


wrf精度调优介绍
发表于 2025/10/15
0
1 WRF介绍
WRF(Weather Research and Forecasting Model),是一个天气研究与预报模型,可以用来进行精细尺度的天气模拟与预报,是高性能计算(High-Performance Computing)应用的重要场景之一。天气预报不仅关系到日常企业生产、人民生活,还关系到防灾减灾,最大程度保护人民生命财产的安全,因此,天气预报非常重视预报结果的准确性和稳定性。
2 计算精度产生差异的场景
在气象局的招标活动中,为确保新集群环境更准确、更稳定、更快速投入生产,气象局客户都会提出要求:新建集群的预报结果必须与现有集群结果保持一致。气象局过往在更换集群服务器时,都经历了大量人力进行优化,以满足计算结果与以前保持一致。因此气象集群迁移到鲲鹏平台时,也可能会出现运行结果与现有的集群运行结果不一致的现象。
不仅仅是气象领域,在高性能计算程序中,更换集群,更换不同架构的CPU,更换编译器都有可能出现结果不一致的现象。一个细小的差异经过高性能计算中大量的迭代计算会不断累积放大,最终导致计算结果差异很大。
3 计算精度产生差异的来源
3.1 芯片架构差异
从底层架构来看,鲲鹏处理器和x86的芯片架构不同,如x86设计有40位、80位的浮点计算单元,在鲲鹏处理器上并没有这些计算单元。如果x86平台有使用到这些计算单元,就会导致两个平台的计算结果不一致。目前可以在鲲鹏平台上通过软件模拟的方式来解决这类问题引起的差异。例如icc的数学库使用了powr8i4函数,该函数调用了x86的80位指令,即用80位来表示浮点数。在鲲鹏平台上可以使用支持多种精度计算的开源MPFR(Multiple Precision Floating-Point Reliable)库来实现80位浮点数的pow运算。
3.1.1 FTZ(Flush-to-Zero)和DAZ(Denormals-are-Zero):
FTZ和DAZ是专门用来处理非规格化浮点数的标准。FTZ表示浮点运算结果输出为非规格化浮点数时转化为0,DAZ表示输入为非规格化浮点数时转化为0。FTZ转化动作由硬件完成,能够加快非规范浮点数的计算速度。有如下示例代码:
float a = 1.0e-5 * 1.0e-38;
cout << "a = " << a << endl;在不使能FTZ功能下,即-no-ftz时,输出为:
a = 9.94922e-44使能FTZ功能下,gcc增加-ffast-math编译选项即使能FTZ,或者-ftz,输出为:
a = 03.1.2 浮点数转换溢出
浮点数转换为整数类型时,通常会保留整数部分,截取掉小数部分。当浮点数太大,整数类型无法表示浮点数的整数部分时,鲲鹏和x86的行为是不一致的,鲲鹏对于上溢或下溢的行为处理非常清晰和简单,即保留整数部分能表示的最大值或最小值。x86则定义了一个不确定数值(indefinite integer value)来表示溢出值。双精度转换的不确定数值为:0x8000 0000 0000 0000,单精度转换的不确定数值为:0x8000 0000。有下面示例代码:
double a = 1.0e20;
long b = static_cast<long>(a);
std::cout << "b = " << b << std::endl;鲲鹏平台下输出结果为:
b = 9223372036854775807x86平台下输出结果为:
b = -9223372036854775807上面示例中1.0e20超出long能够表示的最大值,鲲鹏平台上把long能够表示的最大整数赋值给b = 9223372036854775807(0x7FFF FFFF FFFF FFFF)。x86平台上把双精度转换的不确定数值赋值给b = -9223372036854775807(0x8000 0000 0000 0000)。
3.2 编译器差异
3.2.1 编译选项-fp-model
