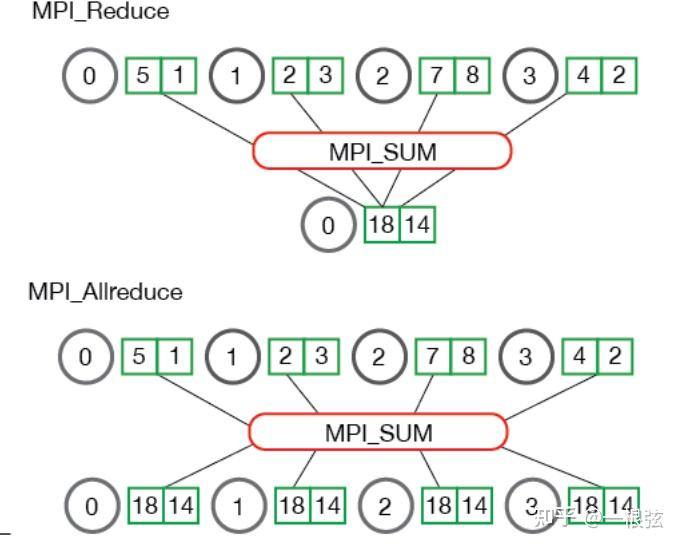
可以看到,Allreduce相比Reduce规约操作,不同点在于:Reduce的结果只会放在进程0中,而allreduce的结果则会放在所有进程中。也就是说: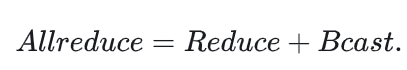
这些集合通信可以大概分为三类:
· One-To-Many(一对多)
· Many-To-One(多对一)
· Many-To-Many(多对多)
其实分类的名字还挺形象的:如果集合通信前,原数据掌握在一个进程,集合通信结束后,需要的数据被所有进程都有,那就是One-To-Many。比如本篇重点介绍的Bcast,又比如刚才提到的Scatter和Reduce.
相反地,如果在集合通信前,数据在多个进程中; 而在集合通信结束后,需要的数据被唯一一个进程所拥有,那就是Many-To-One. 比如刚才介绍的Gather操作。
如果集合通信前后,数据都在所有进程中,那就是Many-To-Many,比如Allreduce、Allgather和Alltoall.
这里有个规律:凡是API接口属于"All字辈",基本都是Many-To-Many类型。
一名HPC从业者的碎碎念
观前提示:如果你看这篇文章的目的只是单纯地想学习和了解MPI,那么这一章就可以跳过了。如果你想听一个在HPC领域摸爬滚打了几年的人碎碎念,顺带给你讲讲私货,那么欢迎来到本章节。
前面章节在提到MPI集合通信接口的诞生原因时,我说了这么一句话:MPI集合通信接口的诞生本质上是把优化工作由MPI的使用者抛给了计算机科学家。
这句话背后的逻辑是:使用MPI的人和优化MPI的人是两拨人。
真可谓“遍身罗绮者,不是养蚕人”。
前面的文章中我提到过,HPC这个领域最重要的是上层各式各样的应用。
这些应用通常是为了解决某一个或某一类科学问题,比如气象(天气预报)、物理学(高能物理、核物理)、医疗制药(分子结构模拟)、机械制造(计算流体力学)等等。
HPC应用通常都是谁写的呢?显然,都是一些科学家,或者科研工作者。
如果按照专业划分的话,这些人来自于大气科学系、物理系、化学系、机械系等等,可谓"百花齐放、百家争鸣"。
MPI(进程级并行)是这些HPC应用最常见的并行策略和并行方式;这些五花八门的人就是MPI的最大用户群体。
HPC程序开发完成后,对一个有追求的开发者而言。
他的第一个问题是:如何能让我的程序跑得快一点?
程序的性能优化是HPC应用开发者们不太擅长的,还是得学计算机的人来。
计算机专家做优化,往往需要理解应用里面的逻辑,可应用的逻辑往往不太好懂。
这里举个例子:计算物理学中有个重要的分支:计算电磁学(Computational Electromagnetics).
计算电磁学的核心是求解麦克斯韦方程组。
这个方程长这样:
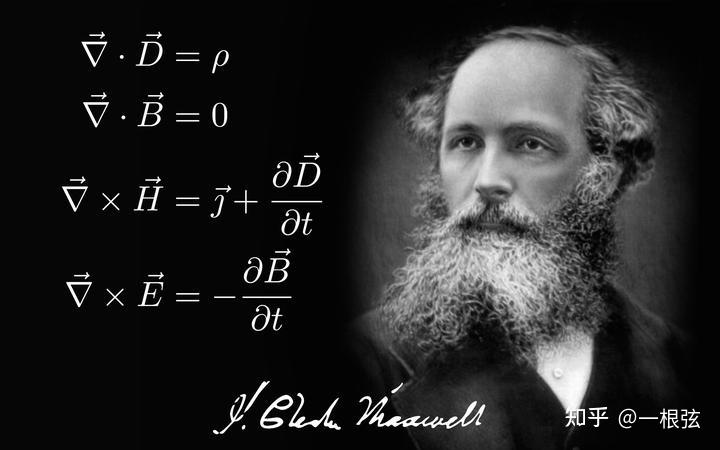
咱们就先不说能不能理解方程的实质,单单要想弄懂上面那个倒着写的三角符的含义,最起码得学过微积分+矢量代数。
这还不算完。这些微分方程要变成可求解的方式需要一系列的算法。
在计算电磁领域,常用算法包括但限于:有限差分法、有限元方法、矩量法、快速多极子方法。
把这些算法理解完成后,才能把程序的架构设计出来,才具备写程序的现决条件。
我有位从事HPC应用优化且计算机科班出身的同事告诉我:他们去HPC相关的学术会议听报告,最怕听到应用的人讲报告,全是满屏的公式,连符号都看不懂。每次到了这些环节,都昏昏欲睡。

