


vLLM编译安装指导(openEuler 22.03&20.03 SP1)
发表于 2025/10/22
0
作者 | 李璐
介绍
本文主要介绍如何在openEuler操作系统上编译安装vLLM,并提供安装过程时遇到故障的解决方法。
安装方式
基于Arm安装GPU版本,需要NVIDIA的CUDA和PyTorch-GPU依赖,提供两种安装方式:
1. 使用CUDA 12.4+Torch>=2.4(nightly版本)安装vLLM 0.6.3版本(PyTorch官方GPU版最低支持Torch 2.4)
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu124 # 最低版本支持Torch 2.4
git clone https://github.com/vllm-project/vllm.git
cd vllm
python use_existing_torch.py
pip install -r requirements-build.txt
pip install -e . --no-build-isolation bdist_wheel --cmake2. 基于源码安装。
本文以CUDA 11.8+PyTorch 2.1.2+vLLM 0.3.2版本为例安装。
环境要求
适用于openEuler 22.03、openEuler 20.03 SP1操作系统(此案例为鲲鹏服务器)。在编译安装vLLM前,需要根据操作系统版本先安装以下软件。
| 项目 | 版本 | |
| openEuler 22.03 | openEuler 20.03 SP1 | |
| openEuler内核 | 5.10 | 4.19 |
| NVIDIA驱动 | 支持CUDA 11.8以上 | CUDA 11.8+520.61.05 |
| CUDA | 11.8 | 11.8 |
| GCC | 10.3.1及以上 | 系统默认7.3.1,安装10.3.1 for openEuler(9.3.1以下版本会报错) |
| CMake | 3.18以上 | 系统默认3.16,手动安装3.22 |
| python3-dev | 3.10 | 3.10 |
| NumPy | <2.0.0 | <2.0.0 |
| Triton | - | Glibc 2.29以下版本操作系统均需要手动编译Triton和vLLM依赖 |
| LLVM | - | 17版本以上 |
编译准备
配置网络代理
1. 打开“/etc/profile”文件。
vi /etc/profile2. 按“i”进入编辑模式,在“/etc/profile”文件中增加以下内容。请根据实际情况填写用户名、密码、代理IP地址、代理端口等信息。
export http_proxy="http://用户名:密码@代理IP地址:代理端口"
export https_proxy=$http_proxy
export no_proxy=127.0.0.1,localhost,local,.local3. 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
4. 使代理生效。
source /etc/profile5. 使用curl命令访问任意网站,若能显示网站信息则表示代理配置成功。
安装CUDA及cuDNN
1. 请按照下图进行选择,获取DUDA安装包。
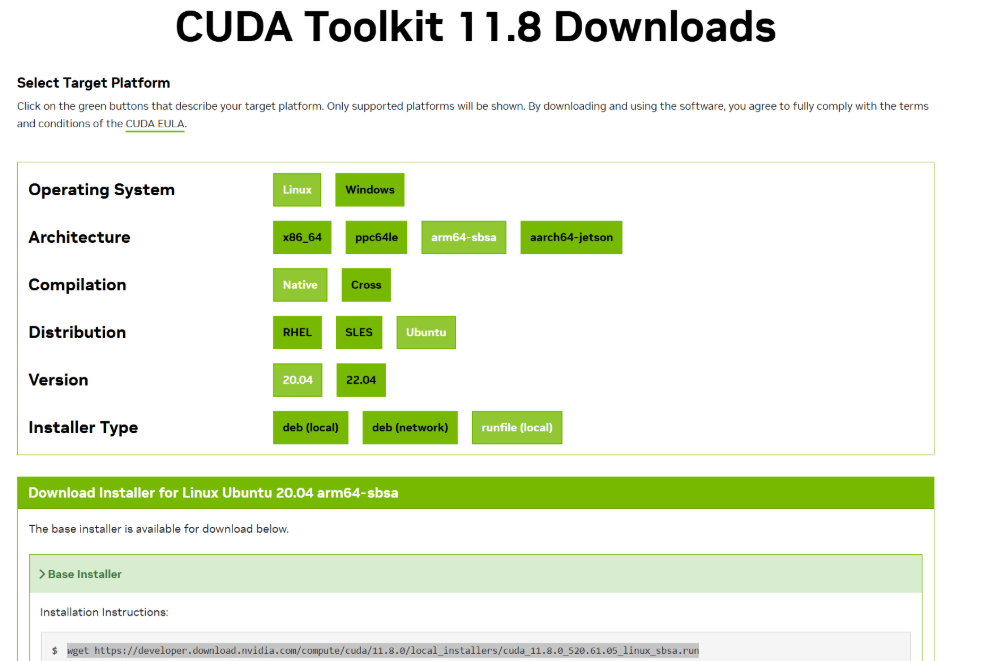
2. 安装CUDA。
sudo sh cuda_11.8.0_520.61.05_linux_sbsa.run3. 安装cuDNN,获取cuDNN安装包(需要登录NVIDIA账号)。
若使用RPM安装过程中报错,可以将RPM包解压,然后手动将include和lib文件夹复制到“usr/”对应目录下。此外,如果之前装过cuDNN,可以使用Yum安装。
yum search cudnn找到合适的版本(选择cuda11)
yum install cudnn安装依赖库
本文使用Python版本为3.10, vLLM官方兼容版本为3.9及以上,如果版本较低需要重新安装。
请不要删除原有的Python,否则Yum会出错,建议使用虚拟环境管理。
1. 安装必要依赖。
yum install wget zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel libffi-devel lzma-devel lzma gdbm-devel gdbm xz-devel gcc make -y2. 安装高版本OpenSSL,确保版本号不低于1.1.1g,否则_ssl模块编译会失败,以1.1.1.w版本为例。
2.1 下载并编译安装OpenSSL。
wget https://www.openssl.org/source/openssl-1.1.1w.tar.gz
