


DevKit 虚拟化无损迁移采集脚本:原理、使用方式与结果解读
发表于 2025/12/05
0
在无源码迁移项目中,迁移工作的第一步往往不是修改代码,而是准确还原源环境的真实形态。在实际项目里,这一步通常比想象中困难得多:同一台服务器上可能部署了多个版本的中间件和数据库,安装方式混杂,目录大量使用软链接,运维资料缺失或过期,甚至连“哪些组件正在被业务使用”都无人能够确认。DevKit 虚拟化无损迁移采集脚本的目标,正是解决这一问题。它通过一次自动化扫描,将分散在磁盘和运行态中的信息统一收敛,最终生成一份可直接用于迁移分析和执行的标准化输入包,尽可能降低迁移前期对人工经验的依赖。
一、脚本解决什么问题
从使用者视角来看,这个脚本并不是一个“找文件”的工具,而是一个迁移资产识别工具。它关注的不是单个文件是否存在,而是:
- 系统中存在哪些中间件、数据库和运行时组件;
- 每个组件的实际版本号是什么;
- 一个组件真正的安装根目录在哪里;
- 哪些组件正在被业务使用;
- 哪些应用包和配置文件需要随组件一起迁移。
这些信息如果靠人工逐条确认,通常需要大量沟通和反复验证。而脚本希望在“无人讲解、无人背书”的情况下,通过规则化方式自动给出一个尽量接近真实情况的答案。
二、脚本如何使用
1. 执行方式
在源服务器上,脚本的使用方式非常直接:
bash devkit_disk_scan.sh -R / -O /home/devkit-component-package其中:
- -R 指定扫描根目录,通常为 / 或业务部署目录;
- -O 指定输出目录,用于保存所有扫描结果和最终打包文件。
脚本支持并行扫描和断点续跑,在实际环境中可以直接后台执行。整个过程中无需人工指定中间件类型,也无需提前整理目录结构。

2. 脚本输入是什么
从逻辑上看,脚本的输入主要包括三部分:
1. 文件系统内容
即 -R 指定目录下的所有文件和目录结构,包括软链接关系。
2. 分类器规则配置
脚本内部使用一份 JSON 格式的分类器文件,描述了常见中间件和数据库的识别方式,例如:
- 哪些文件可以作为组件的“命中点”;
