


基于鲲鹏KAE的MinIO压缩加速参考实践
发表于 2025/12/11
0
1 非商用声明
本实践中提供的代码和调优方法仅供用户参考使用,提供的demo代码仅用于用户验证方案可行性以及性能效果对比,用户可参考构建自己的软件。
2 方案介绍
2.1 背景
MinIO 作为一款高性能的开源对象存储系统,凭借其对 Amazon S3 协议的全面兼容、分布式架构设计以及轻量化的部署特性,已成为云原生时代主流的存储解决方案。其高吞吐、低延迟的性能优势,能够高效支撑日志处理、AI 数据湖等多种应用场景;尤其在大语言模型(LLM)领域,结合检索增强生成(RAG)技术,可实现高效的数据检索与响应。通过对 MinIO 进行针对性调优,可充分释放鲲鹏服务器的硬件潜能,提升应用性能。
2.2 方案简介
本参考实践推荐使用以下方案在鲲鹏服务器上对MinIO进行性能优化:
- 系统性能调优:通过配置服务器性能模式,应用绑核等方法,提升MinIO在鲲鹏服务器上的性能;
- 压缩传输方案:通过将原始文件使用KAE进行高性能压缩后再传输,优化网络带宽和磁盘空间的占用,该方案对文本日志类文件压缩效果较好,图片视频类等已压缩过的文件则没有效果,不建议使用本方案;
本参考实践的优化方案架构图如图所示,在MinIO Server服务器通过系统性能调优提升MinIO程序性能,在存储服务层通过KAE高性能压缩方案优化网络传输和空间占用。
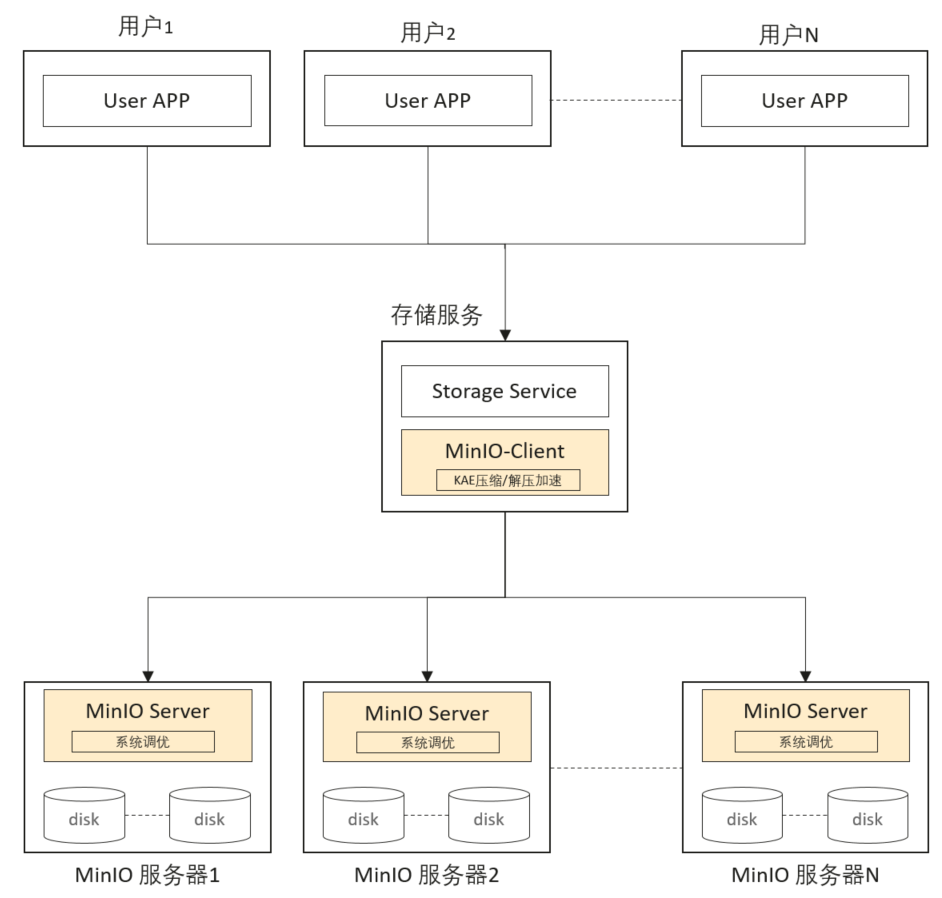
2.3 部署方案
典型硬件配置
节点类型 | 服务器配置 | 数量 | 部署内容 |
MinIO Server节点 | CPU:鲲鹏处理器(本实践采用7270Z) 内存:256GB或以上 存储:NVME盘 | 1台或以上 | 部署MinIO Server,用于存储数据。 |
MinIO Client节点 | CPU:鲲鹏处理器(本实践采用7260) 内存:256GB或以上 存储:NVME盘 | 以实际业务需求为准 | 部署MinIO Client,对内与MinIO Server通信,对外为User APP提供封装后的服务接口。 |
软件版本
本参考实践使用的软件配套版本如下:
软件 | 版本 | 说明 |
MinIO | 2025-09-07T16-13-09Z | MinIO Server |
MinIO Python SDK | 7.2.18 | MinIO Client组件 |
KAE | 2.0 | 硬件加速模块 |
Python | 3.9 | |
OS | openEuler release 22.03 (LTS-SP4) | 物理机OS |
3 部署指导
3.1 软件安装
MinIO安装指导(Server服务器)
本参考实践介绍使用源码编译的方式安装MinIO Server,属于示例Demo,使用其它方式(例如容器部署,二进制部署)也可以正常安装部署MinIO,且同样适用本实践的优化方案。如果需要商用部署,请参考官方MinIO部署文档(https://github.com/minio/minio)。
本实践介绍下载二进制和源码编译部署的安装方式,使用一种即可。
二进制文件下载链接: https://dl.min.io/server/minio/release/linux-arm64/minio
下载后, 将文件配置可执行权限,即可使用:
# 配置可执行权限
chmod +x minio
# 测试能否正常执行
./minio --version源码编译方式,首先部署编译MinIO所需的go环境:
# 安装基础编译工具链
sudo dnf groupinstall "Development Tools" -y
sudo dnf install git wget curl gcc make pkgconfig -y
# 从镜像站下载go的包
wget -O go1.24.2.linux-arm64.tar.gz 'https://mirrors.aliyun.com/golang/go1.24.2.linux-arm64.tar.gz'
# 解压安装go
tar -C /usr/local -xzf go1.24.2.linux-arm64.tar.gz
# 配置环境变量(对当前用户生效)
echo 'export PATH=$PATH:/usr/local/go/bin' >> ~/.bashrc
echo 'export GOPATH=$HOME/go' >> ~/.bashrc
echo 'export PATH=$PATH:$GOPATH/bin' >> ~/.bashrc
# 加载环境变量
source ~/.bashrc
# 验证安装
go version
# 应输出:
# go version go1.24.2 linux/arm64拉取MinIO源码,并编译二进制文件(MinIO Server安装):
# 克隆 MinIO 源码(官方仓库)
git clone https://github.com/minio/minio.git
cd minio
