


基于容器CPU绑核与虚机QoS控制的参考实践,保障关键业务性能和稳定性
发表于 2026/03/12
0
非商用声明
该文档提供的内容为参考实践,仅供用户参考使用,用户可参考实践文档构建自己的软件,按需进行安全、可靠性加固,但不建议直接将相关Demo或镜像文件集成到商用产品中。
1 方案概述
1.1 背景
为了提高硬件资源的整体利用率,业务应用通常会采用物理机上多虚机部署或虚拟机内多容器部署的运行模式。在该场景下,不同业务实例共享同一套底层计算、内存及缓存资源,能够在一定程度上降低资源成本,但也不可避免地引入了资源竞争和性能干扰问题。
1.2 方案简介
针对多虚机、多容器混合部署下的性能干扰与资源争抢问题,本参考实践提出了一套基于CPU绑核、内存带宽QoS控制以及L3 Cache配额管理的性能优化方案。
该方案通过为业务实例绑定固定的CPU核心,减少任务频繁在不同CPU核心间切换带来的性能开销;同时结合内存带宽QoS与L3 Cache资源控制机制,对内存访问和缓存使用进行约束与隔离,避免单一业务对共享资源的过度占用。在此基础上,实现对关键业务的性能保障和对整体系统资源的可控使用。
本方案适用于物理机多虚机部署及虚拟机/物理机内多容器混部等典型场景,可根据业务的重要性、负载特性和性能要求,灵活选择资源控制策略。在不改变业务逻辑和应用架构的前提下,帮助业务方实现性能稳定性与资源利用率之间的平衡。
1.2.1 容器绑核
在虚拟机内运行多容器业务时,关键业务容器对CPU性能敏感,如果CPU调度不合理,可能出现性能波动、延迟增加或吞吐下降的问题。为保证关键业务容器的性能和稳定性,需要对关键业务容器进行CPU绑核,即将容器运行的进程绑定到指定的CPU核心上。
约束条件:
虚拟机内的每个容器都必须进行绑核,不允许随意调度到非指定核心,否则会相互干扰。
1.2.2 虚拟机QoS控制
多个虚拟机部署场景下,由于运行在同一NUMA节点上的虚拟机会共享内存带宽以及L3 Cache等公共资源,故当共享资源有限时,虚拟机之间可能出现资源争抢,导致性能下降。而鲲鹏920新型号处理器支持MPAM功能,能实现虚拟机的内存带宽以及L3 Cache大小的控制。通过限制虚拟机的内存带宽以及L3 Cache资源的使用,可以避免不同虚拟机业务间的相互干扰。
1. 内存带宽控制特性说明
内存带宽控制通过配置虚拟机XML来实现,可以对虚拟机可使用的最大内存带宽进行限制,也可保证竞争场景下的最小可用带宽,同时支持使用硬限制、配置带宽使用优先级等,从而提升关键业务的性能和稳定性。
2. L3 Cache控制特性说明
L3 Cache控制也是通过配置虚拟机XML来实现,可以对虚拟机在指定NUMA节点上可使用的L3 Cache大小进行限制,通过对L3 Cache进行配置以及隔离,可以减少多虚拟机场景下的Cache争抢,提升业务性能稳定性。
2 典型应用场景参考实践
2.1 场景介绍
2.1.1 场景说明
在一卡通业务场景,业务软件部署在一个虚拟机内,不同业务组件打包成多个容器进行部署,由于虚拟机资源有限,多容器部署方案在业务高峰时期,容易出现CPU和内存资源抢占导致关键业务性能下降,需要进行CPU绑核操作,保证关键业务性能。
2.1.2 场景应用部署图
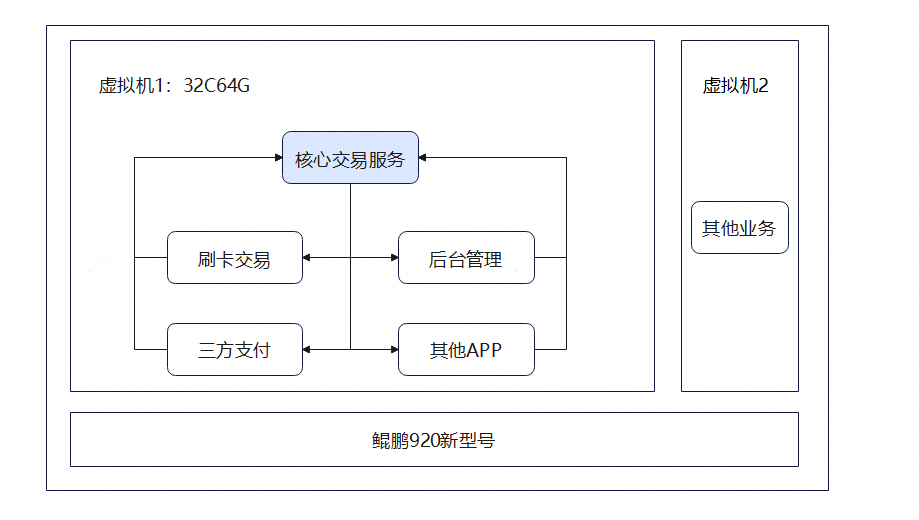
在一卡通业务场景中,核心交易服务作为系统的关键组件,承担着统一交易处理与业务协调的职责。刷卡交易终端、后台管理系统、第三方支付平台以及其他业务应用(APP)等多个业务系统,均访问核心交易服务,并由核心交易服务进行实时处理和响应。
在当前部署架构下,上述业务组件统一部署在同一虚拟机内,并以多个容器的形式运行,共享有限的 CPU 和内存资源。当系统处于高并发访问或业务高峰期时,容易出现 CPU 调度和内存资源争抢,进而导致核心交易服务响应延迟增加,影响刷卡交易等关键业务的处理性能。
因此,在该场景中需要对核心交易服务进行重点资源保障,通过CPU绑核等方式减少调度干扰,提升其运行稳定性。
2.1.3 软硬件配置
容器绑核调优对软硬件配置等并无具体的要求,此处对参考实践中的操作系统和业务软件等做相关说明:
表1 软硬件配置
类别 | 参数 |
|---|---|
CPU | 鲲鹏920新型号( 7270Z、5253Z、5252Z、5235Z、5230Z等) |
操作系统 | openEuler 24.03 SP2 |
表2 虚拟机配置
类别 | 参数 |
|---|---|
操作系统 | openEuler 20.03 SP4 |
CPU核数 | 32 |
内存 | 64G |
2.1.4 业务软件部署
