


金融行业容器云服务典型软件调优实践
发表于 2025/09/23
0
作者 | 张锦鹏
1 实践背景介绍
场景概述
某金融行业典型容器云服务使用鲲鹏服务器,操作系统基于openEuler 6.6构建。在入网之前,计划使用5款测试软件,通过软件默认的测试模型,从软件层面对OS、CPU等系统组件进行性能测试。
测试环境
测试中使用鲲鹏服务器,详细信息如表1-1所示。
表1-1 测试硬件环境信息
|
项目 |
鲲鹏服务器 |
|---|---|
|
服务器型号 |
鲲鹏服务器(CPU型号为鲲鹏920 7270Z处理器) |
|
CPU核数 |
256 |
|
CPU频率 |
2.9GHz |
|
内存 |
2T(64G*32) speed:5600 MT/s |
测试选取5款基础软件进行性能横向对比测试,软件列表如表1-2所示。
表1-2 测试软件信息
|
软件名 |
简介 |
测试场景 |
客户是否关注 |
|---|---|---|---|
|
Nginx |
一款高性能的HTTP和反向代理服务器,支持IMAP/POP3/SMTP等代理。 |
长连接场景、短连接场景 |
关注 |
|
Redis |
一款高性能内存数据库,支持多种数据结构如字符串、哈希、列表等。用途包括高速缓存、消息队列、分布式锁,还有持久化和高可用性功能,例如主从复制和哨兵模式。 |
ping、set、get |
关注 |
|
Etcd |
一个分布式的、高可用的键值存储数据库,主要用于共享配置和服务发现。 |
事务、侦听机制等 |
关注 |
|
Sysbench |
一款开源的模块化工具,主要用于评估系统硬件(如 CPU、内存、磁盘 I/O)及数据库(如 MySQL、PostgreSQL)的性能表现,支持跨平台和多线程测试。 |
CPU、内存、锁 |
关注,部分测试用例不关注 |
|
Vdbench |
用于验证存储系统的数据完整性,并测量块设备(如磁盘)和文件系统的性能指标(如 IOPS、吞吐量、时延)。 |
磁盘 |
不关注 |
测试组网
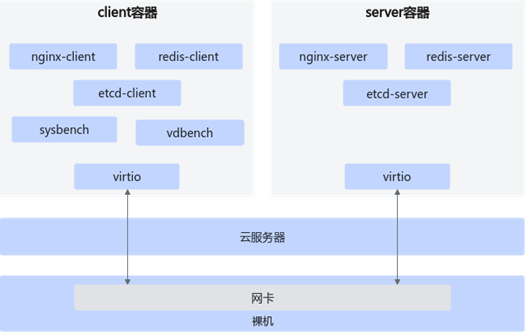
测试组网图如图1-1所示,裸机上携带网卡,云服务器卸载到网卡上(即除云盘外,容器可以直接看到CPU,numa拓扑等信息)。
- server容器绑定CPU的8核心(鲲鹏:0~7核心),共8核16G。
- client容器绑定CPU的8核心(鲲鹏:8~15核心),共8核16G。
- 网络卡直通到容器。
图1-1 测试组网图
测试工具如表1-3所示。
表1-3 测试工具
|
软件名称 |
7U版本 |
8U版本 |
压测工具 |
压测脚本 |
|---|---|---|---|---|
|
Nginx |
1.20.1 |
1.20.1 |
wrk |
nginx1.sh nginx2.sh |
|
Redis |
5.0.0 |
6.2.17 |
redis-benchmark |
redis_test.sh |
|
Etcd |
3.3.25 |
3.3.25 |
benchmark |
etcd_test.sh |
2 性能调优实践
2.1 硬件调优
BIOS配置
对于不同的硬件设备,通过在BIOS中设置一些高级选项,可以有效提升服务器性能。重启服务器后,进入BIOS设置界面,并设置如表2-1所示的选项。
如何进入BIOS界面的具体操作请参见《TaiShan 服务器 BIOS 参数参考(鲲鹏920处理器)》中“进入BIOS界面”的相关内容。
表2-1 配置BIOS
|
选项 |
设置值 |
设置方法 |
|---|---|---|
|
Max Payload Size,PCIe最大有效字节。 |
512B |
依次选择“Advanced > PCIe Config > CPU X PCIe - Port X”,将“Max Payload Size”设置为“512B”。 |
网卡队列对齐
鲲鹏服务器eth0队列数设置为64,server、client容器中eth0队列数设置为16。
设置方法:
ethtool -L eth0 combined [num:64 or 16]网卡中断绑核
鲲鹏服务器中网卡位置在numa1上、网卡中断被散列分布到各numa上,需要将容器移动到网卡所在的numa上(例如server 64~71,client 72~79),网卡中断绑定到容器中后4个核上(例如68~71;76~79)
设置方法:
1. 容器与物理网卡亲和:因容器为K8s管理,直接修改docker inspect无法生效,只能通过修改/sys/fs/cgroup/cpuset,cpus,.../podxxx/xxxx/cpuset.cpus将容器修改到网卡所在的numa上。
2. 容器中网卡中断亲和。通过A virtio网络中断绑核脚本将网卡中断调整到容器中的后4个核上。
