


openGauss数据库源码解析系列文章——SQL引擎源码解析(三)
发表于 2025/10/20
0
物理路径
在数据库中,路径使用path结构体来表示,path结构体“派生”自Node结构体,path结构体同时也是一个“基”结构体,类似于C++中的基类,每个具体路径都从path结构体中“派生”,例如索引扫描路径使用的IndexPath结构体就是从path结构体中“派生”的。
typedef struct Path
{
NodeTag type;
NodeTag pathtype; /* 路径的类型,可以是T_IndexPath、T_NestPath等 */
RelOptInfo *parent; /* 当前路径执行后产生的中间结果 */
PathTarget *pathtarget; /* 路径的投影,也会保存表达式代价*/
/* 需要注意表达式索引的情况*/
ParamPathInfo *param_info; /* 执行期使用参数,在执行器中,子查询或者一些特殊*/
/* 类型的连接需要实时的获得另一个表的当前值 */
Bool parallel_aware; /* 并行参数,区分并行还是非并行 */
bool parallel_safe; /* 并行参数,由set_rel_consider_parallel函数决定 */
int parallel_workers; /* 并行参数,并行线程的数量 */
double rows; /* 当前路径执行产生的中间结果估计有多少数据 */
Cost startup_cost; /* 启动代价,从语句执行到获得第一条结果的代价 */
Cost total_cost; /* 当前路径的整体执行代价 */
List *pathkeys; /* 当前路径产生的中间结果的排序键值,如果无序则为NULL */
} Path;
1.1.1 (四) 动态规划
目前openGauss已经完成了基于规则的查询重写优化和逻辑分解优化,并且已经生成各个基表的物理路径。基表的物理路径仅仅是优化器规划中很小的一部分,现在openGauss将进入优化器优化的另一个重要的工作,即生成Join连接路径。openGauss采用的是自底向上的优化方式,对于多表连接路径主要采用的是动态规划和遗传算法两种方式。这里主要介绍动态规划的方式,但如果表数量有很多,就需要用遗传算法。遗传算法可以避免在表数量过多情况下带来的连接路径搜索空间膨胀的问题。对于一般场景采用动态规划的方式即可,这也是openGauss默认采用的优化方式。
经过逻辑分解优化后,语句中的表已经被拉平,即从原来的树状结构变成了扁平的数组结构。各个表之间的连接关系也被记录到了root目录下的SpecialJoinInfo结构体中,这些也是对连接做动态规划的基础。
1.1.2 1. 动态规划方法
首先动态规划方法适用于包含大量重复子问题的最优解问题,通过记忆每个子问题的最优解,使相同的子问题只求解一下,下次就可以重复利用上次子问题求解的记录即可,这就要求这些子问题的最优解能够构成整个问题的最优解,也就是说应该要具有最优子结构的性质。所以对于语句的连接优化来说,整个语句连接的最优解也就是某一块语句连接的最优解,在规划的过程中无法重复计算局部最优解,直接用上次计算的局部最优解即可。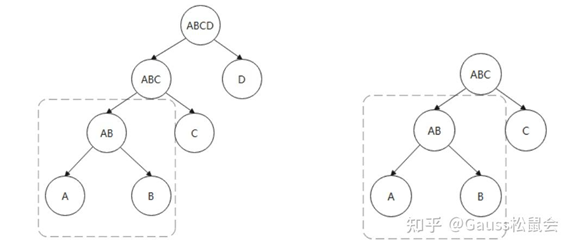
图1 重复子问题的最优解
例如,图1中两个连接树中A×B的连接操作就属于重复子问题,因为无论是生成A×B×C×D还是A×B×C连接路径的时候都需要先生成A×B连接路径,对于多表连接生成的路径即很多层堆积的情况下可能有上百种连接的方法,这些连接树的重复子问题数量会比较多,因此连接树具有重复子问题,可以一次求解多次使用,也就是对于连接A×B只需要一次生成最优解即可。
多表连接动态规划算法代码主要是从make_rel_from_joinlist函数开始的,如图2所示。 图2 多表连接动态规划算法
图2 多表连接动态规划算法
1.1.3 1) make_rel_from_joinlist函数
动态规划的实现代码主入口是从make_rel_from_joinlist函数开始的,它的输入参数是deconstruct_jointree函数拉平之后的RangeTableRef链表,每个RangeTableRef代表一个表,然后就可以根据这个链表来查找基表的RelOptInfo结构体,用查找到的RelOptInfo去构建动态规划连接算法一层中的基表RelOptInfo,后续再继续在这第1层RelOotInfo进行“累积”。代码如下:
//遍历拉平之后的joinlist,这个链表是RangeTableRef的链表
foreach(jl, joinlist)
{
Node *jlnode = (Node *) lfirst(jl);
RelOptInfo *thisrel;
//多数情况下都是RangeTableRef链表,根据RangeTableRef链表中存放的下标值(rtindex)
//查找对应的RelOptInfo
if (IsA(jlnode, RangeTblRef))
{
int varno = ((RangeTblRef *) jlnode)->rtindex;
thisrel = find_base_rel(root, varno);
}
