


基于鲲鹏服务器的金仓数据库调优参考实践
发表于 2026/03/09
0
1 非商用声明
本文档提供的内容为调优参考实践,仅用于技术方案参考。用户可基于本文档构建自有软件系统,但需根据实际业务场景,自行完成安全加固、可靠性验证等关键环节,本文档不承担直接商用带来的相关责任。
2 方案概述
2.1 背景
金仓数据库管理系统KingbaseES(简称KES)是中电科金仓科技股份有限公司研发的通用数据库产品,适用于事务处理类应用、数据分析类应用、海量时序数据采集检索类应用、互联网应用等场景,具有"三高"(高可靠、高性能、高安全)、"三易"(易管理、易使用、易扩展)、运行稳定等特点。
鲲鹏920新型号服务器是鲲鹏推出的新一代服务器,本文基于该服务器部署金仓数据库KingbaseES V8,为进一步发挥硬件潜能,提升数据库整体性能,针对该组合场景开展调优工作,以充分释放鲲鹏的极致算力,优化用户使用体验。
2.2 方案简介
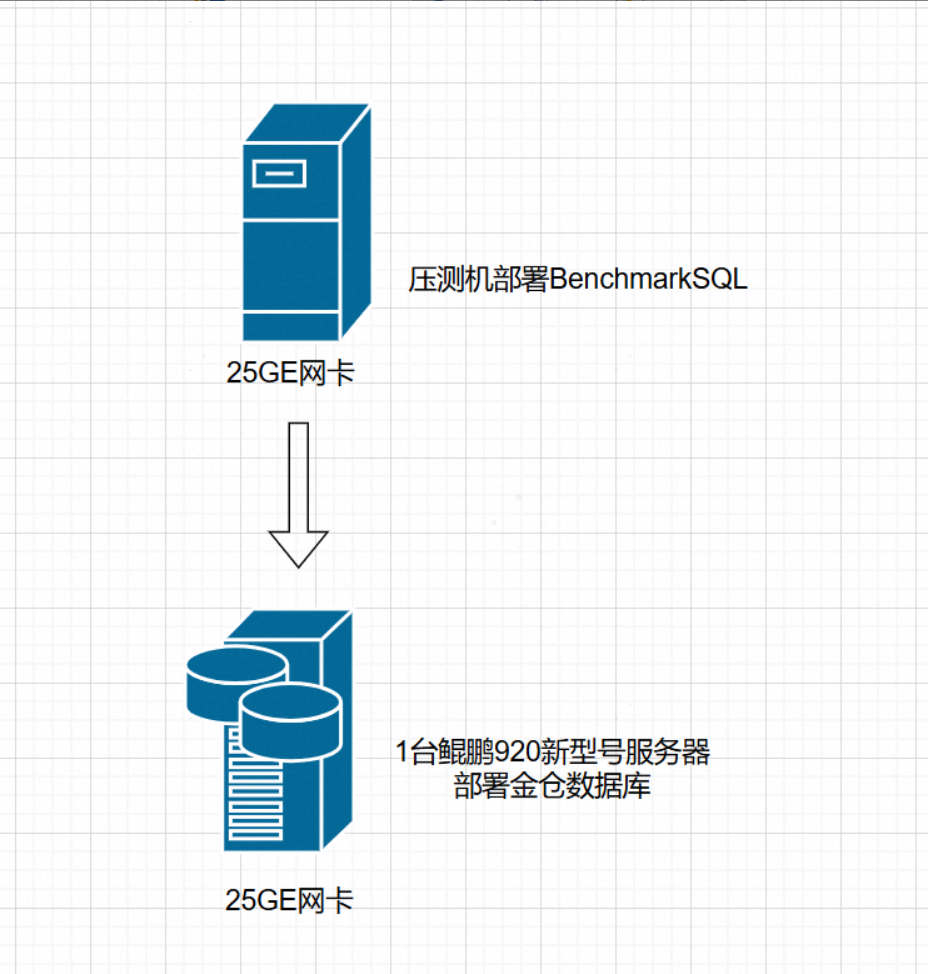
本参考实践以鲲鹏服务器为计算底座,针对金仓数据库开展性能调优。主要设计思路为:一共部署2台服务器进行组网,其中1台为鲲鹏920新型号服务器,采用物理机部署的方式部署金仓数据库,另外1台服务器作为压测机,使用benchmarkSQL进行测试,以提升TPCC测试的tpmC值为目标进行性能优化。本实践虽基于鲲鹏920新型号服务器开展,但下文所述的调优思路与具体手段均属于鲲鹏平台通用特性,同样适用于其他鲲鹏系列服务器,具备广泛的参考价值。
2.3 调优思路
调优主要分为两部分,一部分是采用通用的服务器调优方法,以BIOS配置项调优、操作系统调优、磁盘IO调优、网络系统调优、文件系统调优共5个方向进行系统性能调优; 另一部分是根据金仓数据库的应用特点,对于金仓数据库参数进行调优,具体的调优手段参考章节4"调优参考实践"。
2.4 调优实施方式
为兼顾调优效率与深度,本实践提供两种并行的实施方式供用户选择:
方式一:一键自动调优(推荐) 。为大幅简化调优流程,我们提供了自研的金仓数据库自动调优工具。该工具已将与鲲鹏硬件及金仓数据库相关的BIOS配置、操作系统参数、文件系统设置、数据库关键参数等数十项最佳实践集成在工具里。用户只需运行该工具,即可实现一键式、全栈式的性能配置优化,快速提升系统及数据库性能,适用于快速部署与通用性能提升场景。
具体使用说明参考"通算一体机性能综合调优参考实践(鲲鹏自动调优工具(KAOT)简介及使用说明)":工具说明链接
方式二:分步手动调优。 如果您希望对每一项优化进行深度理解和控制,或需要根据业务负载进行专项调优,则可以遵循本参考实践后续章节提供的手动调优指南。该指南将详细拆解每一项优化措施的原理、操作命令、参数配置及验证方法,适合测试人员、现场实施人员和技术支持人员深度优化使用。
无论选择哪种路径,其优化的核心维度均围绕以下方面展开,具体实践细节详见第4章及后续章节。
2.5 应用场景
主要适用于金仓数据库在鲲鹏服务器上的性能调优,为金融、教育、医疗等解决方案场景提供数据库调优参考实践。
3 环境信息说明
3.1 软硬件配置
本参考实践的调优验证所涉及的详细软硬件信息如 表1 软件信息 和 表2 硬件信息。
表1 软件信息
类别 | 软件名称 | 软件版本 |
|---|---|---|
虚拟机操作系统 | Kylin Linux Advanced Server | V10 SP3-2403 |
数据库软件 | 金仓数据库 | V8R6 |
测试工具 | BenchmarkSQL | 5.0 |
表2 硬件信息
类别 | 硬件描述 |
|---|---|
CPU | 鲲鹏7270Z 64C@2.9Ghz |
内存 | 16*32GB |
硬盘 | 2*3.7TB NVMe硬盘 |
网络 | 2*25GE网卡 |
3.2 环境组网介绍
一共部署2台服务器进行组网,其中1台为鲲鹏920新型号服务器,采用物理机部署的方式部署金仓数据库,另外1台服务器作为独立压测机,与数据库服务器通过高速网络互联。其上部署的BenchmarkSQL测试套件将模拟前端业务压力,向金仓数据库发起连续、并发的TPC-C标准负载,以检验其在真实业务场景下的tpmC吞吐量、响应时间及稳定性。