# 可选:切换到稳定版本分支(推荐)
# 可以选择较新的稳定版,本实践使用的RELEASE.2024-09-10T17-32-36Z
git checkout RELEASE.2025-09-07T16-13-09Z
# 编译 MinIO
make build
# 验证生成的可执行文件
./minio --versionKAE安装指导(Client服务器)
本实践基于7260和7270Z的鲲鹏 CPU+openEuler22.03-LTS-SP1操作系统环境进行。如果使用其它鲲鹏CPU和其他操作系统,需要申请License并安装配套版本的KAE,详情可参考KAE GitCode开源地址:https://gitcode.com/boostkit/KAE
采用KAE压缩方案时,需在Client服务器上安装KAE。注意,根据不同的操作系统版本,可能需要选择不同的KAE安装版本。
本实践介绍rpm包安装和源码编译安装方式,使用一种方式完成安装即可。
rpm包获取链接(根据系统版本自行选择对应zip包,若没有对应版本则使用源码编译方式): https://gitee.com/kunpengcompute/KAE/releases
# 以openEuler22.03 SP4为例
unzip openeuler22.03_sp4.zip
cd openeuler22.03_sp4
# 安装驱动
rpm -ivh kae-driver-2.0.1-1.aarch64.rpm
# 安装zip组件
rpm -ivh kae-zip-2.0.1-1.aarch64.rpm源码安装KAE2.0:
# 安装前检查
lspci | grep -i engine
# 如果有ZIP Engine则可正常进行后续安装动作,如果没有可能为设备不支持或者需要申请license
# 安装依赖
yum install -y make kernel-devel-`uname -r` libtool numactl-devel openssl-devel lz4-devel libzstd-devel chrpath cmake libunwind-devel
# 配置环境变量
export OPENSSL_ENGINES=/usr/local/lib/engines-1.1
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
# 安装KAE
git clone https://gitcode.com/boostkit/KAE.git -b kae2
cd KAE
sh build.sh all
# 安装后检验kaezlib压缩
# 功能测试
cd KAEZlib/test/gtest/
sh build.sh
./kaezlibtest --gtest_filter=*Case*
# 预期结果,SmallCase与LargeCase两个用例的执行结果均为passed
# 编译性能测试工具
cd KAEZlib/test/perftest
make
# 使用系统zip压缩
./zip_perf -m 8 -l 10240 -n 1000
# 使用kaezip压缩
./kaezip_perf -m 8 -l 10240 -n 1000
# 预期结果,压缩速度大幅提升,如果没有大幅提升,则系统使用的CPU压缩,没有使能KAE硬件加速3.2 MinIO Server部署
MinIO Server的服务拉起命令如下:
# 通过环境变量,指定登陆MinIO登陆信息
export MINIO_ROOT_USER=minioadmin
export MINIO_ROOT_PASSWORD=********
# 示例中2个值都配置为minioadmin
# 单机部署场景,根据存储位置修改命令,拉起MinIO服务
./minio server /data/minio/data00 /data/minio/data01 /data/minio/data02 --console-address :9001
# 可通过该写法简化部署命令
./minio server /data/minio/data0{0,1,2} --console-address :9001
# 分布式多机部署场景,需要根据每台机器的IP和存储位置修改命令,示例命令中为示意IP
# 需要在每台服务上,都执行该命令,最终拉起分布式MinIO服务
# 命令中的xx.xx.xx.1/2/3分别代指3台服务器IP,根据实际使用情况修改
./minio server http://xx.xx.xx.1/data/minio/data0{0,1} http://xx.xx.xx.2/data/minio/data0{0,1} http://xx.xx.xx.3/data/minio/data0{0,1} --console-address :9001
# 拉起成功后,会有以下格式打屏,其中包含API/WebUI的登陆信息和登陆地址
MinIO Object Storage Server
Copyright: 2015-2025 MinIO, Inc.
