


基于虚拟机的openGauss调优参考实践
发表于 2025/12/30
0
1 非商用声明
该文档提供的内容为参考实践,仅供用户参考使用,用户需先获取虚拟化平台软件授权,可参考实践文档构建自己的软件,按需进行安全、可靠性加固。
2 方案概述
2.1 背景
鲲鹏920新型号服务器是华为新一代高性能服务器,相比鲲鹏920服务器,它支持开启超线程,通过开启超线程模式,可以虚拟出两倍物理核的CPU,拥有更高的并发性能。在实际业务中,通常会在服务器之上部署虚拟化平台,实现物理资源的隔离以及运行实际业务。本文针对该场景,以openGauss数据库为例,开展其在鲲鹏920新型号+虚拟化平台的调优。
2.2 方案简介
本参考实践以鲲鹏920新型号为计算底座,在虚拟化平台上针对openGauss数据库开展性能调优,打造基于虚拟机的openGauss调优参考实践。主要设计思路为:三台鲲鹏920新型号服务器进行组网,采用ISV的超融合虚拟化平台,分别创建不同虚拟机(宿主机不同),用于安装openGauss和BenchmarkSQL,以提升TPCC测试的tpmC值为目标进行性能优化。优化手段分别从算力、网络、openGauss及应用层四个方向,共8个调优手段开展。
2.3 应用场景
主要适用于openGauss在虚拟化平台上的性能调优,为金融、教育、医疗等解决方案场景提供虚拟机数据库调优参考实践。
3 数据库部署指导
3.1 软硬件配置
本参考实践的调优验证以SmartX超融合平台为例,所涉及的详细软硬件信息如表1和表2。
表1 软件信息
类别 | 软件名称 |
|---|---|
超融合软件 | SMTXOS-5.1.5-oe2003-250707154028-aarch64 |
虚拟化管理软件 | cloudtower-v4.6.1.oe2003.aarch64 |
虚拟机操作系统 | openEuler 20.03 SP3 |
数据库软件 | openGuass 6.0.2 |
测试工具 | BenchmarkSQL 5.0 |
表2 硬件信息
类别 | 硬件描述 |
|---|---|
CPU | 鲲鹏7270Z 64C/2.9G |
内存 | 256G |
硬盘 | 4*NVME 硬盘 |
网络 | 25G网卡 |
交换机 | GE S5700系列,25GE CE6800系列 |
3.2 集群组网介绍
三台鲲鹏920新型号服务器通过如图1组网,其中1GE为管理网络,2个25GE分别为存储网络和业务网络。物理机OS部署SMTXOS,并部署SmartX虚拟化管理平台CloudTower,用于虚拟机的管理、创建、测试及调优。
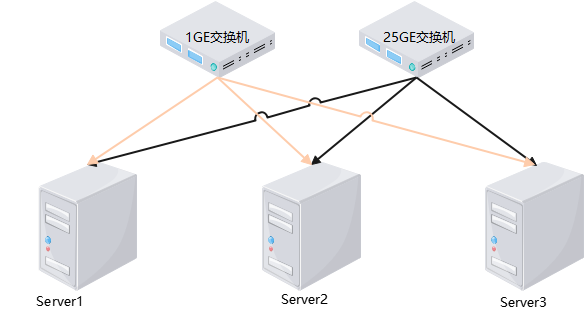
图1 服务器硬件组网图
openGauss的安装及性能测试均在SmartX平台创建的虚拟机上完成。主要测试内容为TPCC测试,采用BenchmarkSQL,因此涉及到客户端Bench和数据库端的安装及组网,其参考示意如图2。
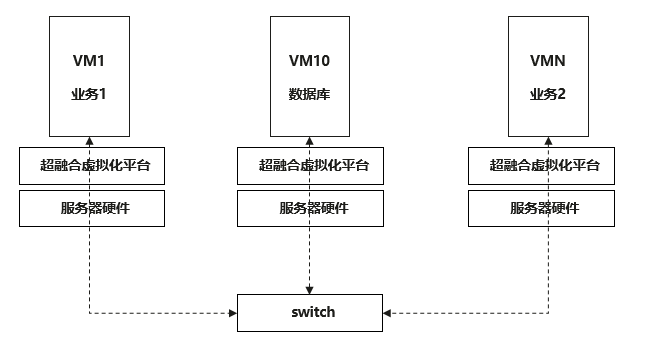
图2 openGauss Bench测试组网运行
3.3 集群部署
集群部署主要参考《安装部署指南》,主要步骤包括:物理机SmartOS部署、SmartX集群部署及虚拟机创建。
3.3.1 物理机SmartOS部署
本次在基于鲲鹏处理器的3台物理服务器上完成了SmartOS的部署。通过BMC(Baseboard Management Controller)远程挂载ISO镜像并启动服务器,随后进入BIOS界面调整启动顺序,确保从虚拟介质引导。安装过程中手动配置了磁盘分区(采用ZFS文件系统)和网络参数,并验证了ARM架构兼容性。部署后测试了基础虚拟化功能(包括ZBS和KVM),确认系统运行稳定。
1)检查BIOS设置:服务器的CPU架构为鲲鹏AArch64,在检查BIOS设置时需确保CPU Prefetching选项为Enabled;
