


C或C++程序ARM上常见迁移适配问题总结
发表于 2025/10/31
0
一、非void函数缺少返回值引起的未定义行为
问题描述:在 C/C++ 中,当函数声明了非void的返回类型时,所有可能的执行路径都必须包含返回值,否则会导致 “缺少返回值” 的问题,进而引发未定义行为(Undefined Behavior)。该问题在迁移C/C++程序过程中发生最为频繁的问题之一,应当首先排查。
编译阶段:当前多数编译器(如 GCC、Clang)只会发出警告(warning: control reaches end of non-void function),只有部分严格模式下才会直接报错。
编译器行为差异:
| 编译器 | 默认行为 | 警告选项 | 错误选项 |
|---|---|---|---|
| GCC | 无警告 | -Wall或-Wreturn-type | -Werror=return-type |
| Clang | 警告 | 无需选项 | -Werror=return-type |
| MSVC | 警告(C4716) | 无需选项 | /WX /W4 |
运行阶段:属于未定义行为(Undefined Behavior),可能返回随机值(栈中残留的垃圾数据),或导致程序逻辑错误、崩溃等。
X86和ARM架构对于该行为的差异:大部分程序在x86上不会发生明显异常,可以“侥幸”运行,但在ARM上对缺少返回值的行为会更敏感,容易异常。
MyString& operator=(const MyString& other) {
if (this == &other) {
std::cout << "自赋值:不做操作\n";
// return *this;
}
delete[] data;
len = other.len;
data = new char[len + 1];
strcpy(data, other.data);
//return *this; // x86:可以正常运行返回构造的对象;arm运行异常
}原因:x86 和 ARM 架构在函数调用约定上的本质不同导致了未定义行为的不同表现。x86 架构的 EAX 寄存器专门用于返回值,在函数执行过程中可能保留最后一次运算结果,从而产生看似 "正常" 的行为;而 ARM 架构的 R0 寄存器是通用的多功能寄存器,在程序内可自由用于存储临时变量、计算中间结果等,极易被修改,导致返回值完全不可预测。
排查思路:
- 启用编译器警告并将其视为错误:如-Werror选项,或者将缺少返回值警告升级为错误:-Werror=return-type
- 依次检查main函数,子函数,特别是操作符重载函数,拷贝构造函数等特殊函数。
- 使用gdb或者打印日志检查是否存在异常的基础语法逻辑错误,且现象较稳定重复出现:如整型比较结果不符合预期,用int比较时:a(101)<= b(100)返回true。如在int a = 0;或者a = b类似基础的语句操作时出现明显异常。
二、char类型问题
问题说明:char类型在x86架构上默认为signed char, 在arm上默认为unsigned char。x86架构代码移植到鲲鹏平台时,需要强制指定char类型变量默认为signed char,或者手动修改代码逻辑。
处理方式:添加编译参数-fsigned-char,指定char类型变量为有符号类型。
三、多线程竞争问题:
C/C++程序在x86到arm的迁移适配过程中发现的两个多线程竞争的现象:
1、多线程间值读取写入时顺序不同:
//程序简化:
int data = 0;
bool ready = false;
//线程1
data = 100;
ready = true; // x86通常能保证data的写入在ready写入之前,arm上无法保障data和ready的写入顺序
//线程2
while (!ready); // 等待ready写入完成
printf("%d",data); //在x86上打印结果为100,在arm上打印结果在0和100间变化
if (data == 100) {
//do something;//在x86上通常执行该分支,程序基本正常
} else {
//do something;//在arm上可能执行该分支,程序容易出现bug
}2、omp程序数据竞争行为不同:
int i, j, k; //在循环外定义 - 默认共享
#pragma omp parallel for
for (i = 0; i < N; i++) {
for (j = 0; j < M; j++) {
for (k = 0; k < P ; k++) {
// 所有线程同时读写i,j,k - 产生数据竞争
// x86执行正常,循环次数正常;arm执行异常,循环次数异常
}
}
}上述两个现象是由于x86和arm架构的内存模型强度和缓存一致性的差异造成的:
(1)内存模型强度表示:处理器架构对内存操作重排序限制程度,定义了硬件允许的内存访问乱序程度,以及需要程序员/编译器插入多少同步指令来保证正确性。
强内存模型:x86/x86-64架构,通过硬件保证顺序,简化编程但功耗较高。
弱内存模型:ARM、PowerPC、RISC-V架构,将由软件保证内存访问顺序,硬件更简单、能效更高。
(2)缓存一致性表示:是指在多处理器/多核系统中,确保所有处理器核心的缓存中的数据副本保持一致的机制。