License: GNU AGPLv3 - https://www.gnu.org/licenses/agpl-3.0.html
Version: DEVELOPMENT.2025-09-07T16-13-09Z (go1.24.2 linux/arm64)
API: http://xx.xx.xx.xx:9000
RootUser: minioadmin
RootPass: minioadmin
WebUI: http://xx.xx.xx.xx:9001
RootUser: minioadmin
RootPass: minioadmin
CLI: https://docs.min.io/community/minio-object-store/reference/minio-mc.html#quickstart
$ mc alias set 'myminio' 'http://xx.xx.xx.xx:9000' 'minioadmin' 'minioadmin'
Docs: https://docs.min.io可以根据打屏信息,登录到http://your_host_ip:9001/访问MinIO的web页面。
考虑到部分用户在部署 MinIO 服务时,并未独占整台服务器,而是与其他业务共用同一主机,建议采用 CPU 绑核的方式运行 MinIO,以限制其占用的 CPU 资源。这样不仅可以实现资源的精细化分配,还能有效降低不同程序之间的相互干扰,提升系统整体稳定性与可预测性,绑核的基础参考命令如下:
# 使用0到15核,拉起MinIO服务
taskset -c 0-15 ./minio server /data/minio/data00 /data/minio/data01 /data/minio/data02 --console-address :90013.3 MinIO Client部署
MinIO Python SDK应用于存储服务,本实践介绍如何通过 MinIO Python SDK 部署 MinIO 客户端,实现文件的上传与下载功能。使用其他兼容 Amazon S3 协议的客户端(例如 boto3)或直接通过 MinIO Web 控制台进行操作,同样能够完成所介绍的功能。
MinIO-Python-SDK的安装方式:
# 使用pip安装MinIO-Pytyon-SDK,本实践使用的Python版本为py3.9
pip install minio
# 查看MinIO-Python-SDK版本
pip list | grep minio
# 本实践使用的版本为7.2.18参考的python脚本内容如下,具体操作流程为,导入MinIO库,通过服务地址和登陆信息,实例化一个客户端,然后使用fput_object和fget_object方法来进行文件的上传和下载:
import time
from minio import Minio
from minio.error import S3Error
# 配置基础信息:
# MINIO_ENDPOINT为已经拉起的MinIO服务,ACCESS_KEY和SECRET_KEY为登陆信息(拉起服务时配置的MINIO_ROOT_USER和MINIO_ROOT_PASSWORD),BUCKET_NAME为存储桶的名称(可以类比为传统文件系统中的“文件夹”)
# 其中OBJECT_NAME为上传后的保存名称,LOCAL_FILE_PATH为本地文件名称,2个值可以配置相同,a.txt可以自行创建
MINIO_ENDPOINT = "xx.xx.xx.xx:9000"
ACCESS_KEY = "minioadmin"
SECRET_KEY = "********" # 此处*为示例,实际使用时需填入真实值,后续都使用*进行表示
BUCKET_NAME = "test-bucket"
OBJECT_NAME = "a.txt"
LOCAL_FILE_PATH="a.txt"
# 初始化 MinIO 客户端(不使用 TLS)
client = Minio(
endpoint=MINIO_ENDPOINT,
access_key=ACCESS_KEY,
secret_key=SECRET_KEY,
secure=False, # 如果使用 HTTPS,则设为 True
)
# 如果bucket不存在,则创建一个bucket
if not client.bucket_exists(bucket_name=BUCKET_NAME):
client.make_bucket(bucket_name=BUCKET_NAME)
# ===== FPUT 操作(文件上传)=====
print("Uploading file...")
start_time = time.perf_counter()
print(start_time)
try:
result = client.fput_object(
bucket_name=BUCKET_NAME,
object_name=OBJECT_NAME,
file_path=LOCAL_FILE_PATH
)
print("fput object_name is: ", result.object_name)
OBJECT_NAME_DOWNLOAD = result.object_name
put_time = time.perf_counter() - start_time
print(f"✅ Upload completed in {put_time:.4f} seconds")
except S3Error as e:
print("❌ Upload failed:", e)
# ===== FGET 操作(文件下载)=====
downloaded_file = "./downloaded_a.txt"
print("Downloading file...")