tar -zxvf openssl-1.1.1w.tar.gz
cd openssl-1.1.1w
./config --prefix=/usr/local/openssl
make && make install2.2 配置新OpenSSL环境。
ln -s /usr/local/openssl/include/openssl /usr/include/openssl
ln -s /usr/local/openssl/lib/libssl.so.1.1 /usr/local/lib64/libssl.so
# 若提示路径不存在,可以直接创建
ln -s /usr/local/openssl/bin/openssl /usr/bin/openssl2.3 设置OpenSSL库文件的搜索路径。
echo "/usr/local/openssl/lib" >> /etc/ld.so.conf2.4 使修改后的“/etc/ld.so.conf”生效。
ldconfig -v2.5 查看OpenSSL版本。
openssl version3. 编译安装Python 3.10。
3.1 获取Python安装,解压并进入解压后目录。
export LD_LIBRARY_PATH=/usr/local/openssl/lib${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
wget https://www.python.org/ftp/python/3.10.0/Python-3.10.0.tgz
tar -xzvf Python-3.10.0.tgz
cd Python-3.10.03.2 编译安装。
./configure --prefix=/user/local/python3.10 --with-openssl=/usr/local/openssl
make -j$nproc
make install3.3 建立软链接。
ln -s /usr/bin/python3.10 /usr/local/python3.10/bin/python3.10
ln -s /usr/bin/pip3.10 /usr/local/python3.10/bin/pip3.10安装PyTorch
vLLM主要依赖PyTorch(Torch)进行张量计算和模型推理,不依赖TorchVision和TorchAudio。
- 如果在使用vLLM时不需要处理图像或音频(例如加载图像数据集或音频数据集),则只需安装Torch,无需安装TorchVision和TorchAudio。
- cuDNN是NVIDIA提供的一种GPU加速库,专门用于深度学习框架中的卷积操作(如CNN)。如果你使用GPU加速运行PyTorch和vLLM,那么cuDNN是必要的。
1. 下载PyTorch源码。
建议先只下载第一层,以免在网络较差的情况下导致Git报错,然后递归更新。
git clone -b v2.1.2 --depth 1 https://hub.yzuu.cf/pytorch/pytorch.git
git submodule update --init --recursive -jobs 4通常,完整下载所需的空间超过2.5GB。如果最终文件大小明显小于这个数值,则可能意味着某些递归依赖的包未被完全下载。
2. 配置环境变量。
2.1 打开“/etc/profile”文件。
vi /etc/profile2.2 按“i”进入编辑模式,在“/etc/profile”文件中增加以下内容。
export USE_CUDA=1
export MAX_JOBS=4
export USE_SYSTEM_NCCL=OFF
export NO_DISTRIBUTED=1
export NO_MKLDNN=1
export NO_NNPACK=1
export NO_QNNPACK=1- export USE_CUDA=1:用于通知后续脚本或程序在构建过程中需启用CUDA加速及相关操作。
- export USE_SYSTEM_NCCL=OFF:若不涉及分布式,请配置为OFF。
- export MAX_JOBS=4:用于指定并行编译任务的最大数量。请根据机器进行设置,过高的配置可能会导致系统崩溃。
2.3 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
2.4 使环境变量生效。
source /etc/profile 3. 安装依赖。
pip install -r requirements.txt如果是Conda环境先查看当前CUDA版本,如果与系统版本不一致需要先执行
source ~/.bashrc。4. 获取patch并上传到服务器,然后添加patch。
该版本存在[CUDNN] RNNv6 API deprecation support的BUG,需要下载PR补丁。
cd /home
ll c71d5a92ee281401eb528a7f8ee2a583ffb798db.patch
