


鲲鹏统一并行加速库KUPL——众核并行调度介绍
发表于 2025/11/30
0
1. 背景介绍
1.1 并行计算的重要性
并行计算通过同时使用多个计算资源来解决复杂问题,显著提高计算效率和处理能力。随着数据量的爆炸性增长和计算任务的复杂性增加,传统的串行计算模型已难以满足需求。并行计算通过多核处理器、多处理器系统和分布式计算集群,能够:
1.提高计算效率:同时处理多个任务,充分利用计算资源,提高系统吞吐量。
2.处理大规模数据:高效处理大数据集,满足科学计算、工程仿真和数据分析的需求。
3.缩短计算时间:实现实时或近实时计算,提升用户体验,减少等待时间。
4.提高可扩展性:通过水平和垂直扩展,轻松应对不断增长的计算需求。
5.降低能耗:更高效地利用资源,减少能耗,降低运营成本。
6.支持复杂算法:加速机器学习和人工智能算法的训练和推理,提高模型的准确性和响应速度。
1.2 任务编程模型的优势
任务编程模型是一种并行计算模型,通过将计算任务分解为多个独立的子任务来实现并行处理。这种模型具有以下优势:
1.提高并行性:任务可以细分为多个小任务,每个任务可以独立执行,从而充分利用多核处理器和多处理器系统的计算资源。任务可以动态分配,确保计算资源的高效利用,避免某些资源闲置而其他资源过载。
2.简化编程:任务编程模型提供高层次的抽象,开发者可以专注于任务的逻辑,而不需要关心底层的并行细节。任务之间的依赖关系和并行性可以通过任务图清晰地表示,使代码更易于理解和维护。
3.灵活性:任务编程模型可以适应不同的硬件架构,包括多核处理器、GPU 和分布式计算集群。任务可以动态创建和销毁,适应不同规模和复杂度的计算任务。
4.高效资源管理:任务可以按需分配资源,避免资源浪费,提高整体系统的资源利用率。任务可以独立管理内存,减少内存碎片和提高内存访问效率。
5.可扩展性:通过增加更多的计算节点,可以轻松扩展系统的处理能力,满足不断增长的计算需求。通过增加单个节点的计算资源,可以提高单个节点的处理能力。
6.支持复杂应用:任务编程模型可以处理复杂的计算任务,如机器学习、科学计算和大数据处理。任务可以异步执行,提高系统的响应速度和处理能力。
总之,任务编程模型通过提高并行性、简化编程、增强灵活性和高效资源管理,为现代并行计算提供了强大的支持,适用于各种复杂和大规模的计算任务。
1.3 鲲鹏统一并行加速库(KUPL)简介
KUPL主要包括众核并行、数据移动和矩阵编程三部分,对标NV CUDA,北向兼容OpenMP、OpenACC等标准编程,发挥鲲鹏920新型号CPU众核、SDMA、OPM、矩阵编程能力。
众核并行主要分成算子间并行、算子内并行和核间同步三个部分。算子间并行主要提供类似CUDA Stream/Event,Graph相关的编程接口。算子内并行主要提供Parallel、Parallel_for等编程接口。核间同步主要提供 Barrier, Reduce, Transpose相关的能力。数据移动主要提供异步内存拷贝的能力,对标cudaMemcpyAsync。同时实现DDR和OPM数据移动与计算重叠的能力。矩阵编程主要简化了矩阵向量化计算加速单元编程,提供类似CUDA wmma和Intel AMX的编程接口。
后续将主要介绍众核并行使用的调度机制及其底层原理。
2. 业界的并行编程框架的调度机制
2.1 TaskFlow
Taskflow 使用平均打散的方式将任务分配给工作线程(worker),但由于无法预估任务的计算资源消耗,容易造成某些线程负载过重、而其他线程空闲。为解决此问题,Taskflow 引入了 work-stealing 机制:每个 worker 线程在自身任务队列为空时,会尝试从其他线程的队列中窃取任务。采用随机选择 victim 线程的策略,并多次尝试窃取。如果多次尝试失败,线程会让出 CPU,并在 yield 过多时跳出等待循环。
2.2 TBB