2)挂载SMTX OS镜像⽂件:在节点的虚拟控制台界⾯顶端单击光驱,在光驱窗⼝中,单击镜像文件;—> 选择SMTX OS的镜像⽂件,完成后单击连接并映射设备;—> 强制重启服务器;
3)重启服务器后,在如下SMTX OS的安装引导界⾯中,选择Automatic Installation;—> 可选“将SMTX OS安装在独⽴的硬RAID1中” 或 “将SMTX OS安装在软RAID 1中” —> 选择完硬盘后,SMTX OS系统将会⾃动安装;—> 安装完成后,服务器会⾃动重启;
4)服务器重启后,⽤默认账户root登录SMTX OS系统。
3.3.2 SmartX集群部署
重装SmartX OS系统后,在浏览器输入任意节点的ip地址访问默认的集群安装Web页面,然后按照以下步骤部署集群:
1)输入集群名称,并选择Boost模式,然后进行下一步;
2)等待一段时间扫描主机完成后,默认会将所有SmartX OS主机扫描到,如果没有扫描到,可以点击“手动添加主机”进行手动添加;
3)修改主机名称,然后继续下一步;
4)配置存储,如果有SSD以及HDD盘则可以选择分层,这里都是SSD则选择不分层;
5)网络配置,需要配置管理网络和存储网络:
a)管理网络:输入管理网络名称,然后选择关联网口,注意多个主机需要选择相同的网口;
b)存储网络:输入存储网络名称,然后选择关联网口,注意多个主机需要选择相同的网口;
c)IP划分:
关联网络IP划分:管理网络IP需要和宿主机的网络IP一致,网关和子网掩码按照实际配置即可;
存储网络IP划分:存储网络IP则是自行划分的私网IP,注意需要保证和管理网络不在同一个网段;
DNS服务器包保持默认不要修改;
NTP服务器:如果有NTP服务器则配置对应的服务器,没有则选择集群内主机作为NTP服务器。
6)点击执行部署,等待一段时间后,自动部署完成;
7)登录到集群机器:此时root用户已被禁止登录,需要使用 smartx 用户进行登录。
3.3.3 虚拟机创建
在物理机上完成smartx集群部署后,我们可以通过smartx自带的原生虚拟化平台ELF进行虚拟机创建,浏览器输入任意一台物理机的管理ip即可登录ELF的web管理页面,在此页面上可以进行虚拟机创建,也可以输入cloudtower虚拟机的ip在cloudtower中创建虚拟机,cloudtower对比原生的管理页面提供了更多的功能。
虚拟机创建步骤(以cloudtower中创建虚拟机为例):
1)浏览器输入cloudtower虚拟机ip,进入cloudtower管理页面;
2)在首页右上角点击创建—>创建空白虚拟机;
3)在创建空白虚拟机—>基本信息页面配置虚拟机所属集群、物理主机、虚拟机名,点下一步;
4)在创建空白虚拟机—>计算资源页面配置虚拟机vcpu数量和内存大小,点击下一步;
5)在创建空白虚拟机—>磁盘页面配置磁盘容量并载入虚拟机os的iso映像(需在首页集群下拉列表—>内容库中提前上传),点击下一步;
6)在创建空白虚拟机—>网络设备中选择虚拟机网络(创建虚拟机网络:首页—>集群名—>创建—>创建虚拟分布式交换机,首页—>集群名—>创建—>创建虚拟机网络),无特殊需求使用默认default就行,点击下一步;
7)在创建空白虚拟机—>其他配置页面配置是否启用HA,勾选创建完成后自动开机,点击创建虚拟机;
8)创建好的虚拟机可在集群名—>虚拟机页面下找到。
3.4 openGauss及BenchmarkSQL部署
openGauss单实例和BenchmarkSQL部署形态如图3所示两台虚拟机要部署在不同的物理机上,其中openGauss所在虚拟机规格如表3所示。
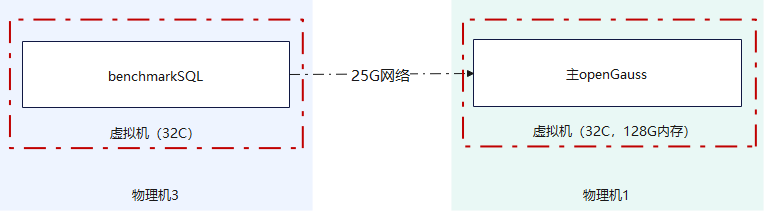
图3 openGauss单实例测试部署形态
表3 openGauss所在虚拟机典型配置
CPU核数 | 内存 | 磁盘 |
|---|---|---|
32 | 128G | 2*300G |
openGauss部署请参考openGauss社区官网,BenchmarkSQL部署参考BenchmarkSQL性能测试。