3.3 软件部署
3.3.1 金仓数据库部署
金仓数据库部署请参考kingbase金仓社区官网。
3.3.2 BenchmarkSQL部署
BenchmarkSQL部署参考BenchmarkSQL性能测试。
4 调优参考实践
4.1 调优手段总览
调优手段总览见下表1
表1 调优手段总览
调优手段 | 作用 |
|---|---|
设置CPU高性能模式 | 通过将CPU频率固定在最高值获得最大化性能 |
开启SMT超线程 | 开启SMT超线程,每个物理核分为两个逻辑核,提升整机性能 |
关闭SMMU | 数据库通常会使用大量的内存和IO资源,而SMMU会增加额外的开销和延迟,关闭后可以提升系统的性能 |
数据库进程绑核(可选) | 将数据库进程绑定到固定CPU核心上,减少跨NUMA访存延迟,从而提升系统性能 【可选】该调优方法多用于低并发场景(并发数<150),高并发场景(并发数>150)收益不明显,用户可以根据实际业务需要选择是否使能该调优项。 |
策略性抑制swap交换内存使用 | 减少数据库缓存交换到磁盘的情况,从而保证数据库的访问性能 |
选用性能更优的文件系统XFS(可选) | XFS是一种高性能的日志文件系统,其具有优秀的伸缩性与鲁棒性健,尤其擅长处理大文件,同时提供了平滑数据传输能力,相比默认的ext4文件系统性能更优 【可选】该调优项适用于新建数据库场景,用户可以根据实际业务需要选择是否使能该调优项。 |
数据、日志分盘 | 分盘后,日志盘专注处理顺序写,数据盘专注处理随机读写,从而减少磁盘竞争,从而提升并发吞吐能力。 |
磁盘IO调度策略调整 | 在固态硬盘场景下,使用none可以提升磁盘IO性能 |
网卡中断绑核 | 将处理网卡中断的CPU core设置在网卡所在的NUMA上,从而减少跨NUMA的内存访问所带来的额外开销,提升网络处理性能 |
数据库共享内存参数优化 | 可以将频繁访问的数据从缓慢的磁盘(微秒/毫秒级)移至高速的内存(纳秒级),从而提升数据库性能 |
数据库I/O相关参数优化 | 根据业务实际调整数据库配置参数,提升磁盘IO性能 |
数据库创表时不加外键(可选) | 去除数据库外键可以减少数据修改时候额外校验带来的性能开销,达到降低CPU、I/O资源消耗,提升性能的效果 【可选】该调优方法多用于benchmark性能测试,在实际业务中仅作为优化思路进行参考,一般用于历史数据迁移或一次性初始化的场景,具体应用需要结合实际业务进行调整。 |
数据库填充因子修改(可选) | 在插入和更新操作频繁的场景下,减小填充因子,可以减少由于索引页分裂而导致的I/O开销,从而提升插入、更新以及写入性能。 【可选】该调优方法多用于benchmark性能测试,在实际业务中仅作为优化思路进行参考,一般用于业务中更新极为频繁的核心表,具体应用需要结合实际业务进行调整。 |
4.1.1 系统性能调优
4.1.1.1 BIOS配置项调优
4.1.1.1.1 设置CPU高性能模式
4.1.1.1.1.1 优化思路
CPU性能模式通常指将CPU频率固定在最高值,以最大化其性能的设置,开启CPU性能模式,无动态调频,固定在标称频率,可以提升事务处理性能。
4.1.1.1.1.2 优化示例
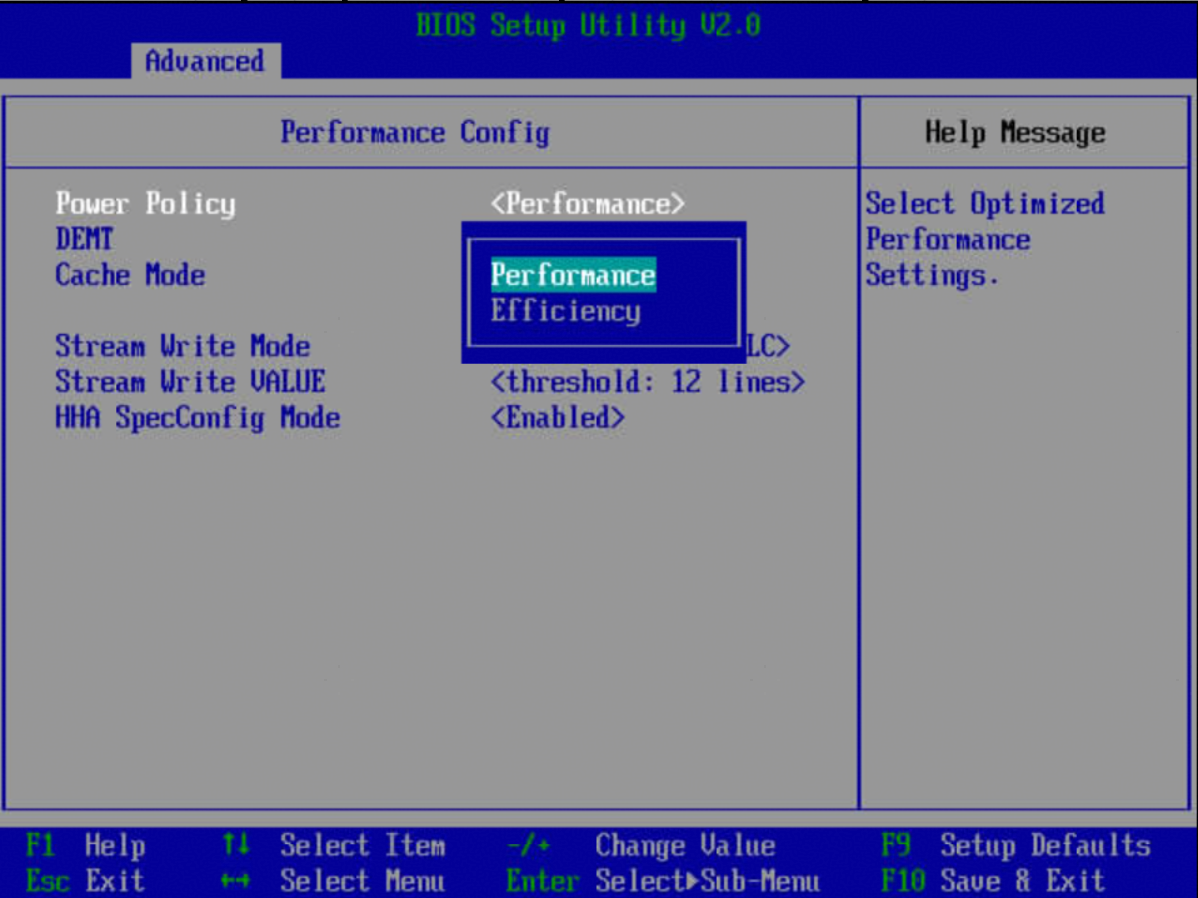
步骤 1 服务器重启,进入BIOS,依次选择“BIOS->Advanced->Performance Config->Power Policy”
步骤 2 设置“Power Policy”选项为“Performance”,按F10保存BIOS配置。
----结束↵
图1 CPU模式设置示意图
4.1.1.1.2 开启SMT超线程
4.1.1.1.2.1 优化思路
开启SMT超线程,每个物理核分为两个逻辑核,提升整机性能。
注意:该调优项仅适用于鲲鹏920新型号服务器,对于其他鲲鹏服务器暂不支持该配置。
4.1.1.1.2.2 优化示例
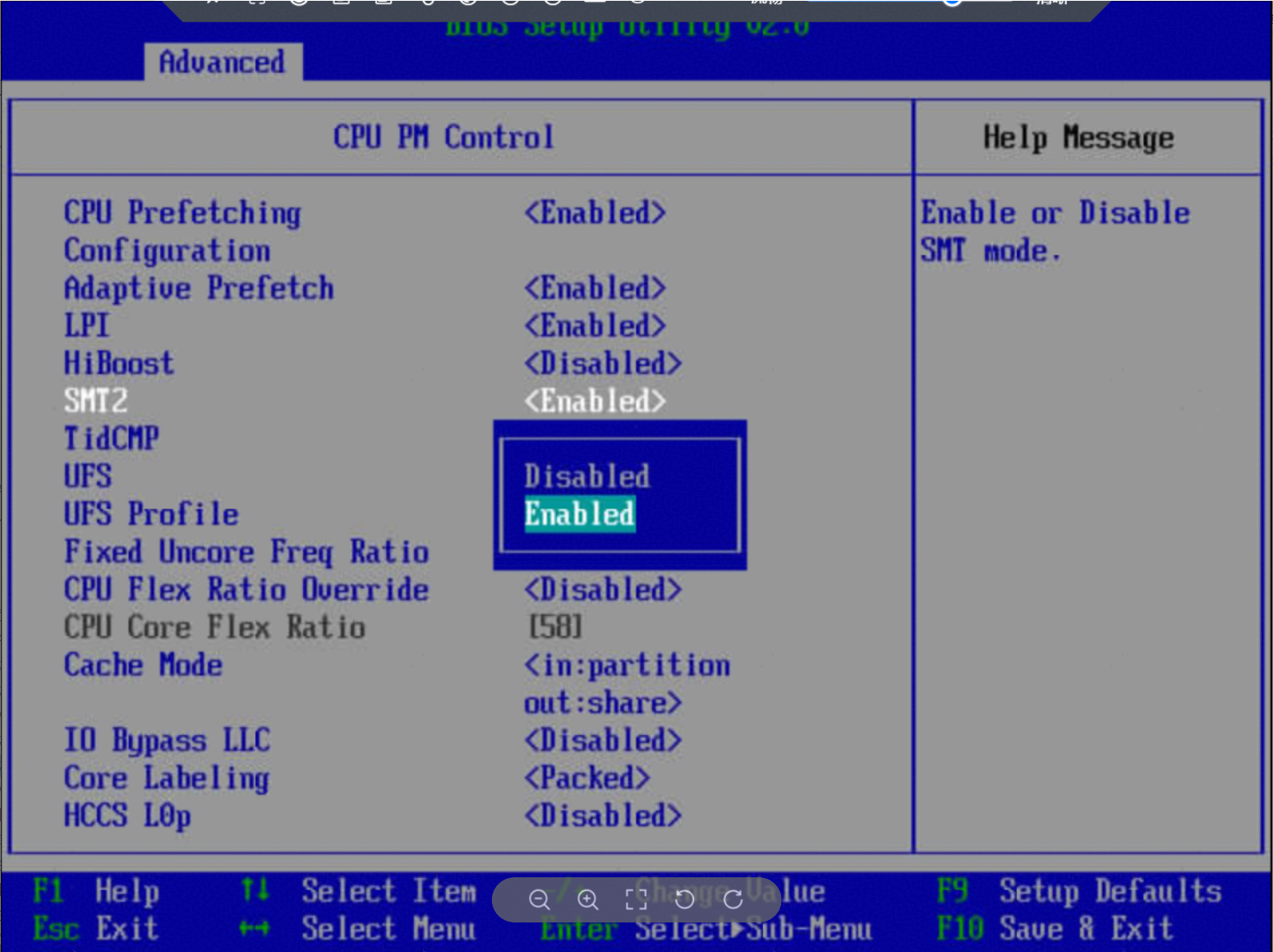
步骤 1 服务器重启,进入BIOS,依次选择“Advanced>Power and Performance Configuration>CPU PM Control>SMT2”,按Enter进入。