start_time = time.perf_counter()
try:
client.fget_object(
bucket_name=BUCKET_NAME,
object_name=OBJECT_NAME_DOWNLOAD,
file_path=downloaded_file
)
get_time = time.perf_counter() - start_time
print(f"✅ Download completed in {get_time:.4f} seconds")
except S3Error as e:
print("❌ Download failed:", e)可通过该脚本,验证MinIO Client的上传下载能力。
上述操作,也可以通过WebUI界面来完成,拉起服务后,登陆到MinIO Serer的IP,端口使用9001,即可访问MinIO的Web页面(拉起服务时可配,或者查看服务拉起打屏的内容),可以进行文件查阅,也可以上传和下载(如果未显示文件,可以尝试点击刷新按钮,即可看到目标文件)。

4 MinIO性能测试和优化实践
4.1 系统优化配置
不同机型的BIOS配置方式有差异,具体操作按实际机器BIOS配置项为准,本实践采用7270Z的机器作为Server进行介绍,以下系统优化均在Server节点进行配置。
4.1.1 配置服务器为高性能模式
调优策略:
配置服务器为高性能模式,让CPU运行在标称频率,不动态调频。
操作指导:
步骤1:
进入BIOS,依次选择“BIOS -> Advanced -> Power And Performance Configuration -> Power Policy”
步骤2:
设置“Power Policy”选项为“Performance”,然后保存配置。
4.1.2 开启服务器超线程
调优策略:
使能超线程,提高处理器的并行处理能力和资源利用率,在多任务或多线程工作负载下提升整体性能。
操作指导:
步骤1:
进入BIOS,依次选择“BIOS -> Advanced -> Power And Performance Configuration -> CPU PM Control -> SMT2”
步骤2:
设置“SMT2”选型为“Enable”,然后保存配置
开启超线程后,一个物理CPU核心会变成两个逻辑核心。在进行应用程序绑核时要注意,如果把不同的应用分别绑到同一个物理核心对应的两个逻辑核心上,它们之间可能会互相干扰,影响性能。
为了实现绑核不跨NUMA,可以参考以下操作:
# 使用命令,查看CPU物理核与逻辑核的对应关系
lscpu -e
# 示例输出如下
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ MHZ
0 0 0 0 0:0:0:0 yes 2900.0000 400.0000 -
1 0 0 0 0:0:0:0 yes 2900.0000 400.0000 -
2 0 0 1 1:1:1:0 yes 2900.0000 400.0000 -
3 0 0 1 1:1:1:0 yes 2900.0000 400.0000 -
# CPU列,代表的逻辑核,也就是绑核时指定的核
# CORE列,代表的物理核,示例中每个物理核出现2次,代表对应2个逻辑核
# 示例中,逻辑核0/1对应的物理核0,建议应用绑核运行时,同时包含0/1核4.1.3 网卡亲和的NUMA绑核
调优目的:
MinIO Server进程所使用的CPU核,与MinIO Server所使用的网卡,建议处于同一个NUMA节点下,提高程序性能。
操作指导:
# 使用ifconfig,查询IP所对应的网卡
ifconfig
# 查看该网卡的基本信息(可选)
ethtool enp65s0f1np1
# 查询该网卡所属的numa节点
cat /sys/class/net/enp65s0f1np1/device/numa_node
# 得到非负值则继续
# 例如得到1,代表处于node1的NUMA节点
# 使用lscpu,查看该NUMA对应的cpu核
lscpu |grep node1
# 例如如下输出,再启动MinIO服务时,将其绑在对应核上
NUMA node1 CPU(s): 64-127
# 例如,使用64到79核,拉起MinIO服务
taskset -c 64-79 ./minio server /data/minio/data00 /data/minio/data01 /data/minio/data02 --console-address :90014.1.4 使用tuned进行系统参数配置
调优目的:
使用tuned进行系统参数配置,提高系统性能。配置文件可参考MinIO官方提供的配置文件(参考链接:https://github.com/minio/minio/tree/master/docs/tuning)。
操作指导:
# 安装tuned,本实践采用的tuned版本为2.19.0
yum install tuned
# 获取tuned.conf文件
wget https://raw.githubusercontent.com/minio/minio/master/docs/tuning/tuned.conf
# 创建目录,将配置文件移动到指定目录
sudo mkdir -p /usr/lib/tuned/minio/
# 注意,不同tuned版本,配置文件存放路径可能不同
# 例如2.24.0的tuned需要在/usr/lib/tuned/profiles下创建路径并放置conf文件
# 将配置文件移动到指定目录
sudo mv tuned.conf /usr/lib/tuned/minio
# 使能tuned为minio模式
sudo tuned-adm profile minio4.2 基于KAE的压缩加速方案
可以使用将原文件进行KAE压缩后存储的方案,实现MinIO性能的整体优化。具体实现方式为:
- Client端将原文件使用KAE压缩后再写入MinIO Server,MinIO Server将压缩文件进行存储,这样可同时减少存储空间和对网络传输带宽的占用。
- 从MinIO Server读文件时,将压缩文件进行返回,Client端将接收到的文件使用KAE解压后返回给应用,也可实现减少网络带宽占用。
该方案的加速效果和文件的压缩率呈现正相关,压缩率60%时的性能数据如表所示:
每秒传输文件数(obj/s) | 提升比 | |
优化前 | 280 | |
KAE压缩加速后 | 466 | 66% |
测试条件如下,测试方式为并发摸高最大吞吐测试,相关测试脚本见附录:
- 测试使用10MB的文本文件(https://github.com/zlib-ng/corpora/blob/master/silesia/dickens),使用KAE的zlib压缩后约为6MB,压缩率为60%。
- 测试环境为25Gbps网络带宽,使用4GB/s写速率的NVME磁盘(单机三盘),CPU采用20核绑核(7270Z)。
使用该方案,需要提前按照软件安装章节中的内容,在Client端完成KAE的安装,压缩和解压过程都在Client端进行实现。
为了提高易用性,本实践将MinIO-Python-SDK的API进行封装,在MinIO原有的put_object/get_object/fput_object/fget_object接口中,增加了自动调用KAE进行压缩/解压缩的操作,原API的参数不变,新增参数compress_mode/uncompress_mode来使能KAE压缩/解压缩功能。
方案的整体使用步骤如下:
步骤1:部署KAE:
先按照参考实践中的KAE安装章节,进行KAE部署,如果已部署完成则忽略此步骤。
步骤2:导入KAE环境变量:
在业务应用的运行环境中,导入KAE环境变量(export LD_LIBRARY_PATH=/usr/local/kaezip/lib:/usr/local/lib:$LD_LIBRARY_PATH)。