4 调优参考实践
数据库调优优化以方案简介为准,分别从算力、网络、openGauss及应用层四个方向,共8个调优手段开展。
4.1 设置CPU模式
4.1.1 优化思路
CPU性能模式通常指将CPU频率固定在最高值,以最大化其性能的设置,开启CPU性能模式,无动态调频,固定在标称频率,可以提升事务处理性能。
基于此,优化思路是:服务器重启时,进入BIOS,选择CPU的性能模式。
4.1.2 优化示例
1)服务器重启,进入BIOS,依次选择“BIOS->Advanced->Performance Config->Power Policy”
2)设置“Power Policy”选项为“Performance”,按F10保存BIOS配置。
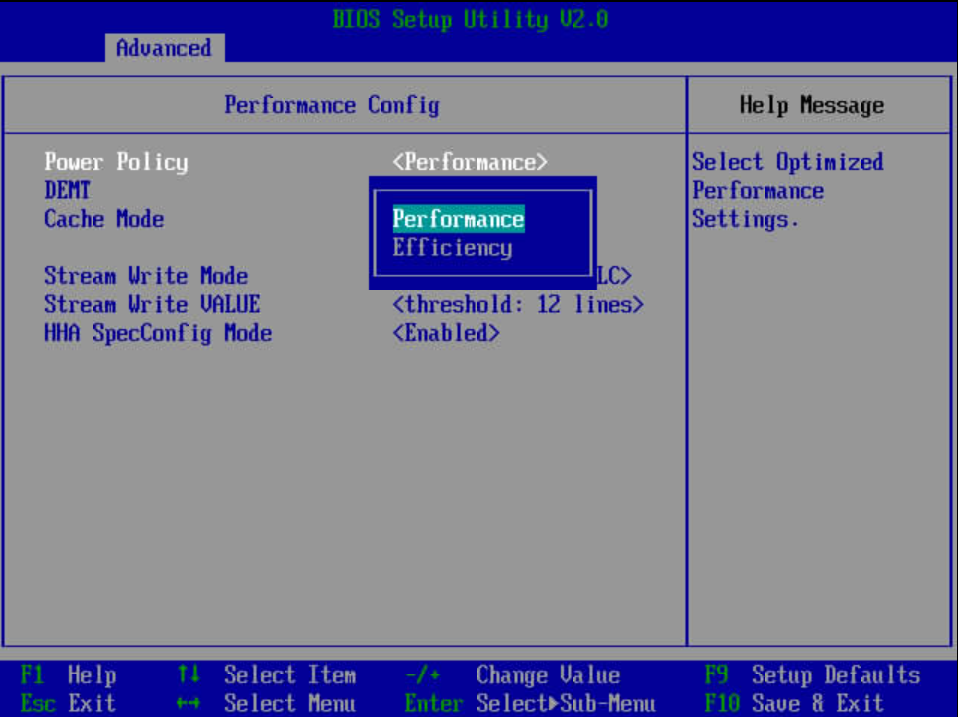
图5 CPU模式设置示意图
4.2 虚拟机绑核
4.2.1 优化思路
NUMA(非统一内存访问)是一种计算机内存架构,其中处理器对本地内存的访问速度比访问其他处理器节点的内存更快。不同NUMA内的CPU核心访问同一个位置的内存性能不同,跨NUMA比本地内存延迟要高。将虚拟机绑定到固定CPU核心上,减少跨NUMA访存延迟。
通常情况下,1颗CPU具有两个NUMA,绑核需要遵循的基本原则是:优先选择将虚拟机的CPU核心绑在同一个NUMA上,若虚拟机所需核心数超出一个NUMA,需尽可能绑在同一颗CPU上。
4.2.2 优化示例
虚拟机绑核分为两部分,步骤1以SmartX为例,其他虚拟化平台可能有差异,步骤2属于通用操作。
1)在创建虚拟机时,在计算资源页面,需要勾选CPU独占;
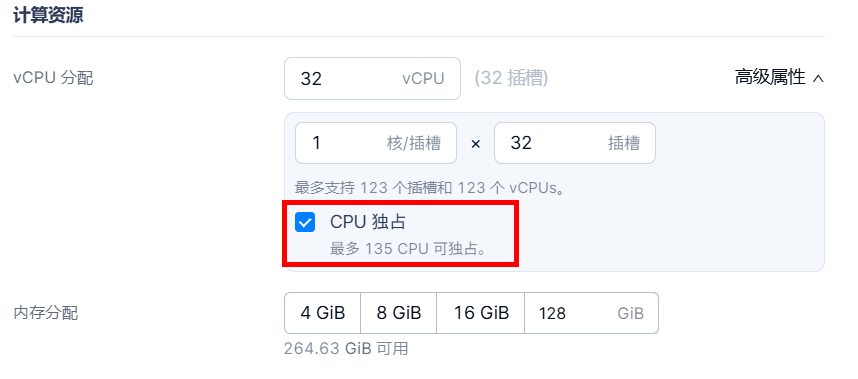
图6 虚拟机创建时CPU独占勾选示意图
2)数据库启动时,对数据库进行绑核,以taskset为例,-D后为openGauss具体安装路径;
taskset -c 0-31 gs_ctl start -D /home/openGauss/install/data/dn14.3 开启Boost模式
4.3.1 优化思路
虚拟机Boost模式是一种通过将服务器虚拟化任务卸载到专用硬件和软件上,来释放虚拟机CPU资源、提高性能的技术。
集群启用Boost模式后,vhost协议将Guest OS、QEMU、ZBS三者之间的内存共享,实现I/O数据请求和数据传输两方面的优化,从而提升虚拟机性能、降低I/O延时。
基于此,优化思路是:集群创建过程中,选择开启Boost模式。
4.3.2 优化示例
优化以SmartX为例,其他平台可能有差异。
开启后,集群会显示Boost模式。
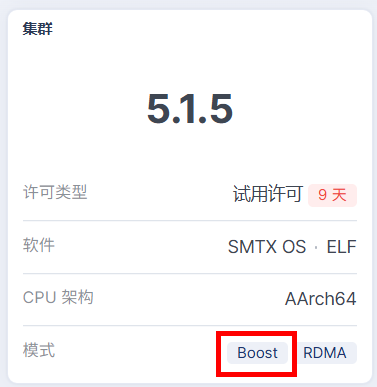
图7 集群Boost模式开启后示意图
4.4 存储网络开启RDMA
4.4.1 优化思路
RDMA(Remote Direct Memory Access) 是一种高效的网络通信技术,允许应用程序直接访问远程主机的内存,而无需经过操作系统内核的干预。其核心特点包括 零拷贝(Zero Copy)、内核旁路(Kernel Bypass) 和 CPU卸载(CPU Offload),显著降低了延迟并提高了带宽利用率。
RDMA的开启需按照3.2完成集群组网,网卡是否支持RDMA需查看网卡产品说明,同时虚拟化平台是否支持RDMA通信需查看虚拟化平台产品说明,建议采用25GE CX5网卡。
基于此,优化思路是:集群创建过程中,选择开启RDMA。
4.4.2 优化示例
优化以SmartX为例配置RDMA,其他平台可能有差异,SmartX支持存储网络开启RDMA。
1)创建集群配置网络时,存储网络勾选RDMA。
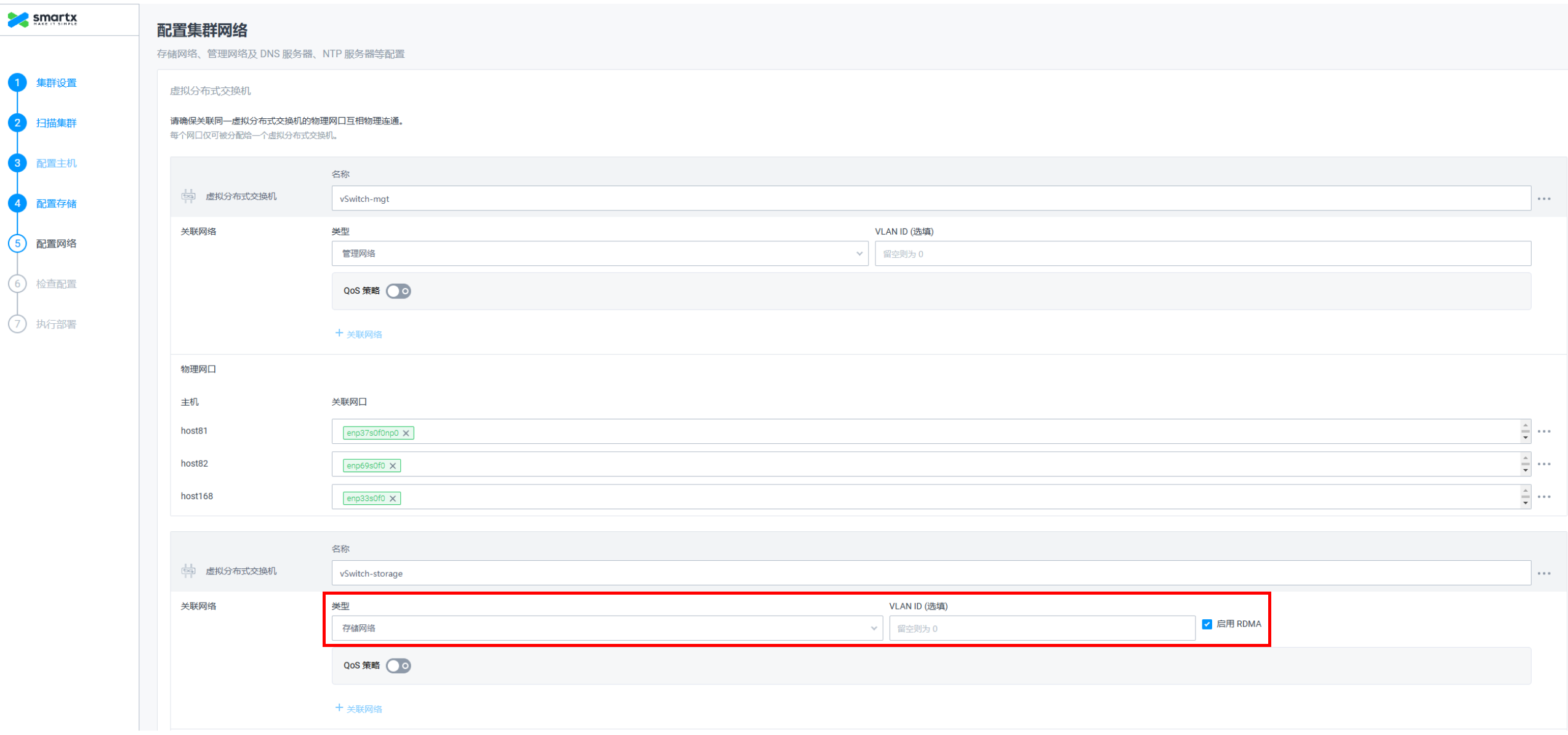
图8 配置存储网络示意图
2)开启后,虚拟分布式交换机存储网络会显示RDMA。
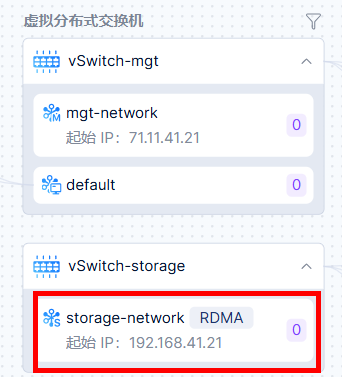