步骤 2 将 “SMT2” 设置为“Enabled”,按F10保存BIOS配置并退出。
----结束↵
图1 开启SMT超线程设置示意图
4.1.1.1.3 关闭SMMU
4.1.1.1.3.1 优化思路
SMMU(System Memory Management Unit)是IO设备与总线桥之间的一个地址转换桥,可以实现虚拟地址到物理地址的转换,同时还可以对内存访问进行权限控制和缓存管理,确保系统内存的安全和高效使用。因为数据库通常会使用大量的内存和IO资源,而SMMU会增加额外的开销和延迟,从而降低系统的性能,因此在物理机部署数据库场景中,开启SMMU并不能带来性能提升,建议在BIOS中将SMMU关闭。
4.1.1.1.3.12 优化示例
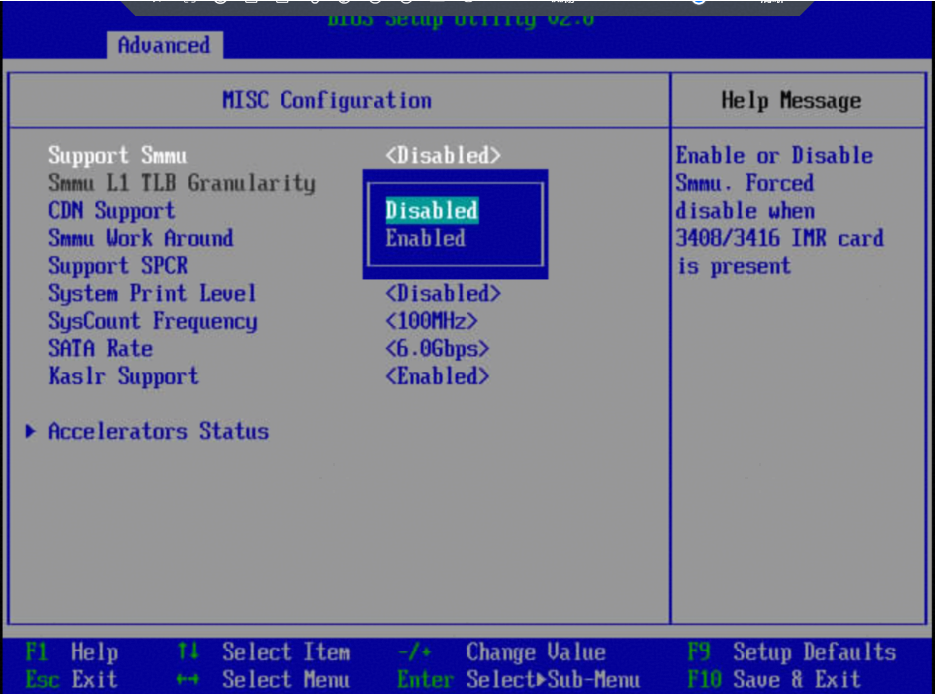
步骤 1 服务器重启,进入BIOS,依次选择“Advanced > MISC Configuration”,按Enter进入。
步骤 2 将“Support Smmu” 设置为“Disable”,按F10保存BIOS配置并退出。
----结束↵
图1 关闭SMMU设置示意图
4.1.1.2 操作系统调优
4.1.1.2.1 数据库进程绑核(可选)
该调优方法多用于低并发场景(并发数<150),高并发场景(并发数>150)收益不明显,用户可以根据实际业务需要选择是否使能该调优项。
4.1.1.2.1.1 优化思路
NUMA(非统一内存访问)是一种计算机内存架构,其中处理器对本地内存的访问速度比访问非本地的内存更快,跨NUMA访问会带来资源调度的消耗和访问延迟。因此可以将数据库进程绑定到固定CPU核心上,减少跨NUMA访存延迟,从而提升性能。
通常情况下,1颗CPU具有两个NUMA,绑核需要遵循的基本原则是:优先选择将数据库进程绑在同一个NUMA的CPU核心上,若数据库进程所需核心数超出一个NUMA的CPU核心数,则尽可能将数据库进程绑在同一颗CPU的核心上。
4.1.1.2.1.2 优化示例
以下示例以金仓数据库为例,非通用操作
步骤 1 进入kingbase.conf配置文件,该文件默认位置为/data/kingbase/es/v8/data/kingbase.conf
步骤 2 在kingbase.conf配置文件中添加参数 bindcpulist = ‘8-127’(此处填入需要绑核的CPU编号,尽可能考虑绑核的CPU都在同一个NUMA上,可以通过lscpu查看CPU以及所在的NUMA;实践中由于业务并发在100左右,因此使用0-127共128核两个NUMA进行绑核,且0-8一般用于系统内核操作,因此从8开始进行绑核;实际使用时可根据业务需要按需调整。)
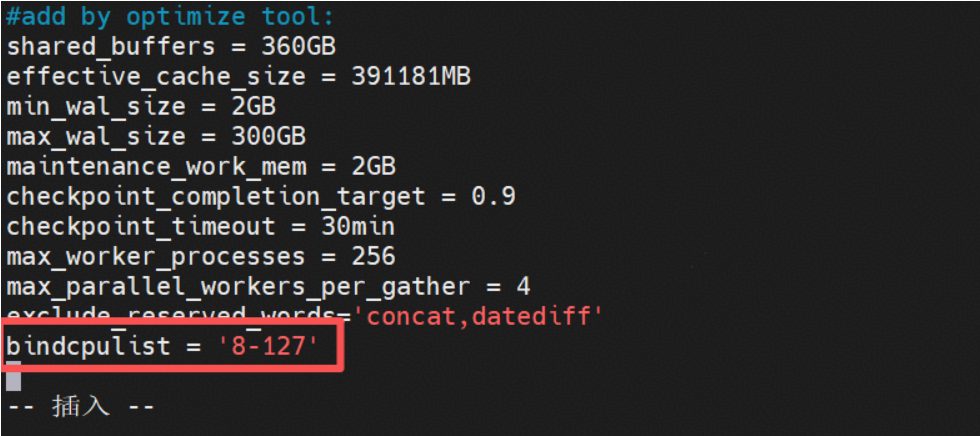
----结束↵
4.1.1.2.2 策略性抑制swap交换内存使用
4.1.1.2.2.1 优化思路
调整内核参数,系统仍保留swap但几乎不使用(除非内存耗尽)。抑制swap交换内存使用可以保障数据库的访问性能,避免把数据库的缓冲区内存淘汰到磁盘上。 如果服务器内存比较小,内存不足时仍可少量使用swap缓冲,避免出现内存溢出的问题。
4.1.1.2.2.2 优化示例
步骤 1 编辑sysctl配置文件:sudo vim /etc/sysctl.conf
步骤 2 在文件末尾添加参数:vm.swappiness=0
步骤 3 通过以下命令(或重启系统)使配置生效并持久化:sudo sysctl -p
----结束↵
4.1.1.3 文件系统调优
4.1.1.3.1 选用性能更优的文件系统XFS(可选)
文件系统类型通常在服务器初始化、磁盘首次格式化时选定。对于已上线运行的生产系统,更换文件系统需要迁移数据,操作复杂、风险高、停机时间长,因此该调优项适用于新建数据库场景。用户可以根据实际业务需要选择是否使能该调优项。
4.1.1.3.1.1 优化思路
XFS是一种高性能的日志文件系统,其具有优秀的伸缩性与鲁棒性健,尤其擅长处理大文件,同时提供了平滑数据传输能力。因此当条件允许的情况下,我们可以优先选择XFS文件系统。
