


鲲鹏在Agent记忆系统上的创新及实践
发表于 2026/03/23
0
在Agent系统中,记忆系统扮演着至关重要的角色,它不仅是Agent存储和检索历史信息的基础设施,更是实现长期对话理解、个性化服务和复杂任务规划的核心组件。然而,随着Agent应用场景的不断扩展和用户期望的持续提升,记忆系统面临着前所未有的挑战。
一、 Agent记忆系统的核心挑战
1. 准确率挑战
准确率是记忆系统最基本也是最重要的指标之一。在实际应用中,记忆系统的准确率挑战主要体现在以下几个方面:
- 语义理解偏差:传统的关键词匹配方法难以准确捕捉用户查询的真实意图。例如,用户询问“上次讨论的项目进展如何?”,系统需要理解“上次讨论”指的是最近一次相关对话,而不是字面上的“上一次”对话。
- 上下文依赖性:记忆的准确性高度依赖于上下文环境。同一段记忆在不同对话场景下可能具有完全不同的相关性权重。这种动态相关性评估对系统的语义理解能力提出了极高要求。
- 噪声干扰:真实对话中包含大量无关信息、重复内容和错误表述,这些噪声会严重影响记忆检索的准确性,导致系统返回不相关或误导性的信息。
2. 上下文过载问题
由于Transformer架构的大模型的计算复杂度与上下文长度呈O(n²)关系,随着上下文长度线性增长,推理时间和计算资源消耗呈指数级增长,上下文长度是制约大模型应用落地成本的关键因素,所以主流的大语言模型都有严格的上下文长度限制(如128K tokens)。但Agent场景下上下文存在过载问题,主要体现在:
(1)工具定义过载:将所有可用的子agent和工具定义一次性加载到模型的上下文中,仅仅工具的定义可能消耗数十万Token,以MCP社区主流的MCP Server为例,58 个工具就已经消耗了大约 55K tokens。
| 服务 | 工具数量 | Token消耗 |
|---|---|---|
| GitHub | 35个工具 | ~26K tokens |
| Slack | 11个工具 | ~21K tokens |
| Sentry | 5个工具 | ~3K tokens |
| Grafana | 5个工具 | ~3K tokens |
| Splunk | 2个工具 | ~2K tokens |
| 合计 | 58个工具 | ~55K tokens |
(2)通过大模型传递数据:在两个有依赖关系的工具和agent之间产生的中间临时数据,需要通过上下文由大模型来传递,随着调用轮次的增加,造成上下文爆炸的同时,也导致了不必要的token计算。
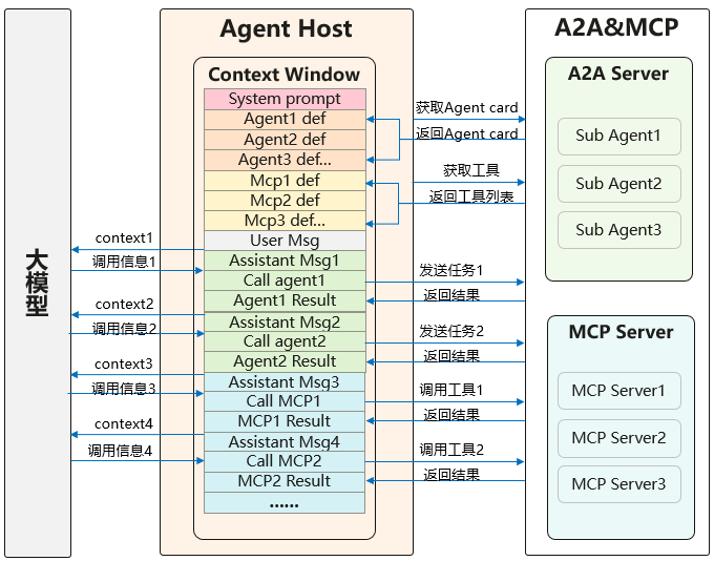
通过大模型传递数据
3. 记忆检索瓶颈
随着OpenClaw等应用在企业端的加速落地,记忆系统底库容量将极速膨胀,以向量为例,可能达到千亿规模,在大规模记忆库中准确检索相关信息面临时延和成本两大挑战:
- 时延挑战:在金融风控、工业生产的场景,用户期望Agent能够即时响应,通常要求检索延迟控制在50毫秒以内,甚至要求毫秒级,然而,在包含千亿条记忆记录的数据库中进行精确检索往往需要数秒甚至更长时间。