图9 存储网络RDMA开启示意图
4.5 openGauss特性优化
4.5.1 性能参数调整
4.5.1.1 优化思路
极限性能场景下,调整postgresql.conf配置文件,使数据库性能达到最优。
4.5.1.2 优化示例
1)进入数据安装目录,编辑postgresql.conf文件;
cd /home/openGauss/install/data/dn1/
vim postgresql.conf2)新增以下内容。
max_connections = 2048
allow_concurrent_tuple_update = true
audit_enabled = off
checkpoint_segments = 1024
cstore_buffers = 16MB
enable_alarm = off
full_page_writes = off
max_files_per_process = 100000
max_prepared_transactions = 2048
wal_buffers = 1GB
synchronous_commit = on
maintenance_work_mem = 2GB
vacuum_cost_limit = 10000
autovacuum_max_workers = 10
autovacuum_vacuum_cost_delay = 10
enable_material = offwal_log_hints = off
autovacuum_vacuum_scale_factor = 0.1
autovacuum_analyze_scale_factor = 0.02
enable_save_datachanged_timestamp = false
instr_unique_sql_count = 5000
advance_xlog_file_num = 100
track_counts = on
track_sql_count = on
plog_merge_age = 0
session_timeout = 0
enable_instance_metric_persistent = off
enable_logical_io_statistics = off
enable_user_metric_persistent = off
enable_xlog_prune = of
fenable_resource_track = on
remote_read_mode=non_authentication
wal_level = hot_standby
hot_standby = on
hot_standby_feedback = off
enable_asp = off
enable_bbox_dump = off
bgwriter_flush_after = 32
wal_keep_segments = 1025
xloginsert_locks=48
bgwriter_delay = 5
sincremental_checkpoint_timeout = 5min
walwriter_sleep_threshold = 50000
xloginsert_locks=16
pagewriter_sleep = 100ms
incremental_checkpoint_timeout=120s
wal_file_init_num = 30
pagewriter_thread_num = 2
max_redo_log_size = 400GB
max_io_capacity = 1GB
enable_cachedplan_mgr = off
light_comm = on
enable_indexscan_optimization = on
time_record_level = 1
shared_buffers = 50GB4.5.2 数据、日志分盘
4.5.2.1 优化思路
