


编译反馈优化PGO原理及示例介绍
发表于 2025/12/05
0
1. 背景介绍
PGO是一种编译技术,它通过收集程序执行期间的runtime信息来优化程序性能。
PGO可以根据实际的运行情况调整优化决策达到提高程序的执行效率的目的。这一技术在GCC、Clang等许多现代编译器中都有实现。
PGO通过通过分析程序使用的特定路径、频繁调用的函数以及其他性能特征,编译器可以更精确地做出决策,选择最合适的优化策略。
PGO还有一些别名:反馈式编译优化、概要文件引导优化、feedback-directed optimization (FDO) 等。
2. PGO原理
PGO首先对程序进行profile(剖分),然后在程序运行时收集runtime数据生成profiling file,之后根据这个profiling file进行针对性的性能优化(比如缩减代码量、减少错误分支预测、重新构建代码布局、减少指令缓存等方法)。
PGO向编译器提供最长执行的代码区域,编译器会对这些特定的区域进行针对性的具体优化,从而达到性能提升的目的。
- 改进代码布局:将频繁执行的代码放在一起,以提高缓存命中率。
- 函数内联:根据调用频率决定是否内联特定函数。
- 循环优化:优化频繁执行的循环,提高循环的执行速度。

- Instrumentation(插桩):编译器在第一次编译程序时,会插入额外代码用于收集运行信息。这些信息包括函数调用频率、热点代码(即经常执行的代码段)、分支孵化率等。插桩后的程序会生成一个可以执行的可执行文件。
- 收集运行数据:使用插桩后的可执行文件运行程序,通常在代表性输入下运行。这可以是在实际使用过程中的输入或测试用例。运行时,插入的代码会记录下运行数据,生成一个性能数据文件(Profile Data),该文件包含了执行路径、分支决策等信息。
- 优化编译:使用收集到的性能数据,重新编译程序。在这个阶段,编译器可以根据实际的执行情况进行优化,比如:优化最常用的路径。对热点函数进行内联编译。改进数据布局,提高缓存命中率。优化热路径的分支预测。
- 生成最终可执行文件:基于优化的结果,生成最终的可执行文件,通常会有更好的性能表现。
3. 使用PGO实例
我们使用一个简单的计算密集型应用程序作为示例:计算Fibonacci 数列的 n 项。使用 PGO 来优化这个程序,显示如何通过 PGO 提升性能。
示例代码:
#include <stdio.h>
unsigned long fib(int n) {
if (n <= 1) return n;
return fib(n - 1) + fib(n - 2);
}
int main() {
int n = 40; // 计算第40个Fibonacci数
unsigned long result = fib(n);
printf("Fibonacci(%d) = %lu\n", n, result);
return 0;
}编译和性能测试步骤
(1)首次编译并生成PGO数据
使用 GCC 编译该程序,并使用 -fprofile-generate 选项生成 profile 数据。
gcc -fprofile-generate -o fibonacci fibonacci.c(2)运行程序获取profile文件
运行生成的程序使之输出第 40 个 Fibonacci 数,但更重要的是,它将生成 profile 数据文件(通常为 .gcda 和 .gcno 文件)。
./fibonacci(3)使用PGO数据进行二次编译
使用生成的 PGO 数据重新编译程序,以优化代码。使用-fprofile-use选项。
gcc -fprofile-use -o fibonacci_opt fibonacci.c(4)比较运行时间
使用time命令来比较未优化版本和 PGO 优化版本的运行时间。】
# 测试未优化版本
time ./fibonacci
# 测试优化版本
time ./fibonacci_opt优化结果对比:
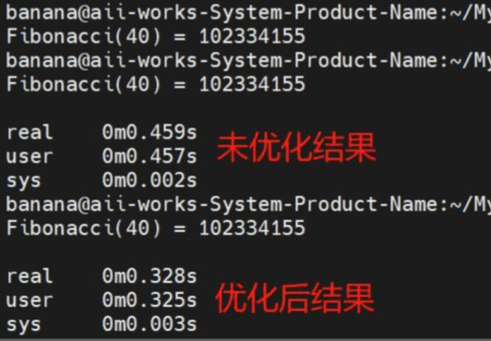
4. 结论
4.1应用方向
PGO在性能敏感型应用上有很大的用武之地,比如:
- 高性能计算(HPC)程序
- 游戏引擎/游戏开发
- 嵌入式系统
4.2 注意事项
- 测试代表性:收集的运行数据需要保证具有代表性,这样才能得到有效的优化效果。
- 增加编译时间:由于需要额外的插桩和两次编译过程,这会增加开发周期。
- 复杂性:对于初学者来说,设置和使用PGO的过程可能稍微复杂,需要理解编译器和性能分析工具的使用。