icc编译器(Intel C++ Compiler)的编译选项-fp-model是用来控制浮点数是否值安全(value-safe),即编译器是否进行在数学逻辑上相等的运算转换,当浮点运算不是值安全时可能会产生计算结果差异。-fp-model默认的选项是fast=1,在-O2及以上优化等级上默认开启。可以指定-fp-model=precise来保证浮点运算是值安全的。
浮点数无法准确表示实数,鲲鹏和x86的默认舍入方式都采用舍入到最接近的实数。舍入带来精度损失,会导致计算机的运算不一定符合数学逻辑上的运算。例如A + B + C 不一定等于 A + ( B + C ),如下面代码所示:
float a = -0.1;
float b = 0.1;
float c = -0.00000000149012;
float sum1 = a + b + c;
float sum2 = a + (b + c);
std::cout << "sum1 = " << sum1 << std::endl;
std::cout << "sum2 = " << sum2 << std::endl;输出结果为:
sum1 = -1.49012e-09
sum2 = 0按照数学运算结果sum1应该等于sum2,问题出现在(b + c)计算上,c(-0.00000000149012)约等于b(0.1)的ULP的五分之一,按照舍入到最近的数的方式,c将会被舍去,(b + c) = b,因此sum2 = a + b = -0.1 + 0.1= 0。
编译器会对代码进行性能优化,有时会隐式打乱计算顺序。而不同的编译器有不同优化策略,会导致在一样的代码下,使用不同的编译器运行结果也会不同。有下面示例代码:
#include <iostream>
float a[4 * 4] = {0};
float sum = 0;
void main ()
{
a[0] = 0.1;
a[1] = -0.1;
a[2] = 0.00000000149012;
for (int i = 0; i < 4 * 4; i++) {
sum += a[i];
}
std::cout << "sum = " << sum << std::endl;
}在icc -O3条件下,输出结果为:
sum = 0在g++ -O3条件下,输出结果为:
sum = 1.49012e-09icc的计算结果跟上个示例中a + (b + c)结果一样。因为在-O3优化等级下,icc默认开启-fp-model=fast,对a[i]进行了向量化优化时,进行了符合数学逻辑运算的转换,导致计算没有按照a[0] + a[1] + a[2]...顺序进行,而gcc编译器则没有进行向量化优化,保持a[0] + a[1] + a[2]...的计算顺序,所以两者结果出现不一致的现象。
在icc -O3 -fp-model=precise条件下,输出结果为:
sum = 1.49012e-09icc编译器在-fp-model=precise使能情况下,会禁止包括但不限于下面的数学逻辑相等的运算转换:
a + b + c → a + (b + c) 、x * 0 → 0 、x + 0 → 0 、A / B → A * (1 / B)
3.2.2 立即数
立即数在代码中是显式表示的数,对于未定义类型的立即数,其加载到内存的值在IEEE 754中未作具体的定义,因此不同的编译器对立即数加载有不同实现时,有时会导致立即数在内存的数值不一致,有下面示例代码:
program test
real (8) :: x
x = 0.002362E12
write(*, '(Z16)') x
end使用gcc编译,输出为:
41E1992840000000使用icc编译,输出为:
41E1992860000000指定立即数类型为双精度浮点数就不会出现差异:
program test
real (8) :: x
x = 0.002362E12_8 ! 指定类型为双精度
write(*, '(Z16)') x
end使用gcc编译,输出为:
41E1992850000000使用icc编译,输出为:
41E19928500000003.3 数学库差异
如果函数在任何情况下产生的误差总是小于0.5ulp,那么说明这个函数总是能够返回最接近精确结果的近似值。但是目前没有统一的标准去约束数学库中log、sin、pow等函数的输出,因此不同的数学库中的函数实现可能具有不一样的舍入模式和精度计算。有下面示例代码:
program test
real::x, y, z
x = 0.699129045
y = 1.4
z = x ** y
print*, z
end使用系统数学库libm.so.6编译,输出结果为:
0.605871201使用鲲鹏数学库libkm.so编译,输出结果为:
0.6058711413.4 应用代码引起的差异
3.4.1 WRF网格划分引起的差异
有如下代码:
ht_loc(its-1, j) = max(ht_loc(its-1, j), ht_shad(its-1, j))
ht_loc(ite-1, j) = max(ht_loc(ite-1, j), ht_shad(ite-1, j))
ht_loc(i, jts-1) = max(ht_loc(i, jts-1), ht_shad(i, jts-1))
ht_loc(i, jte-1) = max(ht_loc(i, jte-1), ht_shad(i, jte-1))代码中的its、ite、jts、jte变量表示网格区域范围,其划分范围跟使用的进程数有关,进程数越多时,每个进程分配的网格区域范围越小,反之分配的网格区域范围越大。当更改测试规模时(测试节点数、、测试进程数、测试线程数),its、ite、jts、jte变量值发生改变,变量ht_loc也一同改变,经过多次迭代运算后,整个程序的输出结果也发生改变。
以conus12km算例为例,具体实测划分如下:

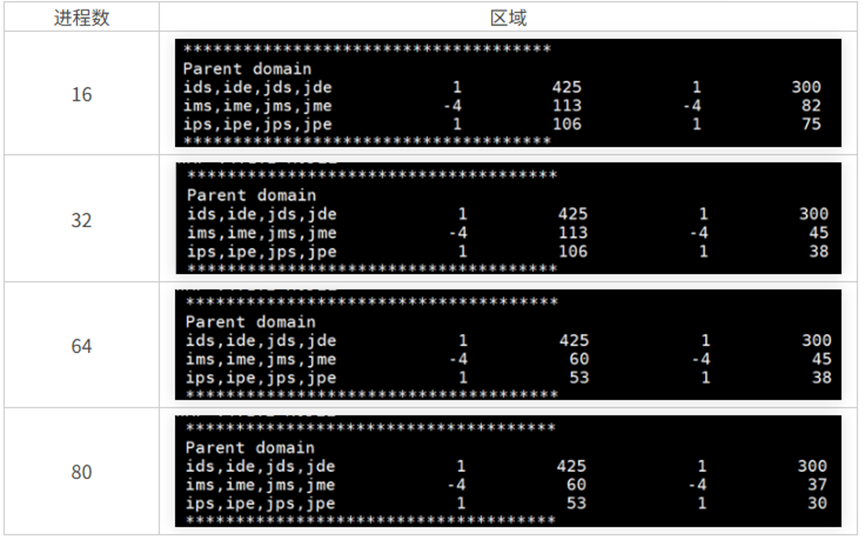
4 消除计算结果差异的措施
4.1 使用精度友好的编译选项
icc编译器的-fp-model编译选项用来控制浮点运算的优化,其影响程序的运行性能和结果的准确性。选用性能更好的优化选项,必然会带来精度上的损失。
在优化等级为-O2及以上时,-fp-model默认选项是fast=1,在优化等级为-Ofast时,-fp-model默认选项是fast=2,这表示编译器对浮点运算应用更多的性能优化。为了获取更高的浮点计算精度,设置-fp-model=precise,保证运算过程中浮点数是值安全的(value-safe),即编译器不会进行在数学逻辑上相等的运算转换,如前文提到的A + B + C转换为A + ( B + C )。当然,更改后可能影响程序性能,这需要开发人员作出权衡。
毕昇编译器同样有编译选项-ffp-contract= off/on/fast控制浮点运算优化。-ffp-contract默认选项是fast,使能浮点数乘加操作,将乘法和加法合并为一条乘加运算从而提升性能。为了获得更高的浮点计算精度,可以设置-ffp-contract= off。
4.1.1 修改建议
- 毕昇编译器增加编译选项-ffp-contract=off。
- icc编译器增加编译选项-fp-model=precise。
4.2 关闭FTZ和DAZ
不使能FTZ选项会带来更好的精度。icc编译器中-ftz会在除了-O0的其他-O优化等级上默认打开,可以使用-no-ftz编译选项选择关闭;毕昇编译器在-ffast-math或-Ofast下使能FTZ,也可以通过-fflushz或-Mflushz(仅对flang有效)选项单独开启FTZ功能;gcc只在-ffast-math下使能FTZ。
4.2.1 修改建议
- 毕昇编译器去掉-ffast-math、-fflushz和-Mflushz其中一个编译选项。
- icc编译器增加编译选项-no-ftz,或者去掉-ftz编译选项。
- gcc编译器去掉-ffast-math编译选项。
4.3 使用鲲鹏数学库kml