模拟一卡通虚机多容器场景,采用redis和nginx两个关键组件为例进行部署,如下是参考实践中部署的业务软件:
表1 业务软件部署情况
容器名称 | 部署软件 | 说明 |
|---|---|---|
redis-server | Redis 服务端。 | 提供Redis服务,处理读写请求。 |
redis-client | Redis 压测客户端。 | 部署redis-benchmark进行压测,访问redis 服务。 |
nginx-server | Nginx 服务端。 | 提供Nginx服务,处理代理请求。 |
nginx-client | Nginx 压测服务端。 | 部署HTTP压测工具wrk进行压测,访问nginx服务。 |
2.2 容器调优指导
说明:
容器绑核适用场景:
对核心业务、实时性要求高的业务进行绑核。
不建议绑核:
业务对性能不敏感,或业务处理数据量小,不存在性能峰值或压力问题。
绑核建议:
在多NUMA节点服务器上(如双路或多路CPU),建议按NUMA节点进行CPU资源规划和绑核,确保容器使用的CPU核来自同一个NUMA节点,避免CPU跨NUMA节点绑定。
鲲鹏920新型号支持超线程,即将一个物理核虚拟成两个逻辑核,在进行绑核时,建议不要跨物理核进行绑核。
容器绑核可分为Docker和k8s两种场景,下面分别介绍这两种场景下容器绑核的方式。
2.2.1 Docker场景绑核
可根据单容器和多容器两种场景,在docker run或docker-compose中使用CPU绑核相关参数进行绑核。
基于当前的业务场景,虚拟机共有32核,绑核策略如下:
表1 绑核策略
容器名称 | 绑核范围 | CPU相对权重 | CPU使用量限制 |
|---|---|---|---|
redis-server | 0-23 | 2048 | 24.0 |
redis-client | 0-23 | 2048 | 24.0 |
nginx-server | 24-29 | 2048 | 6.0 |
nginx-client | 30-31 | 2048 | 2.0 |
如下针对docker run和docker-compose两种方式给出了对应的绑核示例,下面是对应的软件版本:
表2 软件配置
软件名称 | 版本 |
|---|---|
Docker | 18.09.0 |
Docker Compose | 2.25.0 |
1. docker run配置绑核参数
docker run的配置参数说明如下:
表3 docker run配置参数
字段 | 说明 | 参数值 |
|---|---|---|
--cpuset-cpus | 指定容器运行的CPU核心范围,绑定后容器只能在指定核心运行。 | 编号从 0 开始,表示CPU逻辑核编号集合,如 "0,1,2" 或 "0-3"。 |
--cpu-shares | 相对权重参数,在CPU发生竞争时,用于决定容器之间获得CPU时间的比例。 | 默认 1024。 |
--cpus | CPU使用量限制,限制容器在调度周期内可使用的CPU时间来生效,默认不设置上限,但容器可使用的CPU总量不超过其可分配的CPU核心数量。 | 支持小数,如2.5,表示最多消耗2.5个CPU核心等价的算力。 |
如下示例创建了容器,只能使用0-3核,且CPU权重是2048、CPU使用量不超过2:
docker run -dit \
--name <container-name> \
--cpuset-cpus="0-3" \
--cpu-shares=2048 \
--cpus=2 \
image:tag \
bash基于当前的业务场景,可执行以下命令对四个业务分别进行绑核:
redis-server容器:启动redis-server服务
docker run -dit \
--name redis-server \
--net=host \
--cpuset-cpus="0-23" \
--cpu-shares=2048 \
redis:latest \
bashredis-client容器:启动redis-client服务
docker run -dit \
--name redis-client \
--net=host \
--cpuset-cpus="0-23" \
--cpu-shares=2048 \
redis:latest \
bashnginx-server容器:启动nginx-server服务
docker run -dit \
--name nginx-server \
--net=host \
--cpuset-cpus="24-29" \