- 成本挑战:千亿规模的向量,容量达到数百TB(通常768-4096维),如果全部采用内存检索方案,对于时延要求不高的场景,将造成巨大的成本浪费。
二、当前业界的关键技术解决方案
1.上下文压缩技术
针对上下文噪声等问题,上下文压缩旨在减少冗余信息,同时保留关键信息:
- 摘要压缩:通过摘要模型将长段落压缩为简洁的要点。例如,使用专门训练的T5或BART模型对历史对话进行摘要,将原本1000 tokens的对话压缩为200 tokens的关键信息。
- 重要性评分:基于专门的重要性评分模型,为每个token或句子分配重要性分数,只保留高分内容。这种方法能够动态适应不同场景的需求。
- 结构化压缩:将非结构化的对话内容转换为结构化的知识图谱或表格形式,大幅减少冗余信息。例如,将多轮对话中的实体关系提取出来,构建轻量级的知识表示。
压缩能有效解决上下文过载以及噪声等问题,但不可避免地会造成原始信息丢失,特别是在处理复杂逻辑推理或多跳问答时,关键细节的丢失可能导致推理错误。
2. 渐进式披露策略
渐进式披露通过分层次、按需加载的方式管理上下文信息,Anthropic是将这一理念运用到极致的代表,分别提出了以下渐进式披露方式:
- Skill:基于文件系统,以目录的形式,分三层组织指令、可执行代码和参考资料,模型根据需要分层按需加载信息,而不是预先加载所有上下文。
- Programming Tool Call:利用模型自身强大的代码能力,将 MCP 服务器呈现为代码 API,通过代码来调用工具,而不是通过输出一个JSON格式的工具调用文本,这样模型可以按需读取工具定义,无需预先全部读取,同时通过代码对中间结果进行筛选和转换,在两个工具间直接基于变量传递数据,无需经过模型传递。
- Tool Search tool:工具搜索工具允许 Claude 动态发现工具,而无需预先加载所有定义。需要向 API 提供所有工具定义,但要标记工具的defer_loading为true,使其能够按需发现,延迟发现的工具最初不会加载到 Claude 的上下文中,Claude 只会看到工具搜索工具本身以及任何带有标记defer_loading: false的工具(最关键、最常用的工具),当 Claude 需要特定功能时,它会搜索相关工具,工具搜索工具会返回匹配工具的引用,这些引用会在 Claude 的上下文中展开为完整的定义。
渐进式披露弥补了压缩的不足,可以保留原始信息,但目前仅针对静态信息和少量临时数据,对于具有大规模中间临时数据的场景(如BI),仍然无法有效解决。
3. 高效检索算法
检索本质上也是一种压缩上下文的方式—仅筛选与任务相关的上下文,对于上述两大检索挑战(时延与成本),业界普遍基于HNSW和DiskANN来应对。
- HNSW是一种基于图的近似最近邻搜索算法,具有以下优势:
- 分层索引结构:通过多层图结构实现快速粗略定位和精细搜索的结合。
- 导航优化:利用小世界网络特性,在高维空间中实现高效的路径导航。
- 内存友好:相比传统方法,HNSW在保持高召回率的同时显著降低内存占用。
