


Witty-Assistant-rag:一款高效检索增强引擎详解
发表于 2026/04/29
0
Witty-Assistant-rag:一款高效检索增强引擎详解
1. 引言
当前大语言模型技术发展成熟,检索增强生成RAG技术快速迭代,为大模型搭建外部专家知识库,有效提升专业领域知识理解与落地应用能力。Witty-Assistant-rag是openEuler社区官方RAG项目,具备多样化场景化文档解析能力和灵活的混合检索能力,可适配各类业务场景。项目核心优势为内置完善的RBAC基于角色的访问控制机制,支持企业实现知识库分级管理、权限管控与协同办公,显著降低企业级知识库运维成本。
2. 架构设计
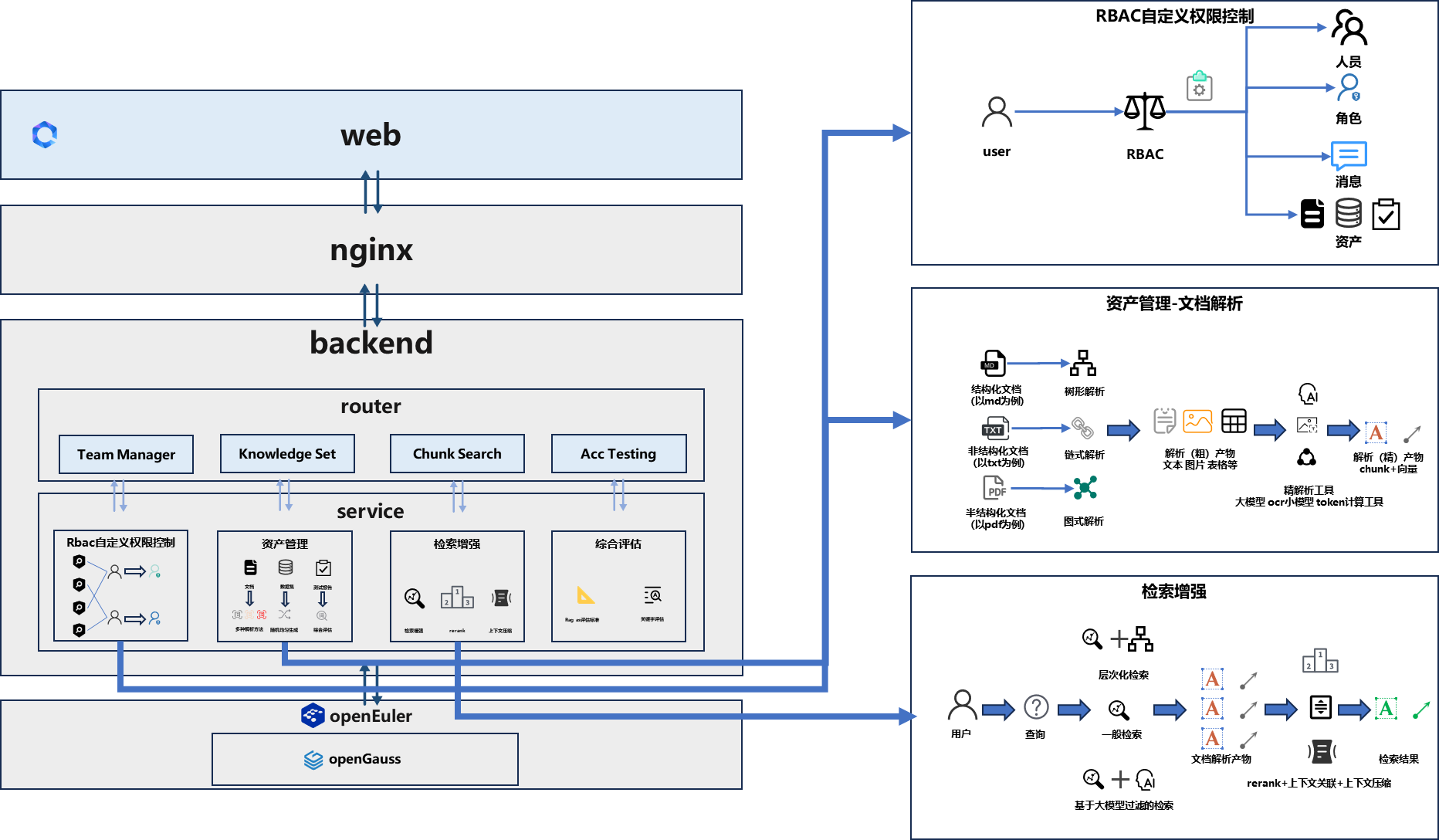
Witty-Assistant-rag采用四层分层架构,从上至下依次为Web层、Nginx层、Backend层、openEuler&openGauss基础层。
Web层提供可视化交互界面,集成团队管理、知识库操作、检索增强问答、准确率测试四大功能,用户可通过图形化界面简易操作。
Nginx层承担反向代理作用,保障前后端通信安全稳定,隔离前后端服务,规避后端服务直接暴露的风险。
Backend层是引擎核心,负责提供API接口、核心算法运行与数据库交互,实现团队管理、文档解析、检索增强、效果测试等全部核心功能。
openEuler&openGauss基础层提供底层支撑,由openEuler操作系统保障服务稳定运行,依托openGauss数据库完成各类数据安全存储。