- 如何从命中点回溯安装根目录;
- 版本信息可能出现在哪里。
3. 运行态信息(可选)
脚本会主动采集当前系统中正在运行的 Java 进程信息,用于判断哪些组件处于实际使用状态。

对用户而言,这些输入全部是“隐式”的,无需额外准备。
三、整体处理原理(从输入到输出)
脚本执行后,会经历一个从“磁盘文件”到“迁移资产”的转换过程。
首先,脚本按照分类器规则扫描磁盘,找出所有可能代表组件的文件。这一步的目标是“尽量不漏”,因此扫描结果中可能包含多个候选命中点。
随后,脚本对每一个命中点进行处理,尝试回答几个关键问题:
这个文件是否代表一个独立组件?如果是,这个组件的完整目录边界在哪里?它的版本号能否识别出来?
在这一过程中,脚本会自动处理软链接,避免同一个组件被重复识别;同时结合分类器中配置的相对层级规则,推导出一个合理的安装根目录。对于 Redis、Tomcat、ZooKeeper 等常见组件,还会加入少量针对实际部署习惯的修正逻辑,以提高识别准确度。
在版本识别方面,脚本并不依赖单一手段,而是按优先级尝试多种方式,包括运行时命令、版本文件、配置文件以及目录名推断。这种“多兜底”的策略,主要是为了适配现场环境中不规范的部署方式。
当一个组件被确认后,脚本会立即将其结构化为一条记录,并在需要时对其安装目录进行打包。对于通过 RPM/YUM 安装的组件,脚本会优先按照包管理器提供的文件清单进行打包,避免遗漏系统级依赖。
四、脚本的主要输出结果
脚本的所有输出都会集中在 -O 指定的目录中,整体结构清晰,便于后续处理。
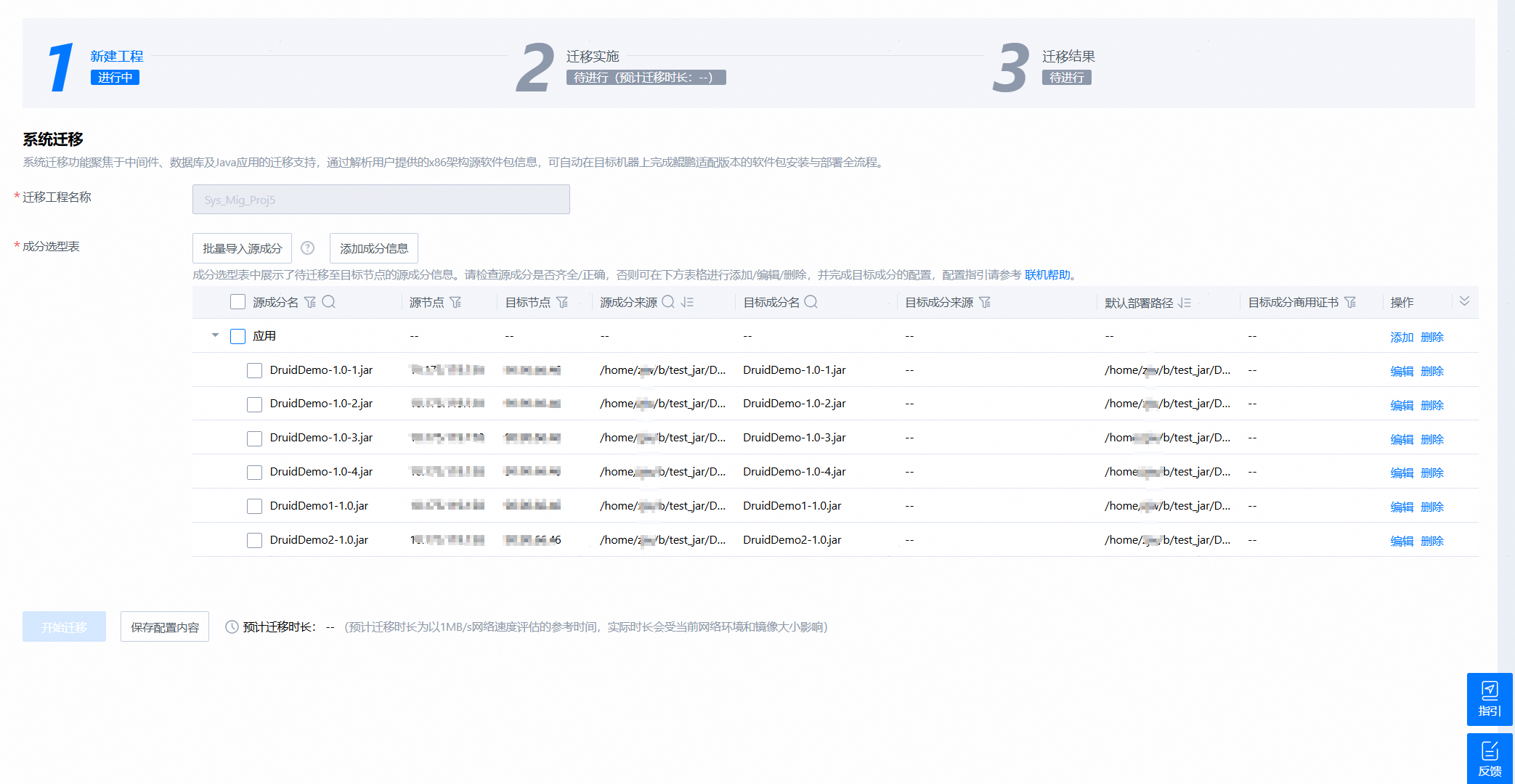
1. 组件清单(components.json)
这是脚本最核心的输出文件,描述了当前系统中识别出的所有中间件和数据库组件。每个组件都会包含如下关键信息:
- 组件名称与类型(中间件 / 数据库 / 运行时);
- 识别出的版本号;
- 安装根目录;
- 是否处于运行状态(in_use 标记);
- 对应的打包文件路径及校验信息。
该文件会被 DevKit 平台直接解析,用于生成迁移任务和评估报告。