//受到from_collapse_limit参数和join_collapse_limit参数的影响,也存在没有拉平的节点,这里递归调用make_rel_from_joinlist函数
else if (IsA(jlnode, List))
thisrel = make_rel_from_joinlist(root, (List *) jlnode);
else
ereport (……);
//这里就生成了第一个初始链表,也就是基表的链表,这个链表是
//动态规划方法的基础
initial_rels = lappend(initial_rels, thisrel);
}
1.1.4 2) standard_join_search函数
动态规划方法在累积表的过程中,每一层都会增加一个表,当所有的表都增加完毕的时候,最后的连接树也就生成了。因此累积的层数也就是表的数量,如果存在N个表,那么在此就要堆积N次,具体每一层堆积的过程在函数join_search_one_level中进行介绍,那么这个函数中主要做的还是为累积连接进行准备工作,包括分配每一层RelOptInfo所占用的内存空间以及每累积一层RelOptInfo后保留部分信息等工作。
创建一个“连接的数组”,类似于[LIST1, LIST2, LIST3]的结构,其中数组中的链表就用来保存动态规划方法中一层所有的RelOptInfo,例如数组中的第一个链表存放的就是有关所有基表路径的链表。代码如下:
//分配“累积”过程中所有层的RelOptInfo链表
root->join_rel_level = (List**)palloc0((levels_needed + 1) * sizeof(List*));
//初始化第1层所有基表RelOptInfo
root->join_rel_level[1] = initial_rels;
做好了初始化工作之后,就可以开始尝试构建每一层的RelOptInfo。代码如下:
for (lev = 2; lev <= levels_needed; lev++) {
ListCell* lc = NULL;
//在join_search_one_level函数中生成对应的lev层的所有RelOptInfo
join_search_one_level(root, lev);
……
}
1.1.5 3) join_search_one_level函数
join_search_one_level函数主要用于生成一层中的所有RelOptInfo,如图3所示。如果要生成第N层的RelOptInfo主要有三种方式:一是尝试生成左深树和右深树,二是尝试生成浓密树,三是尝试生成笛卡儿积的连接路径(俗称遍历尝试)。 图3 生成第N层的RelOptInfo方式
图3 生成第N层的RelOptInfo方式
1.1.6 (1) 左深树和右深树。
左深树和右深树生成的原理是一样的,只是在make_join_rel函数中对候选出的待连接的两个RelOptInfo进行位置互换,也就是每个RelOptInfo都有一次作为内表或作为外表的机会,这样其实创造出更多种连接的可能有助于生成最优路径。
如图4所示两个待选的RelOptInfo要进行连接生成A×B×C,左深树也就是对A×B和C进行了一下位置互换,A×B作为内表形成了左深树,A×B作为外表形成了右深树。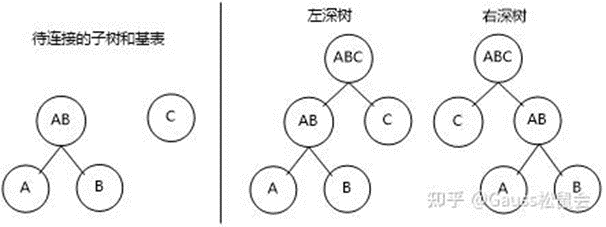 图4 左深树和右深树示意图
图4 左深树和右深树示意图
具体代码如下:
//对当前层的上一层进行遍历,也就是说如果要生成第4层的RelOptInfo
//就要取第3层的RelOptInfo和第1层的基表尝试做连接
foreach(r, joinrels[level - 1])
{
RelOptInfo *old_rel = (RelOptInfo *) lfirst(r);
//如果两个RelOptInfo之间有连接关系或者连接顺序的限制
//优先给这两个RelOptInfo生成连接
// has_join_restriction函数可能误判,不过后续还会有更精细的筛查
if (old_rel->joininfo != NIL || old_rel->has_eclass_joins ||
has_join_restriction(root, old_rel))
{
ListCell *other_rels;
//要生成第N层的RelOptInfo,就需要第N-1层的RelOptInfo和1层的基表集合进行连接
//即如果要生成第2层的RelOptInfo,那么就变成第1层的RelOptInfo和第1层的基表集合进行连接
//因此,需要在生成第2层基表集合的时候做一下处理,防止自己和自己连接的情况
if (level == 2)
other_rels = lnext(r);
else
other_rels = list_head(joinrels[1]);
//old_rel“可能”和其他表有连接约束条件或者连接顺序限制
//other_rels中就是那些“可能”的表,make_rels_clause_joins函数会进行精确的判断
make_rels_by_clause_joins(root, old_rel, other_rels);
}
else
{
//对没有连接关系的表或连接顺序限制的表也需要尝试生成连接路径
make_rels_by_clauseless_joins(root, old_rel, list_head(joinrels[1]));