cd /home/pytorch/pytorch
patch -p1 < ../../c71d5a92ee281401eb528a7f8ee2a583ffb798db.patch 5. 进入PyTorch目录,编译安装。
- 方式一:直接安装
python setup.py install --cmake- 方式二:编译生成whl安装文件(位于dist目录下),然后安装
python setup.py bdist_wheel --cmake pip install dist/torch-xxxx.whl安装过程大概在40分钟~2小时。
6. 运行验证。
6.1 导入PyTorch库。
import torch6.2 查看PyTorch版本。
print(torch.__version__)6.3验证CUDA。
pri nt(torch.cuda.is_available()) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(torch.ones(5, 5).to(device)+ torch.randn(5, 5).to(device))显示true表示成功。您可以再次运行以下代码来查看显卡的数量和型号。
print(torch.cuda.device_count())print(torch.cuda.get_device_name(0))(可选)编译安装Triton
vLLM编译安装需要Triton 2.1.0及以上版本。官方未提供aarch64版本,Glibc 2.30及以上系统可直接下载安装,Glibc 2.30以下系统则需手动编译。
1.编译安装LLVM。
也可安装毕昇编译器获得LLVM。
git clone https://github.com/llvm/llvm-project
cd llvm-project 在Triton代码仓cat cmake/llvm-hash.txt中找到当前依赖的LLVM源码版本,使用git checkout <hash-id>切到该LLVM版本。
git checkout 86b69c31642e98f8357df62c09d118ad1da4e16a
mkdir build
cd build
cmake -G Ninja -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_ASSERTIONS=ON -DCMAKE_C_COMPILER=/path/to/your/gcc -DCMAKE_CXX_COMPILER=/path/to/your/g++ ../llvm -DLLVM_ENABLE_PROJECTS="mlir;llvm"
ninja2.安装pybind11。pybind11是以Python的DSL暴露给用户,然后用户通过Python语法调用预先用C++/CUDA或者Assemble写好的高性能组件。
pip install pybind113.下载Triton。
3.1 获取Triton源码。
git clone --recursive https://github.com/openai/triton.git
git submodule update --init --recursive
git submodule status 3.2 克隆Triton的子项目triton_shared。
cd triton/third_party
export TRITON_PLUGIN_DIRS=$(pwd)/triton_shared
git clone --recurse-submodules https://github.com/microsoft/triton-shared.git triton_shared 3.3 切换到2.1.0分支。
git checkout v2.1.04.编译安装Triton。
- 方式一
pip install ninja cmake wheel
# Modify as appropriate to point to your LLVM build.
export LLVM_BUILD_DIR=$HOME/llvm-project/build
export LLVM_INCLUDE_DIRS=$LLVM_BUILD_DIR/include
export LLVM_LIBRARY_DIR=$LLVM_BUILD_DIR/lib
LLVM_SYSPATH=$LLVM_BUILD_DIR \
pip install -e python- 方式二
mkdir build
cd build
cmake ..编译安装xFormers
vLLM依赖xFormers对Transformers加速:
xformers == 0.0.23.post1 # Required for CUDA 12.1. 官方提供了在线安装方式pip install -U xformers==0.0.23.post1或pip install --pre -U xformers==0.0.23.post1也可安装,但是安装完验证检测不到C++依赖。
