


SVE指令Predicate格式与Bitmask格式的相互转换并在内存中读写
发表于 2026/04/15
0
作者 | 王一权
一、概述
Bitmask作为一种高效的数据结构,在大数据处理、数据库系统及现代查询引擎中广泛应用。在x86向量化指令集中,Bitmask常用于压缩控制信息,如将多个布尔型控制位合并为一个整数类型,每个bit控制一个元素。AVX512指令集中的`_mm512_cmp_epi32_mask`指令用于对两个512位宽的向量进行逐元素比较,结果生成一个16位的掩码,存储在AVX-512的专用掩码寄存器中。K寄存器支持直接存储和从内存读取__mmask16,而P寄存器的长度与向量长度正比,无法直接与W/X/D寄存器交互。SVE使用Predicate寄存器控制向量lane的开闭,P寄存器的有效位根据向量中的元素数量均分。Bitmask与P寄存器之间的高效转换对性能至关重要,对于不同长度的元素,转换方法包括直接移动数据、使用unpack指令和查表等。
二、Bitmask格式
Bitmask作为一种高效的数据结构,在大数据处理、数据库系统以及现代查询引擎中都有广泛应用。在实际业务开发中,常常会使用Bitmask(位掩码)的数据格式来压缩控制信息。例如,将多个布尔型控制位合并为一个整数类型,每个bit控制一个元素,高效地表达状态集合。具体而言,1个uint8可以控制8个元素,uint32可控制32个元素,以此类推。
在x86向量化指令集中,Bitmask一般可以直接作为控制量,例如AVX512指令:
__mmask16 _mm512_cmp_epi32_mask (__m512i a, __m512i b, _MM_CMPINT_ENUM imm8)这条intrinsic指令的功能是对两个512位宽的向量(每个向量包含16个32位有符号整数)进行逐元素比较,比较的方式由imm8立即数查表确定,结果生成一个16位的掩码(__mmask16),用于标识哪些元素满足比较条件。这条指令的返回值存储在AVX-512的专用掩码寄存器(k0-k7)中。K寄存器可以使用kmovw等指令直接拷贝数值到通用寄存器中。
x86的控制量长度、结果位数均是固定的,只能应用于支持AVX-512的x86平台,与AVX2不通用。
K寄存器支持直接存储,直接将__mmask16存储到内存中,后续的算子可以直接从内存中读取__mmask16,控制向量化lane的开闭。
三、P寄存器的数据交互
P寄存器的长度与向量长度正比,因此是变长的位图。
由于长度可变(如16/32/64/128位),P寄存器无法像W寄存器那样作为标量寄存器使用。因此也没有直接提供P寄存器与W/X/D寄存器直接交互的功能,不存在形如MOV P0, W/X/D0的指令,无法直接在寄存器中搬移数据,无法给编译器提供合适的地址类型,intrinsic没有提供P寄存器直接从内存读写的指令,可以使用如下的内嵌汇编,令P寄存器与内存交互。
svbool_t pg;
uint32_t bitmasks[];
__asm__ __volatile__("ldr %0, [%1]" : "=Upl" (pg) : "r" (&bitmasks[idx]) : "memory");
__asm__ __volatile__("str %0, [%1]" : "=Upl" (pg) : "r" (&bitmasks[idx]) : "memory");四、P寄存器的有效位
SVE使用Predicate寄存器,控制向量lane的开闭。
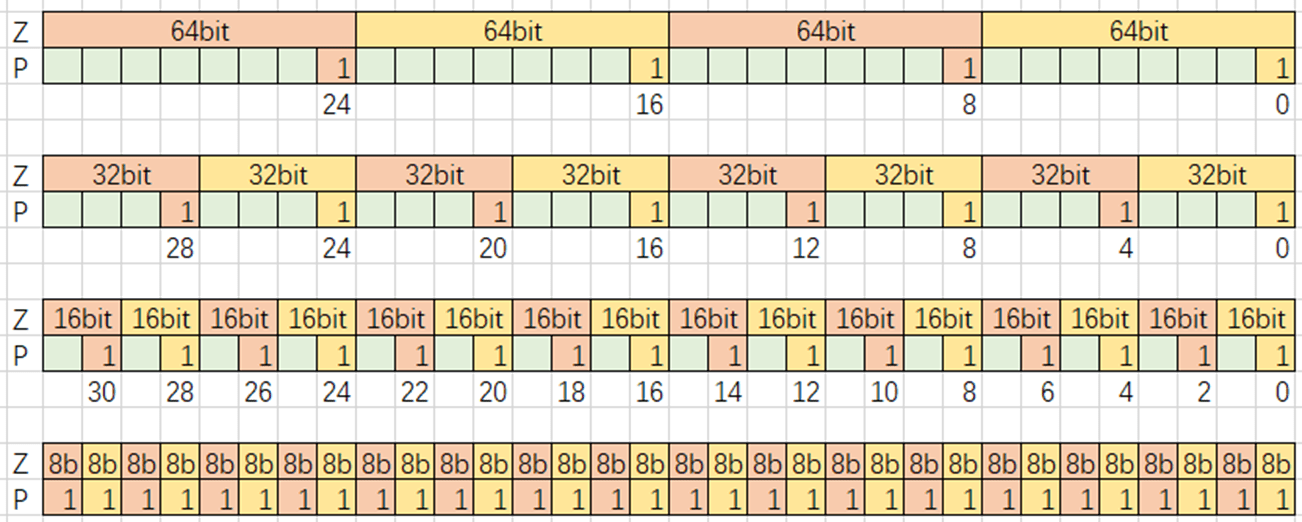
硬件上P寄存器长为Z寄存器的八分之一(SVE256的P寄存器长度为32)。Z寄存器总长固定,当元素宽度变化时,Z寄存器中能容纳的元素数量也会变化。P寄存器每一个bit控制一个Z寄存器中的元素,有效位数量会随着控制的元素类型变化。
- 64位元素:Z寄存器容纳4个元素(256/32),因此P寄存器只有4位有效。
- 32位元素:Z寄存器容纳8个元素,P寄存器只有8位有效。
- 16位元素:Z寄存器容纳16个元素,P寄存器只有16位有效。
- 8位元素:Z寄存器容纳32个元素,P寄存器的所有32位都有效。
由于硬件设计,这些有效位根据向量中的元素数量均分,每段最低位生效,即P寄存器的有效位是不连续的。例如,处理32位元素时(8个元素),P寄存器的有效位是第0、4、8、12、16、20、24、28位(每4位取1位),其余位无效。这种分布方式是为了兼容不同元素宽度下的统一控制逻辑。