}
}
1.1.7 (2) 浓密树。
要生成第N层的RelOptInfo,左深树或者右深树是将N-1层的RelOptInfo和第1层的基表进行连接,不论是左深树,还是右深树本质上都是通过引用基表RelOptInfo去构筑当前层RelOptInfo。而生成浓密树抛开了基表,它是将各个层次的RelOptInfo尝试进行随意连接,例如将第N-2层RelOptInfo和第2层的RelOptInfo进行连接,依次可以类推出(2,N﹣2)、(3,N﹣3)、(4, N﹣4)等多种情况。浓密树的建立要满足两个条件:一是两个RelOptInfo要存在相关的约束条件或者存在连接顺序的限制,二是两个RelOptInfo中不能存在有交集的表。
for (k = 2;; k++)
{
int other_level = level - k;
foreach(r, joinrels[k])
{
//有连接条件或者连接顺序的限制
if (old_rel->joininfo == NIL && !old_rel->has_eclass_joins &&
!has_join_restriction(root, old_rel))
continue;
……
for_each_cell(r2, other_rels)
{
RelOptInfo *new_rel = (RelOptInfo *) lfirst(r2);
//不能有交集
if (!bms_overlap(old_rel->relids, new_rel->relids))
{
//有相关的连接条件或者有连接顺序的限制
if (have_relevant_joinclause(root, old_rel, new_rel) ||
have_join_order_restriction(root, old_rel, new_rel))
{
(void) make_join_rel(root, old_rel, new_rel);
}
}
}
}
}
1.1.8 (3) 笛卡儿积。
在尝试过左深树、右深树以及浓密树之后,如果还没有生成合法连接,那么就需要努力对第N﹣1层和第1层的RelOptInfo做最后的尝试,其实也就是将第N﹣1层中每一个RelOptInfo和第1层的RelOptInfo合法连接的尝试。
1.1.9 2. 路径生成
前面已经介绍了路径生成中使用的动态规划方法,并且介绍了在累积过程中如何生成当前层的RelOptInfo。对于生成当前层的RelOptInfo会面临几个问题:一是需要判断两个RelOptInfo是否可以进行连接,二是生成物理连接路径。目前物理连接路径主要有三种实现,分别是NestLoopJoin、HashJoin和MergeJoin,建立连接路径的过程就是不断地尝试生成这三种路径的过程。
1.1.10 1) 检查
在动态规划方法中需要将N-1层的每个RelOptInfo和第1层的每个RelOptInfo尝试做连接,然后将新连接的RelOptInfo保存在当前第N层,算法的时间复杂度在O(M×N)左右,如果发生第N-1层和第1层中RelOptInfo都比较多的情况下,搜索空间会膨胀得比较大。但有些RelOptInfo在做连接的时候是可以避免掉的,这也是我们需要及时检查的目的,提前检测出并且跳过两个RelOptInfo之间的链接,会节省不必要的开销,提升优化器生成优化的效率。
1.1.11 (1) 初步检查。
下面几个条件是初步检查主要进行衡量的因素。
一是RelOptinfo中joininfo不为NULL。那就说明这个RelOptInfo和其他的RelOptInfo存在相关的约束条件,换言之就是说当前这个RelOptInfo可能和其他表存在关联。
二是RelOptInfo中has_eclass_joins为true,表明在等价类的记录中当前RelOptInfo和其他RelOptInfo可能存在等值连接条件。
三是has_join_restriction函数的返回值为true,说明当前的RelOptInfo和其他的RelOptInfo有连接顺序的限制。
初步检查就是利用RelOptInfo的信息进行一种“可能性”的判断,主要是检测是否有连接条件和连接顺序的约束。
static bool has_join_restriction(PlannerInfo* root, RelOptInfo* rel)
{
ListCell* l = NULL;
//如果当前RelOptInfo涉及Lateral语义,那么就一定有连接顺序约束
foreach(l, root->lateral_info_list)
{
LateralJoinInfo *ljinfo = (LateralJoinInfo *) lfirst(l);
if (bms_is_member(ljinfo->lateral_rhs, rel->relids) ||
bms_overlap(ljinfo->lateral_lhs, rel->relids))
return true;
}
//仅处理除内连接之外的条件
foreach (l, root->join_info_list) {
SpecialJoinInfo* sjinfo = (SpecialJoinInfo*)lfirst(l);
//跳过全连接检查,会有其他机制保证其连接顺序