数据库使用时,将数据表和日志的存储路径分别挂载到不同磁盘上,可以实现数据表和日志(WAL/redo log)分盘,其原理为基于I/O负载分离、减少磁盘竞争,从而提升并发吞吐能力。分盘后,日志盘专注处理顺序写,数据盘专注处理随机读写。
该优化需要虚拟机有两个不同的磁盘。通常情况下,数据库安装好之后,数据库的base和日志pg_xlog都在安装目录下。
基于此,优化思路是:通过使用表空间的方式将数据目录存储到另一个磁盘路径下即可实现数据、日志分盘。
4.5.2.2 优化示例
1)执行lsblk,查看磁盘目录,数据库安装在/home目录;
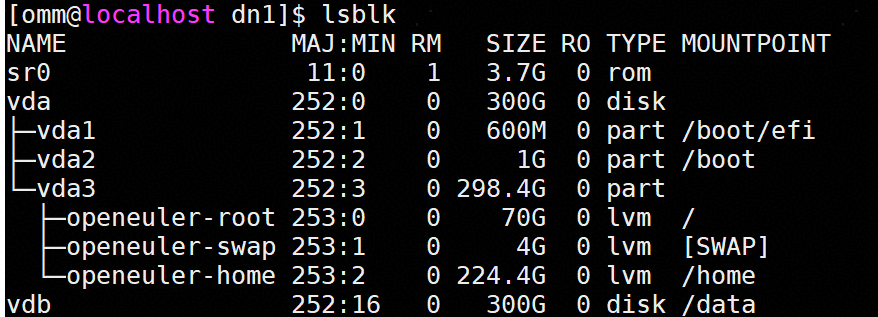
2)在/data目录下创建gauss目录,进入gauss目录后,可以创建数据存放目录;
cd /data && mkdir gauss;
cd gauss && mkdir tbs1 && mkdir tbs2;3)数据库执行以下语句,创建表空间TableSpace(可创建不同的表空间,建议每一张表对应一个表空间);
CREATE TABLESPACE tbs1 location '/data/gauss/tbs1';
CREATE TABLESPACE tbs2 location '/data/gauss/tbs2';4)进入BenchmarkSQL安装目录后,修改创表语句,创表时指定表空间;
vim run/sql.common/taleCreates.sql5)修改后内容如下。
create table bmsql_config (
cfg_name varchar(30) primary key,
cfg_value varchar(50)
);
create table bmsql_warehouse (
w_id integer not null,
w_ytd decimal(12,2),
w_tax decimal(4,4),
w_name varchar(10),
w_street_1 varchar(20),
w_street_2 varchar(20),
w_city varchar(20),
w_state char(2),
w_zip char(9)
);
create table bmsql_district (
d_w_id integer not null,
d_id integer not null,
d_ytd decimal(12,2),
d_tax decimal(4,4),
d_next_o_id integer,
d_name varchar(10),
d_street_1 varchar(20),
d_street_2 varchar(20),
d_city varchar(20),
d_state char(2),
d_zip char(9)
);
create table bmsql_customer (
c_w_id integer not null,
c_d_id integer not null,
c_id integer not null,
c_discount decimal(4,4),
c_credit char(2),
c_last varchar(16),
c_first varchar(16),
c_credit_lim decimal(12,2),
c_balance decimal(12,2),
c_ytd_payment decimal(12,2),
c_payment_cnt integer,
c_delivery_cnt integer,
c_street_1 varchar(20),
c_street_2 varchar(20),
c_city varchar(20),
c_state char(2),
c_zip char(9),
c_phone char(16),
c_since timestamp,
c_middle char(2),
c_data varchar(500)