步骤3:部署压缩方案脚本:
将附录中示例脚本(minio_kae_extension.py),放到和应用脚本同一路径下,或者通过其它方式实现导入示例脚本。
步骤4:存储服务使能KAE压缩:
从示例脚本中导入MinIO使用,替代原有的从MInIO-Python-SDK中导入的MinIO类。导入后,正常初始化Client,然后在写文件/读文件调用时,增加使能压缩/解压的参数,实现快速调用KAE进行加速(注意,压缩文件会自动补充压缩后缀,读文件时时需要使用带压缩后缀的文件名)。
具体使用方式的参考如下:
配置KAE环境变量(export LD_LIBRARY_PATH=/usr/local/kaezip/lib:/usr/local/lib:$LD_LIBRARY_PATH)。
注意,如果未配置KAE环境变量,在KAE未使能的情况下,会自动采用软压缩(CPU压缩),也可正常完成压缩功能。
如果想确认是否在后续压缩时正确调用KAE,可通过如下命令监视KAE资源,如果压缩时示数减少则代表成功调用KAE资源。
watch -n 0.1 cat /sys/class/uacce/hisi_zip-*/available_instances从示例脚本中导入MInIO,并正常实例化Client:
# 将从MinIO-Python-SDK中导入的类,改为从示例脚本中导入
# 将原内容进行替换
# from minio import Minio
# 修改后(拓展脚本名称为minio_kae_extension.py,放在和client脚本相同路径):
from minio_kae_extension import Minio
# 实例化client的用法保持不变
client = Minio(
endpoint=MINIO_ENDPOINT,
access_key=ACCESS_KEY,
secret_key=SECRET_KEY,
secure=False, # 如果使用 HTTPS,则设为 True
)写文件时,接口方法保持不变,通过新增参数使能压缩功能:
# 使用写文件功能时,增加compress_mode="on"使能KAE压缩后上传,若不配置该参数则行为和原minio相同
# 使能压缩后,会对原始文件进行KAE压缩,将存储文件自动增加压缩后缀,并将压缩信息写入metadata
result = client.fput_object(
bucket_name=BUCKET_NAME,
object_name=OBJECT_NAME,
file_path=LOCAL_FILE_PATH,
compress_mode="on",
)
# 可以通过返回值中的object_name得到真实存储的文件名,用于查询和下载
# 若不希望自动添加压缩后缀,可自行对拓展脚本进行修改,但是注意对文件是否压缩做好管理和识别
real_save_name = result.object_name读文件时,注意使用带压缩后缀的文件名,接口方法保持不变,通过新增参数使能解压缩:
# 使用读文件功能时,增加uncompress_mode="on"使能下载后使用KAE解压,若不配置该参数则行为和原minio相同
# 使能解压后,会对对象文件的metadata获取压缩信息(是否压缩,压缩格式),然后进行对应解压操作(若无压缩信息,则不进行解压操作)
client.fget_object(
bucket_name=BUCKET_NAME,
object_name=OBJECT_NAME_DOWNLOAD,
file_path=downloaded_file,
uncompress_mode="on",
)5 附录
5.1 MinIO官方性能测试工具使用指导
可以使用MinIO官方提供的warp工具,进行MinIO的性能测试。可以直接下载二进制文件,解压即用。
下载地址:https://github.com/minio/warp/releases
下载tar.gz压缩包,解压出warp文件即可,本实践用的warp版本为v1.3.1
# 查看整体功能
./warp --help
# 查看具体针对某一操作的使用方法,例如查看上传功能(put)
./warp put --help
# 测试put操作,并发10,文件大小10MB,持续时间1分钟,进行性能测试:
./warp put --host=xx.xx.xx.xx:9000 --access-key=minioadmin --secret-key=******** --concurrent 10 --obj.size 10MiB --duration 60s
# 测试get操作,会先上传一定的文件(通过objects参数指定,默认2500),然后从中开始随机选取文件进行get测试
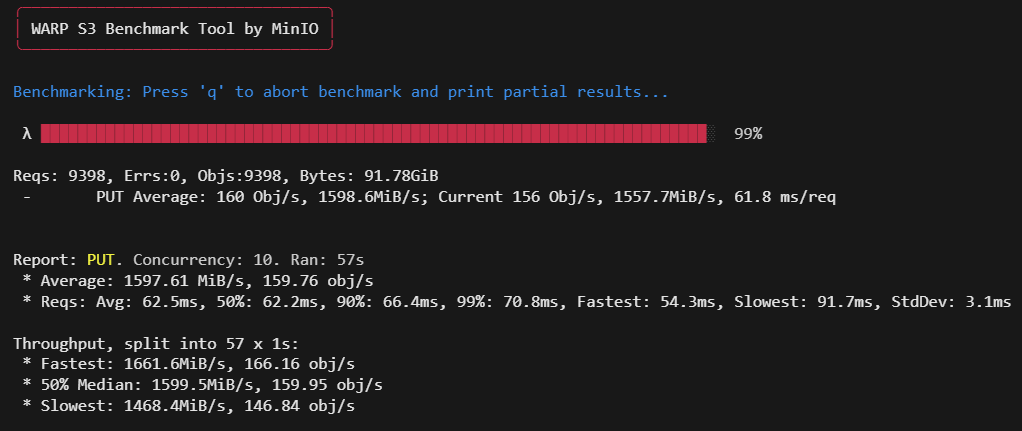
./warp get --host=xx.xx.xx.xx:9000 --access-key=minioadmin --secret-key=******** --concurrent 10 --obj.size 10MiB --objects 200 --duration 60s执行成功后,会出现如下图所示的性能打屏
5.2 负载均衡参考
在分布式部署 MinIO 服务时,每个客户端通常只与一个服务节点建立连接并进行数据传输。如果大量客户端同时访问同一个节点,会导致节点间负载不均,使该节点成为性能瓶颈,进而拖累整个系统的处理效率。
根据实际应用场景,用户可自行决定负载均衡的实现方式,例如MinIO官方提供的Sidekick负载均衡工具(https://github.com/minio/sidekick),或者自行使用Nginx搭建,搭建方式可以参考MinIO官方提供的文档(https://docs.min.io/enterprise/aistor-object-store/installation/linux/load-balancing/),从而实现维持各节点间请求的均匀分布,提升系统整体性能与稳定性。
5.3 KAE压缩加速方案参考实现与性能测试脚本
5.3.1 KAE压缩加速方案参考实现脚本
完整的KAE压缩加速方案脚本(minio_kae_extension.py)参考内容为:
from minio import Minio as _OriginalMinio
from minio.error import S3Error
import os
import zlib
from pathlib import Path
from typing import Optional, Union, List, Any, Generator
from io import BytesIO
class Minio(_OriginalMinio):
"""
继承 Minio 客户端,增加自动压缩/解压功能。
"""
def __init__(
self,
# 新增压缩相关参数
compress_format: str = "zlib", # 支持 zlib格式
compress_level: int = 6, # zlib 压缩等级
*args,
**kwargs
):
super().__init__(
*args,
**kwargs
)
self.compress_format = compress_format.lower()
self.compress_level = compress_level
# 支持的压缩格式,可根据实际情况拓展
self.compress_format_support = {'zlib': '.zlib' }
if self.compress_format not in (self.compress_format_support):
raise ValueError("compress format is supported currently.")