if (sjinfo->jointype == JOIN_FULL)
continue;
//如果这个SpecialJoinInfo已经被RelOptInfo包含就跳过
if (bms_is_subset(sjinfo->min_lefthand, rel->relids) &&
bms_is_subset(sjinfo->min_righthand, rel->relids))
continue;
//如果RelOptInfo结构体的relids变量和min_lefthand变量或min_righthand变量有交集,那么它就有可能有连接顺序的限制
if (bms_overlap(sjinfo->min_lefthand, rel->relids) ||
bms_overlap(sjinfo->min_righthand, rel->relids))
return true;
}
return false;
}
1.1.12 (1) 精确检查。
在进行了初步检查之后,如果判断出两侧RelOptInfo不存在有连接条件或者连接顺序的限制,那么就进入make_rels_by_clauseless_joins函数中,将RelOptInfo中所有可能的路径和第1层RelOptInfo进行连接。如果当前RelOptInfo可能有连接条件或者连接顺序的限制,那么就会进入make_rel_by_clause_joins函数中,会逐步将当前的RelOptInfo和第1层其他RelOptInfo进一步检查以确定是否可以进行连接。
在have_join_order_restriction函数判断两个RelOptInfo是否具有连接顺序的限制,主要从两个方面判断是否具有连接顺序的限制:一是判断两个RelOptInfo之间是否具有Lateral语义的顺序的限制,二是判断SpecialJoinInfo中的min_lefthand和min_righthand是否对两个RelOptInfo具有连接顺序的限制。
对have_join_order_restriction部分源码分析如下:
bool have_join_order_restriction(PlannerInfo* root, RelOptInfo* rel1, RelOptInfo* rel2)
{
bool result = false;
ListCell* l = NULL;
//如果有Lateral语义的依赖关系,则一定具有连接顺序的限制
foreach(l, root->lateral_info_list)
{
LateralJoinInfo *ljinfo = (LateralJoinInfo *) lfirst(l);
if (bms_is_member(ljinfo->lateral_rhs, rel2->relids) &&
bms_overlap(ljinfo->lateral_lhs, rel1->relids))
return true;
if (bms_is_member(ljinfo->lateral_rhs, rel1->relids) &&
bms_overlap(ljinfo->lateral_lhs, rel2->relids))
return true;
}
//遍历root目录中所有SpecialJoinInfo,判断两个RelOptInfo是否具有连接限制
foreach (l, root->join_info_list) {
SpecialJoinInfo* sjinfo = (SpecialJoinInfo*)lfirst(l);
if (sjinfo->jointype == JOIN_FULL)
continue;
//"最小集"分别是两个表的子集,两个表需要符合连接顺序
if (bms_is_subset(sjinfo->min_lefthand, rel1->relids) &&
bms_is_subset(sjinfo->min_righthand, rel2->relids)) {
result = true;
break;
}
//反过来同上,"最小集"分别是两个表的子集,两个表需要符合连接顺序
if (bms_is_subset(sjinfo->min_lefthand, rel2->relids) &&
bms_is_subset(sjinfo->min_righthand, rel1->relids)) {
result = true;
break;
}
//如果两个表都和最小集的一端有交集,那么这两个表应该在这一端下做连接
//故让他们先做连接
if (bms_overlap(sjinfo->min_righthand, rel1->relids) && bms_overlap(sjinfo->min_righthand, rel2->relids)) {
result = true;
break;
}
//反过来同上
if (bms_overlap(sjinfo->min_lefthand, rel1->relids) && bms_overlap(sjinfo->min_lefthand, rel2->relids)) {
result = true;
break;
}
}
//如果两个表上和其他表有相对应的连接关系
//那么可以让他们先和具有连接关系的表进行连接
if (result) {