) tablespace tbs1;
create sequence bmsql_hist_id_seq;
create table bmsql_history (
hist_id integer,
h_c_id integer,
h_c_d_id integer,
h_c_w_id integer,
h_d_id integer,
h_w_id integer,
h_date timestamp,
h_amount decimal(6,2),
h_data varchar(24)
);
create table bmsql_new_order (
no_w_id integer not null,
no_d_id integer not null,
no_o_id integer not null
);
create table bmsql_oorder (
o_w_id integer not null,
o_d_id integer not null,
o_id integer not null,
o_c_id integer,
o_carrier_id integer,
o_ol_cnt integer,
o_all_local integer,
o_entry_d timestamp
);
create table bmsql_order_line (
ol_w_id integer not null,
ol_d_id integer not null,
ol_o_id integer not null,
ol_number integer not null,
ol_i_id integer not null,
ol_delivery_d timestamp,
ol_amount decimal(6,2),
ol_supply_w_id integer,
ol_quantity integer,
ol_dist_info char(24)
);
create table bmsql_item (
i_id integer not null,
i_name varchar(24),
i_price decimal(5,2),
i_data varchar(50),
i_im_id integer
);
create table bmsql_stock (
s_w_id integer not null,
s_i_id integer not null,
s_quantity integer,
s_ytd integer,
s_order_cnt integer,
s_remote_cnt integer,
s_data varchar(50),
s_dist_01 char(24),
s_dist_02 char(24),
s_dist_03 char(24),
s_dist_04 char(24),
s_dist_05 char(24),
s_dist_06 char(24),
s_dist_07 char(24),
s_dist_08 char(24),
s_dist_09 char(24),
s_dist_10 char(24)
)tablespace tbs2;4.6.1 创表时不加外键
4.6.1.1 优化思路
数据外键是一种在关系数据库中用来建立表之间关联的约束,它允许一个表(从表)中的一个或多个字段引用另一个表(主表)的主键字段。
数据外键会增加数据修改时的性能开销,需要额外校验,开发者会选择在应用层自己维护数据完整性,去除数据库外键的优势在于提升性能、简化开发、方便分布式和分库分表,可以有效降低CPU、I/O资源消耗。
基于此,优化思路是:在实际业务中,可以在创表的时候,不指定外键,实现数据更新的加速。
4.6.1.2 优化示例
优化以BenchmarkSQL为例,可扩展到实际业务。
1)进入BenchmarkSQL安装目录后,修改runDatabaseBuild.sh;
vim run/runDatabaseBuild.sh2)修改后内容如下。