1.手动编译Arm版本。
- 方式一
git clone https://github.com/facebookresearch/xformers.git
cd xformers git checkout tags/v0.0.23.post1
git submodule update --init -recursive -jobs 4 #源码里version.txt显示此版本是0.24,安装完之后也会提示与vllm不匹配,没有关系
pip install -r requirements.txt
pip install wheel
pip install e . - 方式二
python setup.py build
python setup.py bdist_wheel 2.验证。
XFORMERS_MORE_DETAILS=1 python -m xformers.info 安装vLLM
1. 安装依赖,请根据CUDA版本修改requirements.txt。
pip install -r requirements.txt 2. 编译带有CUDA 11.8的vLLM。
python setup.py bdist_wheel3. 安装vLLM。其中,“xxxx”请替换为实际文件名称。
cd vllm/dist
pip install vll-xxxx.whl运行和验证
一、采用此方法可自动下载约3GB的模型。
1. 安装依赖。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple modelscope 2. 在服务端执行以下命令,下载QWen服务器并启动。
VLLM_USE_MODELSCOPE=True python3 -m vllm.entrypoints.openai.api_server --model qwen/Qwen1.5-0.5B-Chat --trust-remote-code --host 0.0.0.0 --port 8000 --served-model-name Qwen1.5-0.5B-Chat --dtype=half --gpu-memory-utilization 0.90 -max-model-len=6144 若出现“bfloat16 is only supported on gpus with compute capability of at least 8.0”报错,请在Python命令后增加--dtype=half参数。
若出现“out of memory”报错,请通过watch -n 0.1 -d nvidia-smi命令动态查看显卡使用情况,若确认为内存使用问题,请在Python命令后增加--gpu-memory-utilization 0.80(默认0.9)和-max-model-len=1024参数来调整。
3. 在客户端执行以下命令,进行模型测试。
curl -v -X POST "http://0.0.0.0:8000/v1/completions%22 -H "Content-Type: application/json" -d '{"model": "Qwen1.5-0.5B-Chat", "prompt": "你好"}'
英文有概率出现返回值为空的问题,若未报错,说明已成功安装。
二、在离线环境中,您可以先从魔搭社区下载所需的模型,之后再调用本地模型。
1.下载模型至“/root/autodl-tmp/01ai/Yi-6B-Chat”,使用以下命令开启Server。
python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/01ai/Yi-6B-Chat \
--served-model-name 01ai/Yi-6B-Chat \
--trust-remote-code \
--max-model-len 2048 -q awq 2.测试服务。
curl -X POST "http://0.0.0.0:8001/v1/completions%22 \
-H "Content-Type: application/json" \
-d '{
"model": "01ai/Yi-6B-Chat",
"prompt": "请介绍一下人工智能",
"max_tokens": 200,
"temperature": 0.7
}' 故障排除
1.Git PyTorch源码报错的解决方法
问题现象描述
获取PyTorch源码失败,出现如下图所示报错。

结论、解决方案及效果
尝试更换其他包进行测试,以确认问题是否由Git配置引起:
git clone https://github.com/vllm-project/vllm.git 若能下载,则说明PyTorch包过大,建议参考安装PyTorch先执行第一层。
