


游戏AI调优实践
发表于 2025/09/30
0
作者|陈国豪
1.简介
1.1测试环境
表1 硬件环境信息
|
项目 |
要求 |
|---|---|
|
服务器型号 |
鲲鹏服务器 920 |
|
CPU型号 |
鲲鹏920 7282C处理器 |
|
CPU频率 |
2.9GHz |
|
CPU核数 |
320(4*80, SMT开启) |
|
内存 |
1TB,16*64GB(DDR5-4800) |
|
本地存储 |
SSSTC SSD 500G 16* Samsung SSD 3.5T |
|
网卡 |
2*Mellanox MT2892 (4*100GE) |
|
设备用途 |
测试用户AI游戏应用性能 |
表2 操作系统和软件信息
|
项目 |
版本 |
说明 |
|---|---|---|
|
openEuler |
22.03 (LTS-SP3) |
操作系统 |
|
Embree |
3.13.1 |
光线追踪软件 光线追踪软件 |
|
3.13.5 | ||
|
GO |
1.23.2 |
编程语言软件 |
|
GCC |
10.3.1 |
Gcc for openEuler |
|
Clang |
17.0.6 |
BiSheng 4.1.0.B007 |
1.2测试组网
测试环境架构如下图所示:
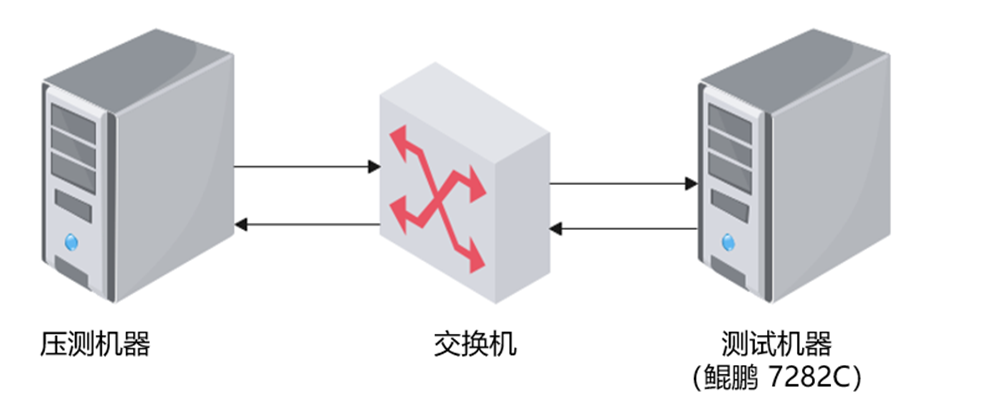
压测机器,通过交换机将测试数据发送到测试机器KUNPENG 7282C上。测试主机KUNPENG 7282C测试的指标维度如下表所示。
表3 测试机器鲲鹏 7282C的测试指标维度
|
指标维度 |
指标要求 |
|---|---|
|
主机CPU使用率 |
<=85% |
|
主机内存使用 |
核存比1:2 |
|
应用超时率 |
<=2% |
表4 测试数据统计方式
|
指标维度 |
统计方式 |
|---|---|
|
主机CPU使用率 |
通过nmon和nmonchart绘制平均CPU使用率 |
|
主机内存使用 |
通过numastat -p $pid 统计进程使用内存 |
|
应用超时率 |
应用日志最后30次超时率平均值 |
|
应用并发性能 |
应用日志最后30次并发数平均值 |
1.3测试用例
压测端通过用户测试脚本启动,脚本指定每次启动的压力(单位:局)。命令如下。
./start_press_p.sh $log_path $server_ip $server_port $press_id $press_num $thread_num
测试观察指标为用户日志并发性能及超时率,并发性能的计算命令如下。grep Total ./profiler.log | grep -v HandleForSpawnIsLandTotal | tail -n 30 | awk -F ‘|’ ‘{sum += $2} END {print “concur_avg=”, sum/NR/273}’