if (has_legal_joinclause(root, rel1) || has_legal_joinclause(root, rel2))
result = false;
}
return result;
}
1.1.13 (2) 合法连接。
由于RelOptInfo会导致搜索空间膨胀,如果上来就对两个RelOptInfo进行最终的合法连接检查会导致搜索时间过长,这也就是为什么要提前做初步检查和精确检查的原因,可以减少搜索时间其实达到了“剪枝”的效果。
对于合法连接,主要代码在join_is_legal中,它主要就是判断两个RelOptInfo可不可以进行连接生成物理路径,入参就是两个RelOpInfo。对于两个待选的RelptInfo,仍不清楚他们之间的逻辑连接关系,有可能是Inner Join、LeftJoin、SemiJoin,或者压根不存在合法的逻辑连接关系,故这时候就需要确定他们的连接关系,主要分成两个步骤。
步骤1:对root中join_info_list链表中的SpecialJoinInfo进行遍历,看是否可以找到一个“合法”的SpecialJoinInfo,因为除InnerJoin外的其他逻辑连接关系都会生成对应的一个SpecialJoinInfo,并在SpecialJoinInfo中还记录了合法的链接顺序。
步骤2:对RelOptInfo中的Lateral关系进行排查,查看找到的SpecialJoinInfo是否符合Lateral语义指定的连接顺序要求。
1.1.14 2) 建立连接路径
至此已经筛选出两个满足条件的RelOptInfo,那么下一步就是要对他们中的路径建立物理连接关系。通常的物理连接路径有NestLoop、Merge Join和Hash Join三种,这里主要是借由sort_inner_and_outer、match_unsorted_outer和hash_inner_and_outer函数实现的。
像sort_inner_and_outer函数主要是生成MergeJoin路径,其特点是假设内表和外表的路径都是无序的,所以必须要对其进行显示排序,内外表只要选择总代价最低的路径即可。而matvh_unsorted_outer函数则是代表外表已经有序,这时候只需要对内表进行显示排序就可以生成MergeJoin路径或者生成NestLoop以及参数化路径。最后的选择就是对两表连接建立HashJoin路径,也就是要建立哈希表。
为了方便MergeJoin的建立,首先需要对约束条件进行处理,故把适用于MergeJoin的约束条件从中筛选出来(select_mergejoin_clauses函数),这样在sort_inner_and_outer和match_unsorted_outer函数中都可以利用这个Mergejoinable连接条件。代码如下:
//提取可以进行Merge Join的条件
foreach (l, restrictlist) {
RestrictInfo* restrictinfo = (RestrictInfo*)lfirst(l);
//如果当前是外连接并且是一个过滤条件,那么就忽略
if (isouterjoin && restrictinfo->is_pushed_down)
continue;
//对连接条件是否可以做Merge Join进行一个初步的判断
//restrictinfo->can_join和restrictinfo->mergeopfamilies都是在distribute_qual_to_rels生成
if (!restrictinfo->can_join || restrictinfo->mergeopfamilies == NIL) {
//忽略FULL JOIN ON FALSE情况
if (!restrictinfo->clause || !IsA(restrictinfo->clause, Const))
have_nonmergeable_joinclause = true;
continue; /* not mergejoinable */
}
//检查约束条件是否是outer op inner或者inner op outer的形式
if (!clause_sides_match_join(restrictinfo, outerrel, innerrel)) {
have_nonmergeable_joinclause = true;
continue; /* no good for these input relations */
}
//更新并使用最终的等价类
//"规范化"pathkeys,这样约束条件就能和pathkeys进行匹配
update_mergeclause_eclasses(root, restrictinfo);
if (EC_MUST_BE_REDUNDANT(restrictinfo->left_ec) || EC_MUST_BE_REDUNDANT(restrictinfo->right_ec)) {
have_nonmergeable_joinclause = true;
continue; /* can't handle redundant eclasses */
}
result_list = lappend(result_list, restrictinfo);
}
1.1.15 (1) sort_inner_and_outer函数。