2.1 团队管理功能
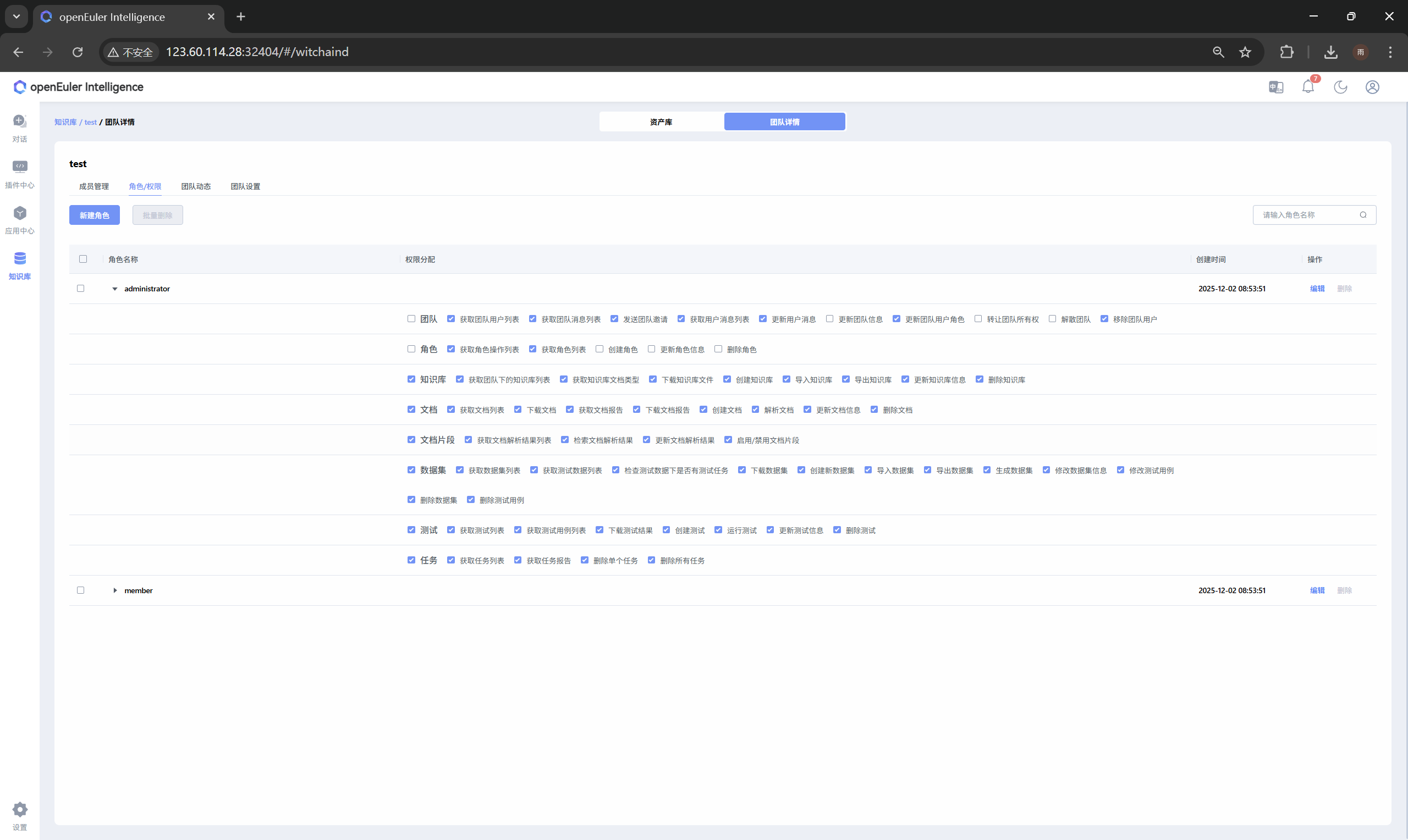
基于RBAC权限模型,对团队人员、角色、操作日志、文档及知识库等资产进行精细化划分与全生命周期管理,严格管控操作权限,满足企业多部门多角色协同办公需求。
2.2 资产管理-文档解析功能
支持结构化、半结构化、非结构化三类文档解析,通过标准化处理生成文本块与向量数据,统一存储至openGauss数据库。兼容doc、docx、pdf、html、json、yaml、md、pptx、txt、xlsx、csv以及主流图片等多种文件格式。