超时率计算命令如下。grep Total ./profiler.log | grep -v HandleForSpawnIsLandTotal | tail -n 30 | awk -F ‘|’ ‘{sum += $8} END {print “time_avg=”, sum/NR}’
1.4测试策略
压测端以步长50局压力进行测试,每次启动完50局后观察10分钟用户指标。如果稳定且满足CPU使用率与应用超时率则继续加压;如果指标不满足CPU使用率或者应用超时率则通过脚本 ./stop.sh ${局数} 降低压力直到满足CPU使用率和应用超时率。
由于鲲鹏7282C CPU以40 物理核组成一个NUMA,本次实验主要选取单个NUMA内一半物理核进行测试。由于开启SMT,在虚拟化场景中,单个NUMA可虚拟出两个40vCore的实例,可充分利用鲲鹏多核性能。启动应用命令如下。
numactl -C 80-119 -m 1 $(pwd)/ai_server
2.性能瓶颈分析
2.1Nmon分析
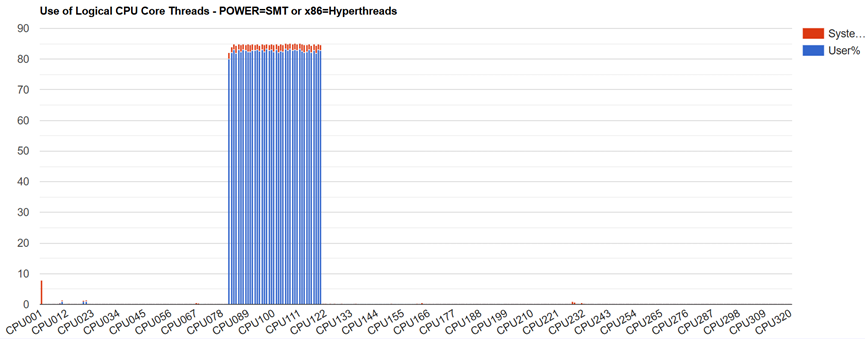
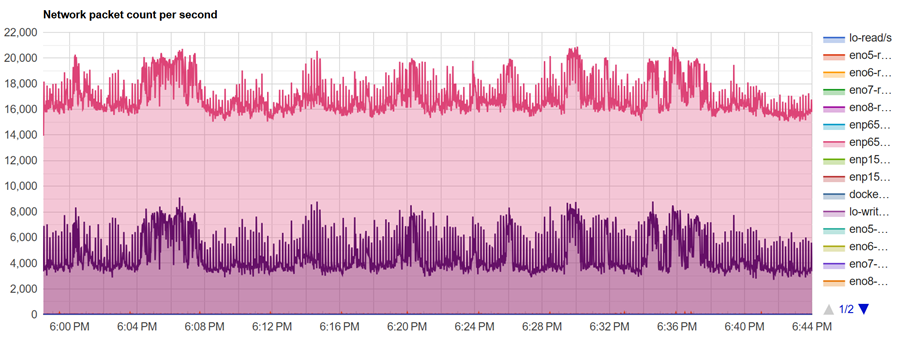
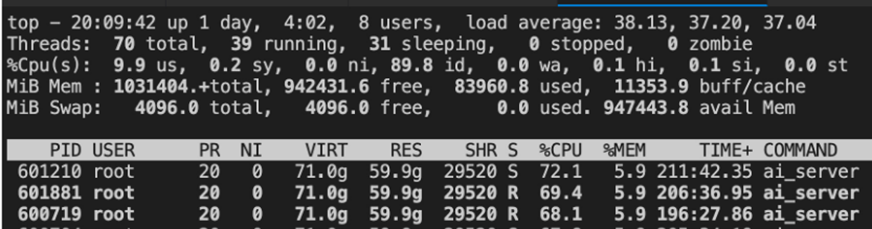
CPU使用率、CPU负载较为均衡,基本都在85%左右,如下图所示。
网络负载无明显瓶颈,中断无异常。
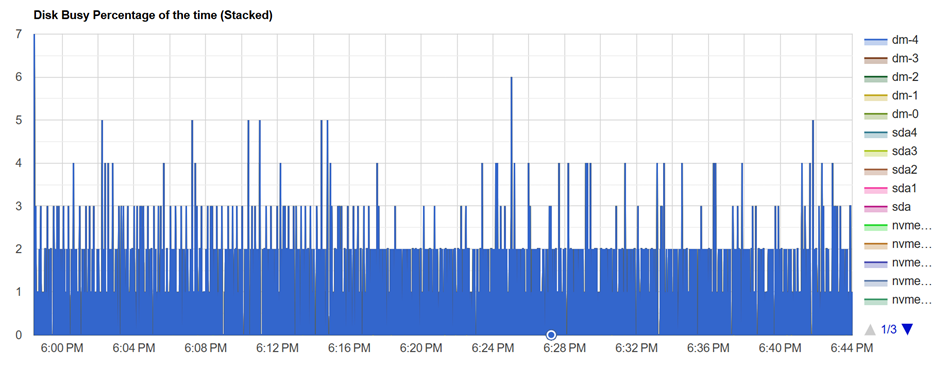
磁盘无明显瓶颈。
2.2 Perf 分析
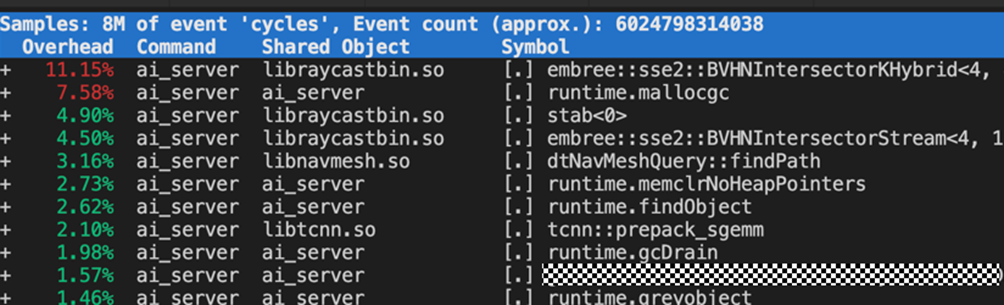
获取perf top分析,主要热点在embree相关函数intersect(11.15%)、occluded(4.5%),共计15.65%。其次为GO GC相关热点mallocgc(7.58%)、memclrNoHeapPointers(2.73%)、findObject(2.62%)、gcDrain(1.98%)、greyobject(1.46),共16.37%。
热点Embree 相关函数,已知在3.13.5版本上新增了neon2x特性,使能后在blender场景会有8%左右的提升。GO GC相关函数,目前暂无有效的优化手段。其余热点为客户闭源代码,本次调优暂不涉及。
2.3 TopDown分析
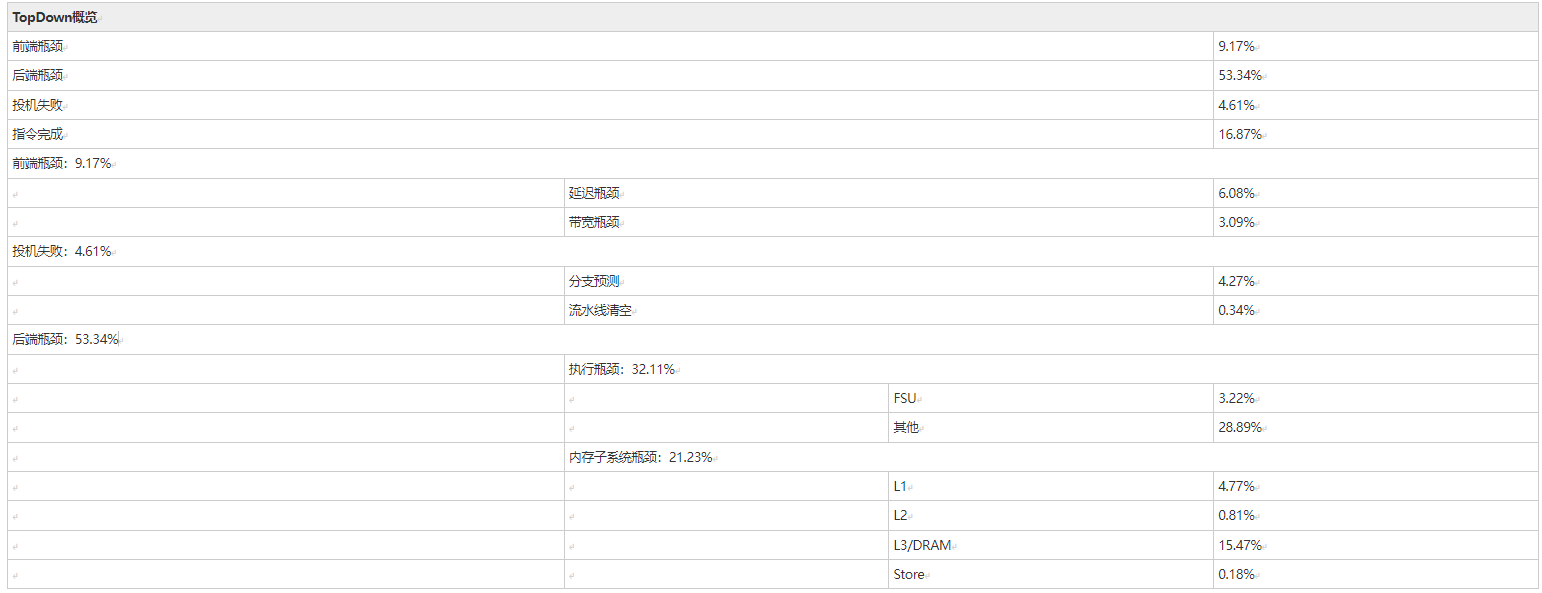
TopDown分析,当前瓶颈在后端瓶颈,其中内存子系统瓶颈占比21%(其中L3/DRAM为15.47)。可通过开启CPU预取提高性能(当前环境已开启)。
3.性能调优实践
3.1 BIOS调优
开启CPU性能模式,提高主频,发挥CPU最大性能。进入BIOS,依次选择“Advanced->Power and Performance Configuration->Power Policy”,将“Power Policy”修改为“Performance”。
3.2 OS调优
开启透明大页,提高TLB命中率。命令 echo always >
/sys/kernel/mm/transparent_hugepage/enabled