鲲鹏数学库(Kunpeng Math Library,以下简称KML)提供了基于鲲鹏平台优化的高性能数学函数,所有接口由C/C++、汇编语言实现,部分接口提供Java语言封装的接口。KML基于鲲鹏架构,通过向量化、数据预取、编译优化、数据重排、内联汇编、算法优化等手段优化代码,以获取极高的运行性能。KML不单针对鲲鹏平台进行深度性能优化,同样在精度方面也经过全面的测试验证。
4.4 修改代码中未定义行为
代码中的未定义行为在不同的场景下执行的结果是不确定的。该问题类型较多,主要的修改思路为综合考虑平台架构、编译器等的差异,增加限定条件保证代码行为一致。如指定立即数数据类型,修改代码数组越界等bug,运行参数保持一致等。
5 误差的计算方法
不同的高性能计算程序有不同的方法去度量结果的准确性。下面介绍通用的误差计算方法,也是WRF使用的方法。
下列公式中的x、y表示待比较的两个数据集。
平均误差ME(Mean Error):数值越小越好。
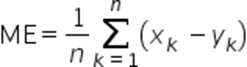
平均绝对误差MAE(Mean Absolute Error):数值越小越好,0代表完全一致。
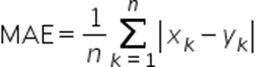
均方根误差RMSE(Root Mean Square Error):表示两个结果的相对偏差大小,数值越小说明两者越接近,0表示完全一致。
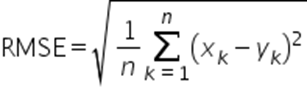
空间相关系数SCC(Space Correlation Coefficient,即pearson相关系数):用来衡量两个数据集是否在一条线上面,它用来衡量定距变量间的线性关系。若相关系数等于0,只能说x与y之间无线性相关关系。相关系数的绝对值越大,相关性越强,相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
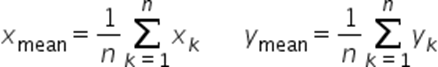
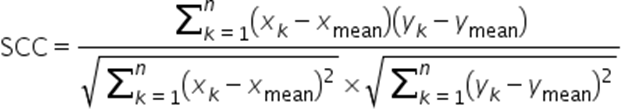
6 WRF结果差异对比方法
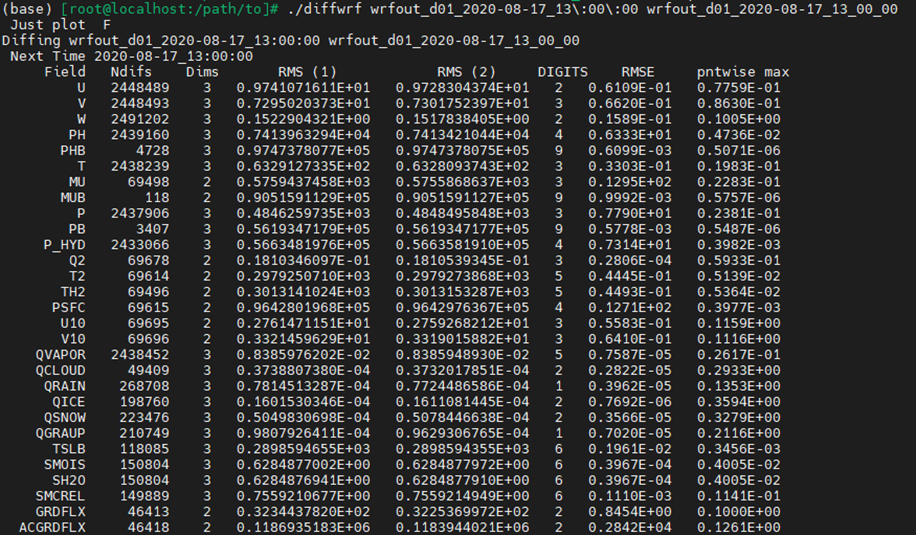
6.1.1 diffwrf
WRF自带工具,能够对比两个WRF数据集的差异。
diffwrf一般所在路径:path/to/WRF/external/io_netcdf
6.1.2 量化评估python脚本
注:修改path为wrfout文件路径
import numpy as np
import sys
from netCDF4 import Dataset
path = '/path/to/wrfout'
file1 = sys.argv[1]
file2 = sys.argv[2]
dataset_920 = Dataset(f'{path}/{file1}')
dataset_x86 = Dataset(f'{path}/{file2}')
u_920 = dataset_920.variables['U10'][0, :, :]
v_920 = dataset_920.variables['V10'][0, :, :]
u_x86 = dataset_x86.variables['U10'][0, :, :]
v_x86 = dataset_x86.variables['V10'][0, :, :]
diff_u = np.abs(u_920 - u_x86)
diff_v = np.abs(v_920 - v_x86)
print("mean diff u:{}".format(np.mean(diff_u)))
print("mean diff v:{}".format(np.mean(diff_v)))
print("max diff u:{}".format(np.max(diff_u)))
print("max diff v:{}\n".format(np.max(diff_v)))