在Agent记忆系统中,HNSW通常用于处理中等规模(十亿千维以下)的记忆库,并能够在50ms内完成高精度检索,对于百亿级甚至千亿级规模向量,当前方案存在巨大挑战。
- DiskANN是专为大规模向量检索设计的磁盘友好的近似最近邻搜索算法:
- 内存-磁盘协同:巧妙利用SSD的随机访问特性,将大部分数据存储在磁盘上,只将热点数据缓存在内存中。
- 量化压缩:采用PQ(Product Quantization)等技术大幅减少向量存储空间。
- 异步I/O优化:通过异步I/O操作隐藏磁盘访问延迟。
DiskANN适用于十亿以上规模的记忆库,在有限内存条件下仍能保持良好的检索性能,但其索引部分仍然需要全部加载到内存,成本仍未压缩到极致。
三、鲲鹏在Agent记忆系统上的创新技术
1. 上下文缓存系统
上下文缓存系统
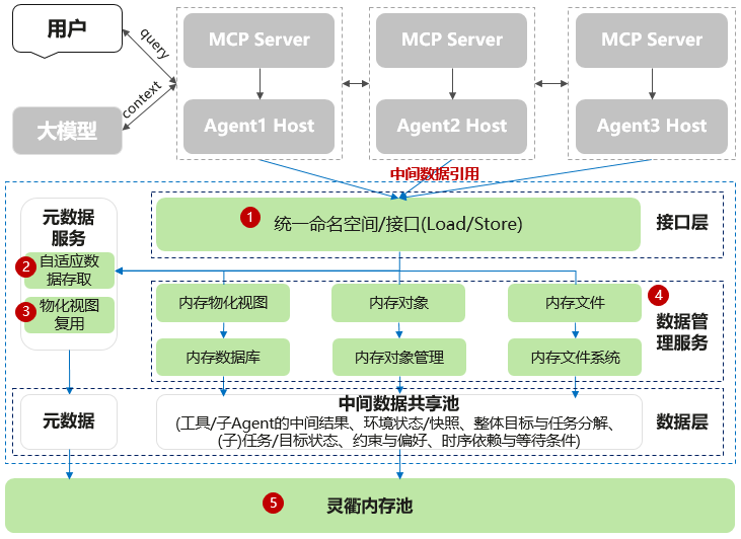
针对Agent多轮调用累计的大量中间数据导致上下文“爆炸”问题,我们提出了上下文缓存。核心思想:构建一个中间数据缓存系统,把MCP和Sub-Agent返回的中间数据存入缓存系统,并转换成数据引用后再通过上下文传递给大模型,而不是直接传递中间中间数据,把该引用作为参数直接填入下一个要调用的工具,并在Host侧再把该引用转换成实际数据后再调用工具。
该系统由以下部分组成:
1. 统一命名空间:基于元数据服务,统一数据库、内存对象以及内存文件三种语义,确保数据引用唯一性,提供Load/Store接口,通过数据引用在大模型、Agent Host以及工具之间自由流动、按需加载。
2. 自适应数据存取:根据用户的数据种类,自动选择数据库、对象或者文件进行存储;通过mmap的方式把临时数据映射到sub-agent和MCP server的进程空间,加速数据访问。
3. 物化视图复用:基于关系代数理论,构建语义解析层,确保具有包含关系的不同子查询可以复用相同物化视图查询。
4. 数据管理服务:内置SOTA内存数据库、内存对象管理系统和内存文件系统及完整的配套工具,用户也可自定义。
5. 基于UB池的数据访问加速:基于UB,跨超节点构建PB级内存池,进一步加速数据访问效率。
初步效果如下:
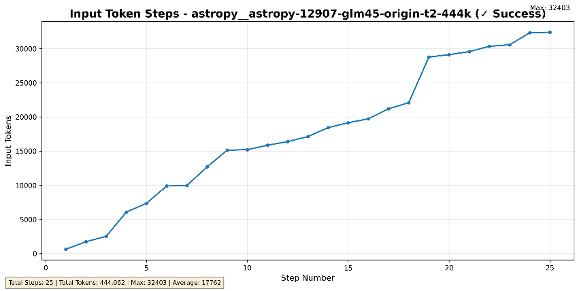
原生上下文管理
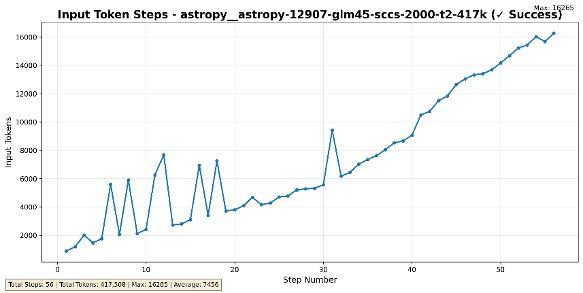
基于上下文缓存的上下文管理
基于GLM-4.5-Air跑SWE Benchmark,从上图可以看出,单次任务调用上下文减少了一半左右, Benchmark中280个Case平均输入token从1653k 降至 968k,平均轮次从60步增至71步,正确率持平,有效降低了成本。
3. 基于内存池的全局向量检索
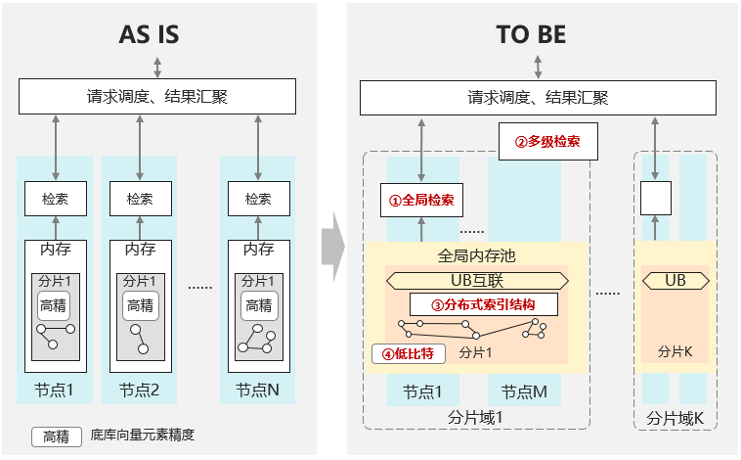
内存池的全局向量检索
HNSW检索算法需要将原始向量和索引数据全部放到内存中,以此获得更高的检索性能。针对大规模向量底库(百亿以上)的检索,原始向量和索引的内存占用量为百TB级,无法在主流通用服务器的单节点内存中容纳,需要采用分布式的方案。