3.3 GO调优
GODEBUG 参数增加 disablethp=0 ,确保应用能使用到透明大页。
lGOGC=200经过测试验证,应用在40vCore场景下内存占比在80G以下,符合核存比要求。
3.4 EMBREE调优
升级embree版本到3.13.5。该版本增加ARM优化特性neon2x,使能avx2neon加速业务处理。
GCC 编译优化:
#修改common/cmake/gnu.cmake 增加编译选项
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -funroll-loops")
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -march=armv8.5-a+bf16+i8mm -mtune=neoverse-n1 -Wl,-q")
SET(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} -fuse-ld=gold")
// 修改kernels/common/device.cpp
// 第72行修改为
case CPU::ARM: frequency_level = FREQUENCY_SIMD256; break;
// 建立build 目录
make -p build && cd build
# 编译
cmake .. -DCMAKE_C_COMPILER=gcc -DCMAKE_CXX_COMPILER=g++ -DCMAKE_BUILD_TYPE=Release -DEMBREE_ISPC_SUPPORT=OFF -DEMBREE_BACKFACE_CULLING=ON -DEMBREE_RAY_MASK=ON -DEMBREE_TUTORIALS=OFF -DEMBREE_MAX_ISA=NEON2X -DEMBREE_ARM=ON -DEMBREE_TASKING_SYSTEM=INTERNAL -DEMBREE_STATIC_LIB=ON
make -j // 下载毕昇编译器版本并安装,安装可以参考链接
// 修改kernels/common/device.cpp
// 第72行修改为
case CPU::ARM: frequency_level = FREQUENCY_SIMD256; break;
// 建立build 目录
make -p build && cd build
// 编译
cmake .. -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DCMAKE_BUILD_TYPE=Release -DEMBREE_ISPC_SUPPORT=OFF -DEMBREE_BACKFACE_CULLING=ON -DEMBREE_RAY_MASK=ON -DEMBREE_TUTORIALS=OFF -DEMBREE_MAX_ISA=NEON2X -DEMBREE_ARM=ON -DEMBREE_TASKING_SYSTEM=INTERNAL -DEMBREE_STATIC_LIB=ON
