


使用KSYS工具解决某交易所TCP握手时延长问题实践
发表于 2025/12/05
0
一、案例背景
交易系统行情剧烈波动,高并发,需要确保系统在峰值压力下仍能 “扛住流量”,避免因并发过高导致的业务中断。
使用的算法:
- 硬算:使用TEE(可信执行环境)国密算法的硬件加速功能,涉及REE和TEE的交互。
- 软算:未使用硬件加速功能,不涉及TEE。
现状:硬算的TCP握手时间明显高于软算,不达预期。
目标:10线程,1k连接情况下,硬算TCP握手时间小于1w us。
二、环境信息
| 服务器 | 架构 | CPU | 操作系统 |
|---|---|---|---|
| 鲲鹏服务器 | ARM架构 | Kunpeng 920处理器 | OpenEuler 22.03 |
三、使用工具
分析过程中使用了鲲鹏系统性能方法论分析工具(KSYS)来采集性能数据,下载链接:鲲鹏DevKit开发套件下载中心-鲲鹏社区。
工具简介及使用方法:
鲲鹏系统性能方法论分析工具功能说明-鲲鹏系统性能方法论分析工具-命令行-用户指南-鲲鹏开发套件开发文档-鲲鹏社区。
四、性能瓶颈分析
使用KSYS工具分别采集了相同配置条件下硬算和软算REE侧的系统性能数据。采集命令如下:
./ksys collect -d 30 -p <PID>4.1热点函数
硬算:
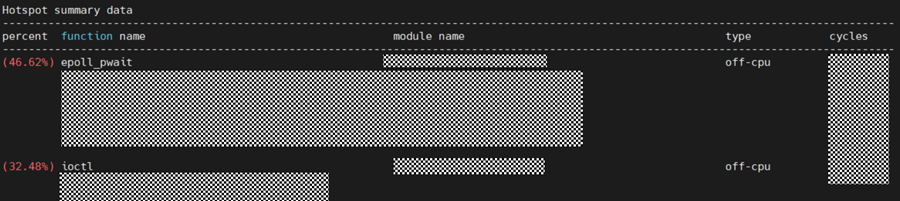
软算:

基于KSYS 的blocked sample分析能力 ,发现硬算接近80%的耗时为epoll_pwait和ioctl。其中软算和硬算epoll_pwait占比都高,为系统框架结构导致,无法优化。ioctl耗时为与 TEE(可信执行环境) 交互频繁导致,系统态压力集中在设备调用。
4.2网络
硬算:

网卡利用率高达51.73%,每秒接收的数据包多达40512,符合业务特点
4.3软中断
硬算:
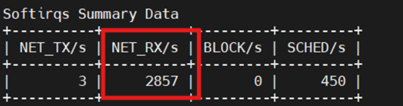
每秒的网络接收软中断次数仅有2857远低于网卡收包速率,网络数据堆积未能及时分发到内核协议栈。
4.4 CPU使用情况
硬算:

内核态执行时间cpu占比12.75%,内核态处理开销很高,ioctl 调用链属此类,说明大量的线程在系统调用中停留。软中断cpu占比也仅有0.17%,网络协议栈(如 TCP/IP)高度依赖 softirq,结合网卡rxpck/s = 40512,软中断NET_RX/s = 2857,当前响应能力严重不足。
4.5 总结
在硬算中ioctl 注册临时共享内存块(SHARED)后REE侧线程是阻塞等待TEE侧返回结果,结合KSYS采集到的数据,我们可以得到(猜测):硬算整体性能瓶颈主要是ioctl 造成的 off-cpu 时间高,当多个线程并发调用 SDF 接口时,会导致 ioctl 的调用链堵塞(off-cpu 占比高达 32.48%),系统资源被占用,影响网络协议栈的处理能力,进而拖慢 TCP 握手过程。
五、优化效果
为解决ioctl问题,将共享内存修改成REGISTER类型,REE 侧线程注册完共享内存后不再阻塞等待 TEE 返回结果。它可以立刻退出或继续处理其他任务,提升了并发性。
5.1优化后硬算性能数据
热点函数:

软中断:
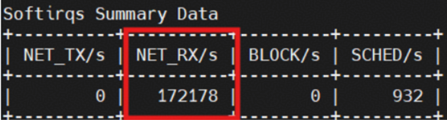
CPU使用情况:

前后变化
| 指标 | 优化前 | 优化后 | 变化分析 |
|---|---|---|---|
| %system | 12.75% | 2.76% | 内核态调用压力大幅降低 |
| %softirq | 0.17% | 1.36% | 网络协议栈响应明显恢复 |
| NET_RX/s | 2857 | 172178 | 网卡数据处理能力大幅上升 |
5.2调优效果
| 参数配置 | 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|---|
| 10线程,1k连接 | TCP握手时间 | 2w us | 4k us | 500% |
| 10线程,2k连接 | TCP握手时间 | 6w us | 6k us(有波动) | 500%+ |