


金融行业银行核心应用鲲鹏一码多芯、同辕开发实践
发表于 2025/09/23
0
作者 | 韩炯
1 实践背景介绍
场景概述
本实践针对金融行业银行业务应用,基于鲲鹏环境搭建CI/CD流水线,在门禁检查->编译构建->测试->发布的全流程中接入DevKit流水线门禁工具、毕昇JDK、系统调优、测试框架等工具等能力,提升代码质量和开发效率。结合鲲鹏软硬件开展全栈深度优化实践,通过DevKit性能分析工具识别性能瓶颈,提升业务应用性能。
以下为本次验证鲲鹏同辕开发的测试应用:
1. 信用卡核心系统
2. 中间业务云系统
以下为本次验证鲲鹏同辕开发测试步骤:
1. 开发流水线改造:流水线集成鲲鹏同辕开发工具
2. 压力测试与瓶颈监控:确定测试基线、监控压测时业务性能瓶颈
3. 应用性能调优:利用DevKit性能分析工具对CPU/内存、线程调度、热点函数等多维度进行分析,识别可优化的业务代码
4. 软硬协同调优:针对业务性能瓶颈利用鲲鹏硬件、openEuler操作系统、性能分析工具、毕昇JDK等协同调优
测试环境
本实践验证的环境信息和软件测试基线信息如表1-1、表1-2所示。
表1-1 硬件环境和虚拟机环境信息
|
项目 |
物理机配置信息 |
虚拟机配置信息 |
|---|---|---|
|
CPU型号 |
鲲鹏920 5220处理器(32核*2) |
鲲鹏920 8vCPU |
|
内存 |
1T |
32G |
|
硬盘 |
100GB * 8,500G*1 |
100GB * 2 |
|
网卡 |
10GE * 1 | |
|
操作系统 |
EulerOS 2.0 |
openEuler 20.03 LTS SP3 |
|
编译器 |
- |
Bisheng JDK 1.8.0_432 |
|
数据库 |
- |
GaussDB 5.0.0 |
表1-2 软件测试基线信息
|
软件名 |
并发数 |
压测时长 |
吞吐量(TPS/s) |
|---|---|---|---|
|
信用卡核心系统 |
60 |
10min |
161.63 |
|
中间业务云系统 |
30 |
5min |
1.7 |
测试组网
测试集群有2台物理机,2台物理机中各创建1个虚拟机用于部署信用卡核心系统及中间业务云系统,发压都从云桌面中的jmeter发起请求,组网如图1-1所示。
图1-1 测试组网示意
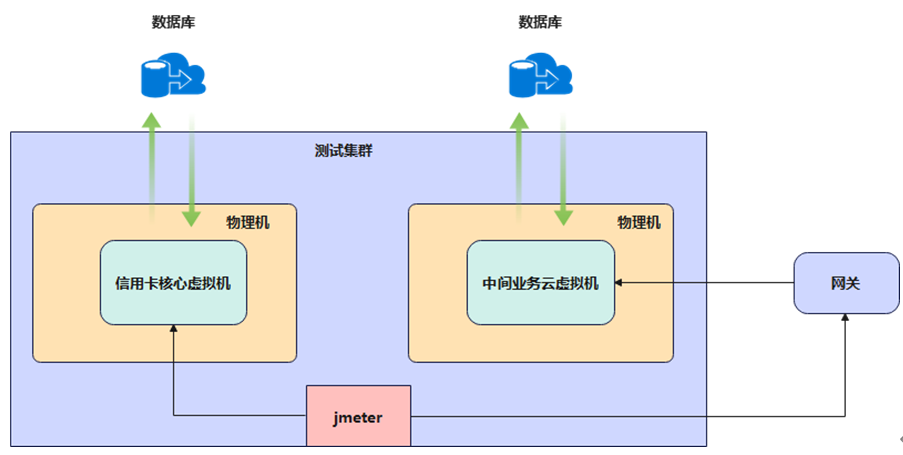
信用卡核心系统业务流:

中间业务云系统业务流:

2 性能瓶颈分析
2.1 信用卡核心系统业务性能瓶颈分析
信用卡核心系统性能瓶颈从CPU、内存、Java热点函数、GC、线程、网卡中断等多个维度进行分析,当前系统源码中存在大量线程等待以及网卡软中断集中问题对系统吞吐量影响较大,建议后续优化方向是对源码进行优化,也可尝试增加网卡队列。
根据性能测试过程数据分析,当前信用卡核心系统及中间业务云系统源码中均存在线程等待及死锁问题,导致CPU利用率下降,针对信用卡核心系统软件做如下分析并给出相应的优化方向。
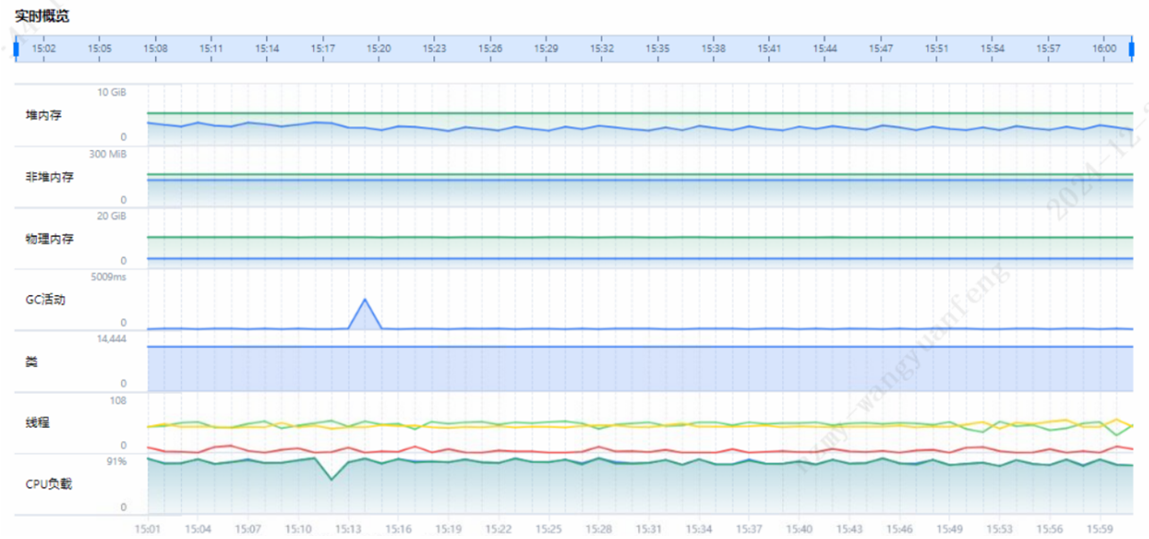
步骤 1 CPU及内存分析。
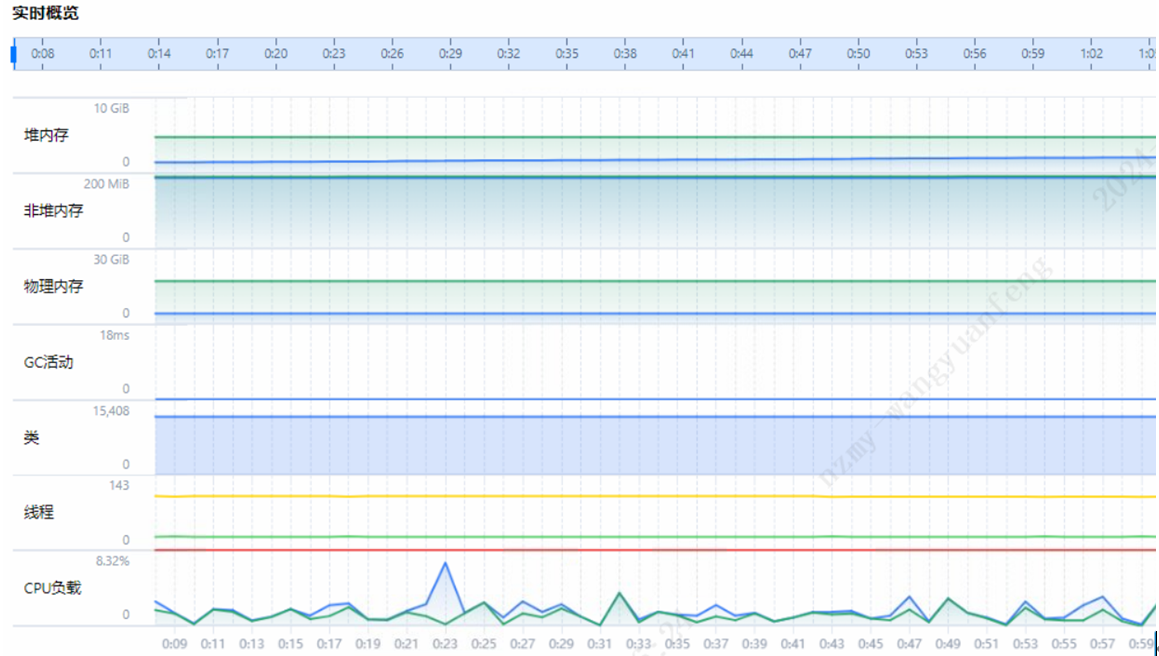
通过DevKit性能分析工具系统概览页面,可以看到当前信用卡核心系统所在虚拟机、CPU、内存均不存在性能瓶颈。
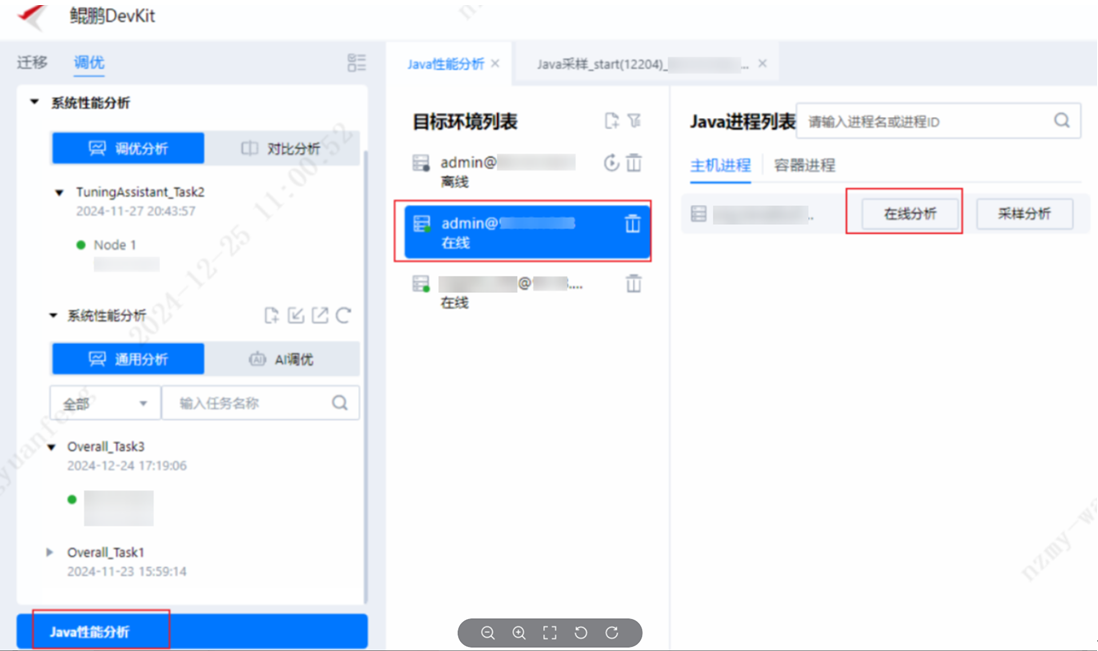
步骤2 Java热点函数分析。
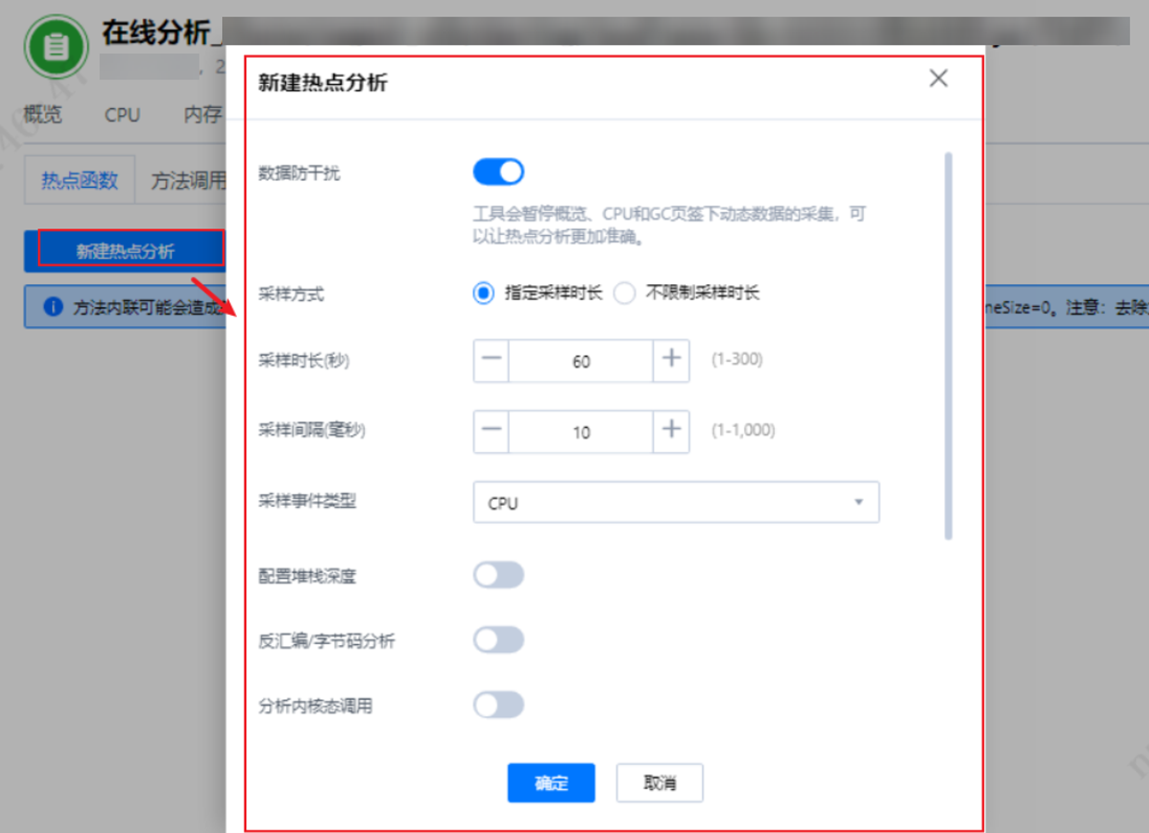
1. DevKit工具支持火焰图抓取,安装好DevKit性能分析工具登录到主界面后,选择“Java性能分析”,添加目标节点信息,选择“在线分析”。
2. 新建热点函数。
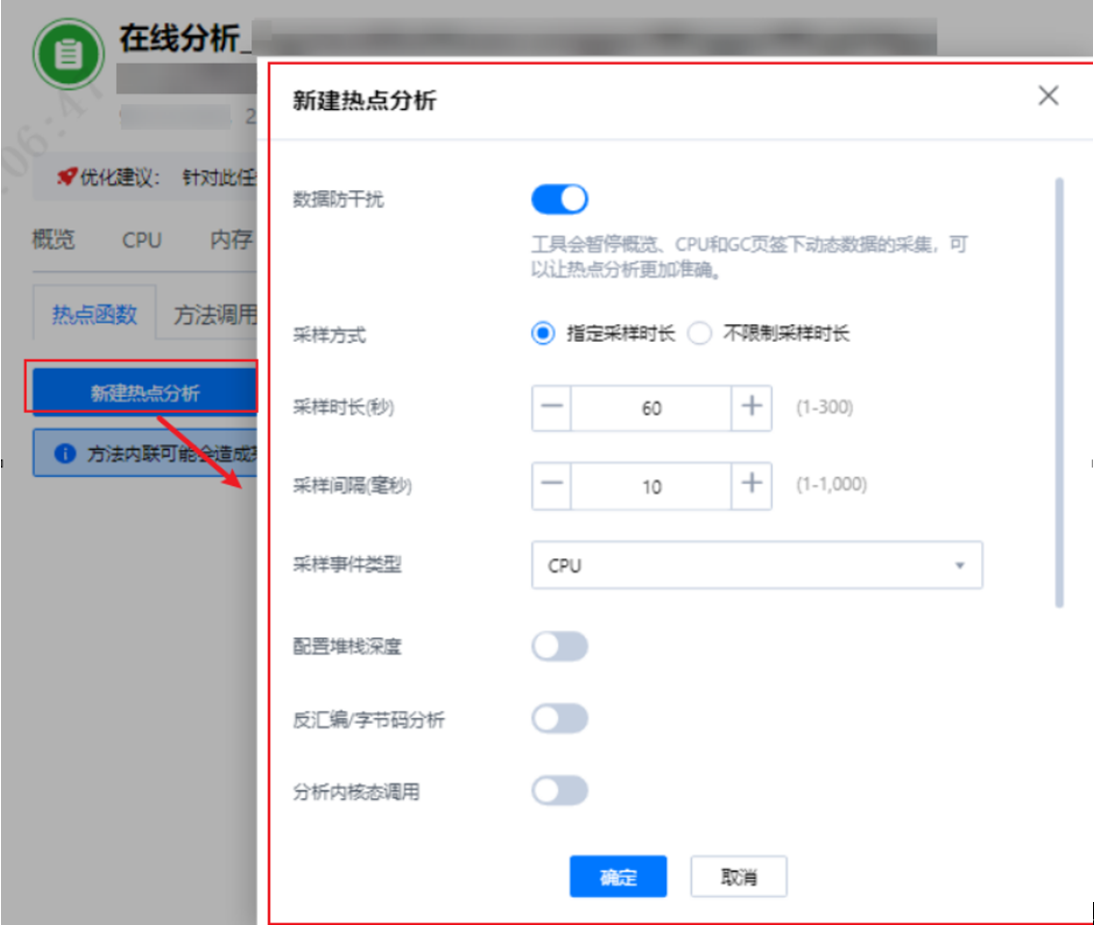
3. 等待采样完成后即可观察到如下火焰图。

从上图可以看到log4j在业务处理中占比较高达20%,结合火焰图信息进一步分析业务代码,考虑是否有优化空间。
步骤 3 GC分析。
DevKit工具支持火焰图抓取,安装好DevKit性能分析工具登录到主界面后,选择“Java性能分析”,添加目标节点信息,选择“在线分析”,选择GC即可看到GC分析结果及原因。
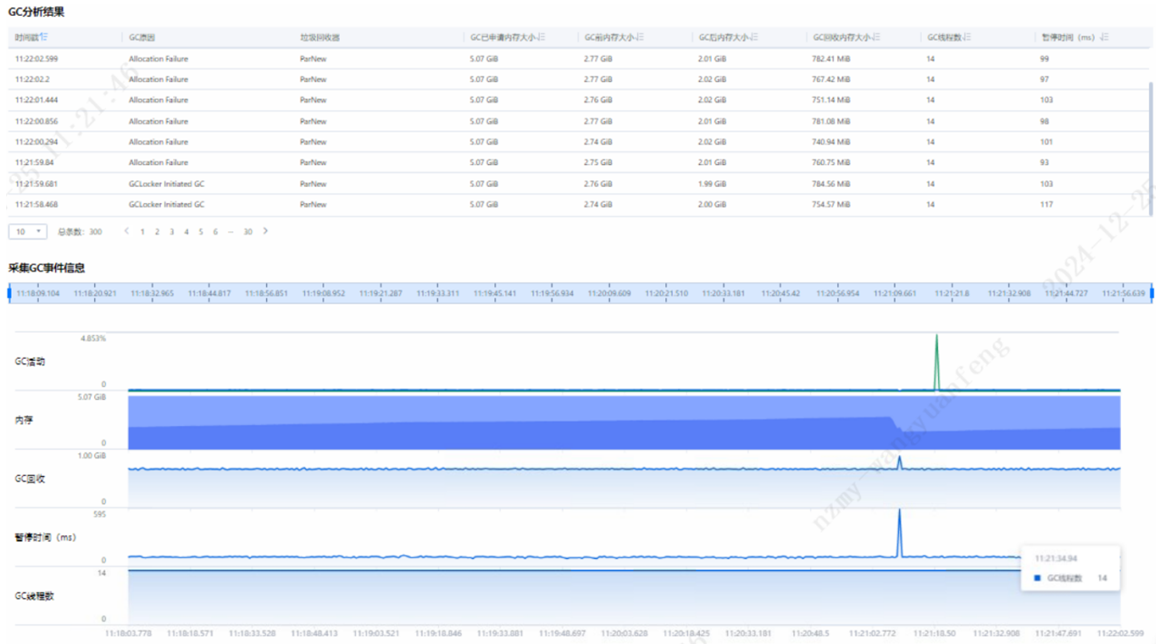
从上图看GC会出现大量Allocation Failure问题,但是GC并不频繁,故GC无需优化。
Allocation Failure由于连续内存分配不足导致,由于当前使用的垃圾回收器为CMS,CMS对内存碎片化处理较差,可以结合自身业务情况考虑是否替换为G1垃圾回收器,G1内存碎片处理能力相比CMS较强,但是此次测试场景中更换G1垃圾回收器对整体性能无明显提升。
步骤 4 线程等待及死锁分析。
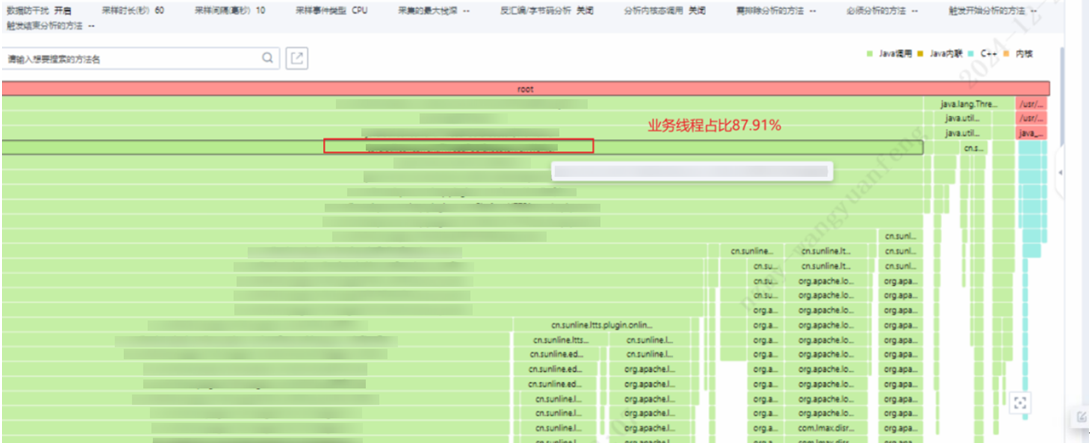
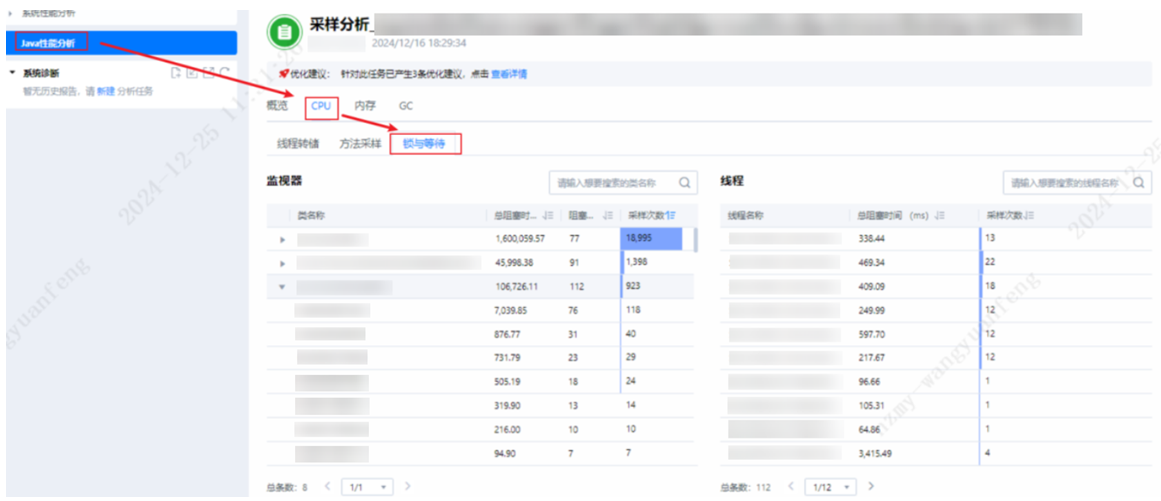
DevKit工具支持线程问题定位,安装好DevKit性能分析工具登录到主界面后,选择“Java性能分析”,添加目标节点信息,选择“在线分析”。再选择CPU中的“锁与等待”,可以从“监视器”中看到当前等待的线程有哪些。通过线程转储中的原始数据,重新导入分析,可以查看线程总览及详情。
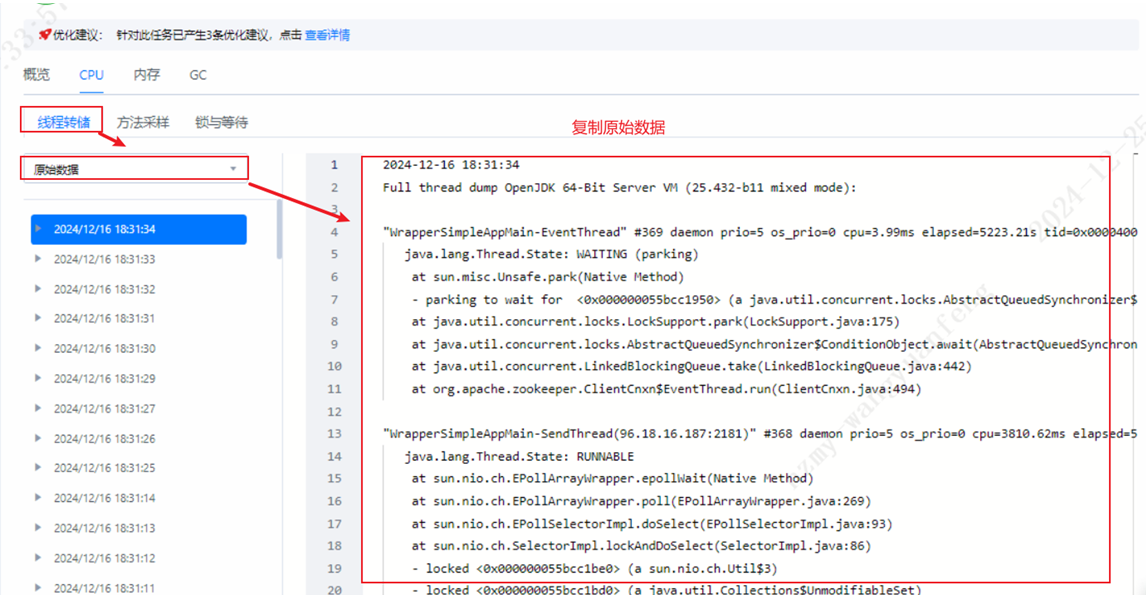
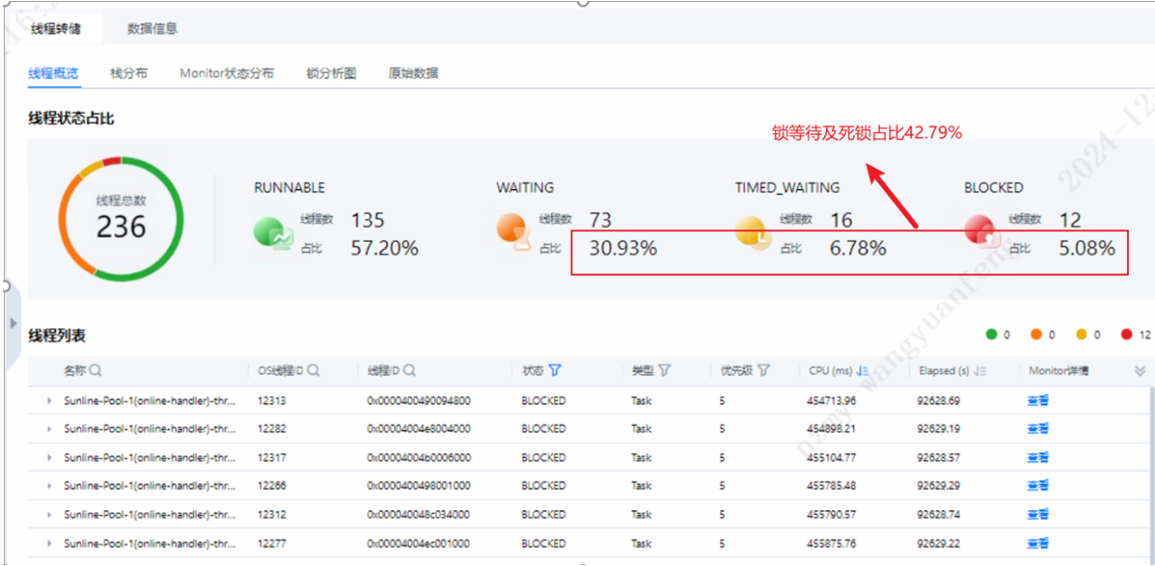
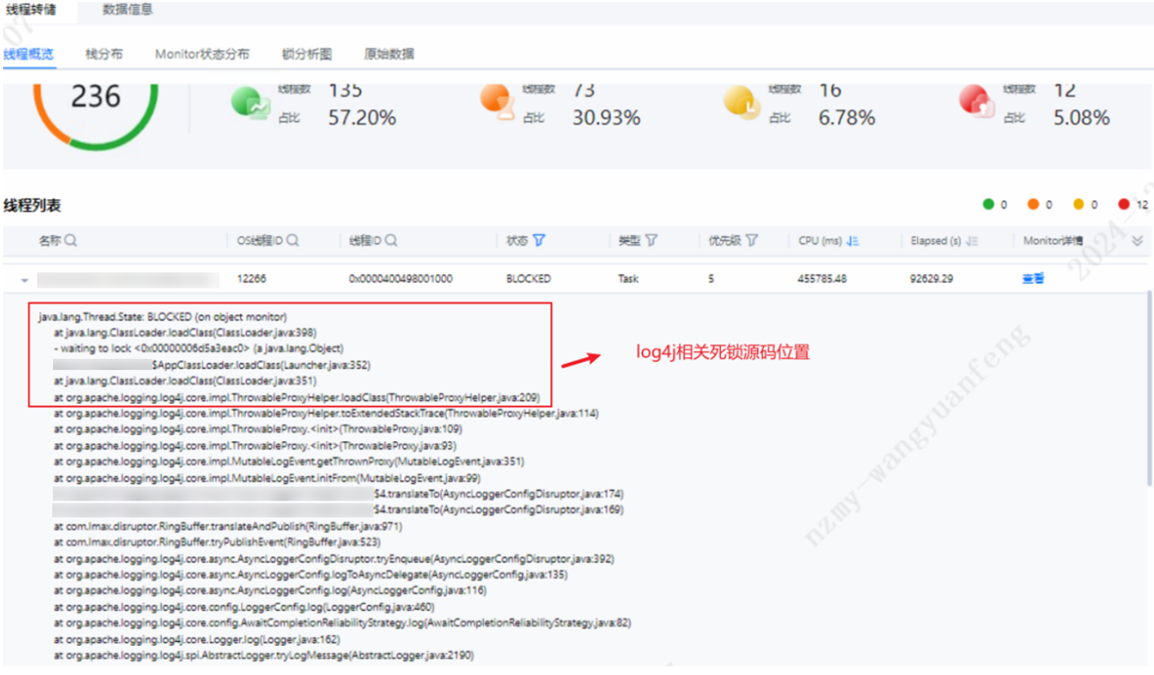
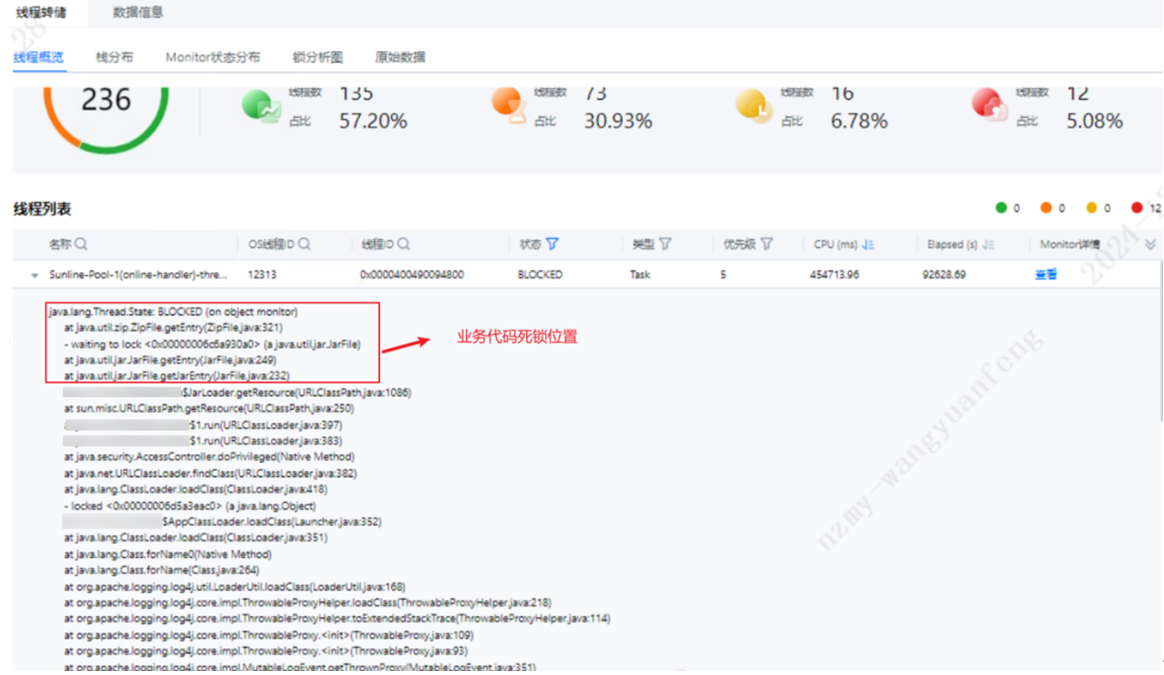
线程转储后,通过上图发现大量业务线程及log4j日志线程等待以及死锁问题,并且线程等待及死锁占比高达42.79%,对系统整体性能影响极大。业务线程锁等待问题可以通过DevKit工具定位到问题点,结合自身业务进优化源码,log4j日志框架优化给出如下建议:
1. 修改日志级别,尽量只打印关键信息。