在创建XFS文件系统时,推荐优先加大文件系统的block,例如默认blocksize为4KB, 推荐使用8KB, 可以进一步提升大文件操作场景的性能。
4.1.1.3.1.2 优化示例
步骤 1 格式化磁盘。假设我们要对nvme0n1进行格式化:
mkfs.xfs /dev/nvme0n1步骤 2 指定blocksize,默认情况下为4KB(4096B),我们假设在格式化时指定为变更为8192B:
mkfs.xfs /dev/nvme0n1-b size=8192步骤 3 挂载到对应的目录
mount -t xfs /dev/nvme0n1 /目录名----结束↵
4.1.1.4 磁盘IO调优
4.1.1.4.1 数据、日志分盘
4.1.1.4.1.1 优化思路
数据库使用时,将数据表和日志的存储路径分别挂载到不同磁盘上,可以实现数据表和日志(WAL/redo log)分盘,其原理为基于I/O负载分离、减少磁盘竞争,从而提升并发吞吐能力。分盘后,日志盘专注处理顺序写,数据盘专注处理随机读写。
该优化需要物理机有两个不同的磁盘。通常情况下,数据库安装好之后,数据库的base和日志pg_xlog都在安装目录下。
基于此,优化思路是:通过使用表空间的方式将数据目录存储到另一个磁盘路径下即可实现数据、日志分盘。
4.1.1.4.1.2 优化示例
创建测试用户时,首先创建分表,指定区别于日志所在的磁盘目录。例如:
create tablespace tb1 location '/data/kingbase/tb1';
create database tpcc100 tablespace tb1 encoding='UTF-8' owner=jack;
这种配置方式使得数据库 tpcc100 中的所有对象(除非特别指定)都将存储在 /data/kingbase/tb1 目录下,实现了逻辑数据与物理存储位置的关联。通过将数据库与特定表空间绑定,可以有效管理数据的存储分布。
4.1.1.4.2 磁盘IO调度策略调整
4.1.1.4.2.1 优化思路
磁盘调度策略根据不同场景设置,在固态硬盘场景下,建议使用none,deadline次之。
4.1.1.4.2.2 优化示例
echo none > /sys/block/sda/queue/scheduler
4.1.1.5 网络系统调优
4.1.1.5.1 网卡中断绑核
4.1.1.5.1.1 优化思路
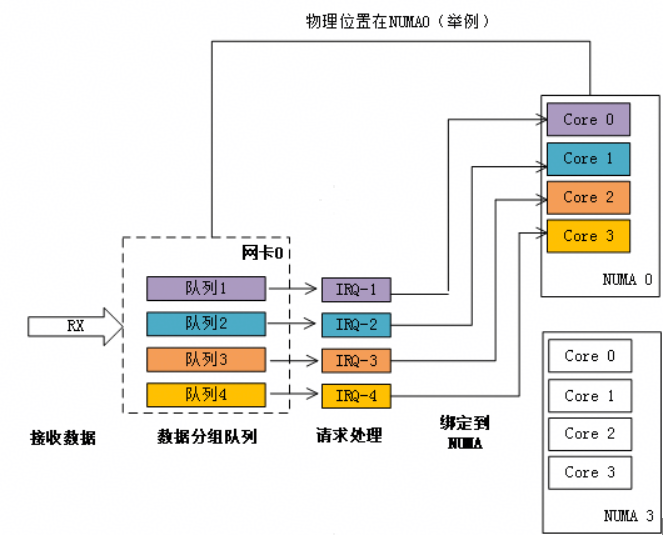
当网卡收到大量请求时,会产生大量的中断,通知内核有新的数据包,然后内核调用中断处理程序响应,把数据包从网卡拷贝到内存。当网卡只存在一个队列时,同一时间数据包的拷贝只能由某一个core处理,无法发挥多核优势,因此引入了网卡多队列机制,这样同一时间不同core可以分别从不同网卡队列中取数据包。
在网卡开启多队列时,操作系统通过Irqbalance服务来确定网卡队列中的网络数据包交由哪个CPU core处理,但是当处理中断的CPU core和网卡不在一个NUMA时,会触发跨NUMA访问内存。因此,我们可以将处理网卡中断的CPU core设置在网卡所在的NUMA上,从而减少跨NUMA的内存访问所带来的额外开销,提升网络处理性能。
图1 自动绑定:中断绑定随机,出现跨NUMA访问内存
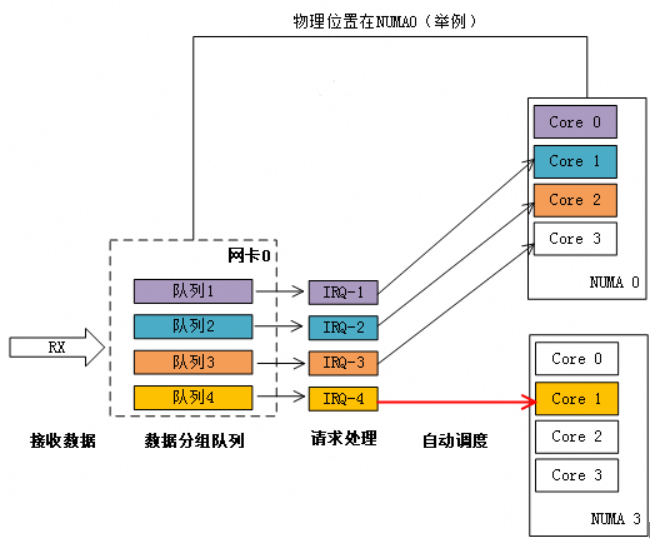
图2 NUMA绑定:中断绑定到指定核,避免跨NUMA访问内存
4.1.1.5.1.2 优化示例
步骤 1 停止irqbalance服务。
systemctl stop irqbalance.service步骤 2 关闭irqbalance服务。
systemctl disable irqbalance.service步骤 3 查看irqbalance服务状态是否已关闭。
systemctl status irqbalance.service状态为inactive即为关闭。

步骤 4 网卡中断绑核。
运行sh irq.sh bind enp193s0f0 64 '160-191',执行绑核脚本。