def fput_object(
self,
bucket_name: str,
object_name: str,
file_path: Union[str, bytes, Path],
metadata: Optional[dict] = None,
compress_mode: str = "off",
*args,
**kwargs
):
"""
注意:当 compress_mode="on" 时,需提供 `length`(原始未压缩大小),
用于 metadata 记录。fput_object 会自动提供此值。
"""
file_path = Path(file_path)
original_metadata = metadata or {}
if compress_mode.lower() == "on":
# 获取原始文件大小(用于 put_object 的 length 参数)
original_size = file_path.stat().st_size
# 以流方式打开文件
with open(file_path, "rb") as file_stream:
return self.put_object(
bucket_name=bucket_name,
object_name=object_name,
data=file_stream,
length=original_size,
metadata=original_metadata,
compress_mode="on", # 触发压缩逻辑
*args,
**kwargs
)
else:
# 不压缩,直接调用父类方法(原生流式上传)
return super().fput_object(
bucket_name=bucket_name,
object_name=object_name,
file_path=file_path,
metadata=original_metadata,
*args,
**kwargs
)
def fget_object(
self,
bucket_name: str,
object_name: str,
file_path: Union[str, Path],
uncompress_mode: str = "off",
*args,
**kwargs,
) -> None:
"""
通过 get_object 同步检查 metadata,决定是否解压。
- 若对象含 X-Amz-Meta-Kae-Compressed: true → 通过 get_object 获取流,若需解压则自动流式解压,全程不加载全文件到内存。
"""
output_path = Path(file_path)
output_path.parent.mkdir(parents=True, exist_ok=True)
# 调用自定义 get_object(可能返回原始流或解压流)
response = self.get_object(
bucket_name=bucket_name,
object_name=object_name,
uncompress_mode=uncompress_mode,
*args,
**kwargs
)
try:
with open(output_path, "wb") as f:
# 流式写入,chunk size 可配置(这里用 10MB)
for chunk in response.stream(amt=10 * 1024 * 1024):
f.write(chunk)
finally:
response.close()
response.release_conn()
def put_object(
self,
bucket_name: str,
object_name: str,
data: Any,
length: int,
metadata: Optional[dict] = None,
compress_mode: str = "off",
*args,
**kwargs,
):
"""
覆盖原 put_object:若满足条件,则先压缩再上传,并添加压缩后缀(例如.zlib)和 metadata 标记。
使用流式压缩(ZlibCompressStream),避免全量加载到内存。
"""
original_metadata = metadata or {}
if compress_mode.lower() == "on":
should_compress = True
else:
should_compress = False
if should_compress and self.compress_format=="zlib":
# 使用流式压缩包装器
compress_stream = ZlibCompressStream(data, compress_level=self.compress_level)
# 修改 object_name 添加后缀
suffix = str(self.compress_format_support.get(self.compress_format, ".zlib"))
new_object_name = object_name + suffix
# 添加 KAE metadata 标记
kae_metadata = {
"X-Amz-Meta-Kae-Compressed": "true",
"X-Amz-Meta-Kae-Format": self.compress_format,
"X-Amz-Meta-Kae-Level": str(self.compress_level),
"X-Amz-Meta-Kae-Original-Size": str(length),
}
merged_metadata = {**original_metadata, **kae_metadata}
# 注意:流式压缩无法预知最终长度,因此必须设 length=-1 并指定 part_size
# 如果调用方未提供 part_size,使用默认值(如 10MB)
if "part_size" not in kwargs:
kwargs["part_size"] = 10 * 1024 * 1024 # MinIO 要求 ≥5MB,可配
return super().put_object(
bucket_name=bucket_name,
object_name=new_object_name,
data=compress_stream,
length=-1, # 流式压缩长度未知
metadata=merged_metadata,
*args,
**kwargs
)
else:
# 不压缩,直接调用父类方法
return super().put_object(
bucket_name=bucket_name,
object_name=object_name,
data=data,
length=length,
metadata=original_metadata,
*args,
**kwargs
)
def get_object(
self,
bucket_name: str,
object_name: str,
uncompress_mode: str = "off",
*args,
**kwargs,
):
"""
若对象含压缩标记,则返回流式解压后的对象(兼容 HTTPResponse 接口);
否则返回原生响应。
全程流式处理,不将完整解压内容加载到内存。
"""
response = super().get_object(bucket_name, object_name, *args, **kwargs)
try:
is_kae_compressed = (uncompress_mode.lower() == "on" and response.headers.get("x-amz-meta-kae-compressed") == "true")
if is_kae_compressed and response.headers.get("x-amz-meta-kae-format") == "zlib":
# 返回流式解压包装器,不聚合数据
return ZlibDecompressStream(response)
else:
return response
except Exception as e:
# 出错时确保释放原始连接
try:
response.close()
response.release_conn()
except Exception:
pass
raise RuntimeError(f"Failed to handle object {object_name}: {e}") from e
class ZlibCompressStream:
def __init__(self, source_data, chunk_size=1 * 1024 * 1024, compress_level=6):
"""
:param source_data: 字节数据或可读流(需具备 .read() 方法)
:param chunk_size: 每次从源数据中读取的字节数
"""
self.source = source_data if hasattr(source_data, 'read') else BytesIO(source_data)
self.chunk_size = chunk_size
self.compressor = zlib.compressobj(level=compress_level)