--cpu-shares=2048 \
nginx:latest \
bashnginx-client容器:启动nginx-clinet服务
docker run -dit \
--name nginx-client \
--net=host \
--cpuset-cpus="30-31" \
--cpu-shares=2048 \
nginx:latest \
bash若要查看容器可使用的CPU核心范围,可执行以下命令查看(以查看nginx-client容器为例):
docker exec nginx-client cat /sys/fs/cgroup/cpuset/cpuset.cpus执行结果如下:

若想停止服务,可执行以下命令:
docker stop nginx-client && docker rm nginx-client2. docker-compose配置绑核参数
多容器场景下,可通过docker-compose.yml配置文件实现多个容器的创建和配置,相比docker run更易管理。
docker-compose的配置参数说明如下:
表4 docker-compose配置参数
字段 | 说明 | 参数值 |
|---|---|---|
cpuset | 指定容器运行的CPU核心范围,绑定后容器只能在指定核心运行。 | 编号从 0 开始,表示CPU逻辑核编号集合,如 "0,1,2" 或 "0-3"。 |
cpu-shares | 相对权重参数,在CPU发生竞争时,用于决定容器之间获得CPU时间的比例。 | 默认 1024。 |
deploy.resources.limits.cpus | CPU使用量限制,限制容器在调度周期内可使用的CPU时间来生效,默认不设置上限,但容器可使用的CPU总量不超过其可分配的CPU核心数量。 | 支持小数,如2.5,表示最多消耗2.5个CPU核心等价的算力。 |
基于当前的业务场景,可按照以下内容创建绑核配置文件docker-compose.yml:
services:
redis-server:
image: redis:latest
container_name: redis-server
network_mode: host
cpuset: "0-23"
cpu_shares: 2048
deploy:
resources:
limits:
cpus: "24.0"
restart: "no"
command:
- bash
- -c
- cat /sys/fs/cgroup/cpuset/cpuset.cpus
redis-client:
image: redis:latest
container_name: redis-client
network_mode: host
cpuset: "0-23"
cpu_shares: 2048
deploy:
resources:
limits:
cpus: "24.0"
restart: "no"
command:
- bash
- -c
- cat /sys/fs/cgroup/cpuset/cpuset.cpus
nginx-server:
image: nginx:latest
container_name: nginx-server
network_mode: host
cpuset: "24-29"
cpu_shares: 2048
deploy:
resources:
limits:
cpus: "6.0"
restart: "no"
command:
- bash
- -c
- cat /sys/fs/cgroup/cpuset/cpuset.cpus
nginx-client:
image: nginx:latest
container_name: nginx-client
network_mode: host
cpuset: "30-31"
cpu_shares: 2048
deploy:
resources:
limits:
cpus: "2.0"
restart: "no"
command:
- bash
- -c
- cat /sys/fs/cgroup/cpuset/cpuset.cpus说明:
该方式启动容器后,若进程结束的容器会停止,需结合实际业务场景修改command字段为业务运行命令。
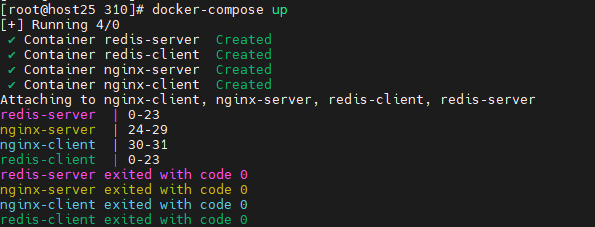
docker-compose.yml创建完成后,在同级目录下执行以下命令即可拉起服务:
docker-compose up如下可以看到不同容器绑定到不同的CPU核:
若想停止服务,可执行以下命令:
docker-compose down2.2.2 k8s场景绑核
在k8s场景下,业务通常以 Pod 形式运行,多个 Pod共享同一节点的CPU资源,此时需要通过CPU绑核的方式,将关键业务Pod固定运行在指定CPU核心上,避免被其他Pod干扰。
如下针对k8s给出了对应的绑核示例,下面是对应的软件版本:
表1 软件配置
软件名称 | 版本 |
|---|---|
Docker | 18.09.0 |
kubelet | 1.19.0 |
kubeadm | 1.19.0 |
kubectl | 1.19.0 |
k8s的配置参数说明如下:
表2 k8s配置参数
字段 | 说明 | 参数值 |
|---|---|---|
resources.requests.cpu | Pod 启动所需 CPU 核心数,整数表示独占核心,调度依据。 | "4" 表示请求 4 个核心,即4 个CPU核心等价的算力。 |
resources.limits.cpu | Pod CPU上限,整数表示独占核心。 | "4" 表示最多使用 4 个核心,即4 个CPU核心等价的算力。 |
requests.memory | Pod启动所需内存大小。 | "1Gi" 表示请求1GiB内存。 |
limits.memory | Pod 使用的内存大小上限。 | "1Gi" 表示最多使用1GiB内存。 |
cpuManagerPolicy | CPU 管理策略,static可绑定CPU核心。 | cpuManagerPolicy: static。 |
reservedSystemCPUs | 预留CPU资源,配合static使用。 | reservedSystemCPUs: "0-2"。 |
k8s实现CPU绑核有以下约束条件:
1、只有整数CPU才能在static policy下被独占绑定。
2、static模式配合requests.cpu=limits.cpu和requests.memory=limits.memory保证Pod独占核心。
下面是k8s开启static policy的步骤:
- 修改kubelet配置文件:
vim /var/lib/kubelet/config.yaml添加以下内容:
cpuManagerPolicy: static
reservedSystemCPUs: "30-31"2. 重启kubelet使配置生效:
systemctl stop kubelet
rm -f /var/lib/kubelet/cpu_manager_state
systemctl start kubelet可通过以下命令查看static策略是否生效,若存在"policyName":"static"则代表配置成功:
cat /var/lib/kubelet/cpu_manager_state基于当前的业务场景,可根据下面的YAML文件内容来创建Pod:
redis-server容器:启动redis-server服务
apiVersion: v1
kind: Pod
metadata:
name: redis-server
spec:
restartPolicy: Never
hostNetwork: true
containers:
- name: redis-server
image: redis:latest
imagePullPolicy: IfNotPresent
command:
- bash
- -c
- cat /sys/fs/cgroup/cpuset/cpuset.cpus
resources:
requests:
cpu: "12"
memory: "10Gi"
limits:
cpu: "24"
memory: "10Gi"redis-client容器:启动redis-client服务
apiVersion: v1
kind: Pod
metadata:
name: redis-client
spec:
restartPolicy: Never
hostNetwork: true
containers:
- name: redis-client
image: redis:latest
imagePullPolicy: IfNotPresent
command:
- bash
- -c
- cat /sys/fs/cgroup/cpuset/cpuset.cpus
resources:
requests:
cpu: "12"
memory: "10Gi"
limits:
cpu: "24"
memory: "10Gi"nginx-server容器:启动nginx-server服务