2. 应用与配置映射(files_map.json)
该文件记录了被采集的应用包和配置文件,以及它们在迁移包中的对应位置。通过这一映射关系,后续工具可以清晰知道:
- 某个业务的Java应用包 JAR/EAR 等原来位于哪里;
- 在迁移过程中应该如何还原到目标环境;
- 是否需要对配置文件进行差异比对或参数调整。
3. 运行态信息(java_runtime.json)
该文件保存了 Java 运行时的快照信息,用于辅助判断组件是否在用,同时也为后续迁移后的验证提供参考。
4. 最终迁移输入包(result/*.tar.gz)
在所有信息收集完成后,脚本会自动将当前主机的扫描结果打包为一个完整的压缩文件,例如:
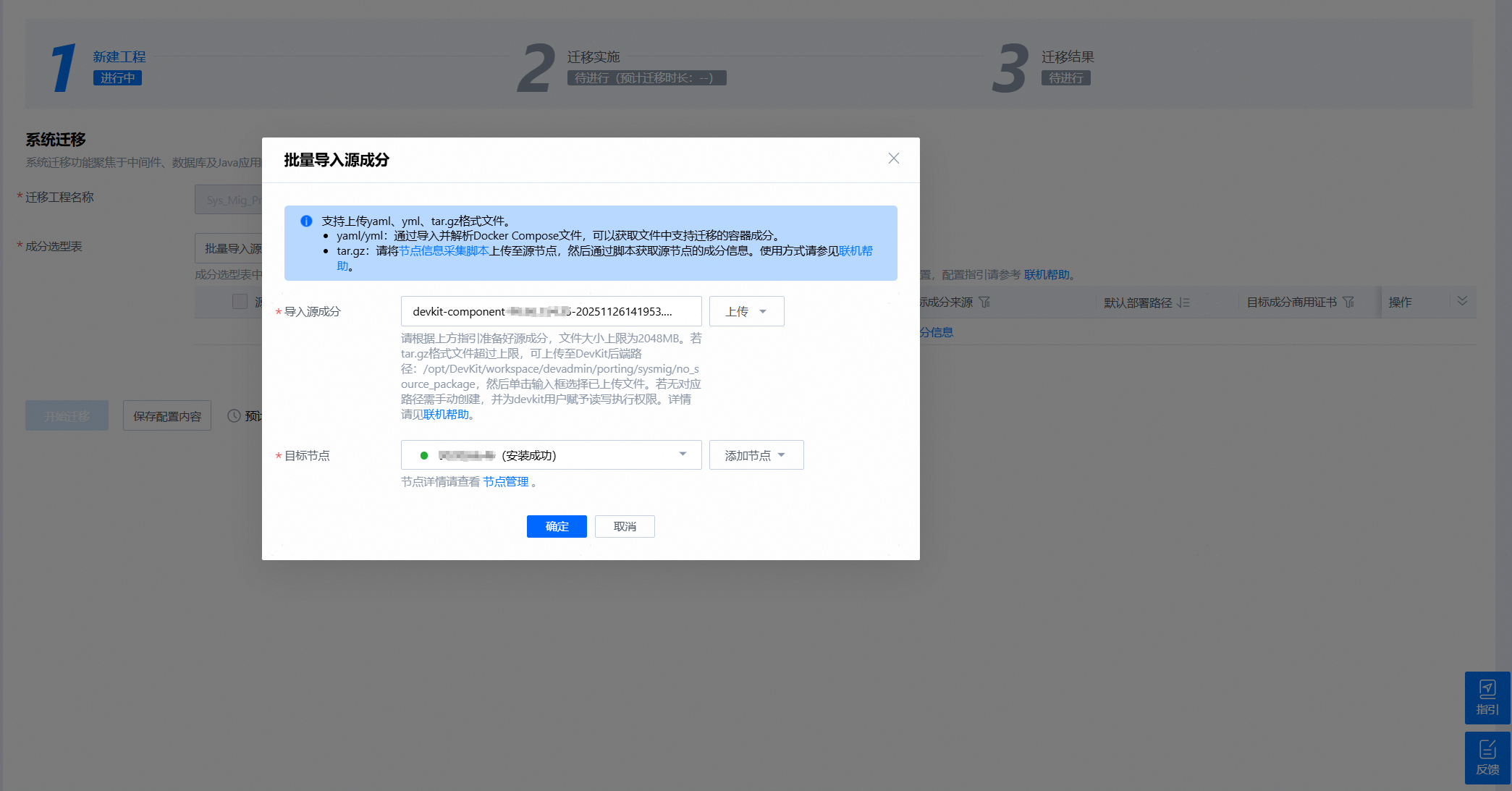
result/devkit-component-90.90.66.8-20250102103045.tar.gz
这是现场交付的最终产物,可以直接上传到 DevKit Web 服务进行解析和迁移处理。
五、现场使用时的典型流程
在实际项目中,这个脚本通常作为迁移准备阶段的第一步使用,流程非常固定:
- 在源服务器上执行采集脚本;
- 等待扫描完成,确认 result 目录生成 tar 包;
- 将 tar 包拷贝或上传至 DevKit 平台;
- 在平台侧查看组件识别结果,结合 in_use 标记确认迁移范围;
- 基于自动生成的资产信息,进入后续迁移和改造阶段。
- 将生成的压缩包上传至DevKit客户端进行自动解析。
- 根据解析得到的成分信息候选需要迁移的内容进行迁移
整个过程中,脚本承担的角色是“把复杂现场翻译成迁移工具能理解的语言”。
六、小结
DevKit 虚拟化无损迁移采集脚本并不是为了穷尽所有技术细节,而是围绕迁移这一目标,对“系统资产”进行工程化抽象。它通过统一的扫描入口、规则驱动的识别方式以及清晰的输入输出边界,把原本高度依赖人工经验的迁移前置工作,转化为一次可重复、可验证的一键执行过程。
在复杂、不可控的存量环境中,这种能力往往决定了迁移工作的起点质量,也直接影响后续迁移效率和成功率。