3. 容器中的RPS/XPS绑核。
RPS(Receive Packet Steering)在接收端将网卡硬中断和相应的软中断分离在不同的CPU上处理,解决高硬中断率时两者相互影响带来的单CPU处理瓶颈。XPS(Transmit Packet Steering)和RPS类似,用于发送侧CPU分离。RPS和XPS主要用于网卡硬件队列数少,但CPU资源相对丰富的场景。绑核示例如下:
echo '00000000,00000000,00000000,00000000,00000000,00000040,00000000,00000000' > /sys/class/net/eth0/queues/tx-0/xps_cpus;echo '00000000,00000000,00000000,00000000,00000000,00000040,00000000,00000000' > /sys/class/net/eth0/queues/rx-0/rps_cpus网络模块对齐
通过lsmod | grep nf发现鲲鹏服务器有16个网络模块,删除不必要的多余网络模块保证一致性。
网卡参数优化
进入容器后,执行ethtool - K eth0 tx-nocache-copy on命令,开启网卡发送数据包时的 "无缓存复制" 功能,使得网卡直接从主内存读取数据,跳过CPU缓存的复制步骤,以便减少数据复制开销,降低传输延迟,提升整体吞吐量。
grub参数优化使能steal_task
1. 启动内核grub的cmdline,配置sched_steal_node_limit=4。
grubby --update-kernel=xxx --args="sched_steal_node_limit=4"2. 待OS启动后,配置echo STEAL > /sys/kernel/debug/sched_features。
通过给同一L3上空闲CPU分配更多时间片,主动去从其他忙碌CPU上获取task执行,以便充分发挥空闲CPU算力,提升系统性能。
2.2 操作系统调优
grub参数优化
1. 打开grub配置文件。
vim /etc/default/grub2. 按“i”进入编辑模式,找到GRUB_CMDLINE_LINUX=xx,在GRUB_CMDLINE_LINUX=中添加需要的grub启动参数,可以添加多个参数。
表2-2 grub启动参数
|
参数 |
说明 |
适用场景 |
|---|---|---|
|
audit=0 |
关闭Linux的audit,某些场景下会减少audit带来的性能损耗开销。 说明 Linux audit子系统是一个用于收集记录系统、内核、用户进程发生的行为事件的一种安全审计系统。该系统可以可靠地收集有关上任何与安全相关(或与安全无关)事件的信息,它可以帮助跟踪在系统上执行过的一些操作。 |
POC场景下建议均关闭。 |
|
pci=pcie_bus_perf |
优化PCIe设备的性能配置。 说明 该参数会根据PCIe设备的父总线,将设备的最大有效载荷大小(MPS,Max Payload Size)设置为允许的最大值,同时将最大读取请求大小(MRRS,Max Read Request Size)设置为支持的最大值(但不能大于设备或总线所支持的MPS值)。其目的是在网络和硬盘大吞吐量等场景下,通过增大MPS来提高PCIe设备的数据传输效率,从而提升系统整体性能。 |
对PCIe总线性能有较高需求的和场景。 |
3. 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
4. 重启操作系统,执行cat /proc/cmdline检查是否包含已配置的参数。
使能tcmalloc,降低内存函数热点消耗
1. 安装gperftools-libs。
yum install gperftools-libs2. 使能tcmalloc,降低内存函数热点消耗。
export LD_PRELOAD=/usr/lib64/libtcmalloc.so.4
export TCMALLOC_MEMFS_MAP_PRIVATE="true"
export TCMALLOC_MEMFS_MALLOC_PATH="/mnt/huge/tcmalloc/mnt/huge"使能sysctl参数
sysctl -w net.ipv4.tcp_rmem="4096 87380 16777216"
sysctl -w net.ipv4.tcp_wmem="4096 65536 16777216"
sysctl -w net.ipv4.tcp_tw_reuse=1 #这个可以单独测防止负优化
sysctl -w net.ipv4.tcp_fin_timeout=15
sysctl -w net.ipv4.tcp_fastopen=3