x86:强一致性,采用写失效策略,写操作立即通知其他核心使缓存失效,硬件自动保证强一致性。
arm:弱一致性,采用写更新或写失效策略,写操作可能延迟传播,需要软件显式插入内存屏障。
处理方式:以上现象都是未定义行为,需规范代码写法,软件保证顺序读写一致性,将数据私有化,减少共享数据。
四、内存越界问题:
在 C/C++ 中,内存越界(访问索引超出数组定义范围的元素)是典型的未定义行为,可能导致程序崩溃、数据损坏、安全漏洞等一系列问题。常见的错误报错信息有“Segmentation Fault, SIGSEGV”、“free(): invalid next size(normal)”等。内存越界的问题难以定位,因为内存越界的后果往往不直接体现在越界发生的位置,而是在后续的代码中爆发。
在迁移过程中发现ARM对内存越界行为更容易触发bug,而x86对内存越界容忍度相对较高,这是因为ARM架构对内存对齐和内存访问异常处理机制比x86更为复杂和严格,但x86的宽松行为可能会带来更大的性能开销和更隐蔽的逻辑错误。
这类问题的排查一般通过:
(1)使用内存检测工具,如Valgrind,ASan,devkit内存诊断。
(2)代码走读,代码优先使用vector容器类,智能指针等。
其中ASan工具是GCC 和 Clang 内置的内存错误检测工具,使用方式为:在编译器和链接器中同时添加“-fsanitize=address -g”,然后直接运行程序,当出现内存越界行为时会自动报错。
五、C/C++库链接问题及工具介绍
问题描述:c/c++程序运行时提示“undefined symbol”问题,该问题应该为c/c++程序最为常见的问题之一了。当链接器找不到某个函数或变量的定义时会出现此错误。
可能的原因包括:函数或类成员变量只声明未定义、函数名拼写错误、缺少必要的库链接或未成功链接外部库等。
排查思路:
1、使用 ldd命令查看是否缺少库和未定义符号:ldd命令是调试动态依赖的核心工具,用于查看分析可执行文件或共享库(.so)所依赖的动态链接库。使用ldd -r lib***.so 查看链接的外部库:-r 查看链接的外部库以及打印未定义的符号。此外可以使用-v参数:查看详细依赖信息(版本、符号);-u参数:查看已链接但未实际使用的动态库,用于优化编译。
2、检查动态库搜索路径:动态链接器的搜索路径遵循严格的优先级顺序,从高到低依次为:1.程序所在目录 > 2.环境变量LD_LIBRARY_PATH > 3. 程序编译时配置的RPATH/RUNPATH路径 >> 4.系统缓存/etc/ld.so.cache(由/etc/ld.so.conf配置)> 5.系统默认路径(/lib64、/usr/lib64等)。然后使用find等命令查找not found对应的库名。
3、具体函数或类型找不到定义:可以使用c++filt命令来查看符号对应的具体代码:c++filt _ZN2cv11namedWindowERKSsi(这里替换为undefined symbol的符号) 显示未定义符号对应的具体代码,便于快速找到未定义的符号。
4、使用nm命令来查看动态库是否有需要的符号:nm 命令是 C/C++ 编译链接调试的关键工具,主要用于查看 ELF 格式文件(目标文件.o、可执行文件、共享库.so、静态库.a)的符号表(Symbol Table)。
除上述工具外,常用的还有objdump、readelf来进行C/C++程序的编译链接链接分析。
两个值得注意的顺序:
(1)链接器按照库在makefile中的顺序从左到右处理,被依赖的库必须放在依赖它的库的后面。如果a.so依赖b.so,此时makefile中的顺序为-la -lb。
(2)若多个库存在同名接口,按照库在makefile中的顺序 “先到先得”:即优先使用第一个出现的库中提供的接口实现,后续库中的同名接口会被忽略。
六、C/C++程序调用fortran接口问题
这个问题和架构没有关系,和不同的编译器以及编译参数有关系,且由于现网存在大量fortran77的代码且在移植适配过程中fortran语言的错误通常不会暴露在编译阶段,甚至运行阶段也不会有core dump,问题较为隐蔽,单独进行总结分享。
1、fortran有严格的行长度限制:fortran77为72个字符,超过72个字符会发生截断,自行将上下行拼接起来。在fortran程序中,tab字符为非标准字符,当存在tab字符时,可能会被不同的编译器填充为不同长度的空格,导致原本在a上正常编译运行的代码,在b上可能会发生异常。
处理方式:添加编译选项-ffree-line-length-none(不限制行长)或-ffixed-line-length-132(拓展为132字符行长)避免该问题;或者升级语言版本到fortran90。
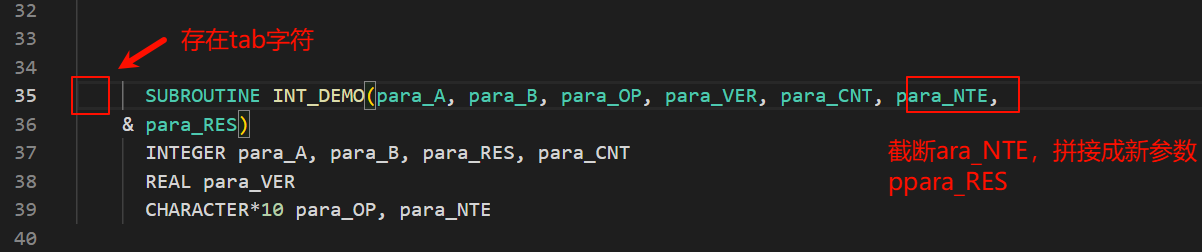
2、C/C++调用fortran接口注意事项1:当fortran中行长少于72字符时,会自动填充空格到末尾,如果有换行的字符串,需要添加编译选项-fno-pad-source解决。
3、C/C++调用fortran接口注意事项2:fortran77中传递字符串给c/c++程序时需要手动添加终止符“\0”,并且需要添加添加“-fbackslash”启动转义字符。在fortran90之后的版本可以直接通过“c_null_char”或者“CHAR(0)”来添加终止符。