2. 写日志的条件判断,不同级别的日志建议分开使用锁,尽量不使用共享锁导致锁竞争。
3. 修改日志配置,但是该配置项会先把日志写入缓存,大大减少了IO和磁盘读写操作,提升了系统的性能,如果服务出现宕机,有部分日志数据丢失风险,可以根据自己的业务自行评估,具体配置如下:
log4j.appender.FILE.ImmediateFlush=false(请求的日志消息被立即输出,默认为true)
log4j.appender.FILE.BufferedIO=true(请求的日志消息不会立即输出,存储到缓存当中,当缓存满了后才输出到磁盘文件中,默认为false,此时ImmediateFlush应当设置为false)
log4j.appender.FILE.BufferSize= 8192(缓存大小,默认为8k)步骤 5 网卡软中断分析。
性能测试过程中,发现网络软中断较集中,当前HCS不支持网卡多队列,故实施RPS网卡散列达到与网卡多队列相同效果,性能未提升,本次网卡软中断问题并非此应用的主要瓶颈点。
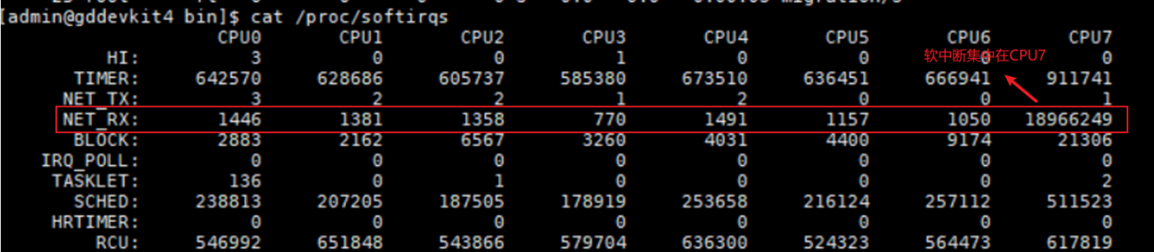
步骤 6 数据库瓶颈分析。
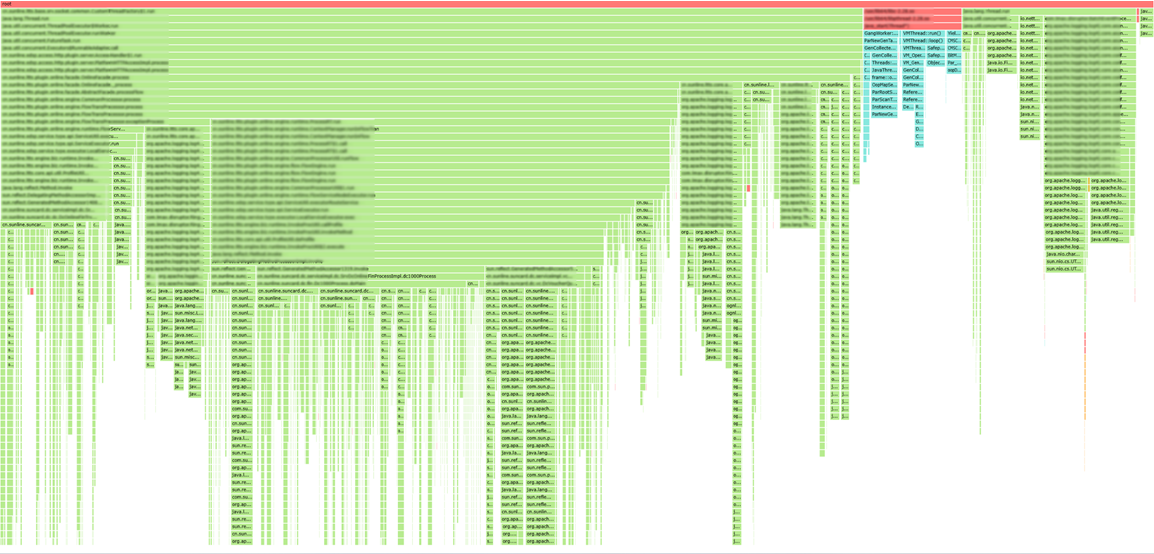
由于无法访问数据库所在服务器,故从业务层面分析数据库瓶颈,从信用卡核心系统的火焰图以及jstack收集的数据分析,并未发现JDBC连接相关的性能瓶颈,数据库可能并非信用卡核心主要性能瓶颈。信用卡核心系统运行态火焰图如下:
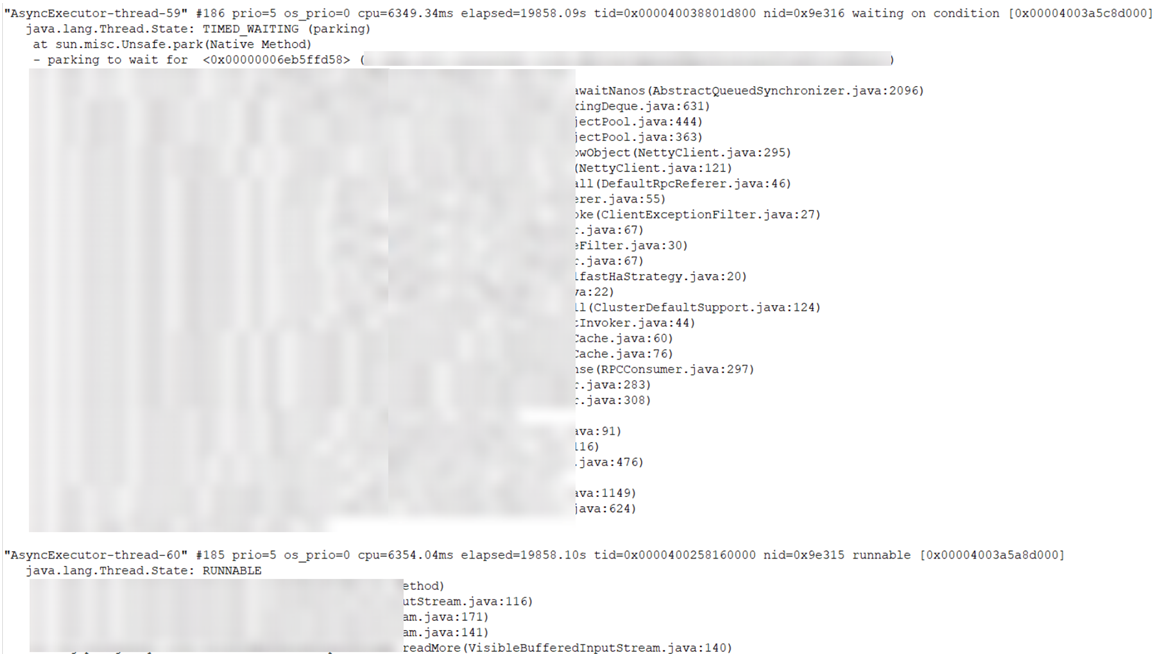
信用卡核心系统运行态jstack采集信息如下:
2.2 中间业务云系统性能瓶颈分析
中间业务云系统性能瓶颈从CPU、内存、Java热点函数、GC、线程、网卡中断等多个维度进行分析,当前系统源码中存在大量线程等待以及网卡软中断集中问题,导致CPU利用率极低,对系统吞吐量影响较大,建议后续优化方向是对源码进行优化,也可尝试增加网卡队列。
根据性能测试过程数据分析,当前中间业务云系统源码中存在线程等待及死锁问题,导致CPU利用率下降,针对中间业务云系统软件做如下分析并给出相应的优化方向。
步骤 1 CPU及内存分析。
通过DevKit性能分析工具系统概览页面,可以看到当前中间业务云系统所在虚拟机,CPU、内存均不存在性能瓶颈。
步骤 2 Java热点函数分析。
DevKit工具支持火焰图抓取,安装好DevKit性能分析工具登录到主界面后,选择“Java性能分析”,添加目标节点信息,选择“在线分析”。
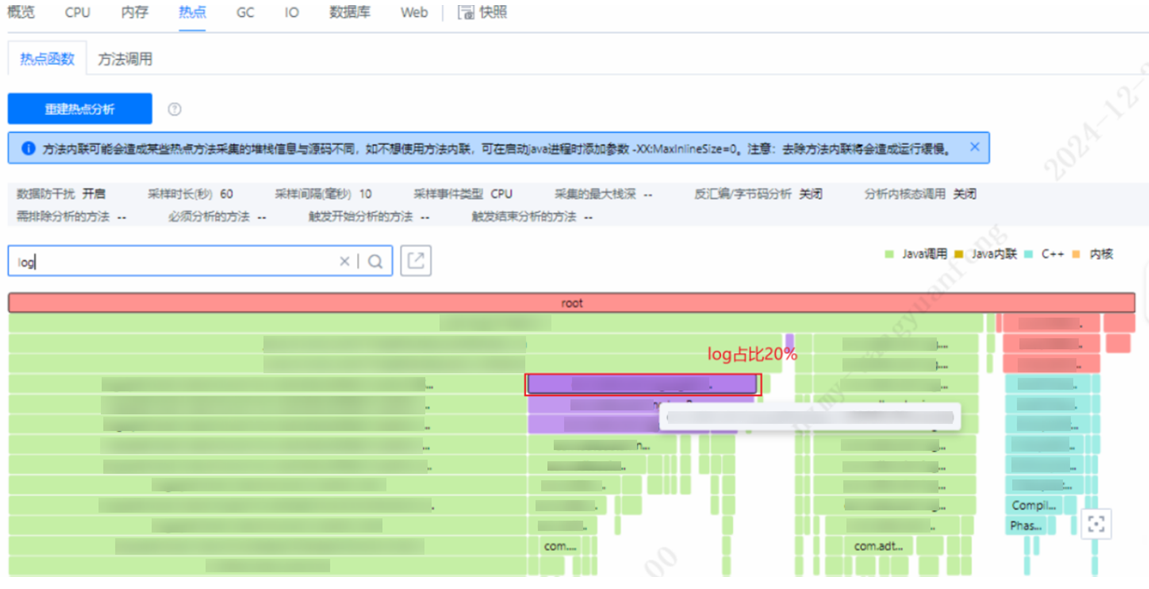
从上图可以看到,整体业务中,log占比高达20%,可以结合业务考虑是否有优化空间。
步骤 3 GC分析。
DevKit工具支持火焰图抓取,安装好DevKit性能分析工具登录到主界面后,选择“Java性能分析”,添加目标节点信息,选择“在线分析”,选择GC即可看到GC分析结果及原因。
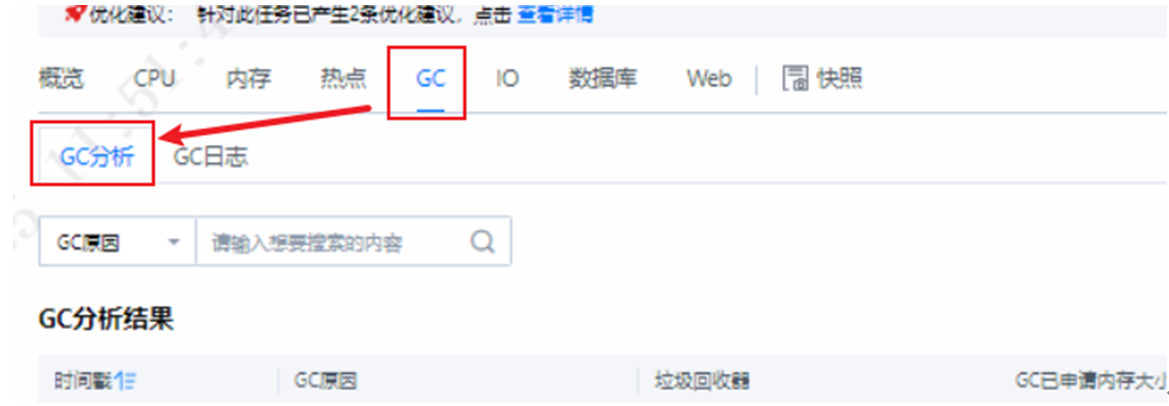
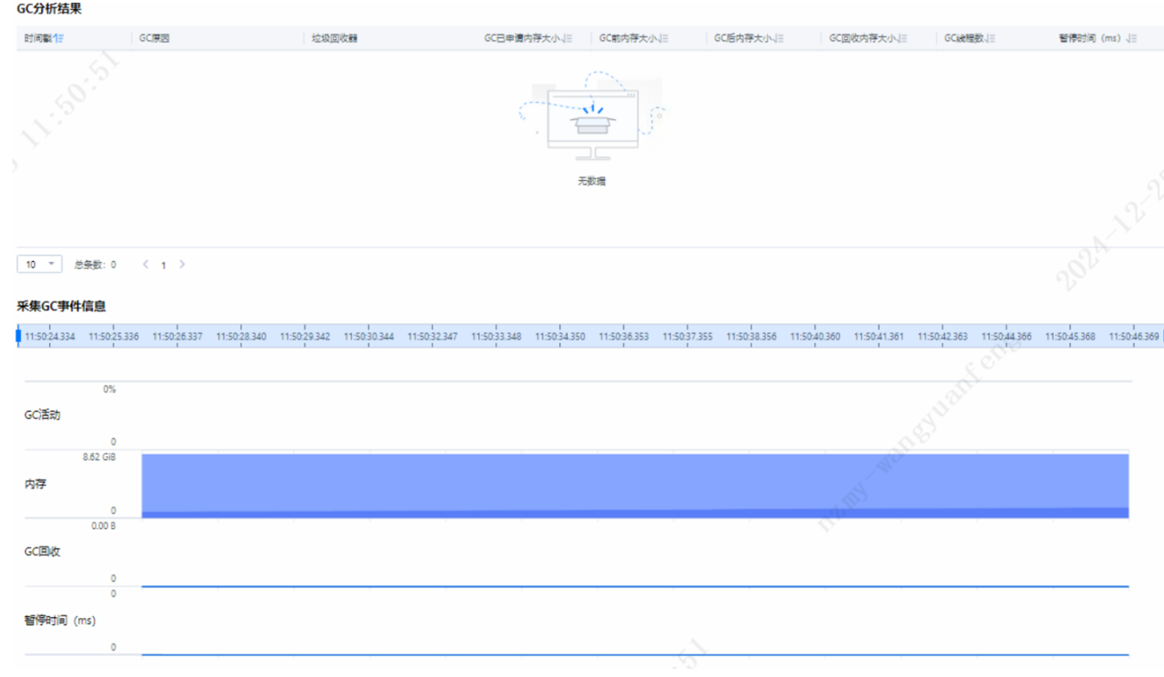
从上图中GC采集信息来看,该应用并无频繁GC,无需优化。
步骤 4 线程等待及死锁分析。
接口耗时日志打印
接口阶段耗时:从下图可以看出,主要耗时在接口事务处理。
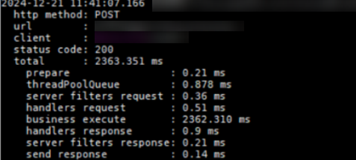
DevKit工具扫描
DevKit工具支持线程问题定位,安装好DevKit性能分析工具登录到主界面后,选择“Java性能分析”,添加目标节点信息,选择“在线分析”。再选择CPU中的锁与等待,可以从“监视器”中看到当前等待的线程有哪些。通过线程转储中的原始数据,重新导入分析,可以查看线程总览及详情。
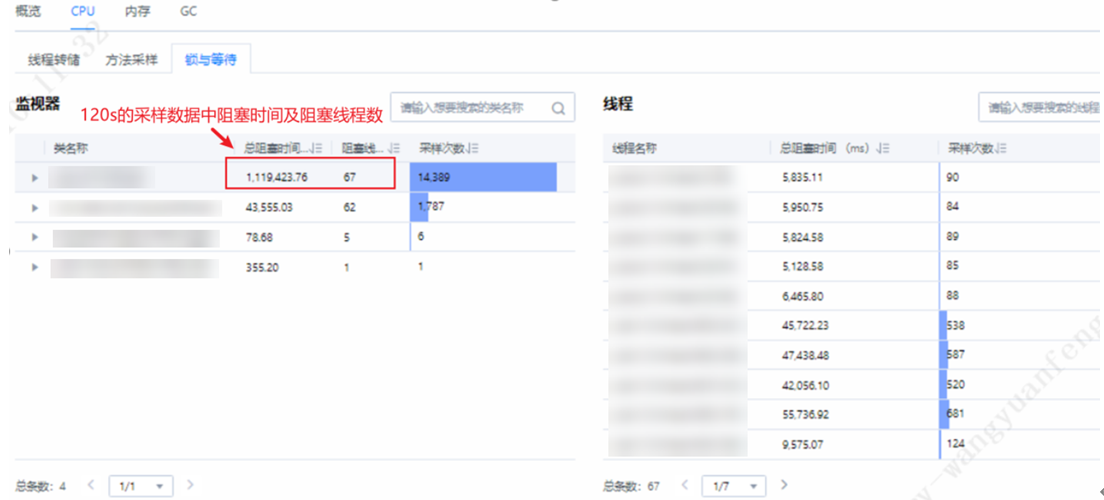
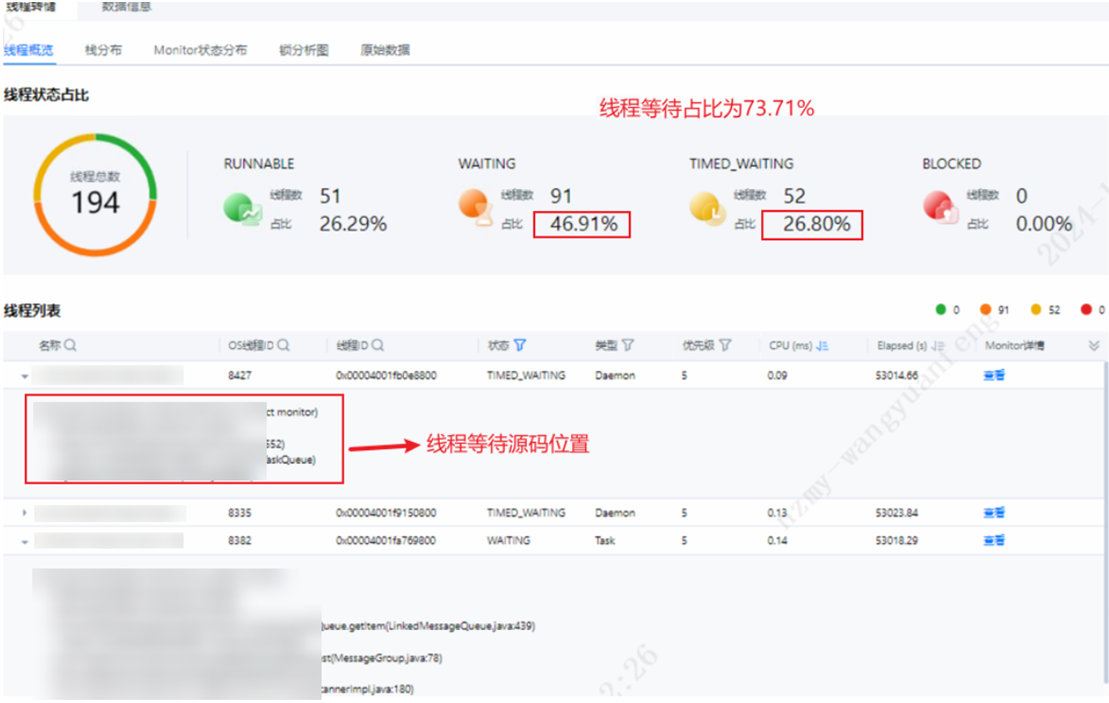
通过上图可以看到,有业务线程及log4j日志线程导致的锁等待及死锁问题,并且线程等待及死锁占比高达73.71%,对系统性能影响极大。业务线程锁等待问题可以通过DevKit工具定位到问题点,结合自身业务进行优化源码,log4j日志框架优化给出如下建议:
1. 修改日志级别,尽量只打印关键信息。
2. 写日志的条件判断,不同级别的日志建议分开使用锁,尽量不使用共享锁导致锁竞争。
修改日志配置,但是该配置项会先把日志写入缓存,大大减少了IO和磁盘读写操作,提升了系统的性能,如果服务出现宕机,有部分日志数据丢失风险,可以根据自己的业务自行评估,具体配置如下:
log4j.appender.FILE.ImmediateFlush=false(请求的日志消息被立即输出,默认为true)
log4j.appender.FILE.BufferedIO=true(请求的日志消息不会立即输出,存储到缓存当中,当缓存满了后才输出到磁盘文件中,默认为false,此时ImmediateFlush应当设置为false)
log4j.appender.FILE.BufferSize= 8192(缓存大小,默认为8k)步骤 5 网卡软中断分析。
性能测试过程中,发现网络软中断较集中,当前HCS不支持网卡多队列,故实施RPS网卡散列达到与网卡多队列相同效果,性能未提升,本次网卡软中断问题并非此应用的主要瓶颈点。
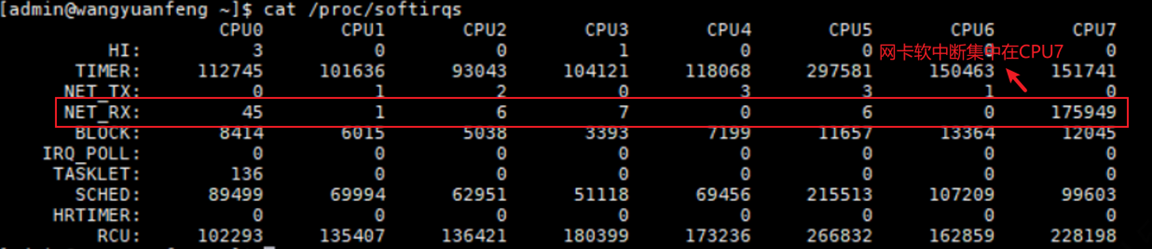
步骤 6 数据库瓶颈分析。
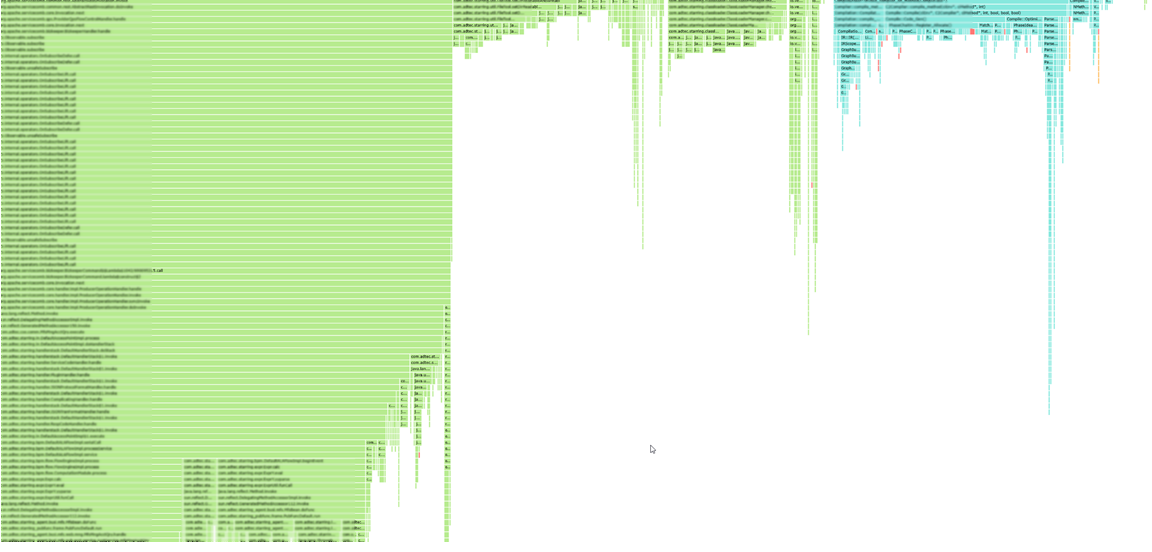
由于无法访问数据库所在服务器,故从业务层面分析数据库瓶颈,从中间业务云系统的火焰图以及jstack收集的数据分析,并未发现JDBC连接相关的性能瓶颈,数据库可能并非信用卡核心主要性能瓶颈。中间业务云系统运行态火焰图如下:
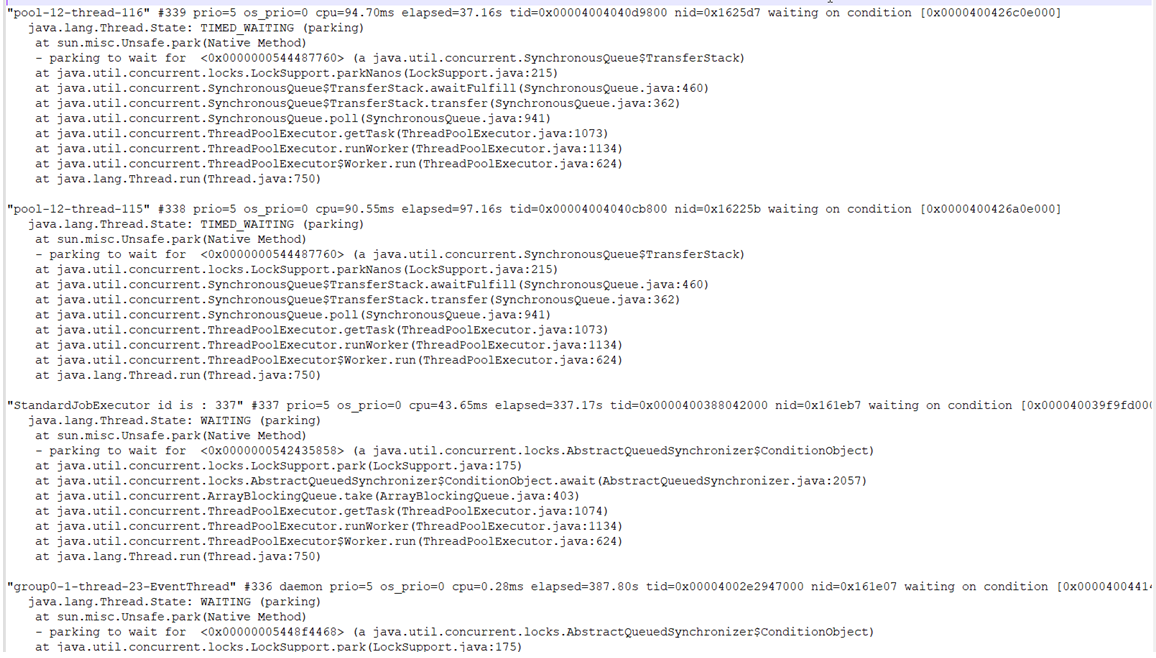
中间业务云核心系统运行态jstack采集信息如下:
3 性能调优实践
3.1 硬件调优
3.1.1 BIOS调优
对于不同的硬件设备,通过在BIOS中设置一些高级选项,可以有效提升服务器性能。重启服务器后,进入BIOS设置界面,并设置如表3-1所示的选项。