Bitmask:1011 1101 <-> P寄存器:00010000000100010001000100000001
如何高效完成上述的双向转换影响了Bitmask相关算子的性能。
五、Bitmask转换为P寄存器
对于长度为8的元素,P寄存器中的格式与Bitmask相同,使用内嵌汇编直接移动数据。对于长度为16/32的元素,间隔补0的位运算是非线性的,需要使用Pg unpack指令。
向量化场景下要进行循环展开,可以合并进行。如下图所示,32位的4个P寄存器的格式转换可以共用中间值,均摊了加载与第一层unpack,性能较优。
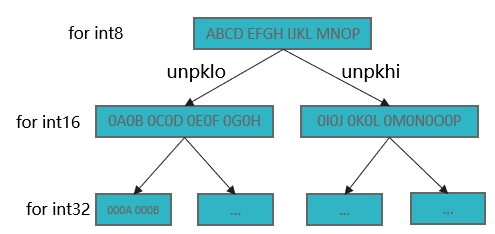
__asm__ __volatile__("ldr %0, [%1]" : "=Upl" (maskb0) : "r" (&nulldir[nullidx]) : "memory");
svbool_t maskh0 = svunpklo(maskb0);
svbool_t maskh1 = svunpkhi(maskb0);
svbool_t maskw0 = svunpklo(maskh0);
svbool_t maskw1 = svunpkhi(maskh0);
svbool_t maskw2 = svunpklo(maskh1);
svbool_t maskw3 = svunpkhi(maskh1);对于长度为64的元素,输入的种类数有限,这种场景下也可以选择查表:
uint32_t bn0 = *loc;
uint32_t bmd0 = bn0 & 0xF;
uint32_t bmd1 = ( bn0 >> 4 ) & 0xF;
uint32_t bmd2 = ( bn0 >> 8 ) & 0xF;
uint32_t bmd3 = ( bn0 >> 12 ) & 0xF;
... ...
__asm__ __volatile__("ldr %0, [%1]" : "=Upl" (pf0) : "r" (pg_table + bmd0) : "memory");
__asm__ __volatile__("ldr %0, [%1]" : "=Upl" (pf1) : "r" (pg_table + bmd1) : "memory");
__asm__ __volatile__("ldr %0, [%1]" : "=Upl" (pf2) : "r" (pg_table + bmd2) : "memory");元素长度/实现方式 | 树形unpack | 查表 |
|---|---|---|
8 | 无需格式转换 | 无需格式转换 |
16(建议unpack) | 每元素均摊0.5load 1unpack | 表格大小需求2^16,过大不宜查表 |
32(建议unpack) | 每元素均摊0.25load 1.5unpack | 表格大小1024byte,每元素均摊2位运算 1.25load |
64(建议查表) | 每元素均摊0.125load 1.75unpack | 表格大小64byte,每元素均摊2位运算 1.25load |
六、P寄存器转换为Bitmask
- 对于长度为8的元素,P寄存器中的格式与Bitmask相同,使用内嵌汇编直接移动数据。
- 对于长度为16/32的元素,在SVE长度为256时,这2个长度均满足“元素数≤元素长度”,辅助向量的生成与元素无关,只需要初始化时执行,单循环的开销只有addv。
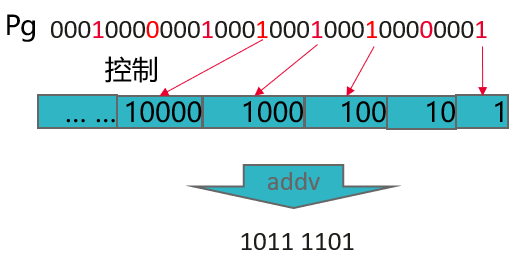
svuint32_t indices = svindex_u32(0, 1);//生成向量 0、1、2、3、4....
svuint32_t ones = svdup_n_u32(1); //生成全1向量
svuint32_t shifts = svlsl_u32_x(svptrue_b32(), ones, indices);
//使用全1向量,左移生成向量 1,10,100,1000,10000...(二进制)
svbool_t pg;//转换的P寄存器
uint32_t bitmask = svaddv(pg, shifts);