注:此处的enp193s0f0为网卡,64为中断数量,可以通过ethtool -l 网卡查询;'160-191' 为要用于绑定网卡中断的CPU编号,建议与网卡在同一个NUMA, 网卡所在NUMA可以通过cat /sys/class/net/eth0(替换成对应的网卡)/device/numa_node查询。
脚本中$bus_info要改成对应的网卡的总线信息,可以通过ethtool -l 网卡查询后替换。
irq.sh脚本:
#!/bin/bashs
# chkconfig: - 50 50
# description: auto irq
#获取网卡所在cpu
function get_default_cpu(){
eth_numa_node=`cat /sys/class/net/${eth}/device/numa_node`
numa_nodes=`lscpu | grep node\(s | awk '{print $NF}'`
cpus=`lscpu | grep CPU\(s | head -1 | awk '{print $NF}'`
sockets=`lscpu | grep Socket\(s | awk '{print $NF}'`
cpus_per_socket=`lscpu | grep Core\(s | awk '{print $NF}'`
numa_per_socket=$((${numa_nodes} / ${sockets}))
eth_socket=$((${eth_numa_node} / ${numa_per_socket}))
first_cpu=$[$[$[${cpus_per_socket}*${eth_socket}]]]
last_cpu=$[$[${cpus_per_socket}*$[${eth_socket}+1]]-1]
cpurange="${first_cpu}-${last_cpu}"
}
#根据参数获取cpu队列
function get_cpu_list(){
IFS_bak=$IFS
IFS=','
cpurange=($1)
IFS=${IFS_bak}
cpulist_arr=()
n=0
for i in ${cpurange[@]};do
start=`echo $i | awk -F'-' '{print $1}'`
stop=`echo $i | awk -F'-' '{print $NF}'`
for x in `seq $start $stop`;do
cpulist_arr[$n]=$x
let n++
done
done
}
#中断绑核
function bind(){
echo ${cnt}
ethtool -L ${eth} combined ${cnt}
#irq=`cat /proc/interrupts| grep ${eth} | awk -F ':' '{print $1}'`
irq=`cat /proc/interrupts| grep "$bus_info" | awk -F ':' '{print $1}'`
i=0
for irq_i in $irq
do
if [ $i -ge ${#cpulist_arr[*]} ]; then
i=0
fi
echo ${cpulist_arr[${i}]} "->" $irq_i
echo ${cpulist_arr[${i}]} > /proc/irq/$irq_i/smp_affinity_list
let i++
done
}
#读取网卡绑定cpu信息
function check(){
ethtool -l $eth
#irq=`cat /proc/interrupts | grep ${eth} | awk -F ':' '{print $1}'`
irq=`cat /proc/interrupts| grep "$bus_info" | awk -F ':' '{print $1}'`
for irq_i in $irq
do
cat /proc/irq/$irq_i/smp_affinity_list
done
}