#!/bin/sh
if [ $# -lt 1 ] ; then
echo "usage: $(basename $0) PROPS [OPT VAL [...]]" >&2
exit 2
fi
PROPS="$1"
shift
if [ ! -f "${PROPS}" ] ; then
echo "${PROPS}: no such file or directory" >&2
exit 1
fi
DB="$(grep '^db=' $PROPS | sed -e 's/^db=//')"
BEFORE_LOAD="tableCreates"
AFTER_LOAD="indexCreates extraHistID buildFinish"
for step in ${BEFORE_LOAD} ; do
./runSQL.sh "${PROPS}" $step
done
./runLoader.sh "${PROPS}" $*
for step in ${AFTER_LOAD} ; do
./runSQL.sh "${PROPS}" $step
done4.6.2 填充因子修改
4.6.2.1 优化思路
数据库填充因子是一个介于 0 到 100% 的百分比值,它决定了创建或重建索引时,数据页被填充的程度,以便为将来的数据插入和更新预留空间。
在插入和更新操作频繁的场景下,减小填充因子,可以减少由于索引页分裂而导致的I/O开销。填充因子越小,每个数据页可以容纳的数据越少,从而有更多的空间来容纳新的数据,从而提升插入、更新以及写入性能。
基于此,优化思路是:创表时,适当减小FILLFACTOR到80。
4.6.2.2 优化示例
优化以BenchmarkSQL为例,可扩展到实际业务。
1)进入BenchmarkSQL安装目录后,修改填充因子;
vim run/sql.common/taleCreates.sql2)修改后内容如下。
create table bmsql_config (
cfg_name varchar(30) primary key,
cfg_value varchar(50)
);
create table bmsql_warehouse (
w_id integer not null,
w_ytd decimal(12,2),
w_tax decimal(4,4),
w_name varchar(10),
w_street_1 varchar(20),
w_street_2 varchar(20),
w_city varchar(20),
w_state char(2),
w_zip char(9)
)WITH (FILLFACTOR=80);
create table bmsql_district (
d_w_id integer not null,
d_id integer not null,
d_ytd decimal(12,2),
d_tax decimal(4,4),
d_next_o_id integer,
d_name varchar(10),
d_street_1 varchar(20),
d_street_2 varchar(20),
d_city varchar(20),
d_state char(2),
d_zip char(9)
)WITH (FILLFACTOR=80);
create table bmsql_customer (
c_w_id integer not null,
c_d_id integer not null,
c_id integer not null,
c_discount decimal(4,4),
c_credit char(2),
c_last varchar(16),
c_first varchar(16),
c_credit_lim decimal(12,2),
c_balance decimal(12,2),
c_ytd_payment decimal(12,2),