传统做法是采用基于分片的分布式向量检索方案,将一个大的向量底库,拆分成N个分片,每个分片分别部署在不同的节点上。向量检索时,将查询请求路由到N个节点,同时进行本地检索,最后再将个节点的检索结果汇聚并返回TopK。
分片检索方案存在2个主要缺点:
(1)HNSW索引被分片,各分片独立检索,检索结果容易陷入局部最优。
(2)每个请求都需要所有节点参与计算,算力消耗大。
基于UB内存池的全局向量检索方案,利用UB互联能力,将M个节点组成一个大的内存池,内存容量百TB级,能够容纳大规模向量底库。向量检索时,只需路由到1个节点进行检索,利用UB的内存语义访问远端内存。针对超大规模向量底库,如果UB共享域无法容纳底库,也支持级联检索方案。
基于UB内存池的全局向量检索方案对比传统分片检索方案有如下优势:
(1)保留完整的HNSW整图索引,检索结果能做到全局最优。
(2)每个请求只有1个节点参与计算,算力消耗更低,同等算力情况能达到更高的QPS。
4. 超低内存混合介质向量检索
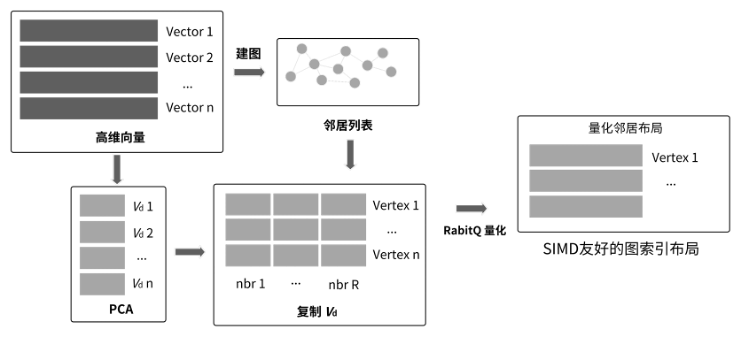
超低内存混合介质向量检索
核心思路:
(1)RabitQ+PCA量化检索:基于PCA+RabitQ的多重量化算法,大幅降低粗排过程计算开销,同时亲和SIMD计算流程,降低检索时延。
(2)SIMD友好的紧凑化索引结构:提出一种SIMD友好的紧凑化索引结构,直接整合量化编码与图结构信息,从而提升数据访问效率和计算性能,并通过全数据下盘降低内存开销。
方案效果:
(1)性能提升:在开源Gist等数据集上进行实测,相较于DiskANN、Starling等算法,检索性能QPS提升2-5x。
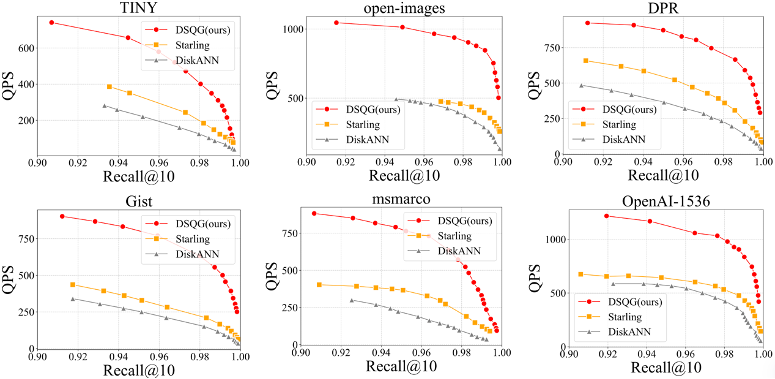
实测性能提升
(2)降低内存开销:基于亿级1024维数据集实测,检索性能较DiskANN在Kunpeng920芯片上性能提升2x+,内存开销下降99%+。
| 算法 | Cores | QPS | 内存占用 | SSD占用 | Recall10@10 |
|---|---|---|---|---|---|
| DiskANN | 16 | 2619 | ~12GB | 800GB | 95.00 |
| Ours | 16 | 5578 | ~100MB | 800GB | 95.12 |
四、OpenClaw + OpenViking + 鲲鹏,打造端到端AI Agent最佳实践
OpenClaw凭借本地自托管、强执行能力、低部署门槛的核心优势,成为2026年开源Agentic AI领域的现象级框架,鲲鹏联合OpenViking,打造OpenClaw + OpenViking + 鲲鹏服务器解决方案,经实测验证,核心效果如下:
| 测试场景 | 任务执行准确率提升 | Input Token消耗减少 |
|---|---|---|
| 场景1: 基础指令执行(单步骤任务) | 45% | 91% |
| 场景2: 多步骤流程处理(3-5步任务) | 60% | 92% |
| 场景3: 跨会话任务衔接(多轮交互) | 65% | 95% |