内置六种差异化解析方法,general轻量高效适用于常规文字表格提取,ocr依托模型实现图片文字提取,enhanced可对图片内容生成摘要,qa适配问答类文档解析,deep针对复杂格式PDF优化,fine为高精度PDF结构化解析。不同解析方式在准确率和处理速度上各有差异,可按需选用。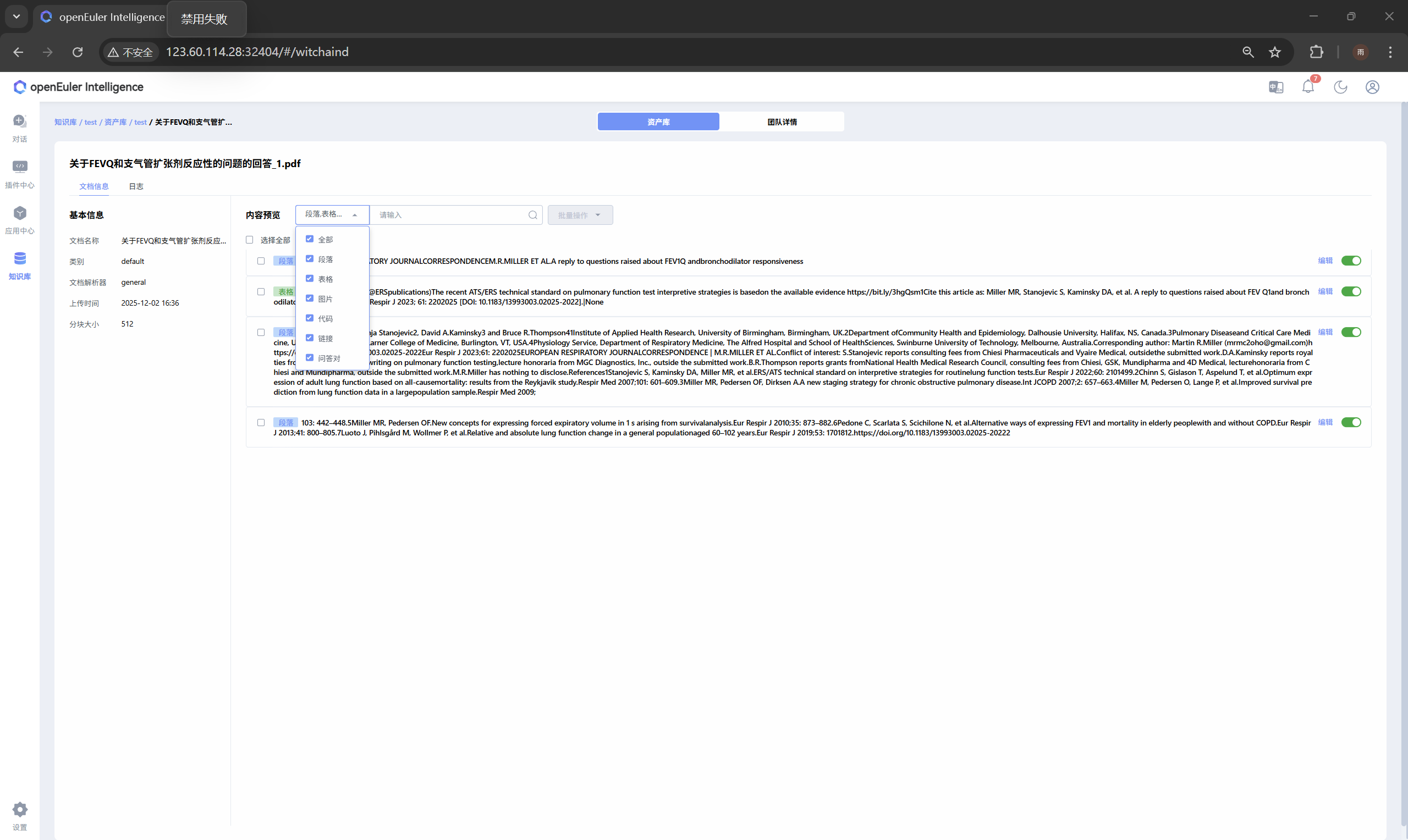
2.3 检索增强功能
以关键字检索和向量检索为基础,结合混合检索、分层检索、过滤检索等方式,搭配重排序、上下文填充、token压缩等优化手段,兼顾检索召回率、内容完整性与运行成本。
共提供八种检索方法,包含向量语义检索、BM25关键字精准检索、关键字与向量融合检索、动态权重混合检索、文档摘要筛选检索、结构化文档分层检索、大模型辅助过滤检索、查