TBB 的任务调度器也采用了动态的、基于工作窃取(work-stealing)的调度机制。其核心设计如下:每个工作线程维护一个本地任务池(ready pool),用于存储可执行的任务。这减少了使用全局队列时可能出现的争用问题。当任务被执行时,它可能生成新的子任务,这些子任务会被放入当前线程的本地池中。如果某个线程的本地池为空,它会随机选择另一个线程的池并“窃取”一个任务来执行,从而自动实现负载平衡。调度器在启动时创建一个线程池(默认大小与硬件线程数匹配),并通过随机窃取算法管理任务分配。
2.3 work-stealing 调度机制的缺陷
work-stealing 作为一种调度机制,缺乏适应性,无法应对多样化的工作负载。而且开销相对比较大,对于特定的场景无法满足低延时的特性。对于公平性要求比较高的场景,可能无法实现公平的资源分配。对于单一的调度机制不能适应所有的问题类型,
KUPL 引入了多层调度的概念,提出了算子内并行和算子间并行的调度逻辑,弥补了单一调度机制存在的缺陷。
3. KUPL 的调度机制
3.1 KUPL 任务调度的基本原则
负载均衡是任务调度中的一个核心原则,旨在确保计算资源的高效利用,避免某些资源过载而其他资源闲置。通过负载均衡,可以提高系统的整体性能和响应速度,减少任务等待时间,提高系统的吞吐量。
负载均衡的基本原则包括任务分配均匀、动态调整和优先级调度。任务分配均匀是指将任务均匀分配到各个计算资源上,确保每个资源的负载大致相同。动态调整则是根据系统的实时状态和任务的动态信息,动态调整任务的分配,以适应负载变化。优先级调度是指在任务分配时考虑任务的优先级,优先调度高优先级的任务,确保重要任务能够及时完成。
负载均衡的实现方法包括静态负载均衡、动态负载均衡和混合负载均衡。静态负载均衡包括预分配和固定分配两种方式。预分配是在任务创建时,根据任务的预估计算量和资源需求,预先分配任务到计算资源。固定分配则是将任务固定分配到特定的计算资源,适用于任务依赖关系和资源需求已知且固定的情况。动态负载均衡则包括工作窃取,即计算资源在完成当前任务后,从其他资源的任务队列中“窃取”任务,确保所有资源都能持续工作。混合负载均衡结合了静态和动态负载均衡的优点,先进行静态预分配,再根据实际情况进行动态调整,以实现更高效的资源利用。
3.2 KUPL 调度器的接口
KUPL 调度器的接口主要分成4 部分,初始化、反初始化、添加任务和获取并执行任务。初始化发生在 main 函数调用之前,该步骤主要把调度器所需的资源进行申请与初始化,并根据用户指定的环境变量进行调度器的选择。反初始化主要销毁在初始化中申请的资源。添加任务作为调度器的接口,由不同类型的调度器各自实现。执行任务会首先调用调度器获取任务的接口,如果获取到任务再执行。
3.3 KUPL 调度器的架构
KUPL 调度器采用的概念是分层调度,通过组合两种不同的调度策略来兼顾性能与灵活性。其核心原理是采用内外两层架构:外层默认采用sspe 调度器以保障基础性能,内层则可由用户按需配置(默认为 static_mq),任务获取按“先外层后内层”的优先级顺序进行。分层调度的主要特点在于其智能的按需激活机制与策略融合能力。系统只有在相应层级中有任务添加时,才会激活该层的调度器,有效避免了无谓的轮询开销。分层调度的模式既保留了 sspe 的轻量化高性能优势,又能借助内层调度器(如mq或static_mq)灵活适应多样化任务负载,适用于需要平衡极致性能与通用负载适应性的复杂计算场景。它能够在外层高效处理对延迟敏感的关键任务,同时在内层从容应对负载波动或批量任务。
同时分层调度的模式能很好的适配算子内并行和算子间并行的调度逻辑,外层调度器专门应对算子内并行需要低延迟、高性能的特点,内层调度器处理算子间并行更灵活和高效,也能充分利用多核资源实现负载均衡。
3.4 KUPL 调度器的实现方案
sspe 调度器