apiVersion: v1
kind: Pod
metadata:
name: nginx-server
spec:
restartPolicy: Never
hostNetwork: true
containers:
- name: nginx-server
image: nginx:latest
imagePullPolicy: IfNotPresent
command:
- bash
- -c
- cat /sys/fs/cgroup/cpuset/cpuset.cpus
resources:
requests:
cpu: "6"
memory: "10Gi"
limits:
cpu: "6"
memory: "10Gi"nginx-client容器:启动nginx-clinet服务
apiVersion: v1
kind: Pod
metadata:
name: nginx-client
spec:
restartPolicy: Never
hostNetwork: true
containers:
- name: nginx-client
image: nginx:latest
imagePullPolicy: IfNotPresent
command:
- bash
- -c
- cat /sys/fs/cgroup/cpuset/cpuset.cpus
resources:
requests:
cpu: "2"
memory: "10Gi"
limits:
cpu: "2"
memory: "10Gi"以nginx-clinet服务为例,若配置文件名称为nginx_clinet_bind_cpu.yaml,则执行以下命令拉起服务:
kubectl apply -f nginx_clinet_bind_cpu.yaml如下可以看到nginx-clinet容器绑定到两个CPU核:

若想停止服务,可执行以下命令:
kubectl delete -f nginx_clinet_bind_cpu.yaml2.3 虚拟机调优指导
2.3.1 约束条件
- 必须明确指定虚拟机可使用的CPU核的范围,可根据NUMA拓扑和业务需求进行规划。
- 核心业务所绑定的CPU核心不得分配给其他虚拟机使用,以保证性能和资源隔离。
2.3.2 环境部署
新硬件特性对OS内核版本和配套软件有约束,要在鲲鹏920新一代服务器上使用MPAM特性,需要使用配套OS和相关软件:
表1 软硬件配置
类别 | 配置 |
|---|---|
CPU | 鲲鹏920新型号( 7270Z、5253Z、5252Z、5235Z、5230Z等) |
操作系统 | 参考实践以openEuler 24.03 SP2为例(要求不低于该版本) |
虚拟化管理工具 | 参考实践以libvirt 9.10.0为例(要求不低于该版本) |
虚拟化组件 | 参考实践以QEMU 8.2.0为例(要求不低于该版本) |
参考实践的虚拟机配置如下,仅做参考,并没有具体要求:
表2 虚拟机配置
类别 | 配置 |
|---|---|
操作系统 | openEuler 22.03 SP4 |
CPU核数 | 32 |
内存 | 64G |
测试工具 | lmbench 3-4 |
资源分配和规划
1. 执行以下命令可以查看NUMA拓扑即NUMA对应的CPU核心:
lscpu | grep NUMA如下所示,NUMA 0对应的CPU逻辑核为0-63:

2.由于虚拟机在同一NUMA节点上共享内存带宽以及L3 Cache资源,故参考实践构建两个在同一NUMA节点的虚拟机进行测试,内存大小均为64G,绑定的CPU核分别为0-31(虚拟机1)和32-63(虚拟机2),并分别测试内存带宽和L3 Cache的控制效果以及对业务的性能影响。
以下是虚拟机1的XML配置,将虚拟机核绑在NUMA 0,虚拟机2的配置类似,但需注意将cputune字段的cpuset范围改为32-63:
<domain type='kvm'>
<numatune>
<memnode cellid='0' mode='strict' nodeset='0'/>
</numatune>
<cpu mode='host-passthrough' check='none'>
<numa>
<cell id='0' cpus='0-31' memory='67108864' unit='KiB'/>
</numa>
</cpu>
<cputune>
<vcpupin vcpu='0' cpuset='0'/>
<vcpupin vcpu='1' cpuset='1'/>
...