询语句扩写检索,覆盖通用场景、专业名词检索、长文档检索、复杂问题检索等多种需求,各方式在算力消耗和检索耗时上形成差异化适配。
3. 核心功能详解
项目围绕团队协同、知识库构建、检索问答、效果评估打造完整业务闭环,包含三大核心模块。
3.1 团队管理 企业级协同管控核心
用户可自主创建团队,支持公开和私密两种模式,公开团队可被所有用户申请加入,私密团队仅能通过邀请加入。
团队内部可进行成员管理、自定义角色与权限配置、全流程操作日志记录,同时支持修改团队信息、移交或解散团队。团队加入分为申请加入和邀请加入两种模式,全方位保障企业团队资产安全与权限合规。
3.2 知识库管理 全流程资产构建与优化
在团队资产库中可创建专属知识库,自定义知识库名称、解析规则、检索参数等配置。支持多格式文档批量上传与自动解析,用户可手动编辑、启停解析内容,优化文本质量。
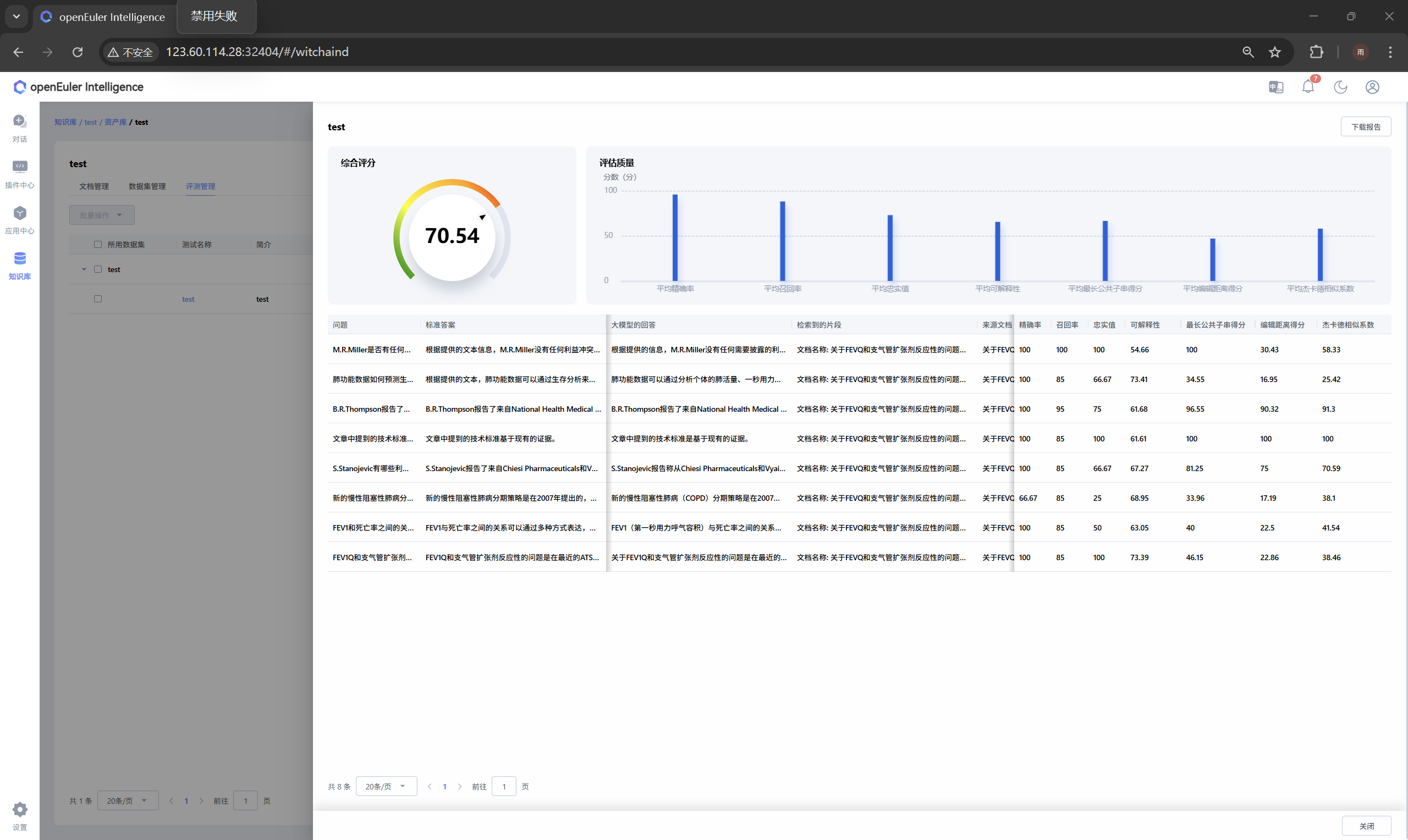
系统可基于文档自动生成问答对数据集,支持人工修改校准,用于后续效果测评。依托数据集可创建准确率测试任务,结合ragas与多种关键字评估算法,测试不同检索模型组合的实际效果,为知识库优化和算法选型提供数据依据。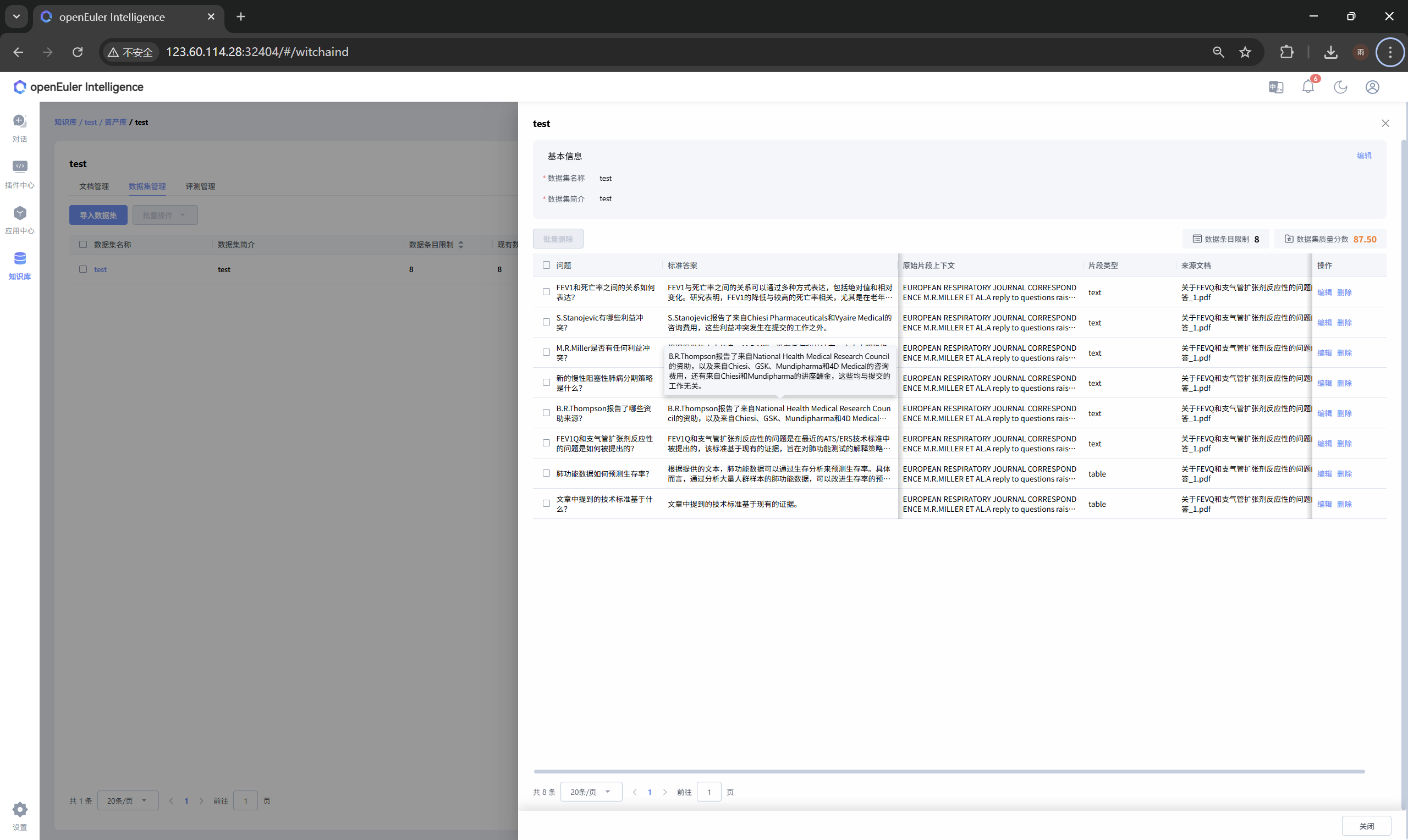
3.3 问答与文档溯源 检索增强核心应用
用户选定知识库即可发起智能问答,系统通过对应检索算法匹配资料,结合大模型生成回答。具备文档溯源能力,可查看回答对应的原始文档来源,提升内容可信度。