sort_inner_and_outer函数主要用于生成MergeJoin路径,它需要显式地对两个字RelOptInfo进行排序,只考虑子RelOptInfo中的cheapest_total_path函数即可。通过MergeJoinable(能够用来生成Merge Join的)的连接条件来生成pathkeys,然后不断地调整pathkeys中pathke的顺序来获得不同的pathkeys集合,再根据不同顺序的pathkeys来决定内表的innerkeys和外表的outerkeys。代码如下:
//对外表和内表中的每一条路径进行连接尝试遍历
foreach (lc1, outerrel->cheapest_total_path) {
Path* outer_path_orig = (Path*)lfirst(lc1);
Path* outer_path = NULL;
j = 0;
foreach (lc2, innerrel->cheapest_total_path) {
Path* inner_path = (Path*)lfirst(lc2);
outer_path = outer_path_orig;
//参数化路径不可生成MergeJoin路径
if (PATH_PARAM_BY_REL(outer_path, innerrel) ||
PATH_PARAM_BY_REL(inner_path, outerrel))
return;
//必须满足外表和内表最低代价路径
if (outer_path != linitial(outerrel->cheapest_total_path) &&
inner_path != linitial(innerrel->cheapest_total_path)) {
if (!join_used[(i - 1) * num_inner + j - 1]) {
j++;
continue;
}
}
//生成唯一化路径
jointype = save_jointype;
if (jointype == JOIN_UNIQUE_OUTER) {
outer_path = (Path*)create_unique_path(root, outerrel, outer_path, sjinfo);
jointype = JOIN_INNER;
} else if (jointype == JOIN_UNIQUE_INNER) {
inner_path = (Path*)create_unique_path(root, innerrel, inner_path, sjinfo);
jointype = JOIN_INNER;
}
//根据之前提取的条件确定可供MergeJoin路径生成的PathKeys集合
all_pathkeys = select_outer_pathkeys_for_merge(root, mergeclause_list, joinrel);
//处理上面pathkeys集合中每一个Pathkey尝试生成MergeJoin路径
foreach (l, all_pathkeys) {
……
//生成内表的Pathkey
innerkeys = make_inner_pathkeys_for_merge(root, cur_mergeclauses, outerkeys);
//生成外表的Pathkey
merge_pathkeys = build_join_pathkeys(root, joinrel, jointype, outerkeys);
//根据pathkey以及内外表路径生成MergeJoin路径
try_mergejoin_path(root, ……,innerkeys);
}
j++;
}
i++;
}
1.1.16 (2) match_unsorted_outer函数。
match_unsorted_outer函数大部分整体代码思路和sort_inner_and_outer一致,最主要的一点不同是sort_inner_and_outer是根据条件去推断出内外表的pathkey。而在match_unsorted_outer函数中,是假定外表路径是有序的,它是按照外表的pathkeys反过来排序连接条件的,也就是外表的pathkeys直接就可以作为outerkeys使用,查看连接条件中哪些是和当前的pathkeys匹配的并把匹配的连接条件筛选出来,最后再参照匹配出来的连接条件生成需要显示排序的innerkeys。
1.1.17 (3) hash_inner_and_outer函数。
顾名思义,hash_inner_and_outer函数的主要作用就是建立HashJoin的路径,在distribute_restrictinfo_to_rels函数中已经判断过一个约束条件是否适用于Hashjoin。因为Hashjoin要建立哈希表,至少有一个适用于Hashjoin的连接条件存在才能使用HashJoin,否则无法创建哈希表。
1.1.18 3) 路径筛选
至此为止已经生成了物理连接路径Hashjoin、NestLoop、MergeJoin,那么现在就是要根据他们生成过程中计算的代价去判断是否是一条值得保存的路径,因为在连接路径阶段会生成很多种路径,并会生成一些明显比较差的路径,这时候筛选可以帮助做一个基本的检查,能够节省生成计划的时间。因为如果生成计划的时间太长,即便选出了“很好”的执行计划,那么也是不能够接受的。