如何进入BIOS界面的具体操作请参见《TaiShan 服务器 BIOS 参数参考(鲲鹏920处理器)》中“进入BIOS界面”的相关内容。
表3-1 配置BIOS
|
选项 |
设置值 |
设置方法 |
|---|---|---|
|
Power Policy,CPU性能算力强相关场景,设置CPU电源策略为性能模式,无动态调频,固定运行在标称频率,提高主频,发挥CPU最大性能,但会增加功耗开销。低功耗场景设置CPU电源策略为节能模式,支持CPPC动态调频。 |
Performance/Efficiency |
依次选择“Advanced > Performance Config > Power Policy”,将“Power Policy”设置为“Performance”或“Efficiency”。 |
|
Custom Refresh Rate,自定义内存刷新速率,85°C下刷新率为64ms,减少刷新频率会提升内存性能,85°C上将为32ms,建议设置为Auto。 |
Auto |
依次选择“Advanced > Memory Config > Custom Refresh Rate”,将“Custom Refresh Rate”设置为“Auto”。 |
|
Support Smmu,服务器上的SMMU一般用来完成设备的地址转换,并且可以实现设备隔离,在虚拟化中很实用,但是在物理机测试场景下,SMMU可能会导致性能下降,尤其对于小包网络场景,建议关闭该功能提升服务器性能。在虚拟机场景需要打开此配置来使用PCI直通功能。 |
Enabled |
依次选择“Advanced > MISC Config > Support Smmu”,将“Support Smmu”设置为“Enabled”。 说明 如果服务器配置了Avago SAS3408iMR、Avago SAS3416iMR RAID卡或Avago MegaRAID SAS 9440-8i RAID控制卡时,该参数需要设置为“Disabled”。否则兼容性有问题会导致开机异常。 |
|
CPU Prefetch Configuration,CPU预取可以令CPU先行提取下一段指令,提高系统效能,内存带宽提高,内存延迟增加,预取内容若错误则造成额外开销,需根据实际情况选择是否打开,防止其对性能造成影响。 |
Enabled |
依次进入“Advanced > MISC Config > CPU Prefetching Configuration”,将“CPU Prefetching Configuration”设置为“Enabled”。 |
|
NUMA,控制是否使能NUMA。CPU核访问本地NUMA内存会更快,但是访问节点外内存会变慢。 |
Enabled |
依次选择“Advanced > Memory Config -> NUMA”,将设置“NUMA”为“Enabled”。 |
|
Stream Write Mode,流写入模式指数据以流形式写入时的缓存/内存交互策略,常见于数据库、存储系统或高性能计算场景,用于优化连续/批量数据写入的效率。设置为“Allocate LLC”后在流写入数据时,可将数据临时分配到LLC缓存中,再通过缓存同步到内存或存储,优化写入性能。 |
Allocate LLC |
依次选择“Advanced > Performance Config > Stream Write Mode”,将设置“Stream Write Mode”为“Allocate LLC”。 |
3.1.2 CPU
设置CPU perfromance
性能测试场景下可以将OS层面设置CPU最大频率运行,效果同BIOS性能模式,但是OS侧可能不稳定。设置方法:
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor说明
鲲鹏920处理器下BIOS设置性能模式后OS上“/sys/devices/system/cpu/cpu*/cpufreq”目录不会存在,无需再设置。
程序绑核
对于CPU调度频繁、跨NUMA和跨片带来性能下降的场景,可以将CPU绑定到固定核心上,不会发生CPU调度、跨NUMA和跨片。设置方式1:通过taskset命令绑核
- 启动时绑核:
taskset -c {cpu_lists} + 运行的程序- 运行中绑核:
taskset -cp {cpu_lists} + 程序的pid设置方式2:通过numactl命令绑核
- 绑核:
numactl -C {cpu_list} + 运行的程序
#-C cpus或者--physcpubind=cpus都可以
- 绑NUMA范围的核:
numactl -N {numa_node_list} + 运行的程序
# -N nodes或者--cpunodebind=nodes都可以说明
- {cpu_list}:示例0,或者1~13,16等
- {numa_node_list}:示例+0,或者+0,+2等多个numa,或者0-2
- 查看程序当前运行的CPU核亲和性:taskset -cp {pid}
- numactl其它参数:
− -m {numa_node}绑内存,如-m+0,绑定内存到numa0,-m+0,+1则绑定到numa0和numa1,或者0-2也可以,表示numa0/1/2。
− -i <nodes>设置内存交织,如-i 0,1则numa0和numa1的内存交织,-i all表示所有numa内存交织。
3.1.3 内存
内存调优
通道数插满,即每个内存通道插1根(1DPC)内存条,所有内存速率为2933MT/s,容量和Rank等规格一样。
说明
- 内存配置助手:https://info.support.huawei.com/computing/tools/memory-configuration/enterprise/kunpeng-computing?lang
- 鲲鹏920处理器单CPU 2个Die(部分型号1个Die),最大支持8个内存通道,单通道最大支持2个DDR4 DIMM,单CPU最大支持16 个DDR4 DIMM。
- 内存配置速率最大可达2933MT/s,2DPC内存配置速率最大可达2666MT/s。