支持调节大模型温度参数,灵活调整回答的严谨性与多样性,适配不同使用场景。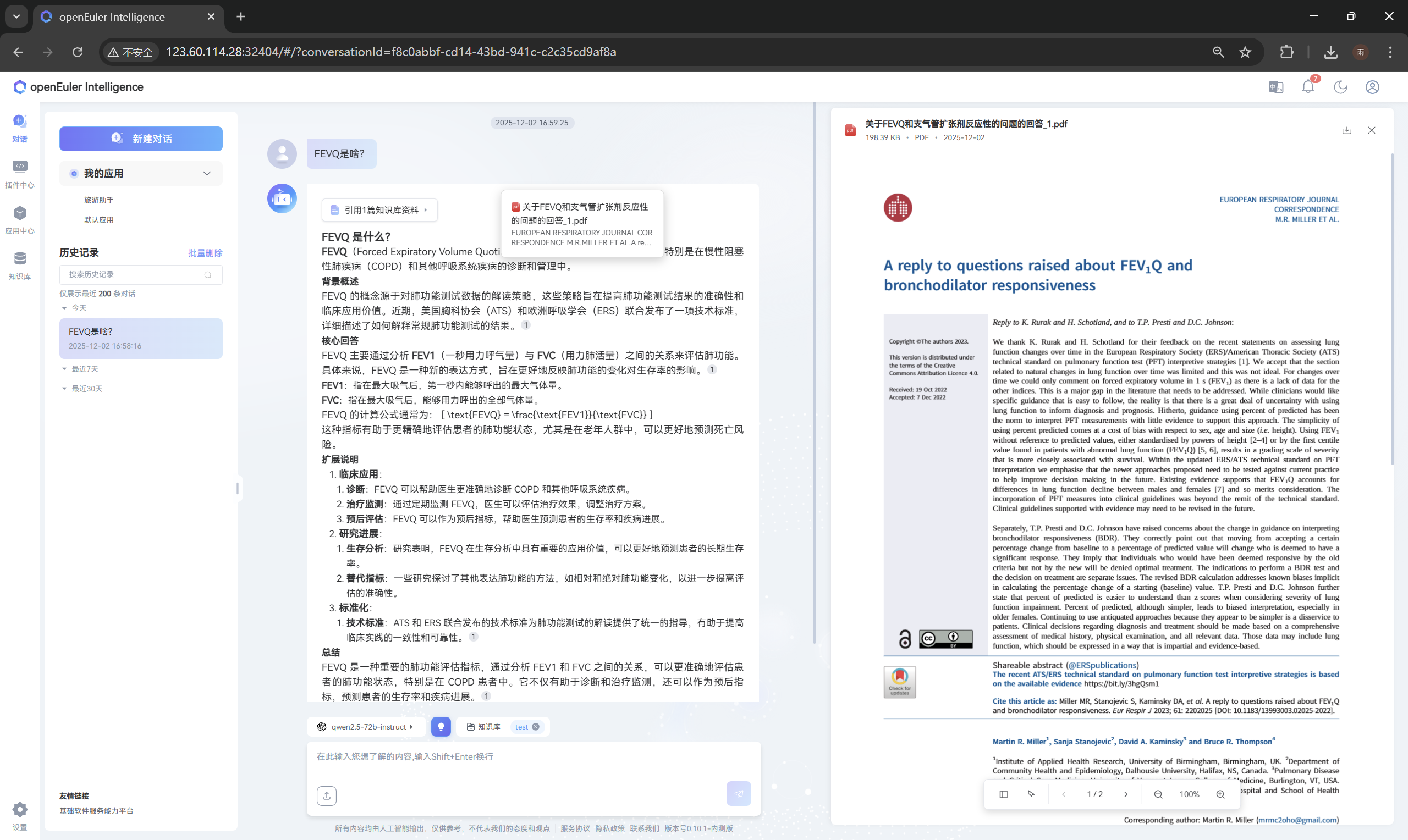
4. 资源获取
Witty-Assistant-rag具备高效灵活、权限可管控的特点,文档解析与检索能力完善,企业落地优势突出。
项目官方介绍页 https://www.openeuler.org/zh/projects/intelligence/
后端源码仓库 https://atomgit.com/openeuler/euler-copilot-rag
前端源码仓库 https://atomgit.com/openeuler/euler-copilot-witchaind-web