sysctl -w net.ipv4.tcp_syncookies=0
sysctl -w net.ipv4.tcp_max_syn_backlog=65536
sysctl -w net.ipv4.tcp_window_scaling=1
sysctl -w net.core.somaxconn=655352.3 编译优化
反馈编译优化pgo
减少Redis、Nginx、etcd的前端瓶颈,提高分支预测率,通过插桩后压测获取到bisheng-redis.profdata文件,编译指定CFLAGS="-fprofile-use=/path/to/bisheng-redis.profdata" LDFLAGS="-fprofile-use=/path/to/bisheng-redis.profdata"。
毕昇编译器优化Nginx、Redis、Sysbench
- Nginx:使用毕昇编译器重新编译Nginx,使能lto+静态编译,以便使用专有编译器优化Nginx指令分布,提升执行效率。参数说明如下:
− -flto链接时优化:链接阶段优化技术,扩大编译优化范围,进行全局跨文件优化。
− inline-threshold=2000:增大内联阈值,增加函数内联概率。
− tsv110:鲲鹏架构指定的流水线,根据鲲鹏指令集、pipeline,定制编译优化。
− Wno-error:抑制编译告警。
make distclean
CC=/path-to-compiler/BiShengCompiler-4.2.0-aarch64-linux/bin/clang CFLAGS="-mcpu=tsv110 -O3 -fuse-ld=lld -flto=full -mllvm -inline-threshold=2000 -Wl,-mllvm,-inline-threshold=2000 -Wno-error=unused-command-line-argument -Wno-error=implicit-function-declaration -Wno-error=int-conversion " LDFLAGS="-O3 -mcpu=tsv110 -flto=full -fuse-ld=lld -Wl,-mllvm,-inline-threshold=2000 " auto/configure --prefix=/nginx --without-http_rewrite_module --with-http_ssl_module
# 修改链接选项,修改objs/Makefile
LINK="/path-to-compiler/BiShengCompiler-4.2.0-aarch64-linux/bin/clang -O3 -mcpu=tsv110 -flto=full -fuse-ld=lld -Wl,-mllvm,-inline-threshold=2000"
# 开始编译,编译产物./objs/nginx
make -j
make -j install- Redis:通过毕昇编译器重新编译Redis进行鲲鹏亲和优化,释放硬件算力。
− -flto链接时优化:链接阶段优化技术,扩大编译优化范围,进行全局跨文件优化。
− inline-threshold=2000增大内联阈值,增加函数内联概率。
− tsv110:鲲鹏架构指定的流水线,根据鲲鹏指令集、pipeline,定制编译优化。
# 为了依赖库版本能够兼容,容器内编译命令,需填充毕昇编译器路径
下载mimalloc最新版本,编译输出静态库libmimalloc.a
mkdir build && cd build
cmake ../
make
将libmimalloc.a拷贝至redis-5.0.0目录
将jemalloc切换为mimalloc,redis-5.0.0/src/Makefile打上patch
--- src/Makefile_orig 2025-03-06 17:50:42.453262510 +0800
+++ 2025-03-06 17:51:36.653262510 +0800
@@ -125,6 +125,10 @@ ifeq ($(MALLOC),jemalloc)
FINAL_LIBS := ../deps/jemalloc/lib/libjemalloc.a $(FINAL_LIBS)
endif
+ifeq ($(MALLOC),libc)
+ FINAL_LIBS := ../libmimalloc.a $(FINAL_LIBS)
+endif
+
# 使用如下编译选项编译
make distclean