<vcpupin vcpu='31' cpuset='31'/>
</cputune>
</domain>使能MPAM特性
要使能MPAM特性,需修改内核启动参数,按如下编辑/boot/efi/EFI/openEuler/grub.cfg配置文件,添加arm64.mpam:

然后执行reboot重启物理机,并执行以下命令挂载resctrl文件系统:
mount -t resctrl resctrl /sys/fs/resctrl/执行以下命令查看是否有内容,有则代表安装成功:
ll /sys/fs/resctrl2.3.3 内存带宽控制方案
内存带宽控制的配置参数说明如下:
表1 内存带宽控制参数
字段 | 说明 | 参数值 |
|---|---|---|
vcpus | 需要限制的vCPU列表。 | vCPU编号或范围,如:0,1,2 或 0-3。 |
id | NUMA ID。 | 要控制的NUMA ID。 |
bandwidth | 最大可用带宽上限,百分比。 | 有效值范围[1,100]。 |
min_bandwidth | 最小保证内存带宽,百分比。 | 有效值范围[0,100]。 |
hardlimit | 是否启用硬限制。 | 有效值0或者1。 |
priority | 内存带宽分配优先级,数据大优先级高。 | 有效值[0,7]。 |
下面展示了配置内存带宽的步骤:
1. 执行以下命令关闭虚拟机:
virsh shutdown <vm_name>2. 执行以下命令编辑虚拟机XML配置,其中<vm_name>为虚拟机名称:
virsh edit <vm_name>如下配置将内存带宽限制到50%:
<domain type='kvm'>
<cputune>
<memorytune vcpus='0-31'>
<node id="0" bandwidth="50" min_bandwidth="10" hardlimit="1" priority="5"/>
</memorytune>
</cputune>
</domain>3. 执行以下命令启动虚拟机:
virsh start <vm_name>4. 可在物理机上查看schemata文件,确认MPAM控制组是否创建成功,如下所示:

如下为带宽测试步骤:
# 安装测试工具lmbench
yum update && yum install -y lmbench
# 测试命令
/opt/lmbench/bin/bw_mem -P 32 -N 5 512M rd以下展示了不同内存带宽大小下的测试效果:
表2 内存带宽测试结果
场景 | 实测带宽(MB/s) |
|---|---|
不限制内存带宽 | 116340.18 |
限制内存带宽70% | 85738.05 |
限制内存带宽50% | 69591.50 |