self.buffer = b""
self.finished = False
def read(self, size: int) -> bytes:
"""为 put_object() 实现类似文件的 .read(size) 方法"""
while len(self.buffer) < size and not self.finished:
raw_chunk = self.source.read(self.chunk_size)
if not raw_chunk:
# 输入结束,flush compressor
self.buffer += self.compressor.flush()
self.finished = True
break
compressed = self.compressor.compress(raw_chunk)
if compressed:
self.buffer += compressed
result = self.buffer[:size]
self.buffer = self.buffer[size:]
return result
class ZlibDecompressStream:
"""
流式 zlib 解压包装器,模拟 urllib3.HTTPResponse 行为。
支持 .read(), .stream(), .close(), .release_conn()。
"""
def __init__(self, compressed_stream, chunk_size: int = 1 * 1024 * 1024):
"""
:param compressed_stream: 原始压缩数据流(如 MinIO get_object() 返回的响应)
:param chunk_size: 每次从压缩流读取的字节数
"""
self._compressed_stream = compressed_stream
self._chunk_size = chunk_size
self._decompressor = zlib.decompressobj()
self._buffer = b""
self._finished = False
self.closed = False
def read(self, size: int = -1) -> bytes:
if self.closed:
raise ValueError("I/O operation on closed file.")
if size == -1:
# 读取剩余全部内容(仍流式进行)
parts = []
while True:
chunk = self.read(1 * 1024 * 1024)
if not chunk:
break
parts.append(chunk)
return b"".join(parts)
# 按需填充缓冲区
while len(self._buffer) < size and not self._finished:
compressed_chunk = self._compressed_stream.read(self._chunk_size)
if not compressed_chunk:
# 压缩流结束,flush 解压器
leftover = self._decompressor.flush()
if leftover:
self._buffer += leftover
self._finished = True
break
decompressed = self._decompressor.decompress(compressed_chunk)
if decompressed:
self._buffer += decompressed
# 返回请求的字节数
result = self._buffer[:size]
self._buffer = self._buffer[size:]
return result
def stream(self, amt=1 * 1024 * 1024, decode_content=None):
"""兼容 urllib3.HTTPResponse.stream()"""
while True:
chunk = self.read(amt)
if not chunk:
break
yield chunk
def close(self):
if not self.closed:
try:
self._compressed_stream.close()
self._compressed_stream.release_conn()
except Exception:
pass # 忽略关闭异常
self.closed = True
def release_conn(self):
"""兼容接口,实际由 close() 处理"""
self.close()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.close()5.3.2 KAE压缩加速方案测试参考脚本
若想使用该方案进行并发性能测试,本实践提供参考的并发性能测试脚本,其中吞吐量的计算采用原文件大小进行统计。
使用示例:
python minio_perf_test.py \
--endpoint xx.xx.xx.xx:9000 \
--access-key minioadmin \
--secret-key ******** \
--bucket perf-test \
--file dickens.txt \
--duration 30 \
--concurrency 10 \
--test both注意事项:
1. get测试时会先落盘到tem路径后删除,如果tem空间不足,可修改指定落盘路径。
2. get测试时,会先使用1s上传文件,如果测试大文件时1s不足,则可修改脚本延长时间。
3. put测试完后,不会自动删除上传的测试文件,需要手动删除。
KAE压缩加速方案测速示例脚本minio_perf_test.py:
import os
import time
import argparse
import tempfile
import multiprocessing as mp
from pathlib import Path
from minio_kae_extension import Minio
from minio.error import S3Error
def upload_worker(args, worker_id, result_queue):
client = Minio(
endpoint=args.endpoint,
access_key=args.access_key,
secret_key=args.secret_key,
secure=False, # 如果使用 HTTPS,则设为 True
)
if not client.bucket_exists(args.bucket):
client.make_bucket(args.bucket)
local_file = Path(args.file)
file_size_bytes = local_file.stat().st_size
file_name = local_file.name
start_time = time.time()
op_count = 0
total_latency = 0.0
errors = 0
while time.time() - start_time < args.duration:
round_id = op_count + 1
remote_name = f"work_{worker_id:04d}_times_{round_id:08d}_{file_name}"
try:
t0 = time.perf_counter()
client.fput_object(args.bucket, remote_name, str(local_file),part_size=10*1024*1024,compress_mode="on")
latency = time.perf_counter() - t0
total_latency += latency
op_count += 1
except Exception as e:
errors += 1
print(f"[Upload Worker {worker_id}] Error: {e}")
result_queue.put(("upload", worker_id, op_count, total_latency, errors, file_size_bytes))
def download_worker(args, worker_id, result_queue):
client = Minio(
endpoint=args.endpoint,
access_key=args.access_key,
secret_key=args.secret_key,
secure=False, # 如果使用 HTTPS,则设为 True
)
local_file = Path(args.file)
original_file_name = local_file.name
file_size_bytes = local_file.stat().st_size