make MALLOC=libc CC=/path-to-compiler/BiShengCompiler-4.2.0-aarch64-linux/bin/clang CFLAGS="-mcpu=tsv110 -O3 -fuse-ld=lld -flto=full -mllvm -inline-threshold=2000 -Wl,-mllvm,-inline-threshold=2000 -Wno-error=unused-command-line-argument -Wno-error=implicit-function-declaration -Wno-error=int-conversion " LDFLAGS="-O3 -mcpu=tsv110 -flto=full -fuse-ld=lld -Wl,-mllvm,-inline-threshold=2000 " VERBOSE=1 -j
# 构建产物 src/redis-server- Sysbench:通过毕昇编译器重新编译Sysbench进行循环、控制流优化,释放鲲鹏最大算力。
− PIC针对循环的优化,它试图识别并移除循环中的冗余条件检查,以提高循环的执行效率。
− unroll-runtime是针对循环展开的优化,它通过复制循环体的一部分或全部来减少循环的开销,这有助于提高循环的迭代速度。
− allow-expensive-trip-count=true决定是否进行某些可能成本较高的优化时更加宽松。
# 增加-fPIC解决编译问题
# sysbench-1.0.20/third_party/luajit/luajit/src/Makefile
CCOPT= -O2 -fomit-frame-pointer -fPIC
# 为兼容依赖库版本,选择在容器内编译
make clean
./autogen.sh
./configure CC="/path-to-compiler/BiShengCompiler-4.2.0-aarch64-linux-POC/bin/clang -mllvm -enable-pnc-opt=true -mllvm -unroll-runtime=true -mllvm -allow-expensive-trip-count=true"
make -j
make install升级golang编译器,重新编译etcd
1. golang高版本合入了新特性,对ARM平台等进行优化,提升鲲鹏平台上的性能。建议下载golang编译器1.23版本,执行./build完成编译,将其从1.12版本升级到1.23版本。
2. 下载etcd-v3.3.25源码,执行./build完成编译。
etcd详细的编译安装操作请参见《ectd安装指南》。
2.4 应用软件调优
Redis使用多redis-benchmark压测
压测过程发现鲲鹏上Redis的CPU利用率低,使用两个redis-benchmark进程进行压测,增大压力,修改压测脚本为:timeohttps://www.hikunpeng.com/document/detail/zh/kunpengdbs/ecosystemEnable/Redis/kunpengredis_02_0004.htmlut 1800 redis-benchmark -h ${C_SERVER} -t ping,set,get -q -P 16 -d 1000 -n 10000000 -c 50 --csv >redis-result1.txt&
timeout 1800 redis-benchmark -h ${C_SERVER} -t ping,set,get -q -P 16 -d 1000 -n 10000000 -c 50 --csv >redis-result2.txt&Redis编译使能-finline-limit=10000,通过内联减少调用栈深度
通过火焰图发现鲲鹏的调用栈比较深,通过使能内联参数,鲲鹏性能提升19.6%。CFLAGS='-finline-limit=10000'
Redis详细的编译安装操作请参见《Redis移植指南》。
Redis编译使能memcpy使用sve向量库
使用sve向量库,在汇编指令层面加速memcpy,消除memcpy热点。CFLAGS='-Wl,--defsym,memcpy=__memcpy_aarch64_sve'
3 实践总结
- Nginx:通过对网络配置拉起、容器、CPU/NUMA绑定函数优化、RPS/XPS优化等方式,整体提升Nginx性能329.58%。
- Redis:通过对网络配置拉起、容器、CPU/NUMA绑定函数优化、inline、gettimeofday函数优化、tcmalloc等方式,整体提升Redis性能48.32%。
- Etcd:通过LSE禁用、btb优化等方式,鲲鹏所有可用调优手段均实施后,整体提升Etcd性能20+%。
- Sysbench:通过升级golang编译器、毕昇编译器重新编译sysbench、使能STEAL_TASK等优化方式,整体提升sysbench性能16.71%。