numactl命令对内存的优化
当需要绑定内存避免跨Die和跨片场景,可以numactl命令对内存进行优化,使得通过CPU仅在本NUMA下访问内存。
设置方法:
1. 绑定到1个或者多个NUMA节点。
numactl -m {numa_node} + 运行的程序
# 绑内存如numactl -m +0 top,top进程内存绑定内存到numa0,numactl -m +0,+1 top,则内存绑定到numa0和numa1
# 绑定后不能访问其它节点内存,不够时会使用swap,建议在内存足够时使用
# --membind=nodes, -m nodes都可以绑内存的NUMA节点2. 优先使用本节点内存,不够时使用其它节点内存。
numactl -l {numa_node} + 运行的程序
# --localalloc和-l都可以3. 进行内存Die交织,可以在软件上让程序把多个NUMA作为1个NUMA来访问内存,根据场景使用。
numactl -l {numa_node} + 运行的程序
# --localalloc和-l都可以min_free_kbytes=112640
针对内存密集型任务内存不够用跑到swap分区场景时,建议设置min_free_kbytes=112640,使得OS保留最小内存大小(以KB计算),低于该值OS会进行内存回收。
设置方法:
临时生效:sysctl -w min_free_kbytes=112640
永久生效:
echo "min_free_kbytes=112640" >> /etc/sysctl.conf
sysctl -p3.1.4 硬盘
调整硬盘预读缓存大小read_ahead_kb
顺序读场景下,预读是提高磁盘性能的有效手段,目前对顺序读比较有效,主要针对HDD硬盘,对于随机读则没有作用,在SSD硬盘上甚至有害,因此在SSD上需要关闭预读。
设置方法:
|
方式 |
命令 |
调整方式 |
单位 |
生效范围 |
底层机制 |
|---|---|---|---|---|---|
|
方式1 |
echo 4096 > /sys/block/${disk}/queue/read_ahead_kb,其中${disk}为实际盘符,例如sda。 |
直接修改sysfs文件 |
KB(千字节) |
仅当前设备(如sda) |
通过内核sysfs接口直接写入参数 |
|
方式2 |
blockdev --setra 8192 /dev/${disk},其中8192对应read_ahead_kb中的4096KB,1个扇区是512字节,2个扇区是1KB;${disk}为实际盘符,例如sda。 |
使用blockdev工具 |
扇区(Sectors) |
仅当前设备(如sda) |
ioctl系统调用修改块设备参数 |
调整硬盘请求队列长度nr_requests和硬盘队列深度queue_depth
硬盘吞吐性能测试场景下,通过调整硬盘IO队列相关参数,减少请求阻塞、提升设备并行处理能力,最终改善存储性能。nr_requests参数,可以提高系统的吞吐量,但是也不能过大,因为这样会消耗大量的内存空间。
设置方法:
echo 512 >/sys/block/${disk}/queue/nr_requests
echo 256 >/sys/block/${disk}/device/queue_depth
# ${disk}为实际盘符,如sda3.1.5 网络
网卡中断绑核
网络高负载场景或者需要把网卡中断绑定到特定CPU核心时,可以通过网卡中断绑核提升性能。设置后网卡中断在固定CPU核心上处理软中断。设置方法:
1. 停止irqbalance服务,如果不关闭,即使绑定网络中断,irqbalance服务会把中断指定到别的CPU核心上,需要停止该服务。
service irqbalance stop2. 获取网卡的中断号列表,不同网卡获取方式不同,根据实际情况选择。
a. 查看网卡的队列数。
ethtool -l <network_device name>示例:ethtool -l enp3s0,如下回显表示有16个队列。
Channel parameters for enp3s0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 16 #表示网卡最大支持设置的队列
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 16 #当前设置的队列b. 修改网卡的队列数。
ethtool -L <network_device name> combined N示例:ethtool -L enp3s0 combined 4,设置4个队列,通过ethtool -l enp3s0查询设置结果,回显信息如下:
Channel parameters for enp3s0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 16
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 4c. 获取网卡的中断号。
方法1:执行以下命令获取网卡中断号,如果看到的队列号数量和设置的队列一致则使用此方法获取,其中network_device name为实际环境看到的网口名。
cat /proc/interrupts | grep <network_device name> |awk '{print $1" "$NF}',示例:cat /proc/interrupts | grep enp3s0 |awk '{print $1" "$NF}'
394: enp3s0_qp0
395: enp3s0_qp1
396: enp3s0_qp2
397: enp3s0_qp3方法2:有时候无法通过网口名获取到队列号,需要通过网口的bus-id号获取队列中断号。
i. 查询网口的bus-id:ethtool -i <network_device name>|grep bus-info
示例:ethtool -i enp3s0|grep bus-info