此处需要注意的是,当存在两台或两台以上的虚拟机竞争同一NUMA节点上的内存带宽资源时,均需要配置内存带宽限制,以下通过示例说明该情况。
在同一个NUMA节点上创建两台32C/64G的虚拟机,并同时执行内存带宽控制测试。测试命令如上所示,具体测试结果如下:
表3 内存带宽竞争测试结果
场景 | 虚拟机1实测带宽(MB/s) | 虚拟机2实测带宽(MB/s) |
|---|---|---|
虚拟机1限制内存带宽50%,虚拟机2不限制 | 57927.27 | 77680.95 |
虚拟机1限制内存带宽50%,虚拟机2限制内存带宽20% | 69591.50 | 28437.25 |
默认情况下,操作系统会按进程组默认权限分配带宽,可能导致已限制带宽的虚拟机性能受到影响。
2.3.4 L3 Cache控制方案
L3 Cache控制的配置参数说明如下:
表1 L3 Cache控制参数
字段 | 说明 | 参数值 |
|---|---|---|
vcpus | 需要限制的vCPU列表。 | vCPU编号或范围,如:0,1,2 或 0-3。 |
id | NUMA ID。 | 要控制的NUMA ID。 |
level | Cache Level。 | L3。 |
type | 参数类型。 | 有效值有both、code、data,分别对应MPAM中的L3、L3CODE、L3DATA。 |
size | Cache Line数值,与unit一起组成Cache Line大小。 | 需是单条Cache Line大小的整数倍,最小是单条Cache Line大小,且需小于单个NUMA的L3 Cache大小。 |
unit | Cache Line单位。 | 有效值有KiB、MiB以及GiB,默认值为KiB。 |
说明:
由于libvirt限制L3 Cache时,要求独占Cache Line,需要事先调整其他控制组(包括默认控制组)的Cache Line使用情况,空余出足够的Cache Line,但需保证其他控制组(包括默认控制组)的L3 Cache大小至少为单条Cache Line大小。
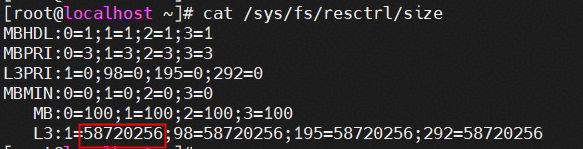
物理机L3 Cache大小查看
如下所示,单个NUMA的L3 Cache大小为58720256字节即56MiB:
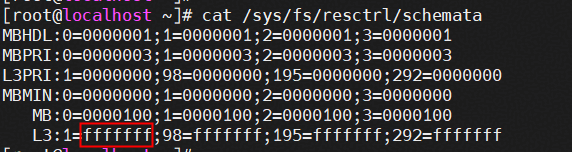
如下所示,共有7位十六进制掩码,对应28位二进制掩码,即28条Cache Line,则单条Cache Line的大小为2MiB:
L3 Cache配置示例
如下示例展示了如何将虚拟机的L3 Cache大小限制为4MiB:
1. 修改默认控制组L3 Cache数据,将最高两位掩码对应的Cache Line设置为空闲(此处最多将前27为掩码设置为空闲),即空出4MiB的L3 Cache空间:
echo "L3:1=3ffffff" > /sys/fs/resctrl/schemata2. 执行以下命令关闭虚拟机:
virsh shutdown <vm_name>3. 执行以下命令编辑虚拟机XML配置:
virsh edit <vm_name>如下配置将L3 Cache限制到4MiB:
<domain type='kvm'>
<cputune>
<cachetune vcpus='0-31'>
<cache id='0' level='3' type='both' size='4' unit='MiB'/>
</cachetune>
</cputune>
</domain>4. 执行以下命令启动虚拟机:
virsh start <vm_name>5. 可在物理机上查看schemata文件,确认MPAM控制组是否创建成功,如下所示,虚拟机的L3 Cache大小被限制在4MiB:

L3 Cache配置对mem latency的影响
L3 Cache的配置会影响缓存命中率。当发生Cache Miss时,CPU需要访问内存获取数据,从而增加mem latency(内存访问延迟)。mem latency用于衡量CPU从发起内存访问请求到获取数据所需的时间,是评估系统性能的重要指标之一。在对时延高度敏感的业务场景中,通过合理配置L3 Cache以降低Cache Miss率,可以有效减少mem latency,提升应用的响应速度和整体性能。
通过采用mem-lat作为测试工具, 测试L3 Cache在不同的ways下,内存latency的分布情况,也从侧面验证MPAM对L3 Cache的隔离功能。如下分别测试不同ways的mem latency,并绘制成图片:
图1 内存访问延迟测试
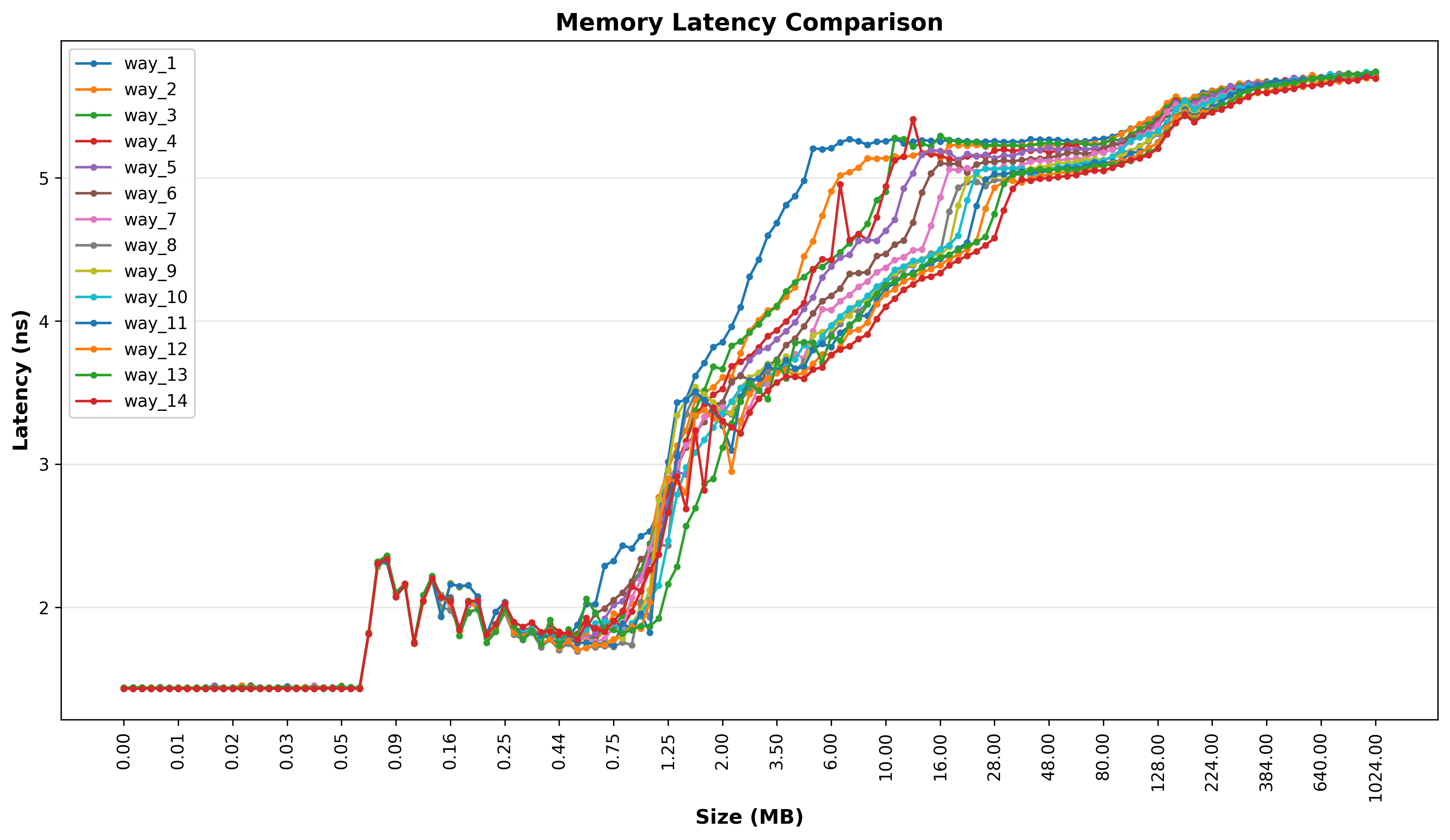
2.3.5 模拟业务性能测试
下面基于redis场景,验证内存带宽限制以及L3 Cache大小控制对redis性能的影响。
测试步骤:
1. 安装redis
yum install -y redis2. 启动redis服务:
redis-server3. 另起客户端,压测性能:
redis-benchmark -t set,get -n 1000000 -c 100 -d 256 --threads 2 -h <vm_ip>两台虚拟机的配置均为32C64G,且均绑定NUMA 0,内存带宽限制以及L3 Cache大小控制情况和测试结果如下所示:
表1 模拟业务性能测试结果
控制项 | 虚拟机1配置 | 虚拟机2配置 |
|---|---|---|
内存带宽限制 | 最大内存带宽50% | 最大内存带宽20% |
L3 Cache大小控制 | L3 Cache大小28MiB | L3 Cache大小14MiB |
吞吐(requests/s) | 210482.00 | 173882.81 |