


基于Devkit性能分析工具的某互联网搜推模型训练调优实践
发表于 2025/12/05
0
1 、案例背景
在模型训练与推理流程中,CPU 与 NPU 的协同工作机制复杂。由于两种硬件架构特性差异显著,导致在实际运行中难以快速判断性能瓶颈。
现状:Kunpeng CPU的NPU服务器机型验证搜广推模型训练,对比X86 CPU的NPU服务器有性能差异。
搜广推模型训练特点:
模型训练流程:数据读取(H2D)->模型前传(NPU)->模型反传(NPU)->梯度AllReduce(D2D)->参数更新(D2H)
2 、环境信息
|
服务器 |
架构 |
CPU |
NUMA数 |
CPU核数 |
|
鲲鹏服务器 |
Arm架构 |
Kunpeng 920处理器 |
8 |
640 |
3 、使用工具
分析过程中使用了Devkit系列性能分析工具采集性能指标,下载链接:鲲鹏DevKit开发套件下载中心-鲲鹏社区。
工具简介及使用方法:
介绍-命令行-用户指南-鲲鹏开发套件开发文档-鲲鹏社区 (hikunpeng.com)
4、性能瓶颈分析
4.1 热点函数
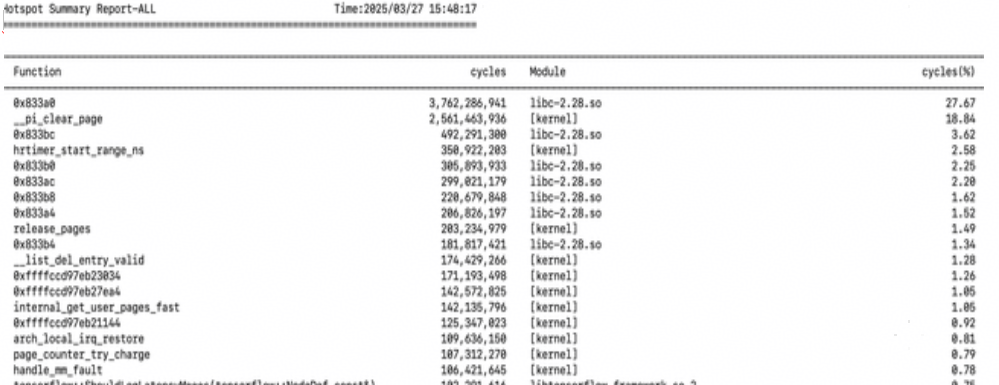
通过objdump发现0x833a0对应了libc-2.28.so的explict_bzero/memcpy函数,业务存在比较高的访存开销。
4.2 微架构分析

CPU后端瓶颈接近65%
(1) exe ports util:流水线并行效率低,不少uops是串行执行,并发度差
(2) memroy bound:cache压力大
4.3 访存分析
DDRC带宽:

NODE-NODE流量矩阵:
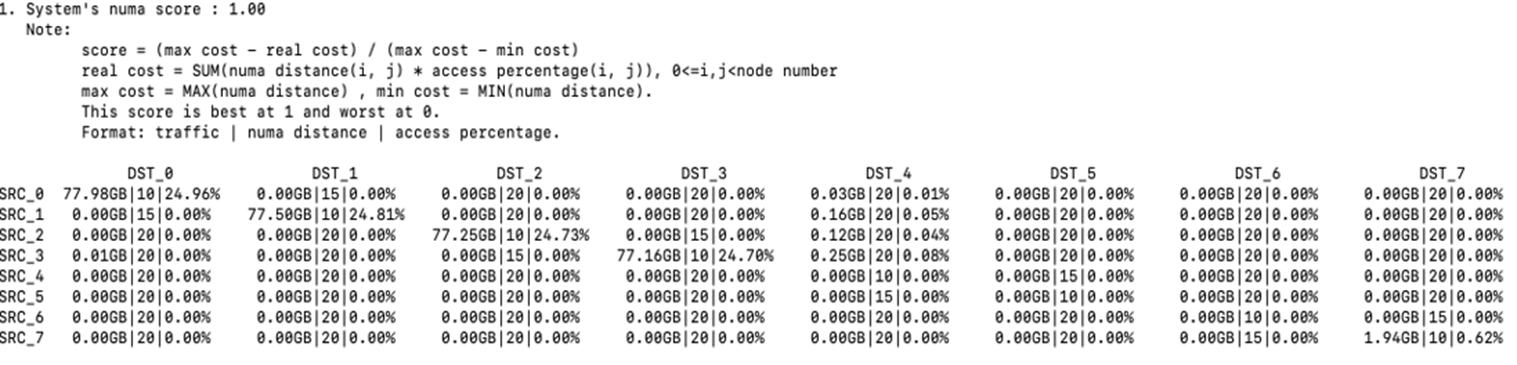 不存在跨CHIP/DIE访存,但是没有充分利用各NUMA Node上的CPU和DDRC带宽。
不存在跨CHIP/DIE访存,但是没有充分利用各NUMA Node上的CPU和DDRC带宽。
5、优化手段和效果
5.1 优化手段
(1)基于热点分析memcpy占用较高的情况,使用鲲鹏glibc库优化memcpy开销
(2)针对未充分利用DDRC带宽的情况,4NUMA绑核优化为8NUMA绑核
(3)当前系统开启了超线程,考虑到可能存在的逻辑核竞争问题,绑核时只绑定物理核。
5.2 优化效果
(1)使用鲲鹏glibc后,吞吐量有所下降,考虑可能原因为当前模型训练的数据特征、内存访问模式和鲲鹏memcpy的优化方向不匹配
(2)使用8NUMA绑物理核后,吞吐量提升15%,一方面充分利用了DDRC带宽,一方面充分利用了CPU资源。