[[ $2 ]] && eth=$2 || eth=`ifconfig | grep -B 1 "192.168" | head -1 | awk -F":" '{print $1}'`
echo "$eth"
[[ $3 ]] && cnt=$3 || cnt=48
[[ $4 ]] && cpurange=$4 || get_default_cpu
get_cpu_list $cpurange
[[ $1 ]] && $1 || bind
# 使用举例:
# sh irq.sh #默认将192.168网卡队列深度设置为48并绑定到网卡所在cpu前48core
# sh irq.sh check eth1 #读取网卡绑核信息
# sh irq.sh bind enp193s0f0 64 '160-191' #完整参数,将eth1队列深度修改为64,并循环绑定到160-191'32个核上,其中cpu支持范围参数,如'1-3,6,7-9'
4.2 数据库参数调优
4.2.1 数据库配置参数调优
4.2.1.1 共享内存参数优化
4.2.1.1.1 优化思路
shared_buffers参数用于设置数据库服务器使用的共享内存缓冲区的数量,主要用于缓存数据,可以将频繁访问的数据从缓慢的磁盘(微秒/毫秒级)移至高速的内存(纳秒级),从而提升数据库性能。该参数根据需求一般不能设置超过物理机整机内存总量的80%,但至少是20%。
4.2.1.1.2 优化示例
修改kingbase.conf,添加参数:
以内存512GB为例,shared_buffers=360GB
4.2.1.2 数据库I/O相关参数优化
4.2.1.2.1 优化思路
在测试过程中分析出磁盘IO是性能瓶颈之一,因此调整数据库I/O相关参数进行磁盘IO性能优化
表1 数据库配置参数调优总览
数据库配置参数名称 | 参数含义及应用 | 默认值 | 参考调优值 |
|---|---|---|---|
checkpoint_timeout | 两个相邻检查点之间的时间间隔,用于刷数据到磁盘。 应用:根据系统写的负载设置, 一般不要太频繁,可以和后台写线程配置相关参数配合使用。 | 5min | 20min |
checkpoint_completion_target | 表示checkpoint的完成时间要在两个checkpoint间隔时间的N%内完成。设置长一点,避免对性能测试的影响 | 0.5 | 0.9 |
bgwriter_delay | 后台写线程的自动执行时间,后台写线程的作用是将 shared_buffer 里的脏页面写回到磁盘,减少 checkpoint 的压力。 应用:如果系统数据修改的压力一直很大,建议将该时间间隔设置小一些,以免积累的大量的脏页面到 checkpoint,使 checkpoint 时间过长(checkpoint 期间系统响应速度较慢)。 | 200ms | 10ms |
max_wal_size | 检查点之间WAL日志允许增长的最大大小。 应用:设置较大的值(如300GB)可防止在写入高峰期因WAL增长过快而频繁触发检查点 | 1GB | 300GB |
4.2.1.2.2 优化示例
修改kingbase.conf,添加参数:
checkpoint_timeout=20min
checkpoint_completion_target=0.9
bgwriter_delay=10ms
max_wal_size=300GB4.2.2 创表时不加外键(可选)
该调优方法多用于benchmark性能测试,在实际业务中仅作为优化思路进行参考,一般用于历史数据迁移或一次性初始化的场景,具体应用需要结合实际业务进行调整。
4.2.2.1 优化思路
数据外键是一种在关系数据库中用来建立表之间关联的约束,它允许一个表(从表)中的一个或多个字段引用另一个表(主表)的主键字段。
数据外键会增加数据修改时的性能开销,需要额外校验,开发者会选择在应用层自己维护数据完整性,去除数据库外键的优势在于提升性能、简化开发、方便分布式和分库分表,可以有效降低CPU、I/O资源消耗。
基于此,优化思路是:在实际业务中,可以在创表的时候,不指定外键,实现数据更新的加速。
4.2.2.2 优化示例
说明:优化以BenchmarkSQL为例,可扩展到实际业务。