make -j
3.5 优化措施
本小节提供未实施的调优措施,用户可根据业务特点选择使用。
GCC
叠加BOLT优化:
# 对编译好的二进制或.so文件,进行轻量级的采样再进行二进制或.so优化
# 安装bolt工具
yum install llvm-bolt
# 在之前二进制编译中加入-Wl,-q(重定位信息)
# 执行应用,并采集<pid>进程的perf信息,采集30s
perf record -p <pid> -- sleep 30
# 如果二进制执行时间短,可以采集完整过程
perf record -- ./embree_raycast ../Highrise.obj ../input.txt
# 生成bolt.profile文件
perf2bolt -p=perf.data ./embree_raycast -o bolt.profile -nl
# bolt二进制到二进制优化(如./embree_raycast新优化出 ./embree_raycast_bolt)
llvm-bolt -reorder-blocks=cache+ -reorder-functions=hfsort+ -split-functions=3 -split-all-cold -dyno-stats -icf=1 -use-gnu-stack --inline-all --update-debug-sections -data bolt.profile ./embree_raycast -o ./embree_raycast_bolt
GCC叠加LTO优化(编译链接时间会增加一些):
# 修改common/cmake/gnu.cmake 增加编译选项,再执行EMBREE编译
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -flto")
4.调优效果
经过调优后,基线版本40vCore的并发性能从1669提升到1821,并发性能提高9%。基于调优版本的测试结果,预估整机并发性能为14568。
|
版本 |
并发性能 |
性能提升(%) |
超时率(%) |
CPU使用率(%) |
内存使用(GB) |
|---|---|---|---|---|---|
|
基线版本(40vCore) |
1669 |
0% |
1.26 |
85% |
59.58 |
|
调优版本(40vCore) |
1821 |
9% |
0.88 |
85% |
64.14 |
|
调优版本(320vCore预估) |
14568 |
NA |
NA |
NA |
NA |
5.总结
本次验证的鲲鹏ARM平台7282c芯片性能较好,体现鲲鹏平台在AI游戏场景有一定的竞争力。
|
型号 |
规格 |
并发性能 |
单核线程数 |
单物理核并发数 |
|---|---|---|---|---|
|
Kunpeng-arm |
40vCore/80G(kunpeng-7282c) |
1821 |
2 |
91 |