c_payment_cnt integer,
c_delivery_cnt integer,
c_street_1 varchar(20),
c_street_2 varchar(20),
c_city varchar(20),
c_state char(2),
c_zip char(9),
c_phone char(16),
c_since timestamp,
c_middle char(2),
c_data varchar(500)
)WITH (FILLFACTOR=80) tablespace tbs1;
create sequence bmsql_hist_id_seq;
create table bmsql_history (
hist_id integer,
h_c_id integer,
h_c_d_id integer,
h_c_w_id integer,
h_d_id integer,
h_w_id integer,
h_date timestamp,
h_amount decimal(6,2),
h_data varchar(24)
)WITH (FILLFACTOR=80);
create table bmsql_new_order (
no_w_id integer not null,
no_d_id integer not null,
no_o_id integer not null
)WITH (FILLFACTOR=80);
create table bmsql_oorder (
o_w_id integer not null,
o_d_id integer not null,
o_id integer not null,
o_c_id integer,
o_carrier_id integer,
o_ol_cnt integer,
o_all_local integer,
o_entry_d timestamp
)WITH (FILLFACTOR=80);
create table bmsql_order_line (
ol_w_id integer not null,
ol_d_id integer not null,
ol_o_id integer not null,
ol_number integer not null,
ol_i_id integer not null,
ol_delivery_d timestamp,
ol_amount decimal(6,2),
ol_supply_w_id integer,
ol_quantity integer,
ol_dist_info char(24)
)WITH (FILLFACTOR=80);
create table bmsql_item (
i_id integer not null,
i_name varchar(24),
i_price decimal(5,2),
i_data varchar(50),
i_im_id integer
);
create table bmsql_stock (
s_w_id integer not null,
s_i_id integer not null,
s_quantity integer,
s_ytd integer,
s_order_cnt integer,
s_remote_cnt integer,
s_data varchar(50),
s_dist_01 char(24),
s_dist_02 char(24),
s_dist_03 char(24),
s_dist_04 char(24),
s_dist_05 char(24),
s_dist_06 char(24),
s_dist_07 char(24),
s_dist_08 char(24),
s_dist_09 char(24),
s_dist_10 char(24)
)WITH (FILLFACTOR=80) tablespace tbs2;