说了半天,我想表达的核心观点是:对从事性能优化的计算机专家来说,HPC应用的算法逻辑太复杂了。
这句话并非贬低学计算机的人。其实即使对同是物理专业的人,做计算电磁的和做流体力学仿真的两个子领域的人都不能相互理解。
这都不是“隔行如隔山”,这属于“隔小行如隔山,隔行如隔大山”。
说回MPI,MPI集合通信接口的设计把MPI的使用者(HPC应用开发者)和MPI优化者(计算机科学家)划了一条清晰的分割线:对HPC应用开发者来说,他们可以轻松地使用这些接口,把这些优化工作交给更专业的计算机专家来做。
MPI是个把两拨人分开的很好的例子,但悲剧的是:在高性能计算领域,这样的例子并不算多。
在本系列的第一篇文章中,我就表达过一个观点:HPC这个领域,容易学起来上瘾。
HPC这个领域还是太复杂了,需要懂的东西太多了。
知识一多,就容易学杂。
学杂了,一不小心把书架上的《母猪的产后护理》给抽出来了。


不抖机灵,送给大家一句话:学无止境。

与诸君共勉。
感谢阅读。这个专栏有没有下一期,就看各位的点赞、收藏和关注了。
你还想知道点儿啥,评论区告诉我。
(本文原载于知乎,知乎作者也是本人,原文链接:https://zhuanlan.zhihu.com/p/1899504956299534916)
参考文献
[1]. EminNuriyev et al, Model-based selection of optimal MPI broadcast algorithms for multi-core clusters, Journal of Parallel and Distributed Computing. 2022.
[2]. Sascha Hunold and Alexandra Carpen-Amarie, MPI Benchmarking Revisited: Experimental Design and Reproducibility. https://arxiv.org/pdf/1505.07734
[3]. Jan Thorbecke, Programming with MPI Collectives, https://janth.home.xs4all.nl/MPIcourse/PDF/05_MPI_Collectives.pdf
[4]. MPI Tutorial: MPI Bcast and Collective Communication: https://mpitutorial.com/tutorials/mpi-broadcast-and-collective-communication/