


CPU 高速缓存管理策略及鲲鹏性能优化技术
发表于 2025/12/05
0
1 CPU Cache管理策略
Cache(高速缓存)作为计算机体系结构中 “CPU - 内存” 层级的核心组件,通过局部性原理(时间局部性、空间局部性)减少 CPU 对主存的访问延迟,是提升系统性能的关键技术。
本文将系统阐述 Cache 的核心管理策略(包括映射策略、替换策略、写策略),深入分析各策略的原理、优缺点及适用场景,并介绍鲲鹏服务器的一些相关性能优化技术。
1.1 缓存组成
- 高速缓存行(Cache line)是 Cache 进行管理的一个最小存储单元。
- 主存与Cache 之间,不同Cache层级之间,数据传送的单位是Cache Block。
- 鲲鹏 920 处理器的 L1 Cache, L2 Cache 的 Cache Block 为 64 字节,L3 Cache 的 Cache Block 可配置为 64 字节 或 128 字节。

1.2 缓存映射
高速缓存映射: 从主存中取出的数据应该放置在Cache的什么位置?
高速缓存映射方式有三种:直接映射、全相联映射 和 组相联映射。
直接映射: 主存中的某个地址对应的数据只能放在Cache中的特定位置。
全相联映射:主存中的某个地址对应的数据能存放于Cache中的任何位置。
组相联映射:主存中的某个地址对应的数据只能存放在Cache中特定组,但可以放在组中任何位置,这一组位置称之为一个组(Set),组中每个位置称为一个 路(Way)。