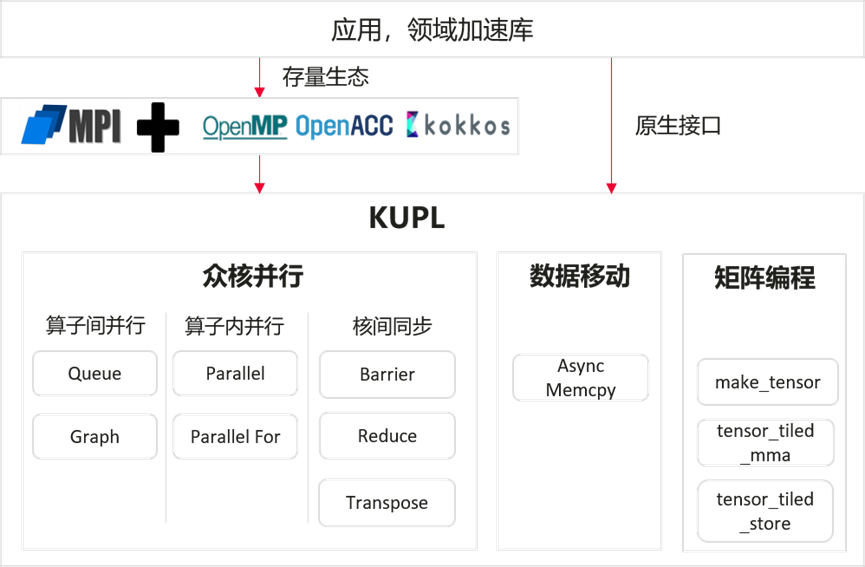
sspe(Single Slot Per Executor)是一种专为高性能并行计算设计的轻量级调度器。其核心原理是采用静态调度策略,在系统初始化时为每个执行器(Executor)预先分配一个固定的任务槽位,用于绑定任务。这意味着任务在提交时就必须明确指定其目标执行器ID。
该调度器的主要特点在于其极简性与专用性。首先,通过与 parallel 功能的深度耦合(如任务获取开关机制),它实现了极低的调度开销。其次,其设计哲学是“以简驭繁”,通过固定的任务-执行器绑定关系,避免了复杂的动态调度逻辑。
因此,sspe 非常适用于对延迟极度敏感、任务粒度均匀且已知的并行计算场景,尤其是 parallel 系列函数所处理的密集型计算任务。在这些场景下,它能以最小的调度代价,最大化地发挥出并行执行的效率优势。
static_mq 调度器
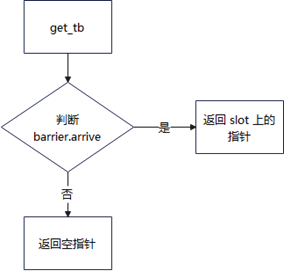
static_mq (Static Multi-Queue) 是一种多任务静态调度器。其核心原理同样是静态绑定,即在系统初始化时为每个执行器(Executor)预先分配一个专属的循环任务队列,而非单一槽位。
该调度器的主要特点体现在能力与开销的平衡上。与 sspe 相比,其任务队列机制带来了显著的功能优势:一是能够缓存多个任务;二是引入了优先级调度功能,可优先执行高优先级任务,确保关键任务的及时性。然而,这些增强功能也带来了相应的代价,即在任务的添加与获取操作上会产生比 sspe 稍大的开销。
因此,static_mq 适用于任务依赖和资源需求已知、且需要一定批量处理能力或优先级调度能力的静态并行场景。它在提供更强功能灵活性的同时,依然保持了静态调度可控性高的优点。
mq 调度器
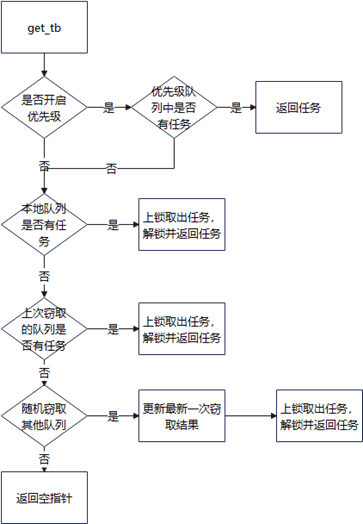
mq (Multi-Queue) 是一种动态负载均衡的调度器。其核心原理是在 static_mq 的静态多队列基础上,引入了工作窃取机制,允许空闲的执行器从其他执行器的队列中窃取任务,从而实现动态的负载均衡。
该调度器的主要特点在于其灵活性与高效性。它既保留了静态队列的局部性优势,又通过动态窃取消除了静态分配可能导致的负载不均问题。此外,mq 还提供了 place-queue 功能,允许为一组执行器设置共享队列;该共享队列中的任务享有更高的调度优先级,非常适合需要跨执行器优先处理特定任务的场景。
因此,mq 适用于任务负载不可预测、且需要系统自动实现高效负载均衡的通用并行计算场景。它能够在保证关键任务优先执行的同时,最大化所有计算资源的利用率。
4. 总结
并行计算调度技术的演进,本质上是一场在“确定性”与“不确定性”之间寻求平衡的探索。静态调度规则有序,但缺乏弹性;动态工作窃取灵活自适应,却难免引入开销与不可预测性。KUPL提出的分层调度架构,其核心创新在于跳出了“二选一”的思维定式,通过让不同特性的调度器协同工作,实现了“鱼与熊掌兼得”。
具体而言,这种设计将调度任务按场景分解:外层的轻量级调度器(sspe)以最小的开销应对确定性高、对延迟敏感的核心计算(算子内并行),确保基础性能的下限;内层的功能更丰富的调度器(static_mq/mq)则灵活处理不确定性强的任务流(算子间并行),保障系统的负载均衡和吞吐量。这种“专业分工”的模式,实质上是将宏观的负载均衡问题,分解为多个更易优化的子问题,从而在整体上获得更优的性能。
在高性能计算库的设计中,没有普适的“银弹”,真正的优化来自于对应用场景的深刻理解与精细化的架构设计。其分层思想不仅适用于调度,对内存管理、任务依赖处理等领域同样具有借鉴意义。展望未来,随着计算架构愈发异构化、应用负载愈发多样化,这种兼具专注与包容、稳定与灵活的系统设计哲学,将是构建下一代高效能计算基础设施的关键。