add_path为路径筛选主要函数。代码如下:
switch (costcmp) {
case COSTS_EQUAL:
outercmp = bms_subset_compare(PATH_REQ_OUTER(new_path),
PATH_REQ_OUTER(old_path));
if (keyscmp == PATHKEYS_BETTER1) {
if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET1) &&
new_path->rows <= old_path->rows)
//新路径代价和老路径相似,PathKeys要长,需要的参数更少
//结果集行数少,故接受新路径放弃旧路径
remove_old = true; /* new dominates old */
} else if (keyscmp == PATHKEYS_BETTER2) {
if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET2) &&
new_path->rows >= old_path->rows)
//新路径代价和老路径相似,pathkeys要短,需要的参数更多
//结果集行数更多,不接受新路径保留旧路径
accept_new = false; /* old dominates new */
} else {
if (outercmp == BMS_EQUAL) {
//到这里,新旧路径的代价、pathkeys、路径参数均相同或者相似
//如果新路径返回的行数少,选择接受新路径,放弃旧路径
if (new_path->rows < old_path->rows)
remove_old = true; /* new dominates old */
//如果新路径返回行数多,选择不接受新路径,保留旧路径
else if (new_path->rows > old_path->rows)
accept_new = false; /* old dominates new */
//到这里,代价、pathkeys、路径参数、结果集行数均相似
//那么就严格规定代价判断的范围,如果新路径好,则采用新路径,放弃旧路径
else {
small_fuzzy_factor_is_used = true;
if (compare_path_costs_fuzzily(new_path, old_path, SMALL_FUZZY_FACTOR) ==
COSTS_BETTER1)
remove_old = true; /* new dominates old */
else
accept_new = false; /* old equals or
* dominates new */
}
//如果代价和pathkeys相似,则比较行数和参数,好则采用,否则放弃
} else if (outercmp == BMS_SUBSET1 &&
new_path->rows <= old_path->rows)
remove_old = true; /* new dominates old */
else if (outercmp == BMS_SUBSET2 &&
new_path->rows >= old_path->rows)
accept_new = false; /* old dominates new */
/* else different parameterizations, keep both */
}
break;
case COSTS_BETTER1:
//所有判断因为新路径均好于或者等于旧路径
//则接受新路径,放弃旧路径
if (keyscmp != PATHKEYS_BETTER2) {
outercmp = bms_subset_compare(PATH_REQ_OUTER(new_path),
PATH_REQ_OUTER(old_path));
if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET1) &&
new_path->rows <= old_path->rows)
remove_old = true; /* new dominates old */
}
break;
case COSTS_BETTER2:
//所有判断因素旧路径均差于或者等于新路径
//则不接受新路径,保留旧路径
if (keyscmp != PATHKEYS_BETTER1) {
outercmp = bms_subset_compare(PATH_REQ_OUTER(new_path),
PATH_REQ_OUTER(old_path));
if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET2) &&
new_path->rows >= old_path->rows)
accept_new = false; /* old dominates new */
}
break;
default:
/*
* can't get here, but keep this case to keep compiler
* quiet
*/
break;
}