# 先上传一个基准文件用于下载(由 worker 0 负责)
if worker_id == 1:
remote_name = f"baseline_{original_file_name}"
client.fput_object(args.bucket, remote_name, str(local_file),compress_mode="on")
else:
# 等待 baseline 文件就绪(简单 sleep,实际可加锁或信号,如果为大文件也可延长时间)
time.sleep(1)
start_time = time.time()
op_count = 0
total_latency = 0.0
errors = 0
with tempfile.TemporaryDirectory() as tmpdir:
while time.time() - start_time < args.duration:
round_id = op_count + 1
remote_name = f"baseline_{original_file_name}"
local_path = Path(tmpdir) / f"dl_{worker_id:02d}_{round_id:03d}_{original_file_name}" # 如果tem空间有限,可在此处指定Path,配置到空间充足的路径
try:
t0 = time.perf_counter()
client.fget_object(args.bucket, remote_name+".zlib", str(local_path),uncompress_mode="on")
latency = time.perf_counter() - t0
# 重新读取实际下载的文件大小(不依赖 metadata)
actual_size = local_path.stat().st_size
if actual_size != file_size_bytes:
raise ValueError(f"Size mismatch: expected {file_size_bytes}, got {actual_size}")
total_latency += latency
op_count += 1
except Exception as e:
errors += 1
print(f"[Download Worker {worker_id}] Error: {e}")
result_queue.put(("download", worker_id, op_count, total_latency, errors, file_size_bytes))
def main():
parser = argparse.ArgumentParser(description="MinIO Throughput Benchmark using fput/fget")
parser.add_argument("--endpoint", required=True, help="MinIO endpoint (e.g., localhost:9000)")
parser.add_argument("--access-key", required=True)
parser.add_argument("--secret-key", required=True)
parser.add_argument("--bucket", default="perf-test-bucket")
parser.add_argument("--file", required=True, help="Local file to upload/download")
parser.add_argument("--duration", type=int, default=60, help="Test duration in seconds")
parser.add_argument("--concurrency", type=int, default=4, help="Number of concurrent processes")
parser.add_argument("--secure", default=False, help="Use HTTP instead of HTTPS")
parser.add_argument("--test", choices=["upload", "download", "both"], default="both")
args = parser.parse_args()
if not os.path.isfile(args.file):
print(f"Error: File {args.file} does not exist.")
return
result_queue = mp.Queue()
processes = []
if args.test in ("upload", "both"):
for i in range(args.concurrency):
p = mp.Process(target=upload_worker, args=(args, i + 1, result_queue))
processes.append(p)
p.start()
if args.test in ("download", "both"):
for i in range(args.concurrency):
p = mp.Process(target=download_worker, args=(args, i + 1, result_queue))
processes.append(p)
p.start()
for p in processes:
p.join()
# Collect results
results = []
while not result_queue.empty():
results.append(result_queue.get())
# Aggregate by type
upload_ops = 0
upload_total_lat = 0.0
upload_errors = 0
upload_file_size = 0
download_ops = 0
download_total_lat = 0.0
download_errors = 0
download_file_size = 0
for typ, wid, ops, lat, err, size in results:
if typ == "upload":
upload_ops += ops
upload_total_lat += lat
upload_errors += err
upload_file_size = size
else:
download_ops += ops
download_total_lat += lat
download_errors += err
download_file_size = size
print("\n" + "="*60)
if args.test in ("upload", "both"):
if upload_ops > 0:
total_data_mb = (upload_ops * upload_file_size) / (1024 * 1024)
avg_latency = upload_total_lat / upload_ops
throughput = total_data_mb / args.duration
print(f"[UPLOAD] Duration: {args.duration}s | Ops: {upload_ops} | Errors: {upload_errors}")
print(f"[UPLOAD] Total Data: {total_data_mb:.2f} MB | Throughput: {throughput:.2f} MB/s")
print(f"[UPLOAD] Avg Latency: {avg_latency*1000:.2f} ms")
else:
print("[UPLOAD] No successful operations.")
if args.test in ("download", "both"):
if download_ops > 0:
total_data_mb = (download_ops * download_file_size) / (1024 * 1024)
avg_latency = download_total_lat / download_ops
throughput = total_data_mb / args.duration
print(f"[DOWNLOAD] Duration: {args.duration}s | Ops: {download_ops} | Errors: {download_errors}")
print(f"[DOWNLOAD] Total Data: {total_data_mb:.2f} MB | Throughput: {throughput:.2f} MB/s")
print(f"[DOWNLOAD] Avg Latency: {avg_latency*1000:.2f} ms")
else:
print("[DOWNLOAD] No successful operations.")
print("="*60)
if __name__ == "__main__":
main()