bus-info: 0000:03:00.0ii. 通过bus-id获取网口的队列中断:cat /proc/interrupts |grep {bus-id} |awk '{print $1" "$NF}'
示例:cat /proc/interrupts |grep '0000:03:00.0' |awk '{print $1" "$NF}'
3. 查询网卡所在NUMA,一般中断需要绑定到网卡所在NUMA的CPU核心,建议通过bus-id的方法确认。
cat /sys/bus/pci/devices/{net_bus_info}/numa_node示例:
ethtool -i enp3s0|grep bus-info #查询网口bus-id bus-info: 0000:03:00.0 cat /sys/bus/pci/devices/0000\:03\:00.0/numa_node #查看网卡所在NUMA 0#如上表示网卡在numa0上
4. 设置网卡队列所在CPU核心,如2.获取网卡的中断号列表,不同网卡获取方式不同,...中获取到队列中断号是394,网卡在numa0,绑定到core 4上。
echo {core} > /proc/irq/{IRQ}/smp_affinity_list示例:echo 4 > /proc/irq/394/smp_affinity_list
按照该步骤依次对所有中断绑核,可以编写脚本进行绑核。
增大MTU,增加吞吐量
当传输网络包都是大包(超过1500字节)时考虑增大MTU(Maximum Transmission Unit),默认MTU 1500字节,最大支持设置9000字节,通过ip addr命令可以查看。1. MTU即最大传输单元,是指通信协议的某一层上面所能通过的最大数据包大小(以字节为单位)。
2. MTU用于设定TCP/IP协议传输数据包时的最大传输单元,即主机发送的数据包的大小。采用TCP/IP协议进行数据传送时,物理网络层一般要限制每次发送数据帧的最大长度,该字节数即MTU值。当一台PC要发送IP数据包信息时,它首先查询网卡的MTU设置,然后把MTU与数据包长度进行比较,当数据包的长度大于MTU值时,就会将数据包进行分片。
3. 网络两端的MTU值要一致。因为当通信两端的MTU的大小不匹配时,可能产生很多IP分片,重组这些IP分片消耗CPU能力,并且增加时延,应该避免。
设置方法:
临时生效,重启系统后失效
ifconfig ethx mtu 9000 永久生效
vi /etc/sysconfig/network-scripts/ifcfg-$(Interface),并增加MTU="9000",完成后重启网络服务说明
netperf/iperf测试中两端设置MTU9000可以增大TCP/UDP带宽上限,同时减少CPU的开销。
设置网卡中断散列RPS和RFS
RPS(Receive Packet Steering)在接收端将网卡硬中断和相应的软中断分离在不同的CPU上处理,解决高硬中断率时两者相互影响带来的单CPU处理瓶颈。RPS主要用于网卡硬件队列数少,但CPU资源相对丰富的场景,解决CPU处理硬中断、软中断和消耗网络数据。在RPS的基础上,通过RFS(Receive Flow Steering)进一步将同一网络流(Flow)的数据包定向到“处理该流的应用程序所在的CPU核心”,减少CPU缓存失效,提升处理效率。网卡的网络中断占用过高成为瓶颈时,可以设置RPS把网卡1个队列中断分散到多个CPU核心上,消除瓶颈,提升性能。多网卡队列如果分布不均匀也可以考虑设置。
设置方法:
1. 以enp125s0f0为例,查看网卡所在NUMA。
ethtool -i enp125s0f0|grep bus-info
bus-info: 0000:7d:00.0
cat /sys/bus/pci/devices/0000:7d:00.0/numa_node
02. 在numa0上,根据设置的网络中断CPU选择,如考虑如置cpu4-7,找1个可以echo设置smp_affinity_list的中断,如330,按照如下方法获取到对应CPU掩码是00000000,00000000,00000000,000000f0
cat /proc/irq/330/smp_affinity_list
2
echo 4-7 > /proc/irq/330/smp_affinity_list
cat /proc/irq/330/smp_affinity
00000000,00000000,00000000,000000f0
# 恢复原始的cpu亲和性
echo 2 > /proc/irq/330/smp_affinity_list3. 设置RPS和RFS。
echo 00000000,00000000,00000000,000000f0 > /sys/class/net/enp125s0f0/queues/rx-0/rps_cpus
echo 32768 > /sys/class/net/enp125s0f0/queues/rx-0/rps_flow_cnt
echo 32768 > /proc/sys/net/core/rps_sock_flow_entries设置硬件网卡队列数
单纯追求网卡带宽时可以将网卡队列数设置为最大,但是需要结合网卡所在NUMA的CPU核心数考虑,减小CPU消耗时可以适当减少网卡队列数。增加或者减少网卡硬件队列,多队列发挥时,每个队列都会对应1个中断,每个中断都消耗CPU。设置方法:
1. 执行ethtool –l <device-name>命令查看网卡队列,如下其中“Pre-set maximums”中的“Combined”是网卡最大支持的队列,“Current”是当前设置的队列数。
示例:ethtool -l enp3s0
Channel parameters for enp3s0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 16
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 42. 执行ethtool –L <device-name> combined <N>命令,设置网卡硬件队列。