附录 virtio网络中断绑核脚本
check-vitrio-irq-cpu.sh
#!/bin/bash
# 功能:检查 virtio 设备的中断号及其绑定的 CPU 核(直接显示 smp_affinity_list)
# 依赖:需要 root 权限
# 主逻辑:生成中断号与 CPU 核的映射
echo "PCI地址 virtio编号 中断号 → smp_affinity_list"
echo "------------------------------------------------------"
for pci in $(lspci -D | grep -i virtio | awk '{print $1}'); do
# 获取 virtio 编号
virtio_num=$(ls /sys/bus/pci/devices/$pci/ 2>/dev/null | grep virtio | sed 's/virtio//')
[ -z "$virtio_num" ] && continue # 跳过无 virtio 编号的设备
# 获取中断号列表
irqs=($(grep "virtio${virtio_num}-" /proc/interrupts | awk '{print $1}' | sed 's/://'))
# 无中断则跳过
[ ${#irqs[@]} -eq 0 ] && continue
# 输出 PCI 地址和 virtio 编号
printf "%-16s %-12s" "$pci" "virtio${virtio_num}"
# 遍历每个中断号
for irq in "${irqs[@]}"; do
# 读取 smp_affinity_list 的值
if [ -f "/proc/irq/$irq/smp_affinity_list" ]; then
affinity_list=$(cat /proc/irq/$irq/smp_affinity_list 2>/dev/null | tr -d ' ')
else
affinity_list="N/A"
fi
# 输出中断号和亲和性列表
printf "%s→%s " "$irq" "$affinity_list"
done
echo "" # 换行
donebind_irqs_affinity_list.sh
#!/bin/bash
# 帮助信息
usage() {
echo "用法: $0 <CPU范围> <中断号列表>"
echo "示例: $0 '0-3,128-131' 42 43 44 45 46 47 48 49 50 51"
echo "功能:将中断号依次绑定到指定CPU核心(循环使用CPU列表),直接写入 smp_affinity_list"
exit 1
}
# 检查参数
if [[ $# -lt 2 ]]; then
usage
fi
# 解析CPU范围
parse_cpu_ranges() {
local ranges=$1
local cpus=()
IFS=',' read -ra parts <<< "$ranges"
for part in "${parts[@]}"; do
if [[ $part =~ - ]]; then
start=${part%-*}
end=${part#*-}
for ((cpu=start; cpu<=end; cpu++)); do
cpus+=($cpu)
done
else
cpus+=($part)
fi
done
echo "${cpus[@]}"
}
# 主逻辑
main() {
local cpu_ranges=$1
shift
local irqs=("$@")
local cpus=($(parse_cpu_ranges "$cpu_ranges"))
local total_cpus=${#cpus[@]}
local index=0
if [[ $total_cpus -eq 0 ]]; then
echo "错误:无效的CPU范围 '$cpu_ranges'"
exit 1
fi
# 绑定中断
for irq in "${irqs[@]}"; do
if [[ ! -d "/proc/irq/$irq" ]]; then
echo "警告:中断号 $irq 不存在,跳过"
continue
fi
# 获取当前CPU核心
local cpu=${cpus[index % total_cpus]}
# 写入 smp_affinity_list
echo "绑定中断 $irq → CPU $cpu"
echo "$cpu" > /proc/irq/$irq/smp_affinity_list 2>/dev/null
# 更新索引
((index++))
done
}
# 执行主函数
main "$1" "${@:2}"