步骤 1 进入BenchmarkSQL安装目录后,修改runDatabaseBuild.sh
vim run/runDatabaseBuild.sh步骤 2 修改后内容如下
#!/bin/sh
if [ $# -lt 1 ] ; then
echo "usage: $(basename $0) PROPS [OPT VAL [...]]" >&2
exit 2
fi
PROPS="$1"
shift
if [ ! -f "${PROPS}" ] ; then
echo "${PROPS}: no such file or directory" >&2
exit 1
fi
DB="$(grep '^db=' $PROPS | sed -e 's/^db=//')"
BEFORE_LOAD="tableCreates"
AFTER_LOAD="indexCreates extraHistID buildFinish"
for step in ${BEFORE_LOAD} ; do
./runSQL.sh "${PROPS}" $step
done
./runLoader.sh "${PROPS}" $*
for step in ${AFTER_LOAD} ; do
./runSQL.sh "${PROPS}" $step
done----结束↵
4.2.3 填充因子修改(可选)
该调优方法多用于benchmark性能测试,在实际业务中仅作为优化思路进行参考,一般用于业务中更新极为频繁的核心表,具体应用需要结合实际业务进行调整。
4.2.3.1 优化思路
数据库填充因子是一个介于 0 到 100% 的百分比值,它决定了创建或重建索引时,数据页被填充的程度,以便为将来的数据插入和更新预留空间。
在插入和更新操作频繁的场景下,减小填充因子,可以减少由于索引页分裂而导致的I/O开销。填充因子越小,每个数据页可以容纳的数据越少,从而有更多的空间来容纳新的数据,从而提升插入、更新以及写入性能。
基于此,优化思路是:创表时,适当减小FILLFACTOR到80。
4.2.3.2 优化示例
说明:优化以BenchmarkSQL为例,可扩展到实际业务。
步骤 1 进入BenchmarkSQL安装目录后,修改填充因子
vim run/sql.common/taleCreates.sql步骤 2 修改后内容如下
create table bmsql_config (
cfg_name varchar(30) primary key,
cfg_value varchar(50)
);
create table bmsql_warehouse (
w_id integer not null,
w_ytd decimal(12,2),
w_tax decimal(4,4),
w_name varchar(10),
w_street_1 varchar(20),
w_street_2 varchar(20),
w_city varchar(20),
w_state char(2),
w_zip char(9)
)WITH (FILLFACTOR=80);
create table bmsql_district (
d_w_id integer not null,
d_id integer not null,
d_ytd decimal(12,2),
d_tax decimal(4,4),
d_next_o_id integer,
d_name varchar(10),
d_street_1 varchar(20),
d_street_2 varchar(20),
d_city varchar(20),
d_state char(2),
d_zip char(9)
)WITH (FILLFACTOR=80);
create table bmsql_customer (
c_w_id integer not null,
c_d_id integer not null,
c_id integer not null,
c_discount decimal(4,4),
c_credit char(2),
c_last varchar(16),
c_first varchar(16),