若不能下载,请先配置Git:
参考配置网络代理在“/etc/profile”中配置或通过以下命令。
git config --global http.proxy http://用户名:密码@代理IP地址:代理端口
git config --global https.proxy https://用户名:密码@代理IP地址:代理端口 配置忽略SSL证书
git config --global http.sslVerify false 2.提示NameError: name 'sympy' is not defined报错的解决方法
需要在Conda里安装SymPy模块,若仍报错,建议安装Mpmath。总之,import torch时遇到缺失依赖的错误,按提示补全相关依赖即可。
3.编译安装PyTorch时提示找不到cmake的解决方法
问题现象描述
编译安装PyTorch时提示找不到CMake,具体报错信息如下图所示。
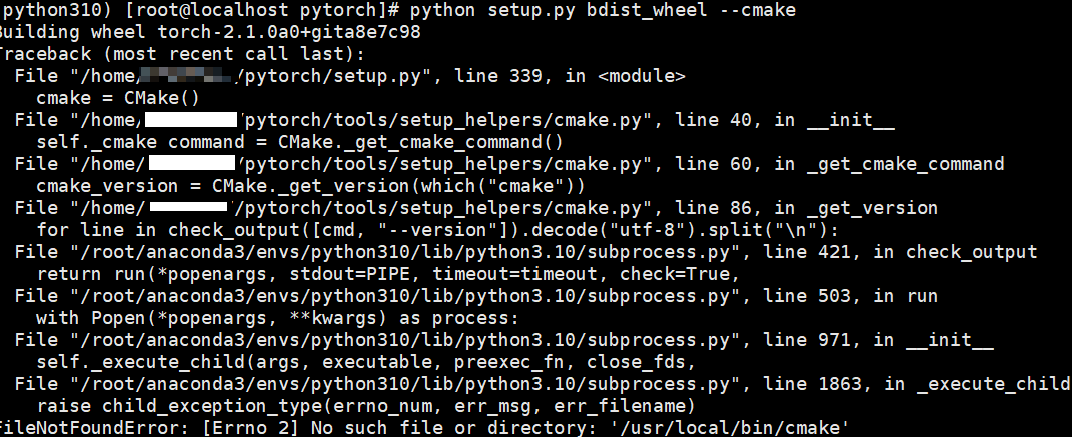
结论、解决方案及效果
查找CMake路径及版本:
which cmake
cmake --version 如果已找到并安装CMake,则添加软链接:
ln -s /usr/local/cmake/bin/cmake /usr/bin/cmake 如果没有安装CMake,则按照指导进行安装参见安装CMake,或直接Yum安装。
yum install cmake 如果出现以下报错,则说明Python软链接有问题,请参考修改Python软链接。

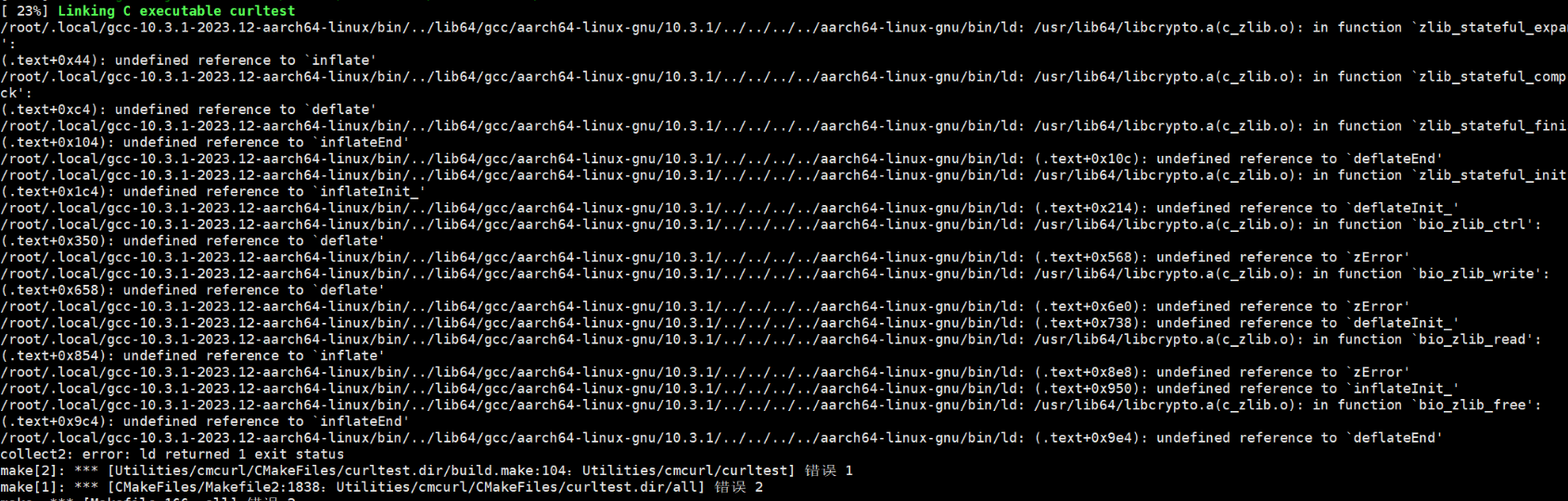
4.提示GCC版本过高/glibcxx3.4.30找不到的解决方法
问题现象描述
提示GCC版本过高或找不到GLIBCXX_3.4.30,具体报错信息如下图所示。
图1 报错一

图2 报错二

结论、解决方案及效果
报错一:GCC版本过高 通过gcc -v查看GCC版本,如果版本高于11,则不被支持。若遇版本过高,请卸载后重新安装。
yum remove gcc
yum install gcc 报错二:GCC10版本为28,需要安装GCC12
conda install -c conda-forge libstdcxx-ng=12 指定环境变量:
export LD_LIBRARY_PATH=/opt/openEuler/gcc-toolset-12/root/usr/lib64:$LD_LIBRARY_PATH 编译增加以下参数:
-DCMAKE_C_COMPILER=/opt/openEuler/gcc-toolset-12/root/usr/bin/gcc -DCMAKE_CXX_COMPILER=/opt/openEuler/gcc-toolset-12/root/usr/bin/g++ 没有Conda环境的情况下直接安装GCC for openEuler 12.3.1及以上版本,并修改对应libstdc++软链接。
另外针对这种GLIBCXX找不到的情况,通常都是因为GCC版本不匹配,如果本身有多个环境(如Conda等),可按照如下操作:
sudo find / -name libstdc++.so.6 #找到不同的版本
strings /usr/lib64/libstdc++.so.6 | grep -E '^GLIBCXX' | sort #如果有合适的版本,将当前环境的LD_LIBRARY_PATH替换即可5.提示Glibc 2.35找不到的解决方法
问题现象描述
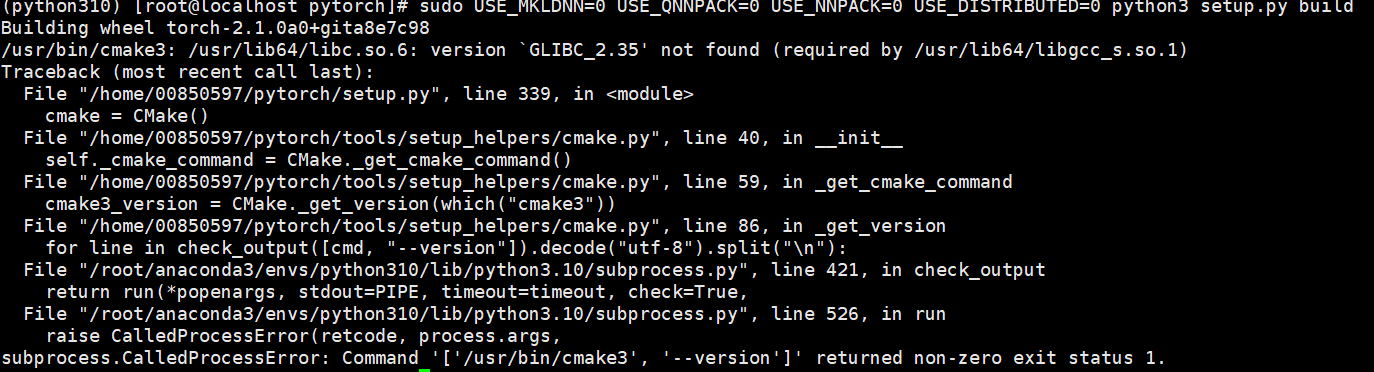
结论、解决方案及效果
某些依赖库或者包如果在高版本的操作系统上编译,然后安装到低版本的操作系统可能会报错。由于升级Glibc风险很大,建议更换软件包。
常见系统Glibc版本:openEuler 20.03 > Glibc 2.28;openEuler 22.03 > Glibc 2.34;openEuler 22.09 > Glibc 2.35;Ubuntu 20.04 > Glibc 2.31。
6.提示Failed to compute shorthash for libnvrtc.so的解决方法
问题现象描述


结论、解决方案及效果
1.在CMakeLists.txt开头添加如下内容。
find_package(PythonInterp REQUIRED) 2.查看cuda12.4文件夹有nvx3源文件,修改CMakeLists.txt路径。
3.安装Kineto库。
git clone --recursive https://github.com/pytorch/kineto.git
cd kineto git submodule init && git submodule update
cd libkineto
mkdir build
cd build
cmake ..