1.3 替换策略
Cache的替换策略是指当Cache中没有空闲块且发生Cache未命中时,用于决定替换哪个现有块的算法。
常见的替换策略:随机替换(Random)、最近最少使用(LRU)及其变种、动态重索引间隔预测算法( DRRIP )。
1.3.1 随机替换
当需要替换Cache中的一个块时,随机选择一个块进行替换。
优点:实现简单,无需额外的硬件支持。
缺点:性能不稳定,局部性利用不足。
1.3.2 最近最少使用替换(LRU)
记录每个Cache块的历史使用情况,当需要替换时,替换离现在最长时间没有使用的数据项。
优点:能够较好地利用程序的局部性原理,提高Cache的命中率。
缺点:当相联度较高时,存储开销大,对于N组M路组相联结构,需要N*M*Log2(M) 比特来记录状态位;实现较为复杂,需要额外的硬件支持来记录和更新块的使用情况。在大规模Cache中,实现真正的LRU可能会带来较高的硬件开销和时间延迟。
鲲鹏处理器的 L1 Cache 为 4 路组相联,使用 LRU 替换策略。
1.3.3 伪LRU策略
- 是LRU策略的近似实现。通过树形结构(二叉树)和位标志记录缓存块的访问模式,而非精确记录每个块的访问时间。
- 对于N路组相联结构的Cache, 每组需要N-1比特来记录状态位。
- 每个节点的标志位(0或1)表示 “最近访问的方向”:0:左子树最近没有被访问。1:右子树最近没有被访问。
- 替换时根据节点标志位选择伪LRU块。当访问缓存块,每个经过的节点标志位被设置为 “相反方向” 。
1.3.4 DRRIP (动态重索引间隔预测算法)替换策略
为每一个Cache line 关联一个重引用预测值(Re-Reference Prediction Value,RRPV),表示该块未来被再次访问的间隔预测值。
重引用预测值越大,表明该块被访问的概率越低。 RRPV 的值根据历史访问模式动态调整。
1.3.5 鲲鹏处理器替换策略
结合鲲鹏处理器替换策略进行优化:根据具体场景选择替换策略
- L1 Cache 主要是LRU替换算法。
- L2 Cache替换策略为 DRRIP。
- L3 可支持随机替换算法,DRRIP, PLRU替换算法,且寄存器可配。
1.4 写策略
Cache 的写策略(Write Policy)决定了数据在 Cache 与主存之间的同步机制。
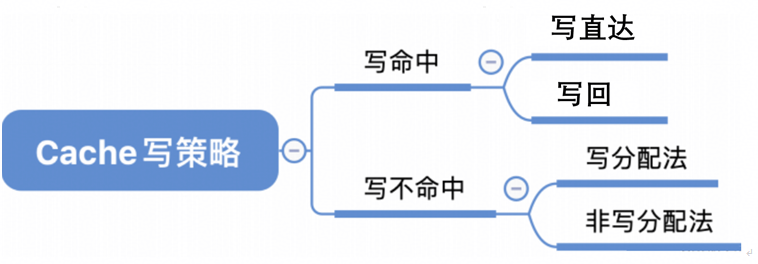
写命中策略均可以和写不命中策略进行搭配。
- 通常写回搭配写分配。写直达搭配非写分配。
- 鲲鹏处理器默认使用写回和写分配策略(性能通常最佳)。性能调优: 对特殊内存位置可以设置 为读写不分配 (non-cacheable)对只访问一次的大型数据结构,避免污染Cache。
1.4.1 写命中策略
Cache 写命中之后可以采用 写直达(Write-Through)与写回(Write-Back)策略。
- 写直达策略数据不仅写入缓存,同时也会立即写入主存。优点:缓存和主存中的数据保持一致,简化数据一致性管理;适合读密集型应用。缺点:写操作开销大;内存总线负载高 ;不适合写密集型应用。
- 写回策略数据只写入缓存,而不会立即写入主存;数据被替换时,才将修改后的数据写到下级存储;每个Cache行需要增加一个dirty位,表示数据是否被修改过。优点:写操作速度快;减少内存总线负载。缺点:数据一致性管理复杂;实现复杂,需要实现缓存行状态跟踪、写回机制等。
1.4.2 写不命中策略
Cache 写不命中之后可以采用 写分配(Write-Allocate)与 非写分配( Not-Write-Allocate )策略。
Cache 的写分配策略是指发生写操作且Cache未命中时,是否将数据加载到Cache中的策略。
- 写分配策略系统先将数据加载到Cache中,然后对该Cache行进行写操作。
- 非写分配策略直接将数据写入主存,而不加载到Cache中。
2 鲲鹏性能优化技术
2.1 鲲鹏PGO优化
PGO(Profile-guided optimization)是一种编译优化技术
- 传统的编译器优化借助于程序的静态分析结果以及启发式规则进行优化。
- PGO优化: 编译器使用程序的运行时 profiling 信息,生成更高质量的代码,从而提高程序的性能。
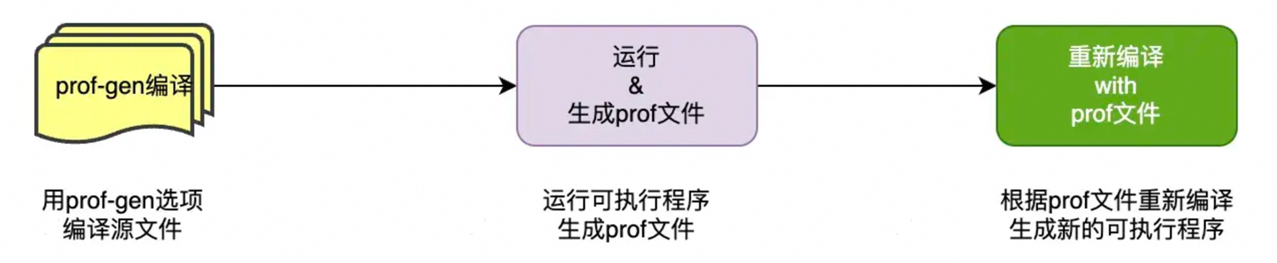
PGO优化流程
- 编译器对程序源码插桩编译,生成插桩后的程序(instrumented program)。编译时增加-fprofile-generate=<profile_dir>选项。
- 运行插桩后的程序,生成 profile 文件。
- 通过编译选项 -fprofile-use=<profile_dir> 使用收集的profile文件,再次对源码进行编译,完成PGO优化编译。
2.2 L0 Cache
根据鲲鹏主力场景业务workload特征分析:
- 在大数据、数据库、存储、虚拟化等应用中,85种场景只有9种场景对LLC容量敏感,76种对于Cache容量不敏感(容量减少90%,性能降低<10%)。
- 利用这一特性,在非LLC容量敏感场景下,将部分LLC容量作为高性能 L0 内存使用,实现热点数据访问时延降低80%、带宽增加5倍,为鲲鹏性能优化带来广阔的创新空间。