c_credit_lim decimal(12,2),
c_balance decimal(12,2),
c_ytd_payment decimal(12,2),
c_payment_cnt integer,
c_delivery_cnt integer,
c_street_1 varchar(20),
c_street_2 varchar(20),
c_city varchar(20),
c_state char(2),
c_zip char(9),
c_phone char(16),
c_since timestamp,
c_middle char(2),
c_data varchar(500)
)WITH (FILLFACTOR=80) tablespace tbs1;
create sequence bmsql_hist_id_seq;
create table bmsql_history (
hist_id integer,
h_c_id integer,
h_c_d_id integer,
h_c_w_id integer,
h_d_id integer,
h_w_id integer,
h_date timestamp,
h_amount decimal(6,2),
h_data varchar(24)
)WITH (FILLFACTOR=80);
create table bmsql_new_order (
no_w_id integer not null,
no_d_id integer not null,
no_o_id integer not null
)WITH (FILLFACTOR=80);
create table bmsql_oorder (
o_w_id integer not null,
o_d_id integer not null,
o_id integer not null,
o_c_id integer,
o_carrier_id integer,
o_ol_cnt integer,
o_all_local integer,
o_entry_d timestamp
)WITH (FILLFACTOR=80);
create table bmsql_order_line (
ol_w_id integer not null,
ol_d_id integer not null,
ol_o_id integer not null,
ol_number integer not null,
ol_i_id integer not null,
ol_delivery_d timestamp,
ol_amount decimal(6,2),
ol_supply_w_id integer,
ol_quantity integer,
ol_dist_info char(24)
)WITH (FILLFACTOR=80);
create table bmsql_item (
i_id integer not null,
i_name varchar(24),
i_price decimal(5,2),
i_data varchar(50),
i_im_id integer
);
create table bmsql_stock (
s_w_id integer not null,
s_i_id integer not null,
s_quantity integer,
s_ytd integer,
s_order_cnt integer,
s_remote_cnt integer,
s_data varchar(50),
s_dist_01 char(24),
s_dist_02 char(24),
s_dist_03 char(24),
s_dist_04 char(24),
s_dist_05 char(24),
s_dist_06 char(24),
s_dist_07 char(24),
s_dist_08 char(24),
s_dist_09 char(24),
s_dist_10 char(24)
)WITH (FILLFACTOR=80) tablespace tbs2;----结束↵