


编解码场景satd算子使能uzp+maxp NEON指令实现算子性能提升
发表于 2026/04/15
0
作者 | 蒋颖昕
一、概述
SATD(变换域绝对差和)是视频编码中用于评估块相似度的关键代价函数,尤其在帧间预测的运动估计和模式决策中应用广泛。与传统的SAD(绝对差和)相比,SATD更接近编码过程中的实际失真,能提高预测精度,同时保持良好的计算效率,因此成为x265、H.264等编码器的默认选择。SATD的计算主要涉及Hadamard变换,通过蝶式运算减少计算量,对4x4的矩阵执行一系列变换后求绝对值和。x265中SATD算子的实现流程包括列和行的Hadamard变换,通过TRN指令优化计算过程,但引入较多TRN指令影响性能。通过使用addp、subp、maxp等指令优化水平加减法,可以显著减少TRN指令的使用,提高算子性能,不同算子上实现10~23%的性能提升。
二、背景介绍
SATD(Sum of Absolute Transformed Differences,变换域绝对差和)是视频编码中用于评估块相似度的核心代价函数,广泛应用于帧间预测的运动估计(ME)和模式决策中。相比传统的 SAD(绝对差和),SATD更接近编码过程中的实际失真(考虑变换和量化的影响),能提升预测精度,同时计算效率适中,是x265、H.264等编码器的默认选择。
计算过程中主要涉及hadamard变换,对一个4-input的hadamard变换示意图如下:
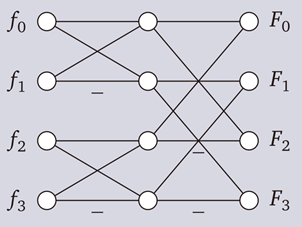
其中
F0 = f0 + f1 + f2 + f3
F1 = f0 - f1 + f2 - f3
F2 = f0 + f1 - f2 - f3
F3 = f0 - f1 - f2 + f3一般会用所谓蝶式运算减少计算量
tmp0 = f0 + f1
tmp1 = f0 - f1
tmp2 = f2 + f3
tmp3 = f2 - f3
F0 = tmp0 + tmp1
F1 = tmp2 + tmp3
F2 = tmp0 - tmp1
F3 = tmp2 - tmp3通过蝶式运算减少了4次加减法,在x265/HW265中,satd算子即对一个4x4的矩阵执行一系列hadamard变换操作后求绝对值和。
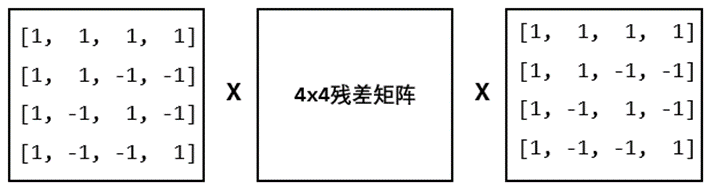
- 针对4x4残差矩阵的每一行做hadamard变换,得到中间结果矩阵
- 针对4x4中间结果矩阵的每一列做hadamard变换,得到变换结果
- 对结果矩阵执行绝对值求和,得到代价评估值

上图展示一个stad_4x4变换的案例,输入矩阵前后分别右乘和左乘系数矩阵,得到结果矩阵,对其进行求绝对值和,得到最终结果。
三、指令使能
目前x265中对于satd算子的实现流程为:
- 计算每列4个值对应的hadamard结果(类似于左乘系数矩阵)同一列不同行的数据保存在不同的向量中,两两做一次ADD和SUB操作得到tmptmp两两做一次ADD和SUB操作得到每列hadamard结果
- 基于列的hadamard结果计算行的hadamard变换(类似于右乘系数矩阵)通过TRN指令将同一行的值在不同向量中对齐排列两两做一次ADD和SUB操作得到tmp通过TRN指令继续将同一行的值在不同向量中对齐排列对结果向量取绝对值后两两求max,求和得到最终结果

流程1比较易懂,用一个例子说明流程2的计算过程
- 2.1 通过TRN指令将原本在同一向量中的数据分散到两个向量中并让他们对齐排列(将A0+B0+C0+D0和A1+B1+C1+D1在两个向量中对齐)
- 2.2 对应行hadamard的第一步运算
- 2.3 继续通过TRN指令将hadamard第二步需要运算的值在向量之间对齐
- 2.4 通过计算过程的优化节省了原本要做的ADD和SUB操作

x265的当前实现问题在于引入较多TRN指令影响算子性能,观察可以发现,对于列hadamard的计算十分简单,因为所有参与计算的值都是在向量中对齐排列的,可以直接应用“垂直加减法“(即ADD和SUB指令)。
// v2: [A0, A1, A2, A3, A4, A5, A6, A7]
// v3: [B0, B1, B2, B3, B4, B5, B6, B7]
addpv0.8h, v2.8h, v3.8h // v0: [A0+A1, A2+A3, A4+A5, A6+A7, B0+B1, B2+B3, B4+B5, B6+B7]
subpv1.8h, v2.8h, v3.8h // v1: [A0-A1, A2-A3, A4-A5, A6-A7, B0-B1, B2-B3, B4-B5, B6-B7]
maxp v0.8h, v0.8h, v1.8h // v0: [max(A0+A1,A2+A3), max(A4+A5, A6+A7), ...]对于行hadamard也可以通过水平加减法来消除TRN指令,应用addp、subp、maxp之后可以完全消除原有实现的TRN指令,减少算子关键路径执行指令数约40%。

当前鲲鹏920新型号处理器芯片不支持subp指令,因此通过uzp1/uzp2 + add/sub来模拟实现。
addp v0.16b, v2.16b, v3.16b
subp v1.16b, v2.16b, v3.16b
// 等价于uzp + add*sub
uzp1 v2.16b, v0.16b, v1.16b
uzp2 v3.16b, v0.16b, v2.16b
add v0.16b, v2.16b, v3.16b
sub v1,16b, v2.16b, v3.16b相较subp方案会引入uzp开销,但仍能减少20%的TRN指令。
四、收益分析
算子 | 性能提升倍率 | opt cycle数 | x265 cycle数 |
|---|---|---|---|
satd[8x8] | 1.14x | 11.61 | 13.12 |
satd[16x16] | 1.23x | 30.05 | 36.88 |
sa8d[8x8] | 1.10x | 15.37 | 16.86 |
sa8d[16x16] | 1.12x | 46.09 | 51.79 |
相比x265实现,uzp+maxp实现在不同算子上实现10~23%的性能提升,端到端性能在8核500帧的yuv测试中提升1.1%。
五、实践总结
对于一些水平类的操作,可以多考虑pair计算指令,减少不必要的转置指令。