示例:ethtool -L enp3s0 combined 8
查询设置结果:ethtool -l enp3s0
Channel parameters for enp3s0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 16
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 83.2 操作系统grub启动参数调优
步骤 1 打开grub配置文件。
vim /etc/default/grub步骤 2 按“i”进入编辑模式,找到GRUB_CMDLINE_LINUX=xx,在GRUB_CMDLINE_LINUX=中添加需要的grub启动参数,如selinux=0,也可以是多个参数。
表3-2 grub启动参数
|
参数 |
说明 |
适用场景 |
|---|---|---|
|
selinux=0 |
关闭Linux的SELinux,某些场景下会减少SELinux带来的性能损耗开销。 说明 安全增强型Linux(Security-Enhanced Linux)简称SELinux,它是一个Linux内核模块,也是Linux的一个安全子系统。 |
POC场景下建议均关闭。 |
|
audit=0 |
关闭Linux的audit,某些场景下会减少audit带来的性能损耗开销。 说明 Linux audit子系统是一个用于收集记录系统、内核、用户进程发生的行为事件的一种安全审计系统。该系统可以可靠地收集有关上任何与安全相关(或与安全无关)事件的信息,它可以帮助跟踪在系统上执行过的一些操作。 |
POC场景下建议均关闭。 |
|
nohz=on |
nohz模式下当CPU处于空闲状态时,直接设置下一次的中断时间而不是使用系统无条件的默认的HZ中断,开启后对延迟有影响。 说明 - Linux内核为每个CPU核设置一个周期性的时钟中断,Kernel依赖这个时钟中断来处理一些进程时间片等周期性的事件。 - 时钟中断本身也要消耗CPU,频率越高调度的时间片越小,系统的实时响应能力越强,也会消耗更好的CPU资源。 - 查询内核的时钟周期值方法:grep ^CONFIG_HZ /boot/config-`uname -r |
性能CPU算力场景,非延迟敏感场景。 |
步骤 3 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
步骤 4 重启操作系统,执行cat /proc/cmdline检查是否包含已配置的参数。
3.3 虚拟机调优
虚拟机绑核
方式一:编辑虚拟机xml配置文件
<domain type = 'KVM'>
...
<vcpu placement = 'static' cpuset='20-27'>8</vcpu>
<cputune>
<vcpupin vcpu='0' cpuset='20'/>
<vcpupin vcpu='1' cpuset='21'/>
<vcpupin vcpu='2' cpuset='22'/>
<vcpupin vcpu='3' cpuset='23'/>
<vcpupin vcpu='4' cpuset='24'/>
<vcpupin vcpu='5' cpuset='25'/>
<vcpupin vcpu='6' cpuset='26'/>
<vcpupin vcpu='7' cpuset='27'/>
<emulatorpin cpuset='20-27'/>
</cputune>
...
<domain>
说明
cpuset='20-27':表示将QEMU主线程绑定到20至27物理CPU上。
方式二:临时生效,虚拟机重启失效
virsh vcpupin [虚机id] vcpuid cupid绑核弊端分析
- 虚拟机场景弊端:
− 资源争抢:当多个虚机绑核到相同的物理核心时,会导致这些虚拟机之间产生CPU资源争抢,降低整体性能。
− 灵活性降低:绑核后虚拟机的CPU资源相对固定,难以根据实际负载动态调整,无法充分利用物理机的空闲CPU资源。
− 运维成本增加:虚拟机核故障的情况不支持自动飘走,需要手动分配资源。
- 容器场景绑核弊端:
− 隔离性问题:容器本身隔离性较弱,绑核后多个容器共享相同的物理核心,可能会导致容器之间的干扰增加,影响应用程序的稳定性和性能。
− 资源分配不均:在多容器环境下,绑核可能导致资源分配不均,一些容器可能获得过多的CPU资源,而另一些容器则资源不足,影响整体的资源利用率和业务性能。
− 管理难度加大:绑核增加了容器管理的复杂性,需要更精细的资源监控和管理策略,以确保各个容器的性能和资源使用情况符合预期。
- 物理机场景绑核弊端:
− 硬件资源浪费:绑核可能导致部分CPU核心被特定应用程序独占,而其他应用程序无法充分利用这些空闲的核心,造成硬件资源的浪费。
− 系统稳定性风险:不当的绑核配置可能会导致系统负载不均衡,增加系统崩溃或死锁的风险,影响物理机的稳定运行。
− 扩展性受限:绑核后物理机的CPU资源分配相对固定,当需要对系统进行扩展或调整时,可能会受到绑核配置的限制,增加调整的难度和风险。
3.4 JVM调优
常用的JVM参数涉及多个方面的调优,如内存管理、垃圾回收、线程管理等。通过合理配置这些参数,可以显著提升Java应用的性能。以下是常见的JVM参数以及如何调优使用这些参数。
表3-3 JVM参数调优建议
|
调优参数 |
调优说明 |
|---|---|
|
快速序列化 |
在需要序列化的场景中(热点函数中存在readObject/writeObject,可以通过火焰图查看),可以添加JVM参数-XX:+UseFastSerializer开启毕昇JDK的快速序列化特性。 |
|
内存管理参数 |
内存管理是JVM调优的核心部分。Java内存模型由堆内存(Heap)、方法区(MetaSpace),以及栈(Stack)组成。调整这些内存参数有助于优化内存使用,减少GC的频率,提高吞吐量。 |
|
堆内存相关参数 |
-Xms:设置堆内存的初始大小。示例:-Xms2g(设置初始堆内存为2GB)。根据应用的初始负载,设置合理的初始堆大小,避免堆内存频繁扩展。 |
|