make如果出现以下报错,需要指定cuda_source_dir变量。
export KINETO_SOURCE_DIR=/home/kineto/libkineto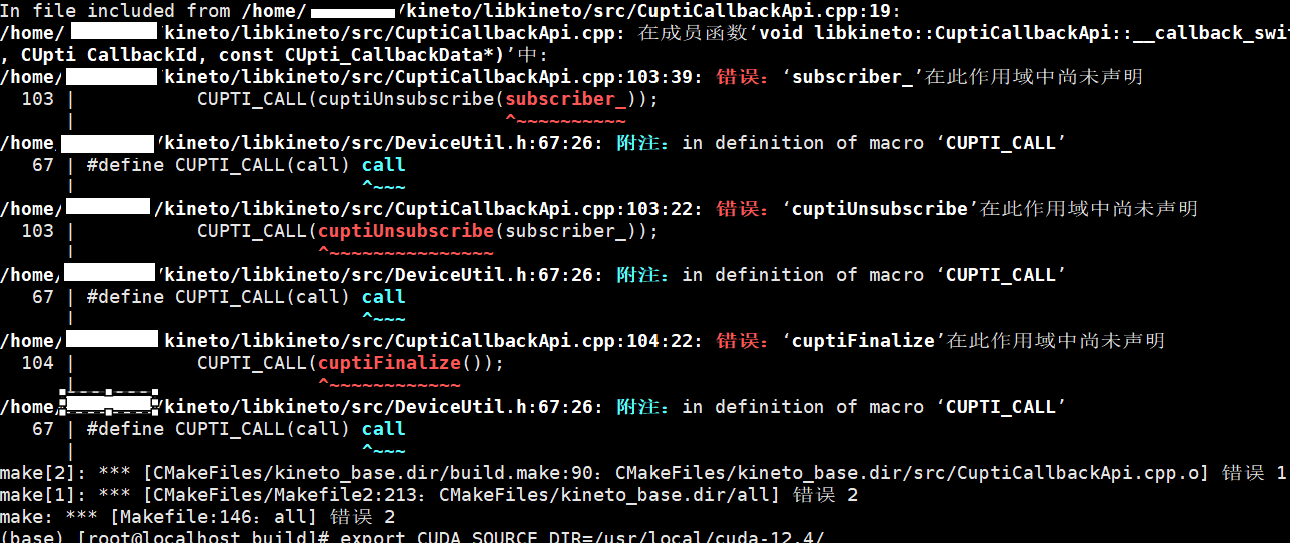
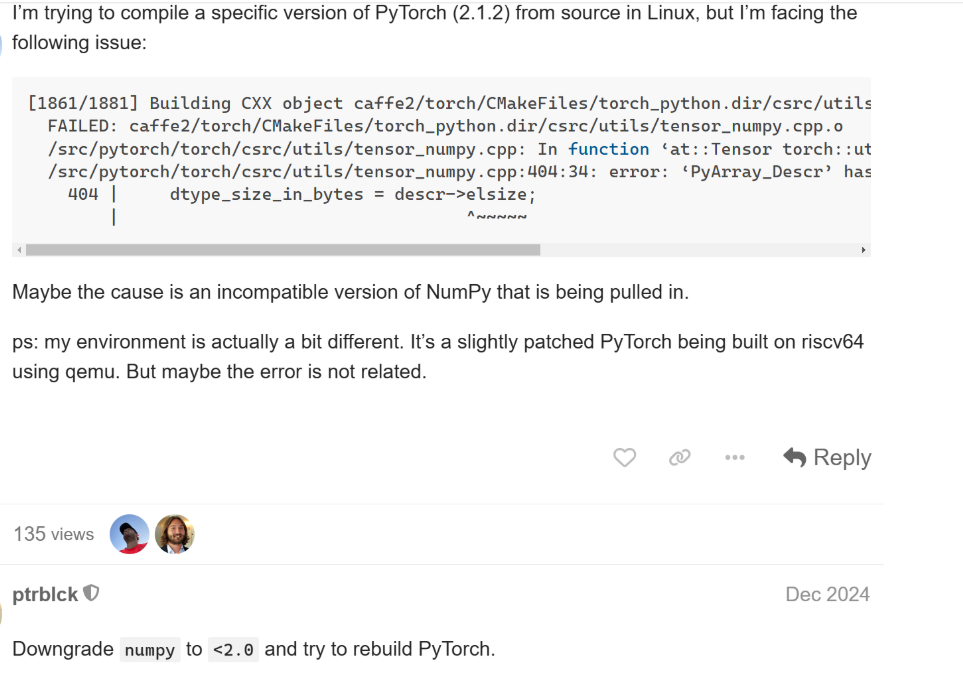
7.提示'PyArray_Descr' has no member named 'elsize'的解决方法
将NumPy版本切换至2.0.0以下。
8.安装高版本Torch后验证报错的解决方法
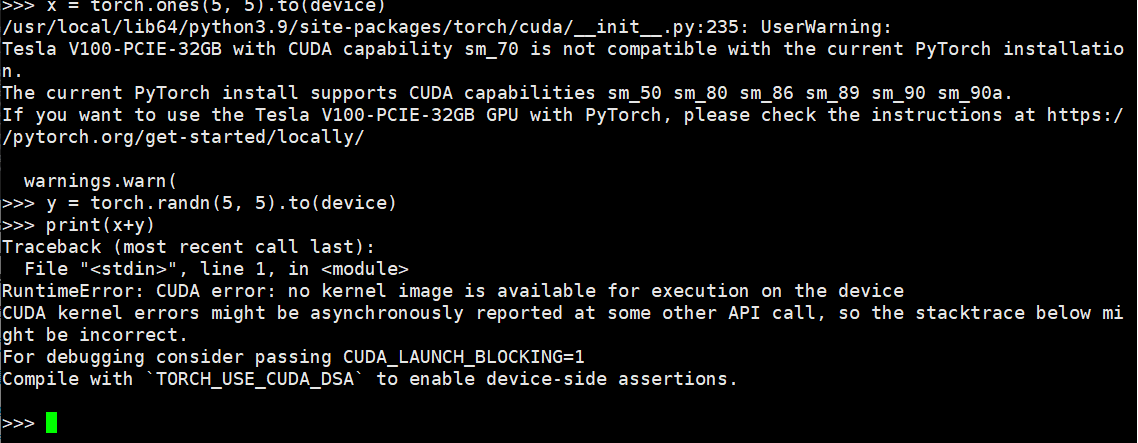
Torch2.6.0>>> torch.cuda.get_arch_list()['sm_50', 'sm_80', 'sm_86', 'sm_89', 'sm_90', 'sm_90a'] 先对照安装的版本是否不一致:
9.执行import torch命令提示cuDNN动态库无法识别的解决方法
使用yum list发现也报错:
/lib64/libcurl.so.4: symbol SSLv3_client_method version OPENSSL_1_1_0 not defined in file libssl.so.1.1 with link time reference 由于“/usr/lib64”中的动态链接无法识别和链接,需要将其添加到环境变量中:
export LD_LIBRARY_PATH=/usr/lib:$LD_LIBRARY_PATHexport LD_LIBRARY_PATH=/usr/lib64:$LD_LIBRARY_PATH 或者加到~/.bashrc文件。
10.编译Triton时出现MLIRC相关报错的解决方法
问题现象描述
编译Triton时出现MLIRC相关报错,具体报错信息如下图所示。
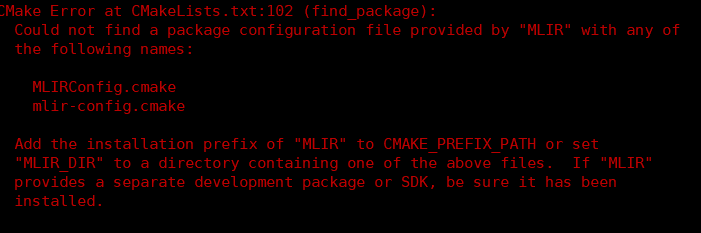
结论、解决方案及效果
重新指定cmake执行install命令时安装的路径前缀。
export CMAKE_PREFIX_PATH=/home/llvm-project/build/lib/cmake/mlir:$CMAKE_PREFIX_PATH11.编译Triton提示ptxas报错的解决方法
问题现象描述
编译Triton时出现ptxas相关报错,具体报错信息如下图所示。
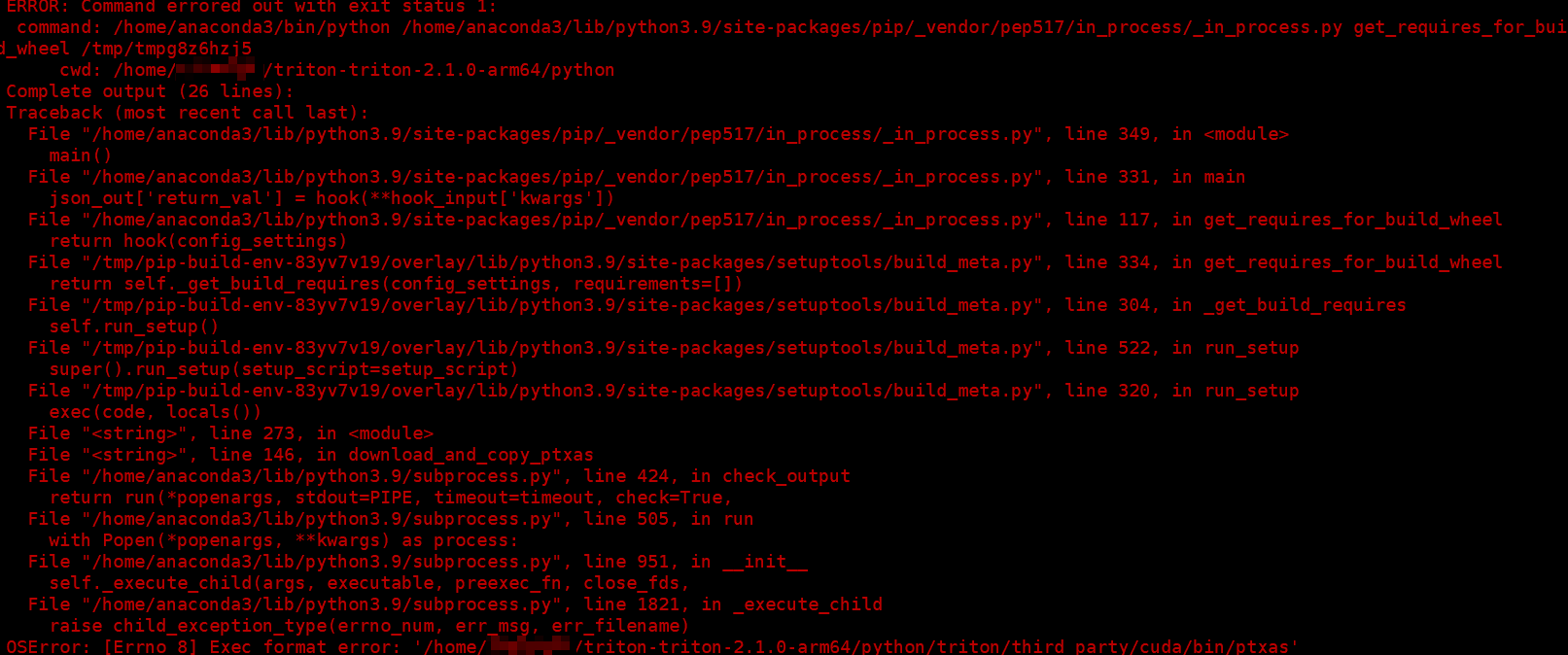
结论、解决方案及效果
查看这个文件是不是x86的:

从安装的CUDA路径里替换这个文件。
12.编译cmake时出现utf-8 codec can't decode byte 0x报错的解决方法
问题现象描述
编译cmake时出现“utf-8 codec can't decode byte 0x”报错。
结论、解决方案及效果
通常,这类问题源于相关文件与系统设置之间的字符编码不匹配。PyTorch使用UTF-8,即Linux默认的字符编码,可以使用locale查看当前系统的字符编码,如果是UTF-8,则需要考虑CMake版本问题:cmake -version,推荐版本是3.22,过高可能会导致该问题。
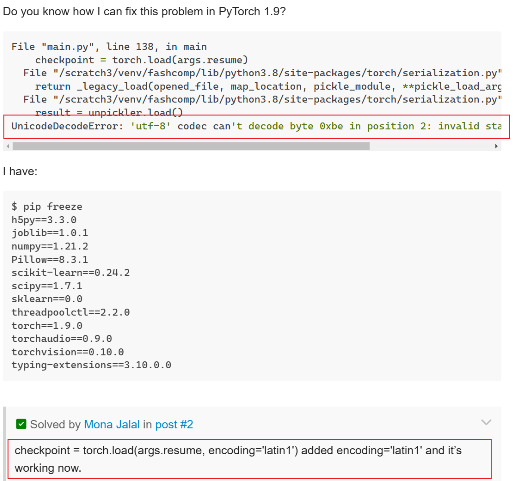
13.运行时出现xFormers wasn't build with CUDA support报错的解决方法
问题现象描述
运行时出现“xFormers wasn't build with CUDA support”报错,具体报错信息如下图所示。
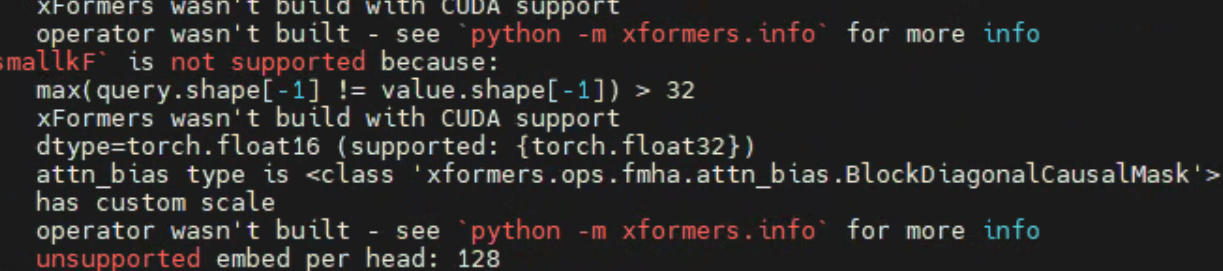
结论、解决方案及效果
当前环境安装的xFormers与Torch版本不一致,读取不到CUDA依赖,需要手动编译安装xFormers 0.0.23.post1版本。