-Xmx:设置堆内存的最大大小。示例:-Xmx4g(设置最大堆内存为4GB)。设置一个合理的最大堆大小,防止内存溢出(OutOfMemoryError),也要避免设置过大,导致系统内存不足。 | |
|
-Xmn:设置年轻代(Young Generation)的大小。示例:-Xmn1g(设置年轻代大小为1GB)。适当调整年轻代的大小,可以优化垃圾回收的频率。一般来说,年轻代的大小为堆内存的1/3。 | |
|
将Xms与Xmx设置为相同的值可以保证虚拟机在启动时完成堆内存初始化,避免业务波动时导致堆内存大小变化带来的STW时间抖动。如果对内存资源敏感,可以设置不同的Xms、Xmx以在内存闲置时节省内存资源。如果使用了G1回收器,在毕昇JDK上可以设置-XX:+G1Uncommit参数来开启内存弹性回收特性。 示例:-Xmx4g -Xms4g | |
|
Metaspace(方法区)参数 |
-XX:MetaspaceSize:设置Metaspace的初始大小。示例:-XX:MetaspaceSize=128m(设置Metaspace的初始大小为128MB)。根据应用使用的类的数量和大小,调整Metaspace的大小。 |
|
-XX:MaxMetaspaceSize:设置Metaspace的最大大小。示例:-XX:MaxMetaspaceSize=512m。设置适当的最大值,避免应用加载过多类导致内存溢出。 | |
|
Stack 内存参数 |
-Xss:设置每个线程的栈大小。示例:-Xss512k(设置每个线程栈大小为512KB)。 对于大并发的应用,增加栈大小可以减少栈溢出错误;对于多线程小内存应用,减少栈大小可以节省内存。 |
|
垃圾回收(GC)相关参数 |
垃圾回收(GC)是JVM性能优化中至关重要的部分。合适的GC策略可以减少停顿时间,提升吞吐量。 |
|
启用不同的垃圾回收器: l -XX:+UseSerialGC:启用串行垃圾回收器(适用于单核或低内存环境)。 l -XX:+UseParallelGC:启用并行垃圾回收器(适用于多核机器)。适合在负载较轻的机器上使用,能够提高吞吐量。 l -XX:+UseG1GC:启用G1垃圾回收器(适用于大内存应用,减少停顿时间)。适用于大内存、高并发的应用。 l -XX:+UseConcMarkSweepGC:启用CMS(并发标记清除)垃圾回收器(低延迟,适合低停顿的场景)。 | |
|
垃圾回收日志: l -XX:+PrintGCDetails:打印详细的垃圾回收日志。 l -XX:+PrintGCDateStamps:打印垃圾回收时间戳。 l -Xloggc:<file-path>:将GC日志输出到指定文件中。 | |
|
调整GC线程数: l -XX:ParallelGCThreads:设置并行垃圾回收线程数。示例:-XX:ParallelGCThreads=4(设置并行垃圾回收线程数为4)。 l -XX:ConcGCThreads:设置CMS垃圾回收的并发线程数。示例:-XX:ConcGCThreads=4。 | |
|
启用ZGC或ShenandoahGC(低延迟垃圾回收): l -XX:+UseZGC:启用ZGC。 l -XX:+UseShenandoahGC:启用ShenandoahGC。 | |
|
内存调优 |
l 增加堆内存大小(-Xmx)以避免频繁的垃圾回收。 l 优化新生代和老年代的比例,例如:-XX:NewRatio=2,使得年轻代占堆的1/3。 |
|
GC调优 |
l 在低延迟应用中使用G1 GC或ZGC。 l 根据应用的负载调整并行回收线程数,使用-XX:ParallelGCThreads,来调整线程数。 |
4 实践总结
鲲鹏一码多芯,同辕开发流水线改造
|
改造项目 |
改造内容 |
改造目的 |
实测结论 |
价值点 |
|---|---|---|---|---|
|
代码开发 |
IDE插件集成鲲鹏DevKit工具 |
集成面向鲲鹏平台进行软件开发、迁移、编译调试和性能调优等一系列端到端工具。 |
不涉及 |
提升开发效率,实现1套代码+1条流水线->多平台版本 |
|
流水线改造 |
迁移扫描门禁 |
软件迁移评估分析用户x86环境上软件包安装路径中的SO库文件,检查文件与鲲鹏平台的兼容性。 |
已集成,本应用软件包与鲲鹏平台兼容。 | |
|
亲和扫描门禁 |
自动鲲鹏兼容和亲和检查,确保鲲鹏兼容。支持C/C++开发语言。 |
不涉及,本次应用为Java应用。 | ||
|
DevKit测试平台 |
DevKit测试平台测试报告,包含兼容性、安全性等测试项。 |
已集成,测试通过。 | ||
|
Jenkins |
鲲鹏流水线构建,基于Jenkins等开源工具。 |
已集成,流水线改造成功。 |
信息卡核心系统调优
信用卡核心系统60并发下,CPU负载最高达到700%+。
说明
虚拟机总共有8个CPU核心,CPU负载达到700,表示该进程在运行时利用了7个核心的计算资源,虚拟机CPU利用率较高。
|
调优项 |
调优内容 |
调优目的 |
实测结论 |
价值点 |
|---|---|---|---|---|
|
压力测试与监视瓶颈 |
集成性能分析工具 |
使用DevKit调优工具,可以快速总览系统整体指标,并且可以快速定位问题点,提高调优效率。 |
已集成,使用热点函数、资源调度、微架构、NUMA精细化分析、IO分析、调优助手功能,生成性能分析报告识别6处优化方向。 |
快速定位问题,分析性能瓶颈 |
|
业务性能瓶颈分析 |
性能瓶颈分析可以找到当前信用卡核心系统瓶颈点,针对瓶颈点做相应优化,进而提升当前业务应用整体吞吐量。 |
已分析,当前系统存在网卡软中断集中问题,会降低CPU利用率,进而影响系统整体的吞吐量。 | ||
|
应用程序调优 |
业务代码分析 |
基础性能分析方式已经实施,为了进一步提高系统吞吐量,对业务代码进一步的探索。 |
已分析,从信用卡核心系统源码分析出当前代码中存在较多线程等待及死锁问题 |
检查代码 |
|
JVM性能调优 |
替换高版本毕昇JDK |
G1垃圾回收器,可以更好的解决当前JVM中连续内存空间分配不足问题。 |
已试用。 |
内存使用率提升 |
|
快速序列化 |
具有更快的序列化与反序列化速度,同时可以减少CPU消耗。 |
未使用,信用卡核心系统并无太多序列化场景,无显著效果。 |
在适用场景下性能可提升10%~30% | |
|
快启动 |
提高Java应用启动性能、减少内存占用,并优化容器化和云原生环境中的资源管理。 |
未使用,信用卡核心系统压测时,结果表示CPU和内存不是性能瓶颈。 | ||
|
加解密加速 |
优化计算密集型、数据密集型和高并发应用的性能,尤其在大规模数据处理、加解密、压缩、图像处理等领域具有显著的性能提升。 |
未使用,当前测试场景不涉及加解密。 | ||
|
操作系统 |
Grub启动参数调优 |
调整Grub配置文件中的启动参数来优化操作系统的启动过程、内核性能、硬件兼容性及系统资源利用效率等。 |
已试用,在本次测试无显著效果。 虚拟机中的CPU和内存资源可能通过虚拟化设备模拟(如virtio)提供,导致内核的一些硬件优化,并不能直接生效。 |
在适用场景下性能可提升5%左右 |
|
鲲鹏硬件调优 |
CPU与内存子系统性能调优 |
虚拟机绑核:通过将进程绑定到特定的CPU核心上,可以避免因CPU资源争用而导致的性能下降。在虚拟化环境中,合理地将虚拟机和物理CPU核心进行绑定可以减少虚拟化开销。 |
已试用,在物理机上实施虚拟机绑核操作,提升系统整体吞吐量。 |
在本应用性能提升11%+ |
|
内存的页大小越大,TLB中每行管理的内存越多,TLB命中率就越高,从而减少内存访问次数。 |
未使用大页内存,当前测试环境大页内存默认开启,故没有提升效果。 |
- | ||
|
网络子系统性能调优 |
网卡中断散列:采用软件模拟的方式,实现了多队列网卡所提供的功能,分散了在多CPU系统上数据接收时的负载,把软中断分到各个CPU处理。 |
已试用,在本次测试无显著效果 实施网卡散列,网卡软中断有所分散,但中断分配的效果可能受到虚拟机的CPU配置和虚拟化平台的I/O调度策略的影响导致某一个单核中断仍然较高。 |
- | |
|
磁盘IO子系统性能调优 |
确保存储设备和系统在处理磁盘读写操作时能够高效、稳定地运行,从而提升应用性能、缩短响应时间、优化资源利用,避免磁盘I/O成为系统瓶颈。 |
未使用,当前业务场景主要IO是日志数据落盘,每秒落盘数据量较小,调整了磁盘队列及调度策略对性能提升并不明显。 |
- |
中间业务云系统调优
中间业务云系统30并发下,CPU负载最高30%。主要原因为中间业务云系统源码中存在大量线程等待,导致CPU利用率极低,对系统吞吐量影响较大,无法将CPU资源利用率提高。
|
调优项 |
调优内容 |
调优目的 |
实测结论 |
价值点 |
|---|---|---|---|---|
|
压力测试与监视瓶颈 |
集成性能分析工具 |
使用DevKit调优工具,可以快速总览系统整体指标,并且可以快速定位问题点,提高调优效率。 |
已集成,使用热点函数、资源调度、微架构、numa精细化分析、IO分析、调优助手功能,生成性能分析报告识别6处优化方向。 |
快速定位问题,分析性能瓶颈 |
|
业务性能瓶颈分析 |
性能瓶颈分析可以找到当前中间业务云系统瓶颈点,针对瓶颈点做相应优化,进而提升当前业务应用整体吞吐量。 |
已分析,当前系统存在网卡软中断集中问题,会降低CPU利用率,进而影响系统整体的吞吐量。 | ||
|
应用程序调优 |
业务代码分析 |
基础性能分析方式已经实施,为了进一步提高系统吞吐量,对业务代码进一步的探索。 |
已分析,中间业务云系统源码中存在大量线程等待,导致CPU利用率极低,对系统吞吐量影响较大。 |
检查代码 |
|
JVM性能调优 |
替换高版本毕昇JDK |
G1垃圾回收器,可以更好的解决当前JVM中连续内存空间分配不足问题。 |
已试用。 |
内存使用率提升 |
|
快速序列化 |
具有更快的序列化与反序列化速度,同时可以减少CPU消耗。 |
未使用,中间业务云系统并无太多序列化场景,无显著效果。 |
在适用场景下性能可提升10%~30% | |
|
快启动 |
提高Java应用启动性能、减少内存占用,并优化容器化和云原生环境中的资源管理。 |
未使用,中间业务云系统压测时,CPU和内存不是性能瓶颈。 应用源码中存在大量线程等待,导致CPU利用率极低。 | ||
|
加解密加速 |
优化计算密集型、数据密集型和高并发应用的性能,尤其在大规模数据处理、加解密、压缩、图像处理等领域具有显著的性能提升。 |
未使用,当前测试场景不涉及加解密。 | ||
|
操作系统 |
Grub启动参数调优 |
调整Grub配置文件中的启动参数来优化操作系统的启动过程、内核性能、硬件兼容性及系统资源利用效率等。 |
已试用,在本次测试无显著效果。 虚拟机中的CPU和内存资源可能通过虚拟化设备模拟(如virtio)提供,导致内核的一些硬件优化,并不能直接生效。 |
在适用场景下性能可提升5%左右 |
|
鲲鹏硬件调优 |
CPU与内存子系统性能调优 |
虚拟机绑核:通过将进程绑定到特定的CPU核心上,可以避免因CPU资源争用而导致的性能下降。在虚拟化环境中,合理地将虚拟机和物理CPU核心进行绑定可以减少虚拟化开销。 |
未使用,因应用源码限制,导致CPU利用率极低,CPU资源没有产生争用故无法提升。 |
在适用场景下性能可提升10%左右 |
|
内存的页大小越大,TLB中每行管理的内存越多,TLB命中率就越高,从而减少内存访问次数。 |
未使用大页内存,当前测试环境大页内存默认开启,故没有提升效果。 | |||
|
网络子系统性能调优 |
网卡中断散列:采用软件模拟的方式,实现了多队列网卡所提供的功能,分散了在多CPU系统上数据接收时的负载,把软中断分到各个CPU处理。 |
已试用,在本次测试无显著效果 实施网卡散列,网卡软中断有所分散,但中断分配的效果可能受到虚拟机的CPU配置和虚拟化平台的I/O调度策略的影响导致某一个单核中断仍然较高。 | ||
|
磁盘IO子系统性能调优 |
确保存储设备和系统在处理磁盘读写操作时能够高效、稳定地运行,从而提升应用性能、缩短响应时间、优化资源利用,避免磁盘I/O成为系统瓶颈。 |
未使用,当前业务场景主要IO是日志数据落盘,每秒落盘数据量较小,调整了磁盘